把《c++ primer》读薄(1-2前言+变量和基本类型)
督促读书,总结精华,提炼笔记,抛砖引玉,有不合适的地方,欢迎留言指正。
一:大小端的概念
Big-Endian和Little-Endian(见计算机存储的大小端模式解析)
二:浮点数的机器级表示
三:c++的基本的内置类型:
1)算术类型,又包括:
整型(包括:整数int、short、long int类型,单个字符(分为存储单个机器字节的char类型,1个字节,char有三种不同的类型,普通char,unsigned char和signed char,一共两个表达方式unsigned char和signed char。和存储汉字和日语等的扩展字符集的wchar_t类型,2个字节),布尔值0,1)。
整型又分为无符号和有符号的(除bool类型之外)
在选用整数类型的时候,一定先分析好大概范围,一些机器int和long int一样,如果贸然总使用范围很大的类型,则额外代价较高,总用范围娇小的,又容易溢出。
浮点型,float,double,long double。一般用double就足够了,且很多经典书籍都建议使用double,少用long doouble,因为一没必要那么高精度,二运行起来代价额外很大。
2)还有一种void ,空类型。
问题1:在输出汉字字符串的时候会乱码,一般解决方案是字符串前面加L,why?
这是在说明字符串的字面值是宽字符wchar_t, L"大家好!" 这样表示就可以了。因为编译器有时候默认使用unicode字符集,不加L显示的日文或者韩文,L代表宽字符
问题2:针对模的问题
unsigned char chr = 255; printf("%u\n", chr);//255 unsigned char chr1 = 256; printf("%u\n", chr1);//1 //在c++或者c,这样的赋值是能被接受的 //超出范围的数值%取值范围,unsigned char是0-255,就是336模256之后的值再赋值chr2 unsigned char chr2 = 336; printf("%u\n", chr2);//80 //-1显然已经超出了范围,但是-1%256应该还是-1的,这里打印255,是因为-1是负数,而我们打印的是无符号数 //编译器就认为-1的补码1111 1111,是无符号数的补码,打印出来那就是255 unsigned char chr3 = -1; printf("%u\n", chr3);//255 //同理,-1模无符号int取值范围之后还是-1,且-1的32位补码16进制是0xffff ffff,编译器认为是无符号的数的补码,那就是32位无符号int类型的最大值4294967295 unsigned int in = -1; printf("%u\n", in);//4294967295 //相对的,使用%d打印就是-1,因为编译器认为这是带符号数的补码 printf("%d\n", in);//-1 int in1 = -1; printf("%d\n", in1);//-1 unsigned int in = 4294967296; printf("%u\n", in);//0
4294967296模4294967296就是0
//%运算符只能用于整数相除求余,运算结果的符号与被除数相同,绝对不能用于实数。
//被除数=商 x 除数 + 余数
//余数的绝对值一定小于除数的绝对值
printf("%d", 5 % 3);//2 printf("\n%d", 3 % 5);//3 printf("\n%d", 3 % -5);//3,3=0 * -5 + 3 printf("\n%d", -3 % 5);//-3,-3=0 * 5 + -3 //一定要思路清晰,脑子里有数学的概念就行 printf("\n%d", 5 % -3);//2,5=-1 * -3 + 2
问题3:没有short类型的字面值常量
字面值常量比如:
有无符号int类型111u,有默认带符号的int类型111,有long int类型111L,有无符号long int类型111LU或者111UL,有默认的double类型,1.1,有单精度类型1.1F,有扩展精度类型1.1L,有true,false的bool字面值,有字符和字符串类型的字面值。就是没有short int类型字面值!
问题4:多行字面值的表示
cout << "aaaaaaaaa" "ddddddd" << endl;//ok cout << "aaaaaaaaaaaa" "bbbbbbbbbbbbbb" << endl;//ok cout << "aaaaaaaa\ bbbbbbbbbbb" << endl;//ok //cout << "aaaaaaaaaaaa // bbbbbbbbbb" << endl;//error
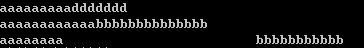
针对第三行代码,\ 虽然可以实现多行字面值字符串的输出输入,但是有局限,\ 必须在本行末尾,后面不能有注释和其他字符,且后续行bbbb前面的空,都算作了字符串字面值的一部分,故出现如图第三行所示的情况,解决办法:
cout << "aaaaaaaa\ bbbbbbbbbbb" << endl;
问题5:程序尽量的不要过多的依赖机器
比如,int在win32下是一个长度,也许换个机器就不一样了,如果有,最好是在依赖处都有说明,否则程序移植起来很困难。
问题6:c和c++的变量为什么要先声明还要定义名字,使用前为什么还必须先定义变量或者常量的类型?
c/c++是静态类型的语言(编译时做类型检测),对程序的操作是否合法都是在编译期间检测,故编译器必须能够识别程序内每个实体,对于不是关键字的且没有呗引号括起来的符号,对于c/c++编译器来说,它是不认识的,如何让编译器知道这个单词是什么意思呢?
所以就有了声明(declare)。编译器每次开始工作,不知道有哪些变量,不知道有哪些函数,也不知道有哪些符号常量,它不是人!如从代码里读了一个单词,既不是关键字,又不是自己认识的东西,编译器就认为这是一个没有声明的东西,因为不认识它,所以不知道如何处理。所以“声明”,就是告诉编译器有这么一个东西。声明的时候主要做四件事:
一是建立变量符号表
声明变量,编译器可以建立变量符号表,如此,程序用到多少变量,每个变量类型是什么,编译器非常清楚,是否使用了没有声明的变量,编译器在编译期间就可以发现,从而帮助了程序员远离由于疏忽而将变量名写错的情况。
二是变量的数据类型指示系统分配多少内存空间
数据类型指示系统如何解释存储空间中的值。同样的数值,不同的类型将有不同的解释。32位机器,一般情况下,int占4个字节,float占4个字节,在内存中同样存储二进制数,且这个二进制数也没有标志区分当前是int还是float型,那么如何区分?就是通过变量的数据类型来区分。由于声明建立了变量符号表,所以系统知道变量存储空间该如何解释。
三是变量的数据类型确定了该变量的取值范围
例如短整型short的数据取值-32768~32767之间。
四是不同的数据类型有不同的操作
比如,模运算,不能用于浮点数。如下:
printf("%d", 5 % 2);// 1 printf("%d", 5.0 % 2);// error printf("%d", 10.0);// %d对应解析带符号10进制整数,实数解析会失败,结果为0。这种陷阱题,基础题,经验题往往确定一个人的水平 printf("%d", (int)10.0);//使用强制类型转换,ok! printf("%f", 1);//因为%f对应解析实数,如果是整数,转化失败就是0.000000,同样可以强制类型转换改正。
问题7:理解初始化和赋值是两个完全不同的概念
c++支持两种初始化方式,复制初始化(使用=),和直接初始化(常用于构造函数的初始化列表),且使用直接初始化,语法更灵活,效率更高(对内置类型没什么区别),专家推荐多用!
double d = 1.0;//ok,复制初始化 double dd(1.11);//ok,直接初始化,想起了构造函数的初始化列表
初始化:创建新的变量,并给变量赋一个初始值的过程。
赋值:变量早在前面声明过,且有了初始值,此时再给它一个新值(把前面的值擦掉)的过程。
string boy("dadadadadafwe"), girl = " ";//ok,混搭没问题! int a , b = 10, c, d = 100;//ok char chr = 'a', chr1('0');//ok
注意
//int a = a;//error,提示变量a没有呗初始化就使用!但是一些编译器就不会报错,建议不要这样写。 //string str1 = str2("dadafa");//error,要分开,分别初始化 //double a = b = c = 1.0;//error,同样要分别分开初始化! string str1 ="da", str2(" "); double a = 0.0, b = 0.1, c = 0.2;
问题8:关于自动初始化
在函数外定义的变量自动初始化为0,函数内就不会自动初始化,且对于c和c++的基本内置类型,最好定义的同时就初始化,即使当下没用。
#include <iostream> #include <string> using namespace std; string str1;//空字符串 int a;//0 double d;//0 float f;//0 char c;//空字符 int main(void) { string str;//ok,string对象创建,自动调用string类的默认构造函数,进行初始化 cout << str << endl;//str自动初始化为空字符串 cout << a << endl;//0 cout << str1 << endl;//空 cout << d << endl;//0 cout << f << endl;//0 cout << c << endl;//空 return 0; }
针对c++,还需要考虑类的构造函数
问题9:变量定义和声明的区别
因为c和c++经常是多文件开发,故有了声明和定义
变量的定义是为了给变量分配内存,指定初始值,一个变量只能有一个定义存在。
声明变量,是告诉程序变量的类型和名称
即定义也是声明,因为定义变量的同时,也声明了变量的名字和类型,一个变量可以有多次声明,但是定义只有一次!因为声明仅仅指定名称和类型,不分配内存!
通常用关键字extern专门进行变量的声明,而不定义。告诉本文件,这个变量已经定义在了其他文件。俗称外链接。
extern double d;//仅仅是变量的声明 extern double d;//同一个变量,可以被声明多次! double d = 0.0;//变量的声明,同时包含了定义 //double d;变量仅仅只能被定义一次 int main(void) { return 0; }
同样,声明也可以变为定义,如果声明有初始化,那么就变为定义,针对extern语句仅仅在函数外部(拥有文件作用域范围),才可以变为定义,否则出错!
#include <iostream> #include <string> using namespace std; extern int a = 1;//声明变为了定义 //int a;“int a”: 重定义 int main(void) { //extern int a = 1;//在函数内部,这样不对 //“a”: 不能对带有块范围的外部变量进行初始化,想实现声明变定义,那么必须给extern的变量 文件作用域范围,也就是写在函数外部,使得a成为一个全局变量 return 0; }
回忆,多文件开发,都是在一个文件进行变量的定义,而其他文件使用这些变量就仅仅需要包含这些变量的声明 即可,无需(也不可以)重定义。
再看:
int sum = 0; for (int i = 0; i != 10; i++) { sum += i; } cout << i << endl;//error,因为i的作用域在for循环体内有效,for外部没有定义变量i,故报错! //“i”: 未声明的标识符
问题10;避免硬编码
int sum = 0; /*for (int i = 0; i < 512; i++) { sum += i; }判断语句的512就是硬编码,如果程序很大,那么可读性就很差(无法从上下文获得512的含义),且如果类似的for语句很多,一旦需求变化,那么想改就不那么容易了! 应该多多用const对象*/ const int j = 512; for (int i = 0; i < j; i++) { // }
这样做,如果常量定义出错,或者被无心的修改,那么可以被编译器立马检测出来!程序健壮性提高!因为常量定义后不能被修改,故常量定义的同时必须马上初始化!
问题11:引用初步探讨
int a = 1024; double d = 0.1, dd = 0.2, ddd = 2.2; int &ref = a;//ok double &refd(d);//ok double &refd1 = dd, &refd2 = ddd;//ok
多个方法定义多个引用没问题,记住:引用就是外号而已!不占新的内存空间,和原数值共享内存空间。
注意,引用必须初始化!因为引用必需要绑定到一个实体对象!故不能是引用的引用。也不能不初始化!
int &ref1; //error C2530:“ref1”: 必须初始化引用 int i = 1024; int &refint = i;//ok int &refint1 = i;//ok,可以给一个对象,起多个外号 int &refint2 = refint;//ok int &&refint3 = i;//error C2440: “初始化”: 无法从“int”转换为“int &&” 无法将左值绑定到右值引用
引用一旦绑定一个对象,不能再绑定其他对象
double d = 1.0; double dd = 1.1; double &refd = d; double &refd = dd;// error C2374: “refd”: 重定义;多次初始化
引用要注意字面值常量的绑定问题
int &ref2 = 1024; // error C2440: “初始化”: 无法从“int”转换为“int &” //因为1024是字面值常量,而ref2是普通引用,ref2是一个变量,又常量不能被修改,故用变量绑定肯定报错! //修改 const int &ref2 = 1024;//ok
同理,const常量必须用const引用来绑定!
//const常量必须用const引用来绑定! const char c = 'a'; //char &refc = c; error C2440: “初始化”: 无法从“const char”转换为“char &” 转换丢失限定符 const char &refc = c;//ok
注意引用和不同类型变量的绑定问题
//把引用绑定到不同类型的对象 int i = 512; //double &refi = i; //error C2440: “初始化”: 无法从“int”转换为“double &” //使用const引用就对了 const double &refi = i;
原因:对于不同类型的引用绑定过程,编译器内部做了这样的优化,先针对int类型的i = 512,自动生成一个double类型的临时变量
double temp = 512;
再让double引用去绑定temp,而不是我们看到的直接绑定int i=512;
double &refi = temp;
故这里有一个问题,现在refi是非const类型,那么说明可以对refi也就是i修改,但是事实上,我们修改只是修改了temp,不会对原值i修改,这违背了引用的初衷,故这样是定义为不合法的行为。同理,使用const引用就ok了,因为仅仅是使用i的值,并不修改,这样是完全合法的。
问题12:尽量多用枚举定义常量
//c++的枚举类型可以省略美剧名字,也可以加上名字,枚举本身就是常量表达式!不能修改它的成员!
enum {}; //勿忘; //枚举默认第一个变量赋值为0,以后的依次+1,如果有初始值,则按照初始值,以后依次+1 enum e{ a, b, c }; //a =0,b =1, c=2
//使用枚举定义de 常量,是真正的常量!不受限于类的对象!且有很好的可读性!含义的聚集性!
比如在类中定义const成员,我们不能在类里初始化,必须创建对象的时候,构造函数初始化。看似是常量,但是针对的只是某一个对象,其他对象的话,仍然可以去初始化属于自己的那一份const成员。并不是真正的constant!而枚举就无所谓这个问题。
enum ee{ aa = 1, bb, cc }; //bb = 2, cc =3 enum eee{ aaa = 1, bbb, ccc = 4, ddd }; //bbb = 2, ddd = 5
//枚举是一种类型!可以定义枚举类型的对象,同理也可以给枚举类型的对象赋值。赋值,必须是这个枚举类型的成员,或者是同一枚举类型的其他的枚举对象!
eee e1;//ok,定义枚举类型的对象e1 //eee e2 = 1;//error,赋值过程错误,应该是本枚举类型的成员 //eee e0 = aa;//error, 赋值错误,应该是同类型的枚举对象,aa是属于ee这个枚举的 //修改 eee e2 = aaa; eee e3 = e2;
问题13:c++也支持结构类型
区别就是c++的结构里,可以有函数,且默认的成员访问属性是public,而class是private。
问题14:回答问题,类A里的private成员int a;都是谁能直接去访问?
千万不能忘记友元!当然还有类A内部的组成部分也可以直接访问。
问题15:规范化的头文件
头文件不应该含有变量或者函数的定义!只能有声明!但是头文件也有例外,那就是头文件可以定义类,头文件可以定义编译时就知道具体值的const对象,可以定义inline函数。
问题16:什么是常量表达式?
编译器在编译的时候,就能够计算得出表达式的明确结果的表达式!表达式由常量表示:
double a = sizeof(double);
两个关键点:一是必须是编译的时候就能计算出明确结果的表达式,二是表达式组成部分都必须是常量,不能包含变量,比如1+2是常量表达式,整型字面值常量就是常量表达式,枚举常量也是常量表达式!如果定义a为常量1,那么a+2也是常量表达式。如果定义变量a,那么a+2就不是常量表达式。
问题17:解答前面const对象默认在函数外部定义,为什么是局部作用域?(需显式的加extern才是全局的,不同于一般变量)
15说了,头文件只能有声明,但是const常量的定义却可以,因为c++里,const常量在函数外部定义的话,c++规定为局部变量(本文件可见,而本文件外的本程序其他文件不可见),故不会造成重定义现象。
注意更深层次的原因:
如果const对象使用常量表达式初始化,那么该变量(变为常量的变量,仅仅说的是这个变量,不是常量表达式本身!)不会被分配内存空间,因为绝大部分的编译器编译时,都直接使用的相应的常量表达式来替换掉该const变量,这需要理解!所以,如果const对象在头文件内的函数外部没有被常量表达式初始化,那么就不应该定义在头文件,应该和其他变量一样定义在源文件并初始化。然后在头文件添加extern声明即可被共享。比如:
const double d = squt(2.11);//一个函数计算的返回值初始化d,此时编译的时候无法确定squt(2.11)的返回值!必须等到执行期间 //所以,d不是被常量表达式初始化的,那么这个语句应该放到源文件!而不是头文件
这里具体意思应该是说,头文件的const,一方面,定义在了函数外部,是局部作用域,局部的那就是互不影响!另一方面,就是大部分const变量都是用常量表达式初始化!上面说了,编译器不会为这样的const变量分配内存,而是使用对应的常量表达式替换该变量名!等价于,声明!那么这里有一个名词叫:
常量折叠
至今没有找到一些权威的论证,网上的各个论坛博客,都说的有一定的道理,但是具体细节又各有不同的争论,还没有什么权威的说法,具体涉及到了编译原理的知识。
再说说c语言里的const常量
《c primer plus》一书清晰的说到:c语音里的const定义的常量,不被看为常量,而是只读变量!《c和指针》一书也说到,c中const定义的常量,仅仅能用在应该使用变量的地方,比如设置数组维数,使用const定义的常量就报错!当然这是c99之前。如今c99也支持了这一做法!如下:
const int const_m = 10;//在c语言(不同于c++)里,const值不被看作是常量 int n = 100;//定义了变量 double d1[10];// ok double d2[5 * 2 + 1];//ok double d3[];//error,没有初始化,也没有大小指定 double d4[sizeof(int)];//ok,sizeof表达式在c里被认为返回一个整数常量 double d5[-10];//error C2118: 负下标 double d6[0];//error C2466: 不能分配常量大小为 0 的数组 double d7[3.14];// error C2058: 常量表达式不是整型 double d8[(int)3.14];//ok double d9[const_m];// error C2057: 应输入常量表达式,“d9”未知的大小 double d10[n];//error C2057: 应输入常量表达式,“d9”未知的大小
c99之后,后两种方式可以了,并且创建了一种新数组VLA(variable length array)变长数组。目的是为了让c更适合做数值计算。
总之,记住,在c里要看编译器支持的标准。在c++里,当const变量是常量表达式初始化的,那么写在头文件,如果不是,最好写到各自需要的源文件,在其他文件,使用extern关键字声明以下,即可共享。
当然不写也不算错,只是规范的编程习惯。
问题18:给头文件设置头文件保护符,避免重定义,也就是多重包含
#ifndef XXXXX_H//一般是大写,避免名字冲突 //该预处理指示的作用是检测 指定的预处理器变量 是否没定义 //if not define的缩写,如果没有定义,那么其后的所有指示都被执行一次,截至到#endif //如果该预处理器变量已经被定义了,那么就不再执行其后的语句,避免了重复包含和重定义。 #define XXXXX_H//该指示的作用是接受一个名字,并定义 该名字为 预处理器变量 //…… //…… #endif//结束指示