Context and Interception : The .NET Context
public class Context
{
public virtual int ContextID{get;}
//Other members
}
Every object can access the context object of the context it's executing by using the CurrentContext static read-only property of the Thread class:
public sealed class Thread
{
public static Context CurrentContext{ get; }
/* Other members */
}
For example, here is how an object can trace its context ID:
int contextID = Thread.CurrentContext.ContextID;
Trace.WriteLine("Context ID is " + contextID);
Note that threads can enter and exit contexts, and in general, they have no affinity to any particular context.
1. Assigning Objects to Contexts
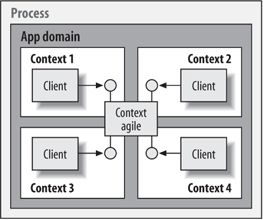
There are two kinds of .NET types: context-agile and context-bound. Both always execute in a context, and the main difference is in their affinity to that context. The context-agile behavior is the .NET default. Any class that doesn't derive from ContextBoundObject is context-agile. Context-agile objects have no interest in component services; they can execute in the contexts of their calling clients because .NET doesn't need to intercept incoming calls to them. When a client creates a context-agile object, the object executes in the context of its creating client. The client gets a direct reference to the object, and no proxies are involved. The client can pass the object reference to a different client in the same context or in a different context. When the other client uses the object, the object executes in the context of that client. The context-agile model is shown in Figure 1. Note that it's incorrect to state that a context-agile object has no context. It does have one—the context of the client making the call. If the context-agile object retrieves its context object and queries the value of the context ID, it gets the same context ID as its calling client.
Figure 1. A context-agile object
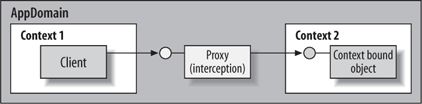
The picture is drastically different when it comes to context-bound objects. A context-bound object is bound to a particular context for life. The decision regarding which context the object resides in takes place when the object is created and is based on the services the object requires and the context of its creating client. If the creating client's context is "good enough" for the object's needs—i.e., the context has adequate properties, and the client and the object use a compatible set of component services—the object is placed in its creating client's context. If, on the other hand, the object requires some other service that the creating client's context doesn't support, .NET creates a new context and places the new object in it. Note that .NET doesn't try to find out if there is already another appropriate context for the object in that app domain. The algorithm is simple: the object either shares its creator's context or gets a new context. This algorithm intentionally trades memory and context-management overhead for speed in allocating the new object to a context. The other alternative would be to examine each of a potentially long list of existing contexts, but that search might take a long time to complete and impede performance. If the object is placed in a different context from that of its creating client, the client gets back from .NET a reference to a proxy instead of a direct reference (see Figure 2). The proxy intercepts the calls the client makes on the object and performs some pre- and post-call processing to provide the object with the services it requires.
Figure 2. Clients of a context-bound object access it via a proxy
|
2. The Call Interception Architecture
The cross-context interception architecture is similar to the one used across app domain boundaries. In .NET, the proxy has two parts: a transparent proxy and a real proxy. The transparent proxy exposes the same public entry points as the object. When the client calls the transparent proxy, it converts the stack frame to a message and passes the message to the real proxy. The message is an object implementing the IMessage interface:
public interface IMessage
{
IDictionary Properties{ get; }
}
The message is a collection of properties, such as the method's name and its arguments. The real proxy knows where the actual object resides. In the case of a call across app domains, the real proxy needs to serialize the message using a formatter and pass it to the channel. In the case of a cross-context call, the real proxy needs to apply interception steps before forwarding the call to the object. An elegant design solution allows .NET to use the same real proxy in both cases. The real proxy doesn't know about formatters, channels, or context interceptors; it simply passes the message to a message sink. A message sink is an object that implements the IMessageSink interface, defined in the System.Runtime.Remoting.Messaging namespace:
public interface IMessageSink
{
IMessageSink NextSink{ get; }
IMessageCtrl AsyncProcessMessage(IMessage msg,IMessageSink replySink);
IMessage SyncProcessMessage(IMessage msg);
}
.NET strings together message sinks in a linked list. Each message sink knows about the next sink in the list (you can also get the next sink via the NextSink property). The real proxy calls the SyncProcessMessage( ) method of the first sink, allowing it to process the message. After processing the message, the first sink calls SyncProcessMessage( ) on the next sink. In the case of cross-app domain calls, the first sink on the client's side is the message formatter . After formatting the message, the formatter sink passes it to the next sink—the transport channel. When the SyncProcessMessage( ) method returns to the proxy, it returns the returned message from the object.
|
2.1. Cross-context sinks
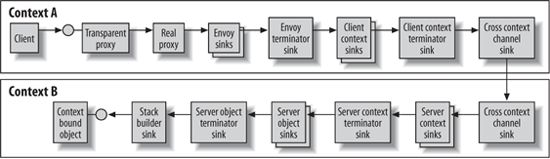
In the case of a cross-context call, there is no need for a formatter; .NET uses an internal channel called CrossContextChannel, which is also a message sink. However, there is a difference in component services configuration between the client and the object, and it's up to the sinks to compensate for these differences. .NET installs as many message sinks as required between the client's context and the object (see Figure 3).
Figure 3. A cross-context call to a context-bound object

The .NET context interception architecture is similar to the Decorator design pattern[*] and is a private case of aspect-oriented programming . A typical message sink does both pre- and post-call processing. The canonical example is again thread synchronization. The sink needs to acquire a lock before proceeding to call the object, and it must release the lock after the method returns. The next sink down the call chain may enforce security, and so on.
[*] See Design Patterns: Elements of Reusable Object-Oriented Software, by E. Gamma, R. Helm, R. Johnson, and J. Vlissides (Addison-Wesley).
It's best to use an example to demystify the way sinks work. Example 1 shows a generic sink implementation. The sink constructor accepts the next sink in the chain. When the SyncProcessMessage( ) method is called, the sink performs some pre-call processing and then calls SyncProcessMessage( ) on the next sink. The call advances down the sink chain until it reaches a stack-builder sink, the last sink. The stack builder converts the message to a stack frame and calls the object. When the call returns to the stack builder, it constructs a return message with the method results and returns that message to the sink that called it. That sink then does its post-call processing and returns control to the sink that called it, and so on. Eventually, the call returns to the generic sink. The generic sink now has a chance to examine the returned message and do some post-call processing before returning control to the sink that called it. The first sink in the chain returns control to the real proxy, providing it with the returned message from the object. The real proxy returns the message to the transparent proxy, which places it back on the calling client's stack.
Example 1. Generic implementation of a message sink
public class GenericSink : IMessageSink |
2.2. Message sink types
Call interception can take place in two places. First, sinks can intercept calls coming into the context and do some pre- and post-call processing, such as locking and unlocking a thread lock. Such sinks are called server-side sinks. Second, sinks can intercept calls going out of the context and do some pre- and post-call processing. Such sinks are called client-side sinks. For example, using a client-side sink, the Synchronization attribute can optionally track calls outside the synchronization domain and unlock locks to allow other threads access. This is done using a client-side sink. You will see later how to install sinks.
Server-side sinks intercepting all calls into the context are called server context sinks. Server-side sinks intercepting calls to a particular object are called server object sinks. The server is responsible for installing server-side sinks. Client-side sinks installed by the client are called client context sinks, and they affect all calls going out of the context. Client-side sinks installed by the object are called envoy sinks. An envoy sink intercepts calls only to the particular object with which it's associated. The last sink on the client's side and the first sink on the server's side are instances of the type CrossContextChannel. The resulting sink chain is comprised of segments, each of which is a different type of sink, as shown in Figure 4. Because there must be a stack builder at the end of the sink chain to convert messages, .NET installs a terminator at the end of each segment. A terminator is a sink of the segment's type; it does the final processing for that segment and forwards the message to the next segment. For example, the last message sink in the server context sink segment is called the ServerContextTerminatorSink. The terminators behave like true dead ends: if you call IMessageSink.NextSink on a terminator, you get back a null reference. The actual next sink (the first sink in the next segment) is a private member of the terminator. As a result, there is no way to iterate using IMessageSink.NextSink on the entire length of the interception chain.
|
3. Same-Context Calls
A context-bound object must always be accessed via a proxy across a context boundary, so that the various sinks can be in place to intercept the calls. The question now is, what happens if a client in the same context as the object passes a reference to the
Figure 4. Client-side and server-side sink chains
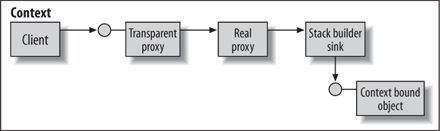
object to a client in a different context (for example, by setting the value of some static variable)? If the same-context client has a direct reference to the object, how can .NET detect that and introduce a proxy between the object and the new client? .NET solves the problem by always having the object accessed via a proxy, even by clients in the same context (see Figure 5). Because the client and the object share the same context, there is no need for message sinks to perform any pre- or post-call processing. The interception layer consists of the transparent and real proxy, and a single message sink—the stack builder. When the same-context client passes its reference to the transparent proxy to clients in other contexts, .NET detects that and sets up the correct interception chain between the new clients and the object.
Figure 5. Even in the same context, clients access a context-bound object using a proxy
|
4. Context-Bound Objects and Remoting
Context-bound objects are a special case of .NET remoting (in particular, of client-activated objects). In many respects .NET treats them just like remote objects, but it does optimize some elements of its remoting architecture for context-bound objects—for example, as mentioned previously, the channel used for cross-context calls is an optimized channel called CrossContextChannel. For truly remote client-activated objects, .NET creates a lease and manages the lifecycle of the object via the lease and its sponsors. However, because the client of a context-bound object shares with it the same app domain, .NET can still use garbage collection to manage the object's lifecycle. In fact, when .NET creates a context-bound object it still creates a lease for it, and the object can even override MarshalByRefObject.InitializeLifetimeService( ) and provide its own lease. However, the lease doesn't control the lifetime of the object.
| With truly remote objects, when the TCP or HTTP channels marshal a reference across a process boundary, these channels set up the lease. With cross-context or cross-app domain objects, the CrossContextChannel and CrossAppDomainChannel channels ignore the lease and let the remote objects be managed via garbage collection. |
Read more at http://mscerts.programming4.us/programming/context%20and%20interception%20%20%20the%20_net%20context.aspx#vFt2rUtbPjB0Hw7M.99