【论文笔记】【Faster Rcnn 优化】《Light-Head R-CNN: In Defense of Two-Stage Object Detector》

论文:https://arxiv.org/abs/1711.07264
代码: GitHub - zengarden/light_head_rcnn: Light-Head R-CNN
1.概述
我们一般将Object detection分为两大系列:
-
一类是two-stage detector:
-
代表算法有Faster RCNN, Mask RCNN等
-
算法分两阶段进行,第1阶段是生成proposals,第2阶段是对这些proposals进行分类、回归【精调】
-
-
另一类是one-stage detector:
-
代表算法有YOLO系列, SSD等
-
算法讲究一步到位,没有生成proposals这一过程
-
一般来说,two-stage系列的检测算法拥有更高的检测精度高,而singel-stage系列的算法则具备更快的检测速度。在实际工业应用【落地】中,算法的速度是我们一种重要的考虑因素,同时随着YOLO系列的算法逐步优化其精度也得到了改善,基本能够满足实际的需求,因此在实际应用中更多的可能还是one-stage系列的算法为主。
作者将论文取名为《守护二阶段物体检测器的尊严》,通过构造轻量级头部R-CNN网络,探讨了R-CNN如何在物体检测中平衡精确度和速度;
-
作者用Resnet-101作为base model,拿到了COCO-2017的冠军。
-
作者用轻量级的Xception作为base model,达到了30.7 mmAP,并且速度达到102FPS,从speed到accuracy都全面击败现有的single-stage的算法

2.为什么two-stage算法那么慢
“Head” in our paper refers to the structure attached to our backbone base network. More specifically, there will be two components: R-CNN subnet and ROI warping
也就是说Head主要包含两部分:
-
ROI warping:通过ROI Pooling/PSRoI Pooling等方式为每一个ROI生成大小固定的特征图
-
RCNN subnet:基于ROI的特征图进一步实现recognition过程,
two-satge算法由于头部的计算量很大,导致即使是轻量级的backbone网络,也并不会对速度有很大的提升。并以Faster R-CNN和R-FCN这两个two-stage算法为例进行了解释说明:

对于Faster-RCNN,导致效率低的原因主要有两个
-
为了保证精度,每一个ROI经过ROI Pooling处理后连接两个大FC层,这十分耗时;
-
第一个FC输入的channel往往很多【比如resnet101的输出就有2048个channel】,这样的计算量就很大了;
【注意:为了提速,通常RoI feature map后面会采用global average pool 而没有直接连接全连接层. 这样做的目的是为了减少第一个FC层的计算量,但是会丢失一些spatial localization的信息,不利于目标bbox回归】
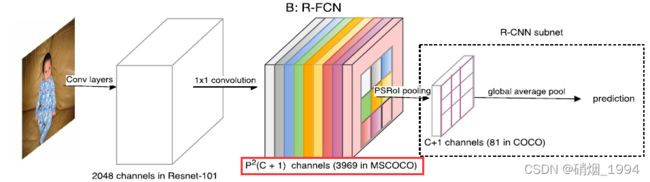
对于R-FCN,采用1x1的卷积核,得到Position-sensitive feature map, 每个RoI经过一个PSRoI Pooling层得到大小固定的feature map【p*p*(c+1),c为类别数】最后通过一个global average pool层得到每个RoI的prediction;相比于Faster-RCNN,PSRoI Pooling输出的通道数要小很多【c+1】,而且去掉了全连接层,因此速度要快一些;但是对于Position-sensitive feature map的channel数需要满足是P^2(C+1)
-
对于COCO数据集80个类别,相应的channel数是3969,这个开销就变得很大;
3.Light-Head R-CNN的优化

上图C为论文中改进后的网络结构,可以看出Light-Head R-CNN由Faster R-CNN和R-FCN改进而来,并结合了两者的一些优点;其改进点主要在以下三个方面:
3.1.Thin feature maps for RoI warping
-
在RoI warping之前先对特征图进行压缩,得到【薄】thin feature map,避免R-FCN中feature map太大,且随类别数C增加而增大的问题
-
其通道数由R-FCN的3969降低至490,计算量大大降低
-
-
在thin feature map后面接PSROI/ROI Pooling,此时得到的ROI-wise feature map也薄,这样后面再接FC层,计算量也就就小了,避免了Faster R-CNN在R-CNN subnet的第一个FC层计算量过大的问题
为了研究通道数更少的thin feature map对精度的影响,作者搭建了以下的网络结构进行实验。

和R-FCN相比,网络结构基本一致,其差别主要在以下两点【其它设置都相同】:
-
减少feature map channel,从3696(7*7*81)减少到490(7*7*10)
-
由于改变了feature map channel数,导致无法直接通过global average pool进行prediction,因此加了一个FC层
其实验结果如下:

其中B1表示的是原作者实现的R-FCN,B2表示的是Light-Head作者实现的R-FCN,并加入了一些tricks[更大的训练图片尺寸、平衡分类和回归的训练损失、修改anchor设置等],可以看出B2比B1提升了3个点。然后在B1/B2模型上改为thin feature map,可以发现:通道数的减少会导致精度的下降,但下降的幅度很小;
-
因为额外加入了一个FC层,所以也并不是只有通道数这一个变量,但模型结构基本一致,其实验结果还是具有一定的对比性
-
此外,由于thin feature map的引入使得feature pyramid network【FPN】的引入成为可能;对于RFCN原始实现来说,由于浅层的特征图的分辨率较高(Resnet stage 2),此时计算量和memory消耗都很大
3.2.Large separable convolution
参考R-FCN的方式,thin feature map的实现是通过1 × 1 convolution直接将通道压缩得到,因为这一层之前的feature map有2048 channel,这一层只有490 channel,这么多channel数的减少会减弱feature map的能力;为了弥补通道减少导致精度的损失,作者引入large seperable convolution,其结构如下图所示,其中kernel大小k=15,所以叫large conv,主要是为了保证通道的压缩不丢失太多精度;

-
此处为了进一步减少计算量,large seperable convolution的实现借鉴了Inception 3的思想,将大小为k*k的卷积核,用1*k和k*1的两层卷积来代替,可以在计算结果一致的前提下减少计算量;
-
计算复杂度跟Cmid和Cout的大小有关,论文中超参数设置为:Cmid = 256, Cout = 490.
实验结果:

-
得益于大kernel带来的更大valid receptive field,pooling后的feature maps具有更强的表达能力,带来了0.7的精度提升;
3.3.light RCNN-subnet
作者只使用了单个FC层(2048 channel)没有dropout,接着是两个全连接用来做classification 和regression;
-
对于每个bounding box只用4 channels,因为在不同类之间共享了regression
-
因为全连接层的上一层的feature map只有10*p*p,再加上只引入了一层全连接层,所以和原始faster rcnn相比,此处的计算量大大降低
实验结果:

- 得益于各种优化策略,Light Head R-CNN在速度和精度都取得了不错的效果;
4.实验
-
synchronized SGD with weight decay: 0.0001,momentum: 0.9.
-
Each mini-batch has 2 images per GPU.
-
Each image has 2000/1000 RoIs for training/testing.
-
Pad images within mini-batch to the same size by filling zeros into the right-bottomof the image.
-
Learning rate: 0.01 for first 1.5M iterations and 0.001 for later 0.5M iterations.
-
Adopt atrous algorithm in stage 5 of Resnet.
-
AdoptOHEM.
-
Backbone network is initialized based on thepre-trained ImageNet.
-
Pooling size: 7.
-
Batch normalization is also fixed for faster experiment.
-
Data augmentation: Horizontal image flipping.
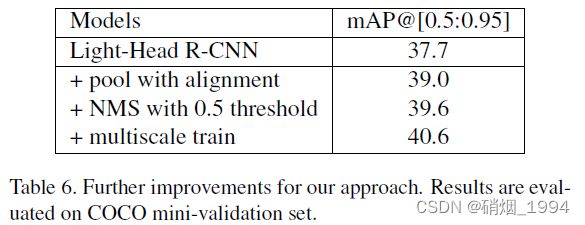
4.1.LightHead RCNN : High Accuracy【准】
-
在PSRoI pooling中加入RoIAlign (Mask-RCNN) 中的插值技术,提升了1.3个点
-
用0.5替换最初的0.3做NMS的阈值,提升了0.6个点【 提升了crowd情况的recall】
-
使用multi-scale进行training, 在训练的时候从{600, 700, 800, 900, 1000}中随机采样scale,提升1个点
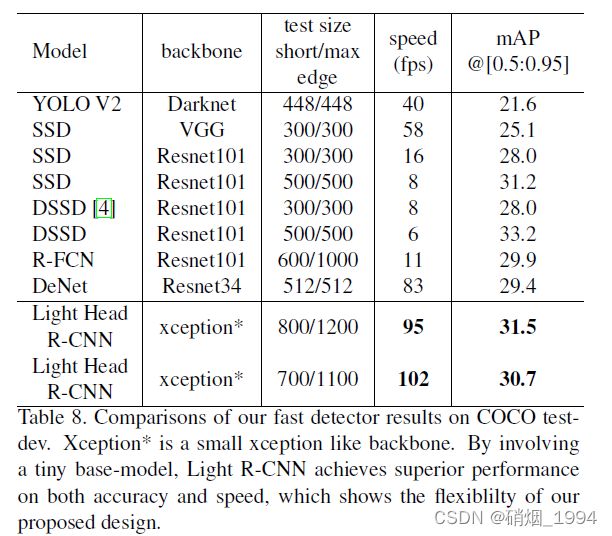
最终,在COCO test-dev数据集上,和其它常见的目标检测算法的性能对比如下:

4.2.LightHead RCNN : High Speed【快】
考虑到实际的落地,提高模型的推理速度,作者做了如下一些改变:
-
采用轻量级的Backbone Xception代替Resnet-101.
-
弃用atrous algorithm【对于小backbone来说有大的计算】
-
将RPN channel减少一半:512 - - >256.
-
改变Large separable convolution的设置: kernel size = 15, Cmid = 64, Cout = 490.
-
采用 PSPooling + RoI-align
采用上述trick之后,能够在COCO上达到102FPS的同时实现30.7%mmAP的精度,这样的性能可以说很香了!!!
5.结论:
-
采用轻量级的Backbone Xception代替Resnet-101.
-
Thin feature maps + Large separable convolution 保证精度的同时提升速度
-
使用单层FC代替 global average pooling
-
去掉最后的两层FC, 减少空间信息的丢失,提升精度
-
加入其他的tricks: PSRoI with RoIAlign、multi-scale training、OHEM