weighing scheme
选以简单的介绍开始,因为以后的文章可能会提到这里面的一些概念,事先写好,也算练练手。
传统重量一个单词大小的方法是测量它在文章中的重要性以及考虑它在文章的特征。
(1)TF-IDF(term frequency,inverse document frequency)
Salton等人[1]提出了TF-IDF,这种方法用来衡量一个术语在整个语料库中的权重。术语在语料库中的重要性会随着它在一个文本中出现的频率的增加而增大,但是与它在整个语料库中出现频率成反比。
在衡量一个术语的权重时,如果仅凭术语在文章中出现的次数的话,显然文章长度大的中的术语会比文章长度小的相同术语权重会高,所以我们应该做一些归一化,即作TF处理。极端一点如果一个术语只在一篇文章中出现过,那这个术语就可以唯一确定这篇文章,这个术语的权重很高,而对于出现在多篇文章中的术语则相对难确定某一文章。因此,应增加前者的权重并减少后者的权重,即作IDF处理。
TFIDFi,j = ( Ni,j / N*,j ) * log( D / Di )
其中Ni,j 是单词i出现在文章j中的次数,N*,j 是文章j中总的单词数,D是文章总数目,Di 是出现单词i的文章数。
(2)TF-PDF(term frequency,proportional document frequency)
Bun等人[2]提出了一个不同的术语权重衡量机制,TF-PDF。Bun 越是出现在多个文章中的单词被认为是热门主题单词的可能性越大,但是传统的TF-IDF则更加看重出现在较少文章中的单词。有如下公式:
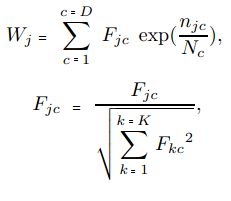
其中Wj代表单词j的权重,Fjc在渠道c中单词j的频率,njc为渠道c中出现单词j的文章的个数,Nc为渠道c中文章的总数目,k为中单词的总数,D为渠道的个数。(我们认为文章是从多个渠道中得得来的,如不同的新闻网站渠道)
此方案由三部分组成。一是单词的权重是由单词在每个渠道中权重的积累。第二个是下面公式中的规范化的Fj,因为不同的渠道会有不同大小的词汇集,具体较多文章的渠道中的单词会有较大的出现频率。三是,公式中的exp(njc/Nc),即(PDF),这意味着如果一个单词出现在的文章多,那么它就更有价值,权重越大。
[1]Salton G., Buckley C. "Term-Weighting Approaches in Automatic Text Retrieval," Information Processing and Management, Vol 4, No. 5, pp.513- 523,1989.
[2]Khoo Khyou Bun,Ishizuka, M., "Topic extraction from news archive using TF*PDF algorithm," Proceedings of the Third International Conference on Web Information Systems Engineering,2002,pp.73 - 82 ,2002.