DSSM论文精读
本文是对原文的翻译,弄懂原文每一句话的意思。
声明:鉴于本人英文一般,有翻译不对的地方望指正,谢谢!
题目
使用点击数据为网页搜索学习深度结构的语义模型
摘要
隐含语义模型,比如LSA,目的是将一个query在语义级别和它相关的文本进行映射,这是基于关键字的匹配做不到的。在本文的研究中,我们利用深度学架构搭建了一系列新的隐含语义模型,将queries和documents映射到一个公共的低维空间。被给的query和一个document的相关性通过它们的距离计算得到。本文提出的深度结构语义模型通过点击数据最大化给定query的被点击document的条件似然估计进行判别训练。为了使我们的模型可被应用于大规模网页搜索,我们使用了Word Hashing技术,它能有效地扩展我们语义模型以处理这类任务中常见的大规模词汇库。新模型在网页文档排序任务中使用实际应用中的数据集进行评估。结果展示我们的模型相比其他隐含语义模型效果最好。
关键词:深度学习,语义模型,点击数据,网页搜索
引言
目前的搜索引擎拉取网页主要依赖搜索queries和文本documents的关键字匹配。然而,在词汇匹配可能并不准确,因为documents和queries中的概念常常使用不同的词汇和语言风格表达。
隐含语义模型(隐含语义分析,LSA)能在语义级别将一个query映射到它相关的documents,这在词汇匹配方法中是做不到的[6,15,2,8,21]。这些隐含语义模型将出现相似内容的不同名词(terms)分到相同语义的分组中,来解决网页文本和搜索语句的语言差异问题。因此,一个query和一个document会在低维语义空间中表示成两个向量,即使它们没有一个相同的名词,也能得到一个很高的相似分数。由LSA模型衍生得到,概率主题模型,如PLSA和LDA,也被提出用来做语义匹配[15,2]。然而,这些模型经常使用一些无监督的方式进行训练,对检索任务使用一个评估度量很不严谨的目标函数。因此,这些模型在网页搜索任务中的效果并没有最初预期的那样好。
最近,在之前提到的隐含语义模型上做了两方面的研究,下面将简要回顾一下:
第一,点击数据由一系列queries和被点击的documents组成。被用来语义建模消除搜索queries和网页documents的语言差异[9,10]。例如,Gao等人[10]提出双语主题模型(BLTMs)和线性判别映射模型(DPMs)在语义级别上query-document匹配的应用。这些模型使用点击数据训练,专门处理document排序任务。更具体地,BLTM是一个生成式模型,要求query和它的点击documents不仅仅在主题上共享相同的分布,而且在每个主题上分配包含相似的词组。相反,DPM是通过S2Net算法[26]学习的模型,该算法遵循[3]中的学习-排序的这种范式。在queris和documents的term向量映射到低维语义空间的concept向量之后,query和它被点击的document之间的向量距离比query和它没有被点击的document之间的向量距离更小。高等人[10]表示在文本排序任务中,BLTM和DPM的效果比无监督隐含语义模型(LSA、PLSA)更好。然而,尽管使用点击数据,BLTM的训练是为了最大化log最大似然,这在文本排序任务评估中不是最优的。另一方面,DPM的训练涉及到大规模的矩阵计算,这些矩阵大小随着词汇的增长而快速增长,在一个网页搜索任务中,这可能是百万级别的量。为了使得训练事件可以接受,词汇被大幅删减。虽然词汇量变小使得模型可以被训练,但这已经不能得到最优的性能。
另一方面的研究,Salakhutdinov和Hinton使用深度自动编码器扩展语义建模[22]。他们证明了嵌入在query和document中的分层语义结构可以通过深度学习提取。这个性能优于常规的LSA[22]。然而,他们使用的深度学习方法仍然是采用无监督学习方法,模型参数的优化是为了documents的重建,而不是为了区分给定query的相关documents和不相关的documents。因此,深度学习模型并没有显著优于基于关键字匹配的基线检索模型。此外,语义哈希模型同样面临大规模矩阵计算的问题,我们将在本文展示学习带有大规模词汇表的语义模型在现实的Web搜索任务中获得良好的结果是至关重要的。
本文研究是在上面提到两个方面研究的基础上进行扩展的。我们提出了网页搜索的深度结构的语义模型(DSSM)。更具体地,我们最好的模型使用深度神经网络(DNN)为给定的query排序一系列documents。如下:第一非线性映射将query和documents映射到共同的语义空间。然后,给定query和每个document通过计算它们共同语义空间下向量的余弦相似度衡量相关性。神经网络模型使用点击数据进行判别训练,即给定query的document被点击的条件似然估计最大化。这不同于之前提到的使用无监督方式训练的隐含语义模型。我们的模型直接优化网页document排序,因此能得到最优的效果。此外,为了处理大规模词汇,我们提出word hashing方法。通过此方法可以将queries或者documents的高维term向量映射成低维的基于n-gram的letter向量。在我们的实验中表明,在语义模型中添加这个额外的表示层,word hashing使我们能够有判别式地学习具有大词汇表的语义模型,这对网页搜索是必不可少的。我们在网页document排序任务中使用真实的数据来评估模型。结果显示我们的模型最优,并在NDCG@1中得到2.5-4.3%的提升。
文章剩下的章内容,章节2回归相关工作,章节3描述我们用于网页搜索的DSSM模型。章节4展示了相关实验。章节5文章总结。
相关工作
我们的工作是基于最近两个用于信息检索(information retrieval,IR)的隐含语义模型研究的扩展。第一个是以有监督的方法利用点击数据学习隐含语义模型[10]。第二个是深度学习方法语义建模的介绍。
2.1 隐含语义模型和点击数据的使用
用于query-document匹配的隐含语义模型在信息检索领域已经是长期以来的研究课题。流行的模型可以被分为两大类,线性映射模型和生成式主题模型,我们将一一介绍。
信息检索最为有名的线性映射模型是LSA[6]。通过使用document-term矩阵的SVD降维,一个document(或者query)可以被映射到低维的concept向量 D ^ = A T D \hat \mathbf{D}= \mathbf A^T \mathbf D D^=ATD,其中 A \mathbf A A是映射矩阵。在文本搜索中,document( D \mathbf D D)和query( Q \mathbf Q Q)的相关性分数可以合理地被认为是它们concept向量( Q ^ 和 D ^ \hat \mathbf Q和\hat \mathbf D Q^和D^)余弦相似分数: s i m A ( Q , D ) = Q ^ T D ^ ∣ ∣ Q ^ ∣ ∣ ∣ ∣ D ^ ∣ ∣ ( 1 ) sim_{\mathbf A}(\mathbf Q, \mathbf D)=\frac{\hat \mathbf Q^T \hat \mathbf D}{||\hat \mathbf Q||||\hat \mathbf D||}\space\space\space\space(1) simA(Q,D)=∣∣Q^∣∣∣∣D^∣∣Q^TD^ (1) 除了隐含语义模型,使用被点击query-document对训练的转移模型为语义匹配提供可选择方法[9]。不同于隐含语义模型,基于转移的方法直接学习document和query之间的转移关系。最近的研究表明,给定大量的点击数据去训练,该方法能取得很好的效果[9,10]。在章节4中我们也将此方法和我们的模型进行对比。
2.2 深度学习
最近,深度学习方法被成功应用于各种语言、信息检索任务[1,4,7,19,22,23,25]。通过研究深度学习结构,深度学习技术可以从训练数据中发现对任务有用的不同抽象级别中隐含的结构和特征。在[22]中,Salakhutdinov和Hinton使用深度网络(auto-encoder,自动编码器)扩展LSA模型,然后去发现嵌入在query和和document中的分层语义结构。他们提出了一个语义哈希(SH)方法,该方法利用从深度自动编码器中学习到的bottleneck特征进行信息检索。这些深度模型训练分为两个阶段:第一,生成式模型(如被限制的玻尔兹曼机)学习document的term向量到低维语义concept向量的层到层之间的映射。第二,模型参数优化是通过最小化document原始的term向量和重构后的term向量之间的交叉熵误差。中间层激活作为特征(如bottleneck)被用于文档排序。他们的评估展示了SH在文本检索任务中的效果由于LSA。然而,SH有两个问题,并且比基于检索模型(如使用TF-IDF term权重的余弦相似性)的标准词汇匹配效果差。第一个问题是模型参数优化是为了文本term向量的重构,而不是为了从给定query不相关的documents中区分相关的documents。第二,为了使计算成本可控,documents的term向量仅仅有最为频繁的2000个单词组成。在下一个章节,我们将介绍我们的模型如何解决这两个问题。
用于网页搜索的深度结构语义模型
3.1DNN用于计算语义特征
我们扩展典型的DNN架构用于将未处理的文本特征映射到语义空间中的特征,如图1所示。DNN的输入(未处理文本特征)是高维的term向量,如未归一化的query或document的term原始计数,DNN的输出是一个映射在低维语义特征空间中的concept向量。DNN模型被用来网页排序如下步骤:1)将term向量映射成相应的语义concept向量;2)计算document和query的concept向量余弦相似度作为它们的相关性分数。
更正式地,如果我们用 x x x表示输入的term向量, y y y表示输入的concept向量。 l i l_i li表示网络的中间隐藏层, W i W_i Wi表示矩阵的第 i i i个权重, b i b_i bi表示偏置项,我们有 l 1 = W 1 x l_1=W_1x l1=W1x l i = f ( W i l i − 1 + b i ) , i = 2 , . . . , N − 1 l_i=f(W_il_{i-1}+b_i),\space\space i=2,...,N-1 li=f(Wili−1+bi), i=2,...,N−1 y = f ( W N l N − 1 + b N ) y=f(W_Nl_{N-1}+b_N) y=f(WNlN−1+bN)其中我们使用tanh作为隐藏层和输出层的激活函数, f ( x ) = 1 − e − 2 x 1 + e − 2 x f(x)=\frac{1-e^{-2x}}{1+e^{-2x}} f(x)=1+e−2x1−e−2xquery和document之间的语义相关性分数: R ( Q , D ) = c o s i n e ( y Q , y D ) = y Q T y D ∣ ∣ y Q ∣ ∣ ∣ ∣ y D ∣ ∣ R(Q,D)=cosine(y_Q,y_D)=\frac{y_Q^Ty_D}{||y_Q||||y_D||} R(Q,D)=cosine(yQ,yD)=∣∣yQ∣∣∣∣yD∣∣yQTyD其中 y Q y_Q yQ和 y D y_D yD是query和document的concept向量。在网页搜索中,给定query,document使用相关性分数进行排序。
通常,在信息检索中,term向量的大小和网页文档索引集合的词汇表一致,可以看成是信息检索中原始bag-of-words特性。真实的网页搜索任务中的词汇集是非常大的。因此,使用term向量作为输入,神经网络输入层的大小在模型训练和推理时变得不可控。为了解决这个问题,我们在DNN的第一层引入了word hashing方法,如图1所示。这一层仅仅由线性单元组成,它的大权重矩阵不用学习。在下一小节中,我们详细介绍word hashing方法。
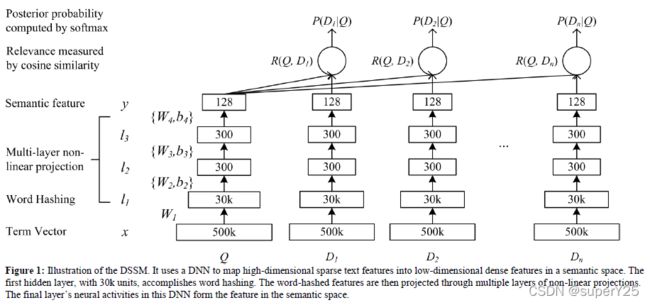
3.2 Word Hashing
这里介绍的word hashing方法主要是为了减少term向量的维度。它是基于字母(letter)的n-gram算法,是针对我们任务的新方法。给定一个单词(如 good),我们首先添加单词的开头和结尾标识(如 #good#)。然后,我们按照字母的n-gram拆分单词(如 tri-grams:#go, goo, ood, od#)。最后,这个单词使用字母n-grams的向量表示。
该方法的一个问题就是冲突,即两个不同的单词由相同的字母n-gram向量表示。表1展示了两个词汇表中word hashing统计,对比原始one-hot向量的大小,word hashing允许我们使用更低维的向量表示query或者document。拿40K大小的词汇表举例,使用字母tri-gram,每个单词可以使用10306维向量表示,少量冲突的情况下维度减少了4倍。在大规模词汇库应用中,向量维度的减少是非常重要的。如表1所示,在500K大小的词汇表中,使用字母tri-gram,每个单词可以表示成30621维向量,在冲突率为0.0044%(22/500000)的情况下维度减少了16倍。
虽然英语单词的数量是无限的,但在英语(或其他相似的语言)中字母n-grams的个数是有限的。而且,word hashing可以将单词的形态变化映射到字母n-gram空间彼此相近的点。更重要的是,虽然在基于单词表示中训练集中的一个单词不可见会造成一些困难,但使用基于字母n-gram表示时这就不是问题了。唯一的风险就是如表1所示的轻微冲突。因此,基于字母n-gram的word hashing对词汇表外的单词也是鲁棒的,允许我们将DNN解决方案扩展到需要超大词汇表的Web搜索任务中。我们将在第4章节介绍该计算的优势。
在我们的实现中,基于字母n-gram的word hashing可以看成时一个固定的线性转换,通过输入层term向量映射到下一层的字母n-gram向量,如图1所示。因为字母n-gram向量是低维向量,所以可以有效地进行DNN学习。

3.3 学习DSSM
点击日志由一系列queries和它们被点击的documents组成。我们假设一个query和因为它被点击的documents是相关的,至少有一部分相关。受到语音和语言处理判别式训练方法的启发,我们提出了有监督方法训练我们的模型,如DSSM模型中权重矩阵 W i W_i Wi和偏置项向量 b i b_i bi,以致给定queries的被点击documents的条件似然概率最大化。
首先,我们通过softmax函数计算给定query的document的后验概率,该概率来自于它们之间的语义相关度: P ( D ∣ Q ) = e x p ( γ R ( Q , D ) ) ∑ D ′ ∈ D e x p ( γ R ( Q , D ′ ) ) P(D|Q)=\frac{exp(\gamma R(Q,D))}{\sum_{D'\in \mathbf D}exp(\gamma R(Q,D'))} P(D∣Q)=∑D′∈Dexp(γR(Q,D′))exp(γR(Q,D))其中 γ \gamma γ表示softmax函数的平滑因子,根据经验设置的。 D \mathbf D D表示被排序documents候选集。理想地, D \mathbf D D应该包含所有可能的documents。实际上,对于每个query和被点击的document(表示成 ( Q , D + ) (Q,D^+) (Q,D+), Q Q Q表示query, D + 表 示 被 点 击 的 d o c u m e n t s D^+表示被点击的documents D+表示被点击的documents),我们近似 D \mathbf D D包含 D + D^+ D+和四个随机选择的未点击document(表示成 D j − , j = 1 , 2 , 3 , 4 D^-_j,j=1,2,3,4 Dj−,j=1,2,3,4)。在我们初步研究中,通过不同的采样策略选择未点击的document并没有什么不同。
在训练过程中,模型参数通过在训练集中给定query的最大化被点击documents的似然概率估计。相等地,我们需要最小化如下损失函数: L ( Λ ) = − l o g ∏ ( Q , D + ) P ( D + ∣ Q ) L(\Lambda)=-log\prod_{(Q,D^+)}P(D^+|Q) L(Λ)=−log(Q,D+)∏P(D+∣Q)其中 Λ \Lambda Λ表示神经网络 { W i , b i } \{W_i,b_i\} {Wi,bi}的参数集,因为 L ( Λ ) L(\Lambda) L(Λ)可微,模型训练使用基于梯度的数值优化算法进行训练。由于篇幅省略了求导的详细过程。
3.4 实现细节
为了得到训练参数并避免过拟合,我们把点击数据分为训练集和验证集两个不重叠的部分。在我们的实验中,使用训练集训练模型,使用验证集优化参数。DNN实验,我们使用三层隐藏层架构,如图1所示。第一层隐藏层是word hashing层,包含30K个节点(字母tri-grams的大小如表1所示)。后面二层隐藏层都有300个节点,最后输出层有128个节点。word hashing是基于固定的映射矩阵实现的。相似度度量是基于128维的输出层。根据[20],我们使用均匀分布给网络权重初始化,区间范围在 [ − 6 / ( f a n i n + f a n o u t ) , 6 / ( f a n i n + f a n o u t ) ] [-\sqrt{6/(fanin+fanout)},\sqrt{6/(fanin+fanout)}] [−6/(fanin+fanout),6/(fanin+fanout)],其中 f a n i n , f a n o u t fanin,fanout fanin,fanout表示输入输出的单元数。根据经验,我们发现逐层做预训练并不能给模型带来更好的效果。在模型训练阶段,我们使用mini-batch的随机梯度下降。每一个mini-batch由1024个样本组成,我们观察到DNN训练通常在整个数据集训练20轮后就收敛了。
实验
我们使用真实的数据进行网页排序任务评估DSSM模型。在本节中,我们首先描述了用于模型评估的数据集。然后,我们将DSSM模型和其他现存最优的排序模型进行对比分析。我们还研究了章节3中提到的技术的故障影响(break-down impact of the techniques)。
4.1 数据集和评估方法
我们使用真实的数据集评估检索模型,以下称为评估数据集。评估数据集包含16510个英文queries,采样自商业搜索引擎一年的搜索日志。平均每个query对应15个网页文本(URLs),每个query和title对有一个相关性等级,这个等级由人工生成,并且有5个级别,0到4。其中4表示document和query相关程度最高,0表示document和query相关程度最低。所有的queries和documents经过预处理,空白被标记、小写、数字保留、没有词干\词形变化。
本研究所有用到的排序模型(DSSM、主题模型、线性映射模型)包含很多超参数,需要根据经验进行估计。在所有的实验中,我们使用2折交叉验证:数据集的一半用来获取结果,另一半用来参数调优。全局的检索结果来自两个数据集的结合。
所有的排序模型结果通过NDCG[17]的平均值进行评估。我们在本节中报告的级别1、3、10的截断NDCG分数。我们还使用了配对t检验进行显著性实验。当p值小于0.05时认为差异是有统计学意义的。
在我们的实验中,我们假设query和query相关被点击的documents的标题是平行的。我们使用和[11]相似的处理方法从一年的查询日志文件中提取了大量的query-title对进行模型训练。一些之前的研究[24,11]展示了query的点击字段,当它有效时,对网页搜索是最有效的信息,其次是标题字段。然而,对于很多URLs点击信息是不可用的,尤其是新URLs和尾部URLs,使它们的点击字段无效(由于稀疏,该字段要么是空的,要么是不可靠的)。本研究中,我们假设评估数据集中每个document要么是新URL,要么是尾URL,因此没有点击信息(它的点击字段是无效的)。我们的研究目标是为了研究如何从这些有大量点击信息的URLs中学习隐含语义模型,并应用模型提高这些尾URLs或者新URLs的检索。为此,我们的实验仅仅使用网页文本的标题进行排序。为了训练隐含语义模型,我们随机采样近1亿query-title对,这些documents是非常流行的并且有大量的点击信息。我们使用包含没有点击信息的评估数据对模型进行评估。我们以同样的方式对query-title进行预处理作为评估数据以保持数据的一致性。
4.2 实验结果
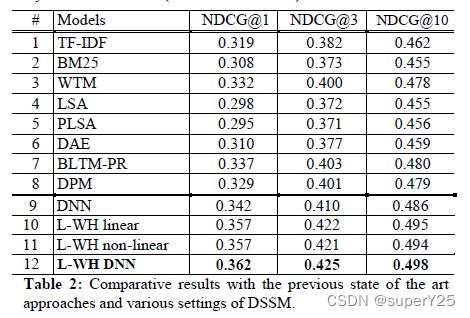
我们实验结果的概要如表2所示,我们将DSSM模型最好的版本(第12行)和三组baseline模型进行对比。第一组baseline模型包含一对被广泛使用的词汇匹配模型,如TF-IDF(第1行)和BM25(第2行)。第二组baseline模型一个单词转换模型(WTM,第3行),其通过学习query的单词和document的单词之间的词汇映射解决query-document语言差异的问题[9,10]。第三组baseline模型包含是当前最优的隐含语义模型,通过无监督学习documents(LSA,PLSA,DAE;第4,5,6行)或者有监督学习点击数据(BLTM-PR,DPM;第7,8行)。为了对比实验结果,我们根据[10]描述的实现了这些模型。由于模型复杂度的限制,LSA和DPM模型使用40K词汇训练。其他模型使用500K词汇训练。接下来篇幅描述更详细的细节。
TF-IDF(第1行)是baseline模型,documents和queries使用TF-IDF算法被表示成term向量。然后通过计算query和document的term向量余弦相似度对documents进行排序。我们也将BM25(第2行)排序模型作为一个baseline模型。TF-IDF和BM25都是基于term匹配的document排序模型。它们在相关的研究中被广泛使用作为baseline模型。
WTM(第3行)是我们根据[9]实现的单词转换模型,用作模型对比分析。我们可以看到WTM模型比baseline模型效果好很多,和[9]中的结果一致。LSA(第4行)是我们实现的隐含语义分析模型。我们使用PCA替代SVD计算线性映射矩阵。queries和titles被认为是分开的documents,来自点击数据的点击对信息(pair information)并没有在这个模型中使用。PLSA(第5行)是我们根据[15]实现的模型,模型训练时仅仅是使用documents(如query-title对中的title)。不同于[15]的是我们实现的PLSA使用如[10]中的MAP估计进行模型学习。DAE(第6行)是我们实现的基于深度自动编码器的语义哈希模型,是Salakhutdinov和Hinton在[22]中提出的模型。由于模型训练的复杂度,输入是基于40K词库的term向量,DAE架构包含4个隐藏层,每层由300个节点,中间的瓶颈层(bottleneck layer)有128个节点。模型使用documents数据进行无监督学习。在微调阶段,我们使用交叉熵误差作为训练标准。中间层激活被用作特征来计算query和document之间的余弦相似度。我们的结果和之前在[22]中报告的结果一致。基于隐含语义模型的DNN效果好于线性映射模型(如LSA)。然而,LSA和DAE都仅仅使用document数据以无监督的方式训练。因此,不会好于最优的词汇匹配排序模型。
BLTM-PR(第7行)是[10]中描述的双语主题模型不同版本中的最好的一个。带有后验规则的BLTM(BLTM-PR)使用query-title对训练模型,使用带有约束的EM算法强制将具有相同terms部分的query和title对分配给每个隐藏主题。DPM(第8行)是[10]提出的线性判别映射模型,映射矩阵是使用S2Net算法[26]对相关和不相关的query-title对进行判别学习得到的。和BLTM一样都是PLSA的扩展,DPM可以看作是LSA的扩展,线性映射矩阵是使用点击数据以有监督的方法学习并以document排序优化得到。我们可以看到,使用点击数据训练模型可以提高模型效果。BLTM-PR和DPM模型的效果都比baseline模型(TF-IDF和BM25)好。
第9到12行展示了不同版本DSSM模型的实验结果。DNN(第9行)是没有使用word hashing的DSSM模型。它使用和DAE(第6行)相同的架构,但使用点击数据以有监督的方式训练。输入和DAE一样也是基于40k的词汇表的term向量。L-WH linear(第10行)是使用基于字母tri-grams的word hashing建模,然后有监督训练模型。和L-WH nonlinear(第11行)不同的是我们在它的输出层没有应用任何非线性激活函数,如tanh。L-WH DNN(第12行)是我们最好的基于DNN的语义模型,使用了3层隐藏层,包含带有基于字母tri-grams的word hashing层(L-WH)和输出层,使用query-title对进行判别式训练,如章节3描述。虽然基于字母n-grams的word hashing方法能应用任意大的词汇表,为了和其他模型对比的公平性,我们的模型也使用500K的词汇表。
表2的结果展示了深度结构语义模型是最优的模型,在NDCG中以统计上显著的优势击败其他方法,并且论证了使用DNN模型进行语义匹配是有效的。
从表2的结果,我也可以清楚点击数据的有监督学习,以信息检索为优化标准对排序进行裁剪,对获取更优的document排序效果是必要的。例如,DNN和DAE(第9和6行)使用相同的40K词汇表和采用相同的深度结构。前者比后者在NDCG中效果提高3.2个点。
Word Hashing允许我们使用大规模的词汇表为模型训练,例如,第12行模型使用500K的词汇表,效果比第9行使用40K词汇表的模型好。尽管前者的自由参数略少于后者,因为单词哈希层只包含大约30k个节点。
我们还在建模嵌入query和document的语义信息时评估使用深层结构和浅层结构的影响。结果如表2所示,DAE(第3行)的效果比LSA(第2行)好,而LSA和DAE都是无监督模型。在有监督模型中,我们观察到浅层结构和深层结构有类似的效果。对比第11和12行的模型,我们知道增加非线性层的数量(从1到3)可以提升NDCG分数,提高了0.4-0.5个点,然而,如果都是一层的浅层模型,在线性和非线性模型之间没有什么不同(第10行 vs 第11行)。
总结
我们展示和评估了一系列新的隐含语义模型,特别时那些基于深度架构的模型,我们称为DSSM模型。主要的贡献是对隐含语义模型(如LSA模型)三个方面的扩展。第一,我们使用点击数据训练优化所有版本模型的参数,这些模型的直接目标是document排序。第二,受到深度学习模型在语言识别的成功应用的启发[5,13,14,16,18],我们使用多个隐藏表示层将线性语义模型扩展到非线性语义模型。深度架构更深,建模能力更强,以致在queries和documents中的更复杂的语义结构都能被捕获和表示。第三,我们使用基于字母n-gram的word hashing技术,这种技术被证明有助于扩大深度模型的训练,以便在真实的网页搜索中使用非常大的词汇表。在我们的实验中,我们展示了与上述三个方面相关的新技术可以显著提高文档排序任务的性能。这三组新技术的结合产生了一种新的最先进的语义模型,它以显著的优势击败了所有之前研究的竞争模型。
参考文献
[1] Bengio, Y., 2009. “Learning deep architectures for AI.” Foundumental Trends Machine Learning, vol. 2.
[2] Blei, D. M., Ng, A. Y., and Jordan, M. J. 2003. “Latent Dirichlet allocation.” In JMLR, vol. 3.
[3] Burges, C., Shaked, T., Renshaw, E., Lazier, A., Deeds, M., Hamilton, and Hullender, G. 2005. “Learning to rank using gradient descent.” In ICML.
[4] Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., and Kuksa, P., 2011. “Natural language processing (almost) from scratch.” in JMLR, vol. 12.
[5] Dahl, G., Yu, D., Deng, L., and Acero, A., 2012. “Contextdependent pre-trained deep neural networks for large vocabulary speech recognition.” in IEEE Transactions on Audio, Speech, and Language Processing.
[6] Deerwester, S., Dumais, S. T., Furnas, G. W., Landauer, T., and Harshman, R. 1990. “Indexing by latent semantic analysis.” J. American Society for Information Science, 41(6): 391-407
[7] Deng, L., He, X., and Gao, J., 2013. “Deep stacking networks for information retrieval.” In ICASSP
[8] Dumais, S. T., Letsche, T. A., Littman, M. L., and Landauer, T. K. 1997. “Automatic cross-linguistic information retrieval using latent semantic indexing.” In AAAI-97 Spring Symposium Series: Cross-Language Text and Speech Retrieval.
[9] Gao, J., He, X., and Nie, J-Y. 2010. “Clickthrough-based translation models for web search: from word models to phrase models.” In CIKM.
[10] Gao, J., Toutanova, K., Yih., W-T. 2011. “Clickthroughbased latent semantic models for web search.” In SIGIR.
[11] Gao, J., Yuan, W., Li, X., Deng, K., and Nie, J-Y. 2009. “Smoothing clickthrough data for web search ranking.” In SIGIR.
[12] He, X., Deng, L., and Chou, W., 2008. “Discriminative learning in sequential pattern recognition,” Sept. IEEE Sig. Proc. Mag.
[13] Heck, L., Konig, Y., Sonmez, M. K., and Weintraub, M. 2000. “Robustness to telephone handset distortion in speaker recognition by discriminative feature design.” In Speech Communication.
[14] Hinton, G., Deng, L., Yu, D., Dahl, G., Mohamed, A., Jaitly, N., Senior, A., Vanhoucke, V., Nguyen, P., Sainath, T., and Kingsbury, B., 2012. “Deep neural networks for acoustic modeling in speech recognition,” IEEE Sig. Proc. Mag.
[15] Hofmann, T. 1999. “Probabilistic latent semantic indexing.” In SIGIR.
[16] Hutchinson, B., Deng, L., and Yu, D., 2013. “Tensor deep stacking networks.” In IEEE T-PAMI, vol. 35.
[17] Jarvelin, K. and Kekalainen, J. 2000. “IR evaluation methods for retrieving highly relevant documents.” In SIGIR.
[18] Konig, Y., Heck, L., Weintraub, M., and Sonmez, M. K. 1998. “Nonlinear discriminant feature extraction for robust text-independent speaker recognition.” in RLA2C.
[19] Mesnil, G., He, X., Deng, L., and Bengio, Y., 2013. “Investigation of recurrent-neural-network architectures and learning methods for spoken language understanding.” In Interspeech.
[20] Montavon, G., Orr, G., Müller, K., 2012. Neural Networks: Tricks of the Trade (Second edition). Springer.
[21] Platt, J., Toutanova, K., and Yih, W. 2010. “Translingual doc-ument representations from discriminative projections.” In EMNLP.
[22] Salakhutdinov R., and Hinton, G., 2007 “Semantic hashing.” in Proc. SIGIR Workshop Information Retrieval and Applications of Graphical Models.
[23] Socher, R., Huval, B., Manning, C., Ng, A., 2012. “Semantic compositionality through recursive matrix-vector spaces.” In EMNLP.
[24] Svore, K., and Burges, C. 2009. “A machine learning approach for improved BM25 retrieval.” In CIKM.
[25] Tur, G., Deng, L., Hakkani-Tur, D., and He, X., 2012. “Towards deeper understanding deep convex networks for semantic utterance classification.” In ICASSP.
[26] Yih, W., Toutanova, K., Platt, J., and Meek, C. 2011. “Learning discriminative projections for text similarity measures.” In CoNLL.
个人理解
全文讲了这么多,其实总结一下就是利用DNN模型将原来的term向量转化成隐含语义的低维向量,为了解决大词汇库的问题提出了word hashing技术。然后为了适应网页搜索排序任务,使用 P ( D ∣ Q ) P(D|Q) P(D∣Q)的条件似然估计优化模型参数。