redis持久化,主从及数据备份
http://blog.csdn.net/lang_man_xing/article/details/38386113
现在在项目里已经大量使用redis了,为了提高redis的性能和可靠性我们需要知道和做到以下几件事:
常用内存优化手段与参数
redis的性能如何是完全依赖于内存的,所以我们需要知道如何来控制和节省内存。
首先最重要的一点是不要开启Redis的VM选项,即虚拟内存功能,这个本来是作为Redis存储超出物理内存数据的一种数据在内存与磁盘换入换出的一个持久化策略,但是其内存管理成本非常的高,所以要关闭VM功能,请检查你的redis.conf文件中 vm-enabled 为 no。
其次最好设置下redis.conf中的maxmemory选项,该选项是告诉Redis当使用了多少物理内存后就开始拒绝后续的写入请求,该参数能很好的保护好你的Redis不会因为使用了过多的物理内存而导致swap,最终严重影响性能甚至崩溃。
另外Redis为不同数据类型分别提供了一组参数来控制内存使用,我们知道Redis Hash是value内部为一个HashMap,如果该Map的成员数比较少,则会采用类似一维线性的紧凑格式来存储该Map, 即省去了大量指针的内存开销,这个参数控制对应在redis.conf配置文件中下面2项:
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
含义是当value这个Map内部不超过多少个成员时会采用线性紧凑格式存储,默认是64,即value内部有64个以下的成员就是使用线性紧凑存储,超过该值自动转成真正的HashMap。
hash-max-zipmap-value 含义是当 value这个Map内部的每个成员值长度不超过多少字节就会采用线性紧凑存储来节省空间。
以上2个条件任意一个条件超过设置值都会转换成真正的HashMap,也就不会再节省内存了,那么这个值是不是设置的越大越好呢,答案当然是否定的,HashMap的优势就是查找和操作的时间复杂度都是O(1)的,而放弃Hash采用一维存储则是O(n)的时间复杂度,如果成员数量很少,则影响不大,否则会严重影响性能,所以要权衡好这个值的设置,总体上还是最根本的时间成本和空间成本上的权衡。
同样类似的参数还有:
list-max-ziplist-entries 512
说明:list数据类型多少节点以下会采用去指针的紧凑存储格式。
list-max-ziplist-value 64
说明:list数据类型节点值大小小于多少字节会采用紧凑存储格式。
set-max-intset-entries 512
说明:set数据类型内部数据如果全部是数值型,且包含多少节点以下会采用紧凑格式存储。
Redis内部实现没有对内存分配方面做过多的优化,在一定程度上会存在内存碎片,不过大多数情况下这个不会成为Redis的性能瓶颈,不过如果在Redis内部存储的大部分数据是数值型的话,Redis内部采用了一个shared integer的方式来省去分配内存的开销,即在系统启动时先分配一个从1~n 那么多个数值对象放在一个池子中,如果存储的数据恰好是这个数值范围内的数据,则直接从池子里取出该对象,并且通过引用计数的方式来共享,这样在系统存储了大量数值下,也能一定程度上节省内存并且提高性能,这个参数值n的设置需要修改源代码中的一行宏定义REDIS_SHARED_INTEGERS,该值默认是10000,可以根据自己的需要进行修改,修改后重新编译就可以了。
持久化
redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中的数据同步到磁盘来保证持久化。redis支持两种持久化方式,一种是 Snapshotting(快照)也是默认方式,另一种是Append-only file(缩写aof)的方式。
snapshotting
快照是默认的持久化方式。这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。可以通过配置设置自动做快照持久化的方式。我们可以配置redis在n秒内如果超过m个key被修改就自动做快照,下面是默认的快照保存配置:
- save 900 1 #900秒内如果超过1个key被修改,则发起快照保存
- save 300 10 #300秒内容如超过10个key被修改,则发起快照保存
- save 60 10000 #60秒内容如超过10000个key被修改,则发起快照保存
也可以命令行的方式让redis进行snapshotting:
- redis-cli -h ip -p port bgsave
保存快照有save和bgsave两个命令,save操作是在主线程中保存快照的,由于redis是用一个主线程来处理所有 client的请求,这种方式会阻塞所有client请求,所以不推荐使用。
快照生成过程大致如下:
- redis调用fork,现在有了子进程和父进程;
- 父进程继续处理client请求,子进程负责将内存内容写入到临时文件。由于os的写时复制机制(copy on write)父子进程会共享相同的物理页面,当父进程处理写请求时os会为父进程要修改的页面创建副本,而不是写共享的页面。所以子进程的地址空间内的数据是fork时刻整个数据库的一个快照;
- 当子进程将快照写入临时文件完毕后,用临时文件替换原来的快照文件,然后子进程退出。
同时snapshotting也有不足的,因为两次快照操作之间是有时间间隔的,一旦数据库出现问题,那么快照文件中保存的数据并不是全新的,从上次快照文件生成到Redis停机这段时间的数据全部丢掉了。如果业务对数据准确性要求极高的话,就得采用aof持久化机制了。
aof
aof 比快照方式有更好的持久化性,是由于在使用aof持久化方式时,redis会将每一个收到的写命令都通过write函数追加到文件中(默认是 appendonly.aof)。当redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。当然由于os会在内核中缓存 write做的修改,所以可能不是立即写到磁盘上。这样aof方式的持久化也还是有可能会丢失部分修改。不过我们可以通过配置文件告诉redis我们想要通过fsync函数强制os写入到磁盘的时机。有三种方式如下(默认是:每秒fsync一次):
- appendonly yes //启用aof持久化方式
- # appendfsync always //每次收到写命令就立即强制写入磁盘,最慢的,但是保证完全的持久化,不推荐使用
- appendfsync everysec //每秒钟强制写入磁盘一次,在性能和持久化方面做了很好的折中,推荐
- # appendfsync no //完全依赖os,性能最好,持久化没保证
aof 的方式也同时带来了另一个问题。持久化文件会变的越来越大。例如我们调用incr test命令100次,文件中必须保存全部的100条命令,其实有99条都是多余的。因为要恢复数据库的状态其实文件中保存一条set test 100就够了。为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。收到此命令redis将使用与快照类似的方式将内存中的数据 以命令的方式保存到临时文件中,最后替换原来的文件。bgrewriteaof命令如下:
- redis-cli -h ip -p port bgrewriteaof
bgrewriteaof命令执行过程如下:
- redis调用fork ,现在有父子两个进程;
- 子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令;
- 父进程继续处理client请求,除了把写命令写入到原来的aof文件中。同时把收到的写命令缓存起来。这样就能保证如果子进程重写失败的话并不会出问题;
- 当子进程把快照内容写入以命令方式写到临时文件中后,子进程发信号通知父进程。然后父进程把缓存的写命令也写入到临时文件;
- 现在父进程可以使用临时文件替换老的aof文件,并重命名,后面收到的写命令也开始往新的aof文件中追加。
这两种持久化方式有各自的特点,快照相对性能影响不大,但一旦崩溃,数据量丢失较大,而aof数据安全性较高,但性能影响较大,这就得根据业务特点自行选择了。
主从复制
redis的主从复制策略是通过其持久化的rdb文件来实现的,其过程是先dump出rdb文件,将rdb文件全量传输给slave,然后再将dump后的操作实时同步到slave中。
要使用主从功能需要在slave端进行简单的配置:
- slaveof master_ip master_port #如果这台机器是台redis slave,可以打开这个设置。
- slave-serve-stale-data no #如果slave 无法与master 同步,设置成slave不可读,方便监控脚本发现问题。
配置好之后启动slave端就可以进行主从复制了,主从复制的过程大致如下:
- Slave端在配置文件中添加了slaveof指令,于是Slave启动时读取配置文件,初始状态为REDIS_REPL_CONNECT;
- Slave端在定时任务serverCron(Redis内部的定时器触发事件)中连接Master,发送sync命令,然后阻塞等待master发送回其内存快照文件(最新版的Redis已经不需要让Slave阻塞);
- Master端收到sync命令简单判断是否有正在进行的内存快照子进程,没有则立即开始内存快照,有则等待其结束,当快照完成后会将该文件发送给Slave端;
- Slave端接收Master发来的内存快照文件,保存到本地,待接收完成后,清空内存表,重新读取Master发来的内存快照文件,重建整个内存表数据结构,并最终状态置位为 REDIS_REPL_CONNECTED状态,Slave状态机流转完成;
- Master端在发送快照文件过程中,接收的任何会改变数据集的命令都会暂时先保存在Slave网络连接的发送缓存队列里(list数据结构),待快照完成后,依次发给Slave,之后收到的命令相同处理,并将状态置位为 REDIS_REPL_ONLINE。
整个复制过程完成,流程如下图所示: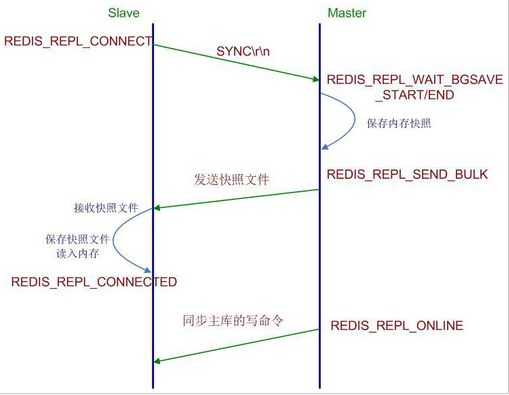
从以上的复制过程中可以发现,Slave从库在连接Master主库时,Master会进行内存快照,然后把整个快照文件发给Slave,也就是没有象MySQL那样有复制位置的概念,即无增量复制,如果一个master连接多个slave,就会比较影响master性能了。
数据备份策略
具体的备份策略是可以很灵活的,比如可以大致如下:
- 为了提高master的性能关闭master的持久化机制,即不进行快照也不进行aof,而是在凌晨访问量低的时候定时的用bgsave命令进行快照,并将快照文件保存到备份服务器上;
- slave端开启aof机制,并定时的用bgrewriteaof 进行数据压缩,将压缩后的数据文件保存到备份服务器上;
- 定时的检查master与slave上的数据是否一致;
- 当master出问题并需要恢复时,如果采用master的备份快照恢复直接将备份的dump.rdb拷贝到相应路径下重启即可;如果要从slave端恢复,需要在slave端执行一次快照,然后将快照文件拷贝到master路径下然后重启即可。不过有一点需要注意的是,master重启时slave端数据会被冲掉,所以slave端要在master重启前做好备份。
持久化磁盘IO方式及其带来的问题
有Redis线上运维经验的人会发现Redis在物理内存使用比较多,但还没有超过实际物理内存总容量时就会发生不稳定甚至崩溃的问题,有人认为是基于快照方式持久化的fork系统调用造成内存占用加倍而导致的,这种观点是不准确的,因为fork 调用的copy-on-write机制是基于操作系统页这个单位的,也就是只有有写入的脏页会被复制,但是一般的系统不会在短时间内所有的页都发生了写入而导致复制,那么是什么原因导致Redis崩溃的呢?
答案是Redis的持久化使用了Buffer IO造成的,所谓Buffer IO是指Redis对持久化文件的写入和读取操作都会使用物理内存的Page Cache,而大多数数据库系统会使用Direct IO来绕过这层Page Cache并自行维护一个数据的Cache,而当Redis的持久化文件过大(尤其是快照文件),并对其进行读写时,磁盘文件中的数据都会被加载到物理内存中作为操作系统对该文件的一层Cache,而这层Cache的数据与Redis内存中管理的数据实际是重复存储的,虽然内核在物理内存紧张时会做Page Cache的剔除工作,但内核可能认为某块Page Cache更重要,而让你的进程开始Swap,这时你的系统就会开始出现不稳定或者崩溃了。经验是当你的Redis物理内存使用超过内存总容量的3/5时就会开始比较危险了。
如果服务器crash,从上一次快照之后的数据将全部丢失。所以在设置保存规则的时候,要根据实际业务设置允许的范围。