DN-DETR 论文笔记
DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
- DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
-
- Why Denoising accelerates DETR training?
- DN-DETR
-
- Denoising
- Attention Mask
- Label Embedding
- Experiment
- Ablation
-
- Different numbers of denoising groups
- Different noise scales
- Acceleration Analysis
- The training wall clock time and GFLOPs
论文作者的知乎文章:https://zhuanlan.zhihu.com/p/478079763
本文提出了一种新的去噪训练方法来加速DETR的训练,并对类DETR方法的慢收敛问题有了更深入的理解
结果表明,二部图匹配的不稳定导致了早期训练阶段的优化目标不一致
为了解决这一问题,除了匈牙利损失外,此文还将具有噪声的gt box输入transformer decoder,并训练模型重建原始box,有效地降低了二部图匹配的难度,提高了算法的收敛速度
方法是通用的,通过添加几十行代码,可以很容易地插入到任何类似detr的方法中
与相同设置下的基线相比,DN-DETR也可以在50%的训练阶段取得了相当的性能,又进一步实现了训练加速
与以前的检测器相比,DETR的训练收敛速度非常慢。为了获得良好的性能,在COCO检测数据集上通常需要500个周期的训练,而在最初的Faster-RCNN训练中使用了12个周期的训练
诞生了许多的办法来解决收敛缓慢的问题
- 例如,Conditional DETR 将每个查询解耦为一个内容部分和一个位置部分,强制执行一个查询与特定的空间位置有明确的对应关系
- Deformable DETR和Anchor DETR 直接将2D参考点作为查询来执行交叉注意
- DAB-DETR将查询解释为4d anchor box,并逐层改进它们
在本研究中发现慢收敛问题也是由二部图匹配造成的。
二部图匹配是不稳定的,特别是在训练的早期阶段,由于随机优化的影响,二部图匹配关系经常是不一致的
因此,对于同一幅图像,一个查询经常与不同时期的不同对象进行匹配,这使得优化更加模糊和不恒定
为了解决这一问题,提出了一种新的训练方法,通过引入一个查询去噪任务来帮助稳定训练过程中的二部图匹配
由于之前的工作已经证明可以有效地将查询解释为参考点或包含位置信息的anchor box,因此遵循它们的观点,并使用4D anchor box作为query
解决方案是将噪声化的gt box作为噪声化的查询和可学习的anchor查询一起输入到变压器解码器中
这两种查询都有相同的输入格式(x、y、w、h),可以同时输入到Transformer decoder
对于噪声查询,我们执行一个去噪任务来重建它们相应的gt box
对于其他可学习的anchor query,我们使用与普通DETR相同的训练损失,包括二部图匹配
由于噪声box不需要经过二部图匹配部分,去噪任务可以看作是一项更容易的辅助任务,有助于缓解不稳定的离散二部匹配,更快地学习box预测
为了最大化这个辅助任务的潜力,我们还将每个解码器查询作为一个边界框和一个类标签嵌入,这样我们就能够同时进行框去噪和标签去噪
总之是一种去噪训练方法。损失函数由两个组成部分组成。一种是重建损失,另一种是匈牙利损失
Why Denoising accelerates DETR training?
匈牙利匹配是图匹配中的一种流行的算法。给定一个代价矩阵,该算法输出一个最优匹配结果。
DETR是第一个在目标检测中采用匈牙利匹配来解决预测对象与GT之间的匹配问题的算法
代价矩阵的微小变化可能会导致匹配结果的巨大变化,从而进一步导致解码器查询的优化目标不一致
将detr体系的模型的训练过程视为两个阶段
- learning good anchors
- learning relative offsets
decoder query负责学习anchor
anchor的不一致更新可能使得学习相对偏移量变得困难
因此利用去噪任务作为训练捷径,使相对偏移学习更容易,因为去噪任务绕过了二部匹配
将每个decoder query解释为一个4d anchor,因此一个噪声查询可以被看作是一个“good anchor”,它附近有一个相应的gt box
因此,去噪训练有一个明确的优化目标——预测原始的box,这从本质上避免了匈牙利匹配带来的模糊性。
为了定量地评价二部匹配结果的不稳定性,我们设计了一个度量如下
对于一个训练图像,我们将从transformer decoder中得到的预测对象表示为 O i = { O 0 i , O 1 i , … , O N − 1 i } \mathbf{O}^{\mathbf{i}}=\left\{O_0^i, O_1^i, \ldots, O_{N-1}^i\right\} Oi={O0i,O1i,…,ON−1i}
式中,N为预测对象的数量,地面真实对象为 T = { T 0 , T 1 , T 2 , … , T M − 1 } \mathbf{T}=\left\{T_0, T_1, T_2, \ldots, T_{M-1}\right\} T={T0,T1,T2,…,TM−1} M是GT的数量
V n i = { m , if O n i matches T m − 1 , if O n i matches nothing V_n^i= \begin{cases}m, & \text { if } O_n^i \text { matches } T_m \\ -1, & \text { if } O_n^i \text { matches nothing }\end{cases} Vni={m,−1, if Oni matches Tm if Oni matches nothing
不稳定性:
I S i = ∑ j = 0 N 1 ( V n i ≠ V n i − 1 ) I S^i=\sum_{j=0}^N \mathbb{1}\left(V_n^i \neq V_n^{i-1}\right) ISi=j=0∑N1(Vni=Vni−1)

DN-DETR

与DAB-DETR类似,将decoder query定义为box坐标。
与DAB-DETR的架构之间的唯一区别在于decoder embedding,它被指定为类标签嵌入来支持标签去噪。
o = D ( q , F ∣ A ) \mathbf{o}=D(\mathbf{q}, F \mid A) o=D(q,F∣A)
F是Image Feature
A是Attention Mask
decoder query有两个部分。
一个是匹配的部分。这部分的输入是learnable anchors,其处理方式与DETR中的相同。
另一个是去噪部分。这部分的输入是噪声的地面真实(GT)box-label pair
去噪部分的输出旨在重建GT对象
o = D ( q , Q , F ∣ A ) \mathbf{o}=D(\mathbf{q}, \mathbf{Q}, F \mid A) o=D(q,Q,F∣A)
q表示去噪的部分
Q表示匹配的部分
为了提高去噪效率,建议在去噪部分使用多个版本的噪声GT对象。
此外,利用一个Attention Mask来防止信息从去噪部分泄漏到匹配部分,以及在同一GT对象的不同噪声版本之间
提出的方法主要是一种训练方法,可以集成到任何类似detr的模型中。
为了在DAB-DETR上进行测试,只添加了最小的修改:将decoder embedding指定为label embedding
Denoising
对于每幅图像,我们收集所有的GT对象,并在它们的边界框和类标签中添加随机噪声。
为了最大化去噪学习的效用,对每个GT对象使用多个噪声版本
通过两种方式向盒子中添加噪声:中心位移和box缩放
将λ1和λ2定义为这两种噪声的噪声尺度
对于中心位移,在中心坐标上增加一个偏移量 ( Δ x , Δ y ) (\Delta x, \Delta y) (Δx,Δy) 并且确保 ∣ Δ x ∣ < λ 1 w 2 |\Delta x|<\frac{\lambda_1 w}{2} ∣Δx∣<2λ1w and ∣ Δ y ∣ < λ 1 h 2 |\Delta y|<\frac{\lambda_1 h}{2} ∣Δy∣<2λ1h, 这里的 λ 1 ∈ ( 0 , 1 ) \lambda_1 \in(0,1) λ1∈(0,1),确保偏移后的中心坐标仍然在原始的box中
对于缩放, 设置 λ 2 ∈ ( 0 , 1 ) \lambda_2 \in(0,1) λ2∈(0,1)
box的宽高在 [ ( 1 − λ 2 ) w , ( 1 + λ 2 ) w ] \left[\left(1-\lambda_2\right) w,\left(1+\lambda_2\right) w\right] [(1−λ2)w,(1+λ2)w] [ ( 1 − λ 2 ) h , ( 1 + λ 2 ) h ] \left[\left(1-\lambda_2\right) h,\left(1+\lambda_2\right) h\right] [(1−λ2)h,(1+λ2)h] 中随机的采样
对于标签噪声,采用标签翻转,随机翻转一些地面真实的标签到其他标签。
标签翻转迫使模型根据噪声盒预测地面真实标签,以更好地捕获标签盒关系
有一个超参数的γ来控制标签与翻转的比率
重建损失为盒子的L1 Loss和GIOU Loss,以及在DAB-DETR中的类标签的focal loss
我们使用一个函数δ来表示有噪声的GT对象。因此,去噪部分中的每个查询都可以表示为 q k = δ ( t m ) q_k=\delta\left(t_m\right) qk=δ(tm),其中tm是第m个GT对象
注意,去噪只在训练中考虑,在推理过程中去掉去噪部分,只剩下匹配的部分
Attention Mask
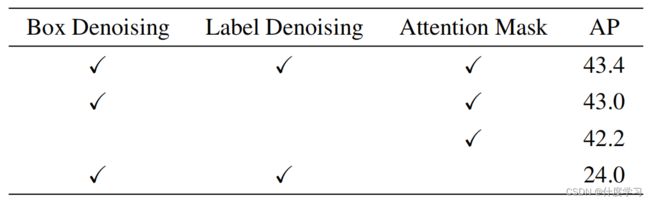
Attention Mask是模型中一个非常重要的组成部分。在没有Attention Mask的情况下,去噪训练会降低性能,而不是提高性能,如表所示

为了引入Attention Mask,首先需要将有噪声的GT对象分组。每一组都是所有GT对象的一个噪声版本。去噪部分变成
q = { g 0 , g 1 , … , g P − 1 } \mathbf{q}=\left\{\mathbf{g}_0, \mathbf{g}_1, \ldots, \mathbf{g}_{\mathbf{P}-1}\right\} q={g0,g1,…,gP−1}
g p g_p gp is defined as the p p p-th denoising group
Each denoising group contains M M M queries where M M M is the number of GT objects in the image
g p = { q 0 p , q 1 p , … , q M − 1 p } \mathbf{g}_{\mathbf{p}}=\left\{q_0^p, q_1^p, \ldots, q_{M-1}^p\right\} gp={q0p,q1p,…,qM−1p}
q m p = δ ( t m ) q_m^p=\delta\left(t_m\right) qmp=δ(tm)
Attention Mask的目的是为了防止信息泄露
有两种类型的信息泄露
一是匹配部分可以看到有噪声的GT对象,并可以很容易地预测GT对象
另一个问题是,GT对象的一个噪声版本可能会看到另一个版本
因此,Attention Mask是为了确保匹配部分看不到去噪部分,而去噪组看不到彼此

We use A = [ a i j ] W × W \mathbf{A}=\left[\mathbf{a}_{i j}\right]_{W \times W} A=[aij]W×W to denote the attention mask where W = P × M + N . P W=P \times M+N . P W=P×M+N.P and M M M are the number of groups and GT objects. N N N is the number of queries in the matching part
We let the first P × M P \times M P×M rows and columns to represent the denoising part and the latter to represent the matching part
a i j = 1 a_{i j}=1 aij=1 means the i i i-th query cannot see the j j j-th query and a i j = 0 a_{i j}=0 aij=0 otherwise.
P是分组的数量,M是GT的数量,N是query的数量
a i j = { 1 , if j < P × M and ⌊ i M ⌋ ≠ ⌊ j M ⌋ ; 1 , if j < P × M and i ≥ P × M 0 , otherwise. a_{i j}= \begin{cases}1, & \text { if } j aij=⎩ ⎨ ⎧1,1,0, if j<P×M and ⌊Mi⌋=⌊Mj⌋; if j<P×M and i≥P×M otherwise.
请注意,去噪部分是否能看到匹配部分不会影响性能,因为匹配部分的查询是不包含地面真实对象信息的学习性查询。
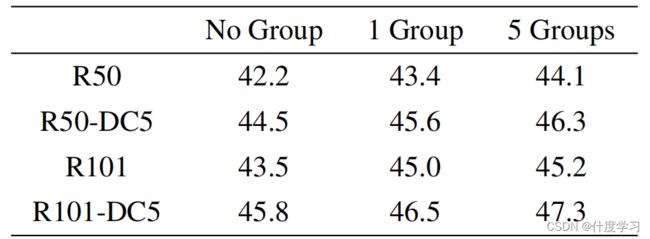
由多个去噪组引入的额外计算是可以忽略不计的——当引入5个去噪组时,对于具有R50主干的DAB-DETR,用于训练的GFLOPs仅从94.4增加到94.6,并且没有用于测试的计算开销
Label Embedding
decoder embedding在模型中被指定为label embedding,以支持box去噪和label去噪
除了COCO 2017 中的80个类外,我们还考虑了匹配部分中使用的未知类嵌入与去噪部分的语义一致。
还在标签嵌入中添加了一个指示器。如果一个查询属于去噪部分,则该指示器为1,否则为0。
Experiment
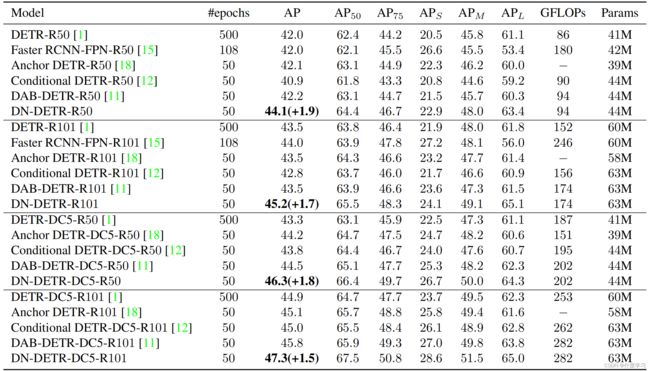
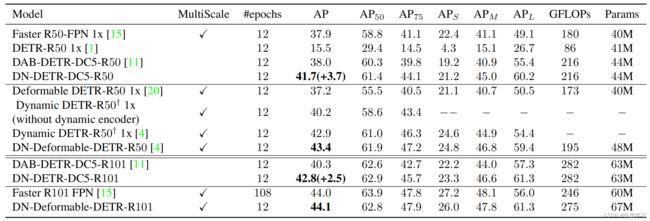

Ablation
Different numbers of denoising groups
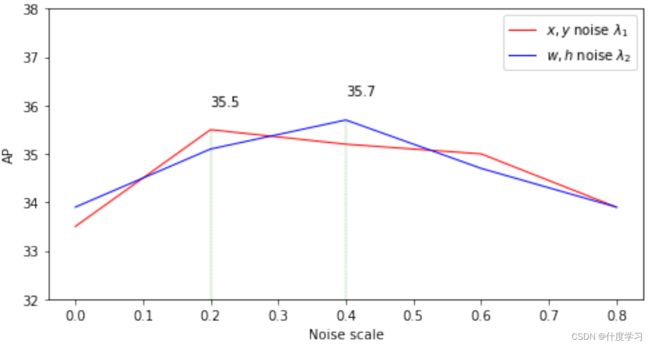
Different noise scales
Acceleration Analysis

The training wall clock time and GFLOPs
