[文学阅读] METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments
METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments
Satanjeev Banerjee Alon Lavie
Language Technologies Institute
Carnegie Mellon University
Pittsburgh, PA 15213
[email protected] [email protected]
Important Snippets:
1. In order to be both effective and useful, an automatic metric for MT evaluation has to satisfy several basic criteria. The primary and most intuitive requirement is that the metric have very high correlation with quantified human notions of MT quality. Furthermore, a good metric should be as sensitive as possible to differences in MT quality between different systems, and between different versions of the same system. The metric should be
consistent (same MT system on similar texts should produce similar scores), reliable (MT systems that score similarly can be trusted to perform similarly) and general (applicable to different MT tasks in a wide range of domains and scenarios). Needless to say, satisfying all of the above criteria is extremely difficult, and all of the metrics that have been proposed so far fall short of adequately addressing most if not all of these requirements.
2. It is based on an explicit word-to-word matching between the MT output being evaluated and one or more reference translations. Our current matching supports not only matching between words that are identical in the two strings being compared, but can also match words that are simple morphological variants of each other
3. Each possible matching is scored based on a combination of several features. These currently include uni-gram-precision, uni-gram-recall, and a direct measure of how out-of-order the words of the MT output are with respect to the reference.
4.Furthermore, our results demonstrated that recall plays a more important role than precision in obtaining high-levels of correlation with human judgments.
5.BLEU does not take recall into account directly.
6.BLEU does not use recall because the notion of recall is unclear when matching simultaneously against a set of reference translations (rather than a single reference). To compensate for recall, BLEU uses a Brevity Penalty, which penalizes translations for being “too short”.
7.BLEU and NIST suffer from several weaknesses:
>The Lack of Recall
>Use of Higher Order N-grams
>Lack of Explicit Word-matching Between Translation and Reference
>Use of Geometric Averaging of N-grams
8.METEOR was designed to explicitly address the weaknesses in BLEU identified above. It evaluates a translation by computing a score based on explicit word-to-word matches between the translation and a reference translation. If more than one reference translation is available, the given translation is scored against each reference independently, and the best score is reported.
9.Given a pair of translations to be compared (a system translation and a reference translation), METEOR creates an alignment between the two strings. We define an alignment as a mapping be-tween unigrams, such that every unigram in each string maps to zero or one unigram in the other string, and to no unigrams in the same string.
10.This alignment is incrementally produced through a series of stages, each stage consisting of two distinct phases.
11.In the first phase an external module lists all the possible unigram mappings between the two strings.
12.Different modules map unigrams based on different criteria. The “exact” module maps two unigrams if they are exactly the same (e.g. “computers” maps to “computers” but not “computer”). The “porter stem” module maps two unigrams if they are the same after they are stemmed using the Porter stemmer (e.g.: “com-puters” maps to both “computers” and to “com-puter”). The “WN synonymy” module maps two unigrams if they are synonyms of each other.
13.In the second phase of each stage, the largest subset of these unigram mappings is selected such
that the resulting set constitutes an alignment as defined above
14. METEOR selects that set that has the least number of unigram mapping crosses.
15.By default the first stage uses the “exact” mapping module, the second the “porter stem” module and the third the “WN synonymy” module.
16. unigram precision (P)
unigram recall (R)
Fmean by combining the precision and recall via a harmonic-mean
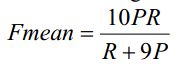
To take into account longer matches, METEOR computes a penalty for a given alignment as follows.
chunks such that the uni-grams in each chunk are in adjacent positions in the system translation, and are also mapped to uni-grams that are in adjacent positions in the reference translation.

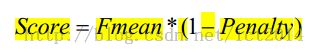
Conclusion: METEOR prefer recall to precision while BLEU is converse.Meanwhile, it incorporates many information.
版权声明:本文博客原创文章,博客,未经同意,不得转载。