postgresql之窗口函数
postgresql之窗口函数
工作中可能会遇到按照部门业绩排名?找出前N的员工进行业绩奖励?两次消费时间隔了多久?等等这样的问题。
对于这样的问题,使用窗口函数能很好的简化sql。
窗口函数是sql中一类特别的函数,通过查询筛选出的行的某些部分,窗口调用函数实现了类似于聚合函数的功能。 但是两者又不同,通俗的讲,聚合函数是将结果合并成一行(每组一条数据),但是窗口函数是扫描所有的行,然后你的表有几行,结果就是有几行。
有的函数随着记录不同,窗口大小都是固定的,这种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。
窗口函数的语法
窗口函数调用语法如下:
function_name ([expression [, expression ... ]]) OVER ( window_definition )
function_name ([expression [, expression ... ]]) OVER window_name
function_name ( * ) OVER ( window_definition )
function_name ( * ) OVER window_name
这里的window_definiton语法如下:
[ existing_window_name ]
[ PARTITION BY expression [, ...] ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [ NULLS { FIRST | LAST } ] [, ...] ]
[ frame_clause ]
- window_name引用的是查询语句中WINDOW 子句定义的命名窗口规范。命名窗口规范通常只是用OVER window_name 来引用
- PARTITION BY选项将查询的行分为一组进入partitions, 这些行在窗口函数中单独处理。PARTITION BY和查询级别GROUP BY 子句做相似的工作,除了它的表达式只能作为表达式不能作为输出列的名字或数。 没有PARTITION BY,所有由查询产生的行被视为一个单独的分区
- ORDER BY 选项决定分区中的行被窗口函数处理的顺序。它和查询级别ORDER BY子句做相似的工作, 但是同样的它不能作为输出列的名字或数。没有ORDER BY,行以一个不被预知的顺序处理。
这里frame_clause用在动态窗口函数中,静态窗口函数哪怕用了也不生效, frame_clause可以是:
[ RANGE | ROWS ] frame_start
[ RANGE | ROWS ] BETWEEN frame_start AND frame_end
可以用RANGE 或 ROWS模式声明;不管哪种情况, 它的变化范围是从frame_start到frame_end。如果省略了frame_end 默认为CURRENT ROW。
frame_start和frame_end可以是:
UNBOUNDED PRECEDING # 表示框架从分区的第一行开始
UNBOUNDED FOLLOWING # 表示框架以分区的最后一行结束
CURRENT ROW # 1.rowsm模式:意味着框架以当前行开始或结束
# 2.在RANGE模式,意味着框架以当前行在 ORDER BY序列中的第一个或最后一个元素开始或结束
value PRECEDING # 边界是当前行减去value的值
value FOLLOWING # 边界是当前行加上value的值
注意:value PRECEDING和value FOLLOWING 当前只允许ROWS模式。这也就意味着,窗口范围从当前行之前或之后指定的行数启动或结束。 value必须是整型表达式,而不能包含变量,聚合函数,或者窗口函数。 该值不能为空或负,但可以是零,表示只选择当前行本身。
例如,以下写法都是可以的:
- rows Between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING 窗口中当前分区的所有行,相当于不写
- rows UNBOUNDED PRECEDING 表示窗口范围从分区的第一行到当前当前行
- rows BETWEEN 1 PRECEDING AND 1 FOLLOWING 表示窗口范围包括前一行,当前行,下一行共3行的数据范围
窗口函数适用的函数
目前,窗口函数可以调用的不仅有内建的窗口函数,还有任何用户定义的聚合函数和内建聚合函数,常见的min(),max(),count(),sum(),avg()就是可用在窗口函数中的内建聚合函数,其余可用的内建函数见官网文档。
内建窗口函数:
| 函数 | 返回类型 | 描述 |
|---|---|---|
| row_number() | bigint | 在其分区中的当前行号,从1计 |
| rank() | bigint | 有间隔的当前行排名;与它的第一个相同行的row_number相同 |
| dense_rank() | bigint | 没有间隔的当前行排名;这个函数计数对等组。 |
| percent_rank() | double precision | 当前行的相对排名: (rank - 1) / (总行数 - 1) |
| cume_dist() | double precision | 当前行的相对排名:(前面的行数或与当前行相同的行数)/(总行数) |
| ntile(num_buckets integer) | integer | 从1到参数值的整数范围,尽可能相等的划分分区 |
| lag(value any [, offset integer [, default any ]]) | 类型同 value | 计算分区当前行的前offset 行,返回value 。如果没有这样的行, 返回default替代。 offset和default 都是当前行计算的结果。如果忽略了,则offset 默认是1,default默认是 null。 |
| lead(value any [, offset integer [, default any ]]) | 类型同value | 计算分区当前行的后offset行, 返回value。如果没有这样的行, 返回default替代。 offset和default 都是当前行计算的结果。如果忽略了,则offset 默认是1,default默认是 null |
| first_value(value any) | 类型同value | 返回窗口第一行的计算value值 |
| last_value(value any) | 类型同value | 返回窗口最后一行的计算value值 |
| nth_value(value any, nth integer) | 类型同value | 返回窗口第nth行的计算 value值(行从1计数);没有这样的行则返回 null |
将内建窗口函数分类,可分为
- 序号函数:row_number() | rank() | dense_rank()
- 分布函数:percent_rank() | cume_dist()
- 前后函数:lag() | lead()
- 其他函数:ntile() | nth_value()
- 头尾函数:first_value() | last_value()
其中:nth_value(),first_value(),last_value()是可实现动态窗口的。
sql示例
接下来,给出sql实例,一起来看看这些窗口函数的用法。
插入测试数据:
create table window_test(
name varchar(255),
subjects varchar(255),
scores int4
);
insert into window_test values ('张三','语文',random()*100);
insert into window_test values ('张三','数学',random()*100);
insert into window_test values ('张三','英语',random()*100);
insert into window_test values ('张三','化学',random()*100);
insert into window_test values ('张三','物理',random()*100);
insert into window_test values ('张三','生物',random()*100);
insert into window_test values ('张三','历史',random()*100);
insert into window_test values ('张三','地理',random()*100);
insert into window_test values ('张三','政治',random()*100);
insert into window_test values ('李四','语文',random()*100);
insert into window_test values ('李四','数学',random()*100);
insert into window_test values ('李四','英语',random()*100);
insert into window_test values ('李四','化学',random()*100);
insert into window_test values ('李四','物理',random()*100);
insert into window_test values ('李四','生物',random()*100);
insert into window_test values ('李四','历史',random()*100);
insert into window_test values ('李四','地理',random()*100);
insert into window_test values ('李四','政治',random()*100);
insert into window_test values ('王五','语文',random()*100);
insert into window_test values ('王五','数学',random()*100);
insert into window_test values ('王五','英语',random()*100);
insert into window_test values ('王五','化学',random()*100);
insert into window_test values ('王五','物理',random()*100);
insert into window_test values ('王五','生物',random()*100);
insert into window_test values ('王五','历史',random()*100);
insert into window_test values ('王五','地理',random()*100);
insert into window_test values ('王五','政治',random()*100);
insert into window_test values ('赵六','语文',random()*100);
insert into window_test values ('赵六','数学',random()*100);
insert into window_test values ('赵六','英语',random()*100);
insert into window_test values ('赵六','化学',random()*100);
insert into window_test values ('赵六','物理',random()*100);
insert into window_test values ('赵六','生物',random()*100);
insert into window_test values ('赵六','历史',random()*100);
insert into window_test values ('赵六','地理',random()*100);
insert into window_test values ('赵六','政治',random()*100);
1. 序号函数:row_number() | rank() |dense_rank()
select name,subjects,scores,
row_number() over (partition by name order by scores desc) as row_number,
rank() over (partition by name order by scores desc) as rank,
dense_rank() over (partition by name order by scores desc) as drank
from window_test;
显示结果如下图。表示每个同学按照学习成绩降序显示结果。这三个函数都能得到序号结果。
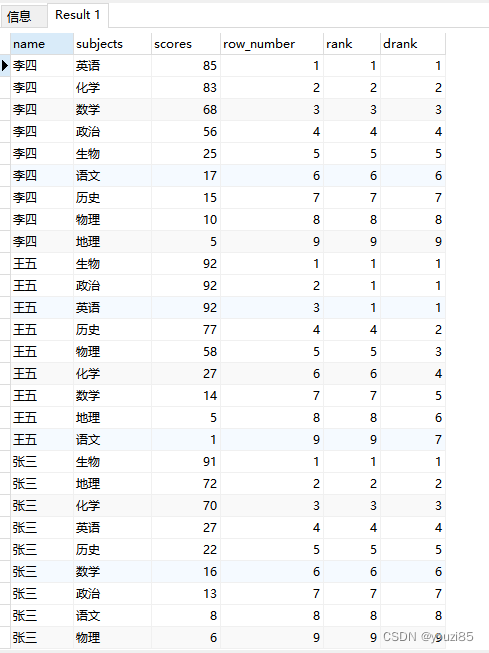
这些函数可以运用于查询每个同学最好的几门课的成绩等这类问题。但是添加过滤条件的时候不能直接加在where条件中,而是需要将查询结果作为子表,在外面套查询语句再用where过滤。原因是窗口函数是在group by,having之后执行的,在where这一步还没执行到窗口函数
# 若是直接 where条件中过滤,会报错
select name,subjects,scores,
row_number() over (partition by name order by scores desc) as row_number,
rank() over (partition by name order by scores desc) as rank,
dense_rank() over (partition by name order by scores desc) as drank
from window_test
where row_number<=4;

select * from (
select name,subjects,scores,
row_number() over (partition by name order by scores desc) as row_number,
rank() over (partition by name order by scores desc) as rank,
dense_rank() over (partition by name order by scores desc) as drank
from window_test
)a
where row_number<=4;
得到结果看下图。查询得到了每个同学最高的四门课的成绩。注意王五同学的成绩,因为王五同学存在三门课同分的情况,这时用row_number、rank、dense_rank得到的结果不同,这也就是这三个函数不同的地方。
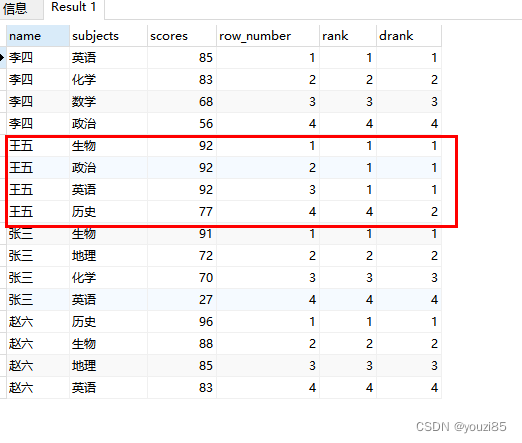
row_number()就是得到行号,不管你的成绩是否一样,都按序依次标号。rank()和dense_rank()都是对同样的成绩都是统一排序,同一名次,但是不同的是,rank()函数对于后面的数据是直接跳过并列数的结果往下编号,而dense_rank()是不跳过序号直接往下编号。
另外,这三个函数对于滑动窗口的使用都是无效的,不会报错,但是没什么改变,以row_number()举个例子看看。
select name,subjects,scores,row_number() over (partition by name order by scores desc),
row_number() over (partition by name order by scores desc rows between 1 preceding and 1 following)
from window_test;
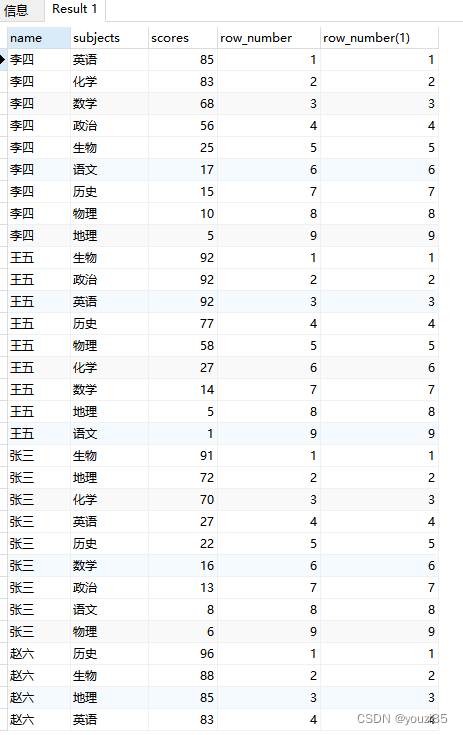
2. 分布函数:percent_rank() | cume_dist()
percent_rank():(rank - 1) / (总行数 - 1)
cume_dist():(前面的行数或与当前行相同的行数)/(总行数)
select name,subjects,scores,
percent_rank() over (partition by name order by scores desc),
cume_dist() over (partition by name order by scores desc)
from window_test;
结果显示如下图。percent_rank()函数是根据rank-1去计算的,所以从0开始计算,两个占比分布函数的第一个数据一个是0/8,一个是1/9计算,然后遇到相同排名的时候,因为rank是并列排名,并列排名后是间隔排名,所以排第四的科目排名直接是(4-1)/8。而cume_dist则是并列排名的比例都一样,然后计算前面的不同成绩的行数(这里是0)+当前相同成绩的行数(这里是3)然后计算排名,就是3/9。
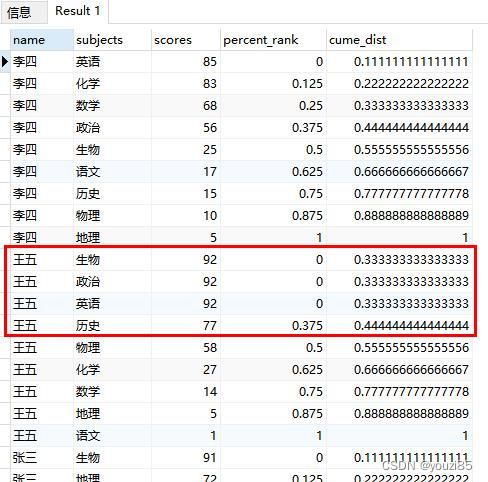
如果还是不太理解cume_dist(),我们再举个例子。
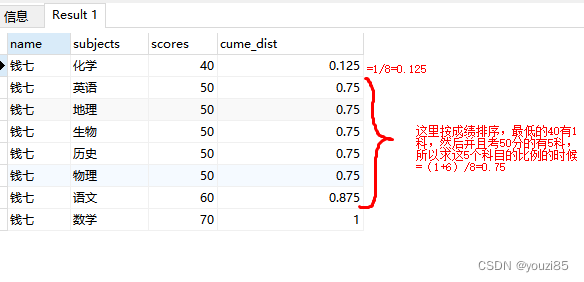
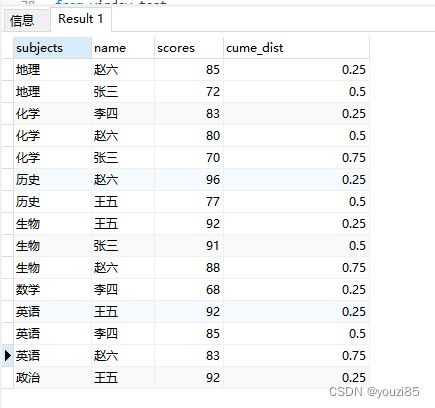
这个函数可以应用于求每个科目及格的同学情况及及格率占比。
select * from (
select subjects,name,scores,
cume_dist() over (partition by subjects order by scores desc)
from window_test
)a where scores>=60;
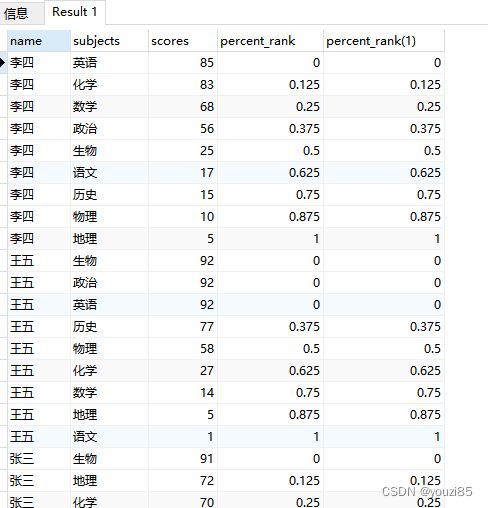
同理,这两个函数只存在静态窗口,滑动窗口使用无效,以percent_rank()为例子。
select name,subjects,scores,percent_rank() over (partition by name order by scores desc),
percent_rank() over (partition by name order by scores desc rows between 1 preceding and 1 following)
from window_test;
3. 前后函数:lag() | lead()
lag()和lead()表示计算当前行的前n行或后n行,n不写默认是1,如果设置default,则表示没有这样的行默认用default代替。
这两个函数利用计算当前行的前n行或后n行,可以用来处理类似连续登陆n天,或者登陆时间最大间隔天数等的问题。
以lag()为例,首先插入测试数据:
create table login_log(
id varchar(255),
log_time date
);
INSERT INTO login_log(id, log_time) VALUES ('101', '2022-02-14');
INSERT INTO login_log(id, log_time) VALUES ('101', '2022-02-15');
INSERT INTO login_log(id, log_time) VALUES ('102', '2022-02-15');
INSERT INTO login_log(id, log_time) VALUES ('101', '2022-02-16');
INSERT INTO login_log(id, log_time) VALUES ('101', '2022-02-17');
INSERT INTO login_log(id, log_time) VALUES ('101', '2022-02-18');
INSERT INTO login_log(id, log_time) VALUES ('101', '2022-02-19');
INSERT INTO login_log(id, log_time) VALUES ('101', '2022-02-20');
INSERT INTO login_log(id, log_time) VALUES ('101', '2022-02-21');
INSERT INTO login_log(id, log_time) VALUES ('101', '2022-02-22');
INSERT INTO login_log(id, log_time) VALUES ('102', '2022-02-23');
INSERT INTO login_log(id, log_time) VALUES ('102', '2022-02-24');
INSERT INTO login_log(id, log_time) VALUES ('103', '2022-02-14');
INSERT INTO login_log(id, log_time) VALUES ('103', '2022-02-15');
INSERT INTO login_log(id, log_time) VALUES ('103', '2022-02-16');
INSERT INTO login_log(id, log_time) VALUES ('103', '2022-02-18');
INSERT INTO login_log(id, log_time) VALUES ('103', '2022-02-19');
INSERT INTO login_log(id, log_time) VALUES ('103', '2022-02-20');
INSERT INTO login_log(id, log_time) VALUES ('103', '2022-02-21');
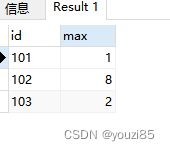
若是想要看看哪些用户连续登陆7天,sql如下:
select *,lag(log_time,6) over (partition by id order by log_time)
from login_log
得到的结果如下图:
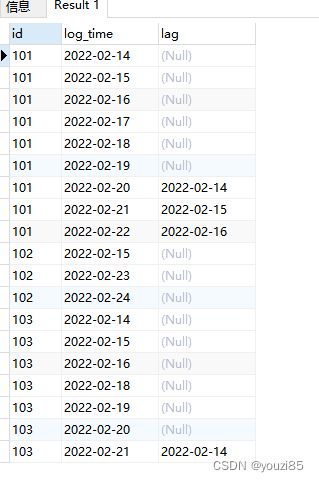
此时lag()函数将log_time下滑6行进行匹配,如果连续登陆的话,两个时间差之间的间隔应该是<=6的,以此来过滤出用户。
select id,log_time,lag from (
select *,lag(log_time,6) over (partition by id order by log_time)
from login_log
)a where log_time-lag<=6;

如上图,最后得到只有101用户是连续7天登陆的。
例如想知道用户登录最大不登录时间间隔,sql如下:
select id,max(log_time-lag) from (
select *,lag(log_time) over (partition by id order by log_time)
from login_log
)tmp group by id;
同样,这两个函数也只有静态窗口。
4. 其他函数:ntile() | nth_value()
- ntile()
ntile()函数表示将数据分成尽可能相等的分区,n传入多少就分成几组,若是n是1,则所有数据都在一组相当于没分区,若是n>=总的条数,那也不会报错,只是每条记录都是一组数据。
这个函数可以用来解决随机分组的问题,例如将班级中的学生随机分成2组。
select name,ntile(2) over (order by random())
from window_test
group by name
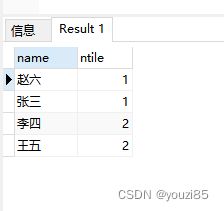
order by random():表示随机排序,也就是一个打乱的一个过程,这里不是必须的,可以删掉的
window_function() over ():over后面不加partition by的时候,表示不再分区,而是对整表进行操作。
2. nth_value()
返回窗口中排名第n行的计算值。这个函数可以使用于在显示每个科目考得前n名的成绩的同学。以每科考前2名成绩的同学为例:
select subjects,name,scores,nth_value(scores,2) over (partition by subjects order by scores desc)
from window_test
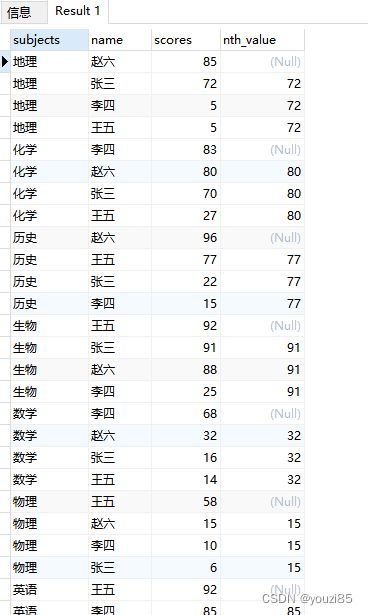
此时得到的结果如上图,这里因为是排名第2的值,所以在最高分的nth_value是null。基于这样的数据条件,想得到每个科目成绩前两名成绩的情况是,条件时nth_value是null,或者scores>=nth_value,综上,班级前2名成绩的sql如下:
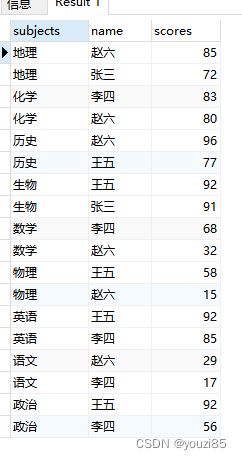
select subjects,name,scores from (
select subjects,name,scores,nth_value(scores,2) over (partition by subjects order by scores desc)
from window_test
)a where scores>=nth_value or nth_value is null
;
这个函数是可以使用滑动窗口的,当使用了滑动窗口,那和静态窗口得到的数据就会有所不同。
select subjects,name,scores,
nth_value(scores,1) over (partition by subjects order by scores desc),
nth_value(scores,1) over (partition by subjects order by scores desc rows between 1 preceding and 1 following)
from window_test
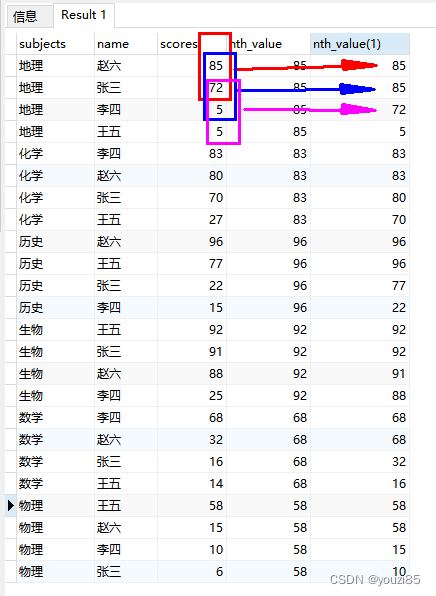
此时,所用的滑动窗口是将前一行,当前行,后一行的数据作为一个整体比较,取这三个数据中的第一个数据。
5. 头尾函数:first_value() | last_value()
其实first_value()和nth_value()当n=1的时候是一样的,但是对于不知道整体几行的时候,无法知道最后一行的行数的时候,可以使用last_value()。而且这两个函数也是可以使用滑动窗口。
select subjects,name,scores,
first_value(scores) over (partition by subjects ),
first_value(scores) over (partition by subjects rows between 1 preceding and 1 following),
last_value(scores) over (partition by subjects ),
last_value(scores) over (partition by subjects rows between 1 preceding and 1 following)
from window_test
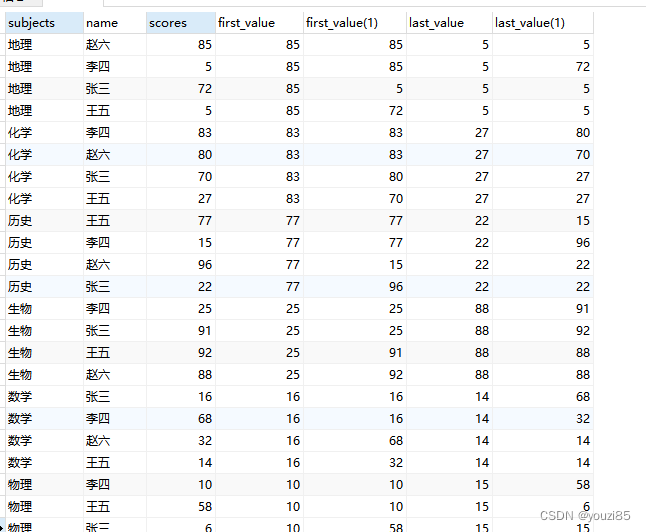
6. 聚合函数
聚合函数也可以配合使用窗口函数,以sum()函数为例,利用窗口函数求每个同学的成绩。
select name,subjects,scores,
sum(scores) over (partition by name),
sum(scores) over (partition by name order by subjects),
sum(scores) over (partition by name order by subjects rows between 1 preceding and 2 following)
from window_test;
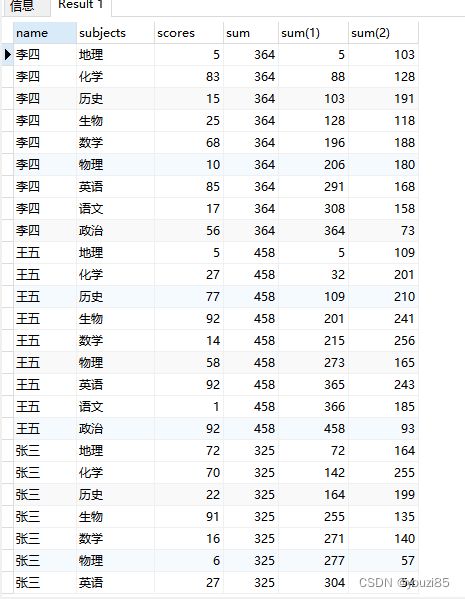
由上图可以看出,使用sum()对每个同学求总分,就能得到一列sum列来显示每个同学的总分,若是添加order by,则是根据科目实现成绩累加的sum1。函数若是配合使用滑动窗口,则是得到窗口内的总分和,此时的order by的累加功能已经失效了,其实和不写效果一样。
注意事项
- 窗口函数一定配有 over ()语句,若是不需要排序分组,对整表进行操作,可以不写里面的内容,只跟一个()即可。
- 如果查询包含窗口函数,并且查询使用任何的聚合、group by或者having,那么使用窗口函数的行是聚合得到的组的行,而不是从from/where 得到的原始表行。
- 窗口调用函数只能在select列,或者查询的order by子句中使用
- 当查询涉及多个窗口函数时,可以写成每一个都带有单独的OVER子句, 但是,如果期待为多个窗口函数采用相同的窗口行为,这样做就会产生重复,并且容易出错。 作为代替,每个窗口行为可以在WINDOW子句中进行命名,然后再被OVER引用,例如:
SELECT sum(salary) OVER w, avg(salary) OVER w
FROM empsalary
WINDOW w AS (PARTITION BY depname ORDER BY salary DESC);
- 当语法over子句和window子句部分内置部分在Windows子句时,语法注意内容可看:[窗口定义:内置使用 OVER 子句和 WINDOW 子句 ]
- window子句必须位于 select 语句的 order by 子句之前
其他参考文档内容:
http://postgres.cn/docs/9.3/tutorial-window.html
http://postgres.cn/docs/9.3/sql-expressions.html#SYNTAX-WINDOW-FUNCTIONS
好啦,本文到这里就结束了。
感谢您的阅读~