Python3.6+Selenium自动化
一、安装与配置
1、安装Python3.6。
2、安装 pip install selenium。
2、安装对应浏览器版本的ChromeDriver驱动。可以将chromedriver.exe放到我们的项目目录中。
二、运行流程

三、准备工作
1、为了验证各种功能、情况,需要自己写一个HTML页面用于调试,HTML代码可在此链接https://blog.csdn.net/l15767016983/article/details/122998171找到。
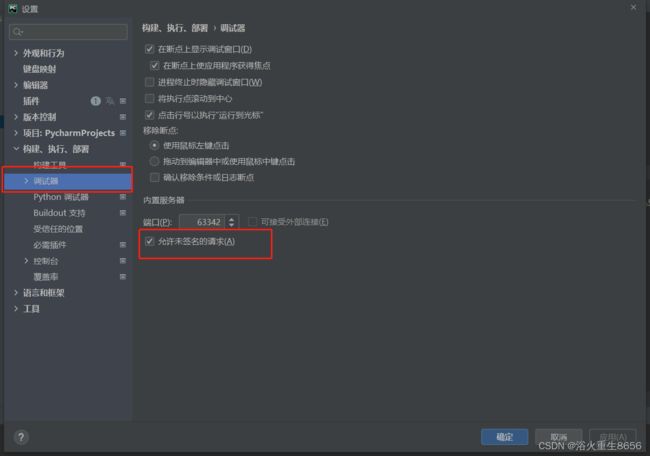
driver.get(net_url)获取一个localhost地址需要在pycharm设置勾选一下“允许未签名的请求”。
四、简单使用
1、启动浏览器
from selenium import webdriver
if __name__ == '__main__':
option = webdriver.ChromeOptions()
# option.add_argument("--headless")#无界面运行
option.add_argument("--start-maximized")#最大化运行
driver = webdriver.Chrome(executable_path="chromedriver", options=option)
net_url = 'http://localhost:63342/PycharmProjects/html_test/html_t.html?_ijt=7q5u4fs2ir2t0p9agurlv4hhht'
driver.get(net_url)2、常用的启动项
| 启动参数 | 作用 |
| window-size=长,宽 | 设置浏览器分辨率 |
| headless | 无界面运行 |
| start-maximized | 最大化运行 |
更多的详细参数解释: List of Chromium Command Line Switches « Peter Beverloo
3、selenium 定位元素一共有八种方法。需要导入from selenium.webdriver.common.by import By
(1)find_element(By.ID, "div_id")#通过元素ID找元素,ID唯一。
div_id=driver.find_element(By.ID, "div_id")#通过ID找元素
print(div_id)(2)find_elements(By.CLASS_NAME, "div_class") # 通过CLASS_NAME找元素,不唯一。
div_class=driver.find_elements(By.CLASS_NAME, "div_class") # 通过CLASS_NAME找元素,CLASS_NAME不唯一
print(div_class)(3)find_elements(By.CSS_SELECTOR, "div[title*=div]")# 通过CSS_SELECTOR找元素,快速语法简洁,功能强大,但不唯一。
# div_class=driver.find_element(By.CSS_SELECTOR, ".div_class") #选中class="div_class"的元素
# div_id=driver.find_element(By.CSS_SELECTOR, "#div_id") #选中id="div_id"的元素
# all=driver.find_elements(By.CSS_SELECTOR, "*") #选中所有元素
# p=driver.find_elements(By.CSS_SELECTOR, "p") #选中所有p标签
# div_p=driver.find_elements(By.CSS_SELECTOR, "div,p") #选中所有div和p标签
# div_p=driver.find_elements(By.CSS_SELECTOR, "div p") #选中所有div里面的p标签
# div_p=driver.find_elements(By.CSS_SELECTOR, "div>p") #选中父元素为div的所有p标签
# target=driver.find_elements(By.CSS_SELECTOR, "[target]") #选中带有target属性的所有标签
# target=driver.find_elements(By.CSS_SELECTOR, "[target=_blank]") #选中带有属性target=_blank的所有标签
# div_title=driver.find_elements(By.CSS_SELECTOR, "[title^=div]") #选中带有属性title以div开头的所有标签
# div_title=driver.find_elements(By.CSS_SELECTOR, "[title$=title]") #选中带有属性title以title结尾的所有标签
# div_title=driver.find_elements(By.CSS_SELECTOR, "div[title^=div]") #选中带有属性title以div开头的所有div标签
div_title=driver.find_elements(By.CSS_SELECTOR, "div[title*=div]") #选中带有属性title包含div的所有div标签
print(div_title,len(div_title))
(4)find_elements(By.LINK_TEXT, "a链接标签") # 通过LINK_TEXT找元素,不唯一且需要全匹配。
link_text=driver.find_elements(By.LINK_TEXT, "a链接标签") # 通过LINK_TEXT找元素,LINK_TEXT不唯一且需要全匹配
print(link_text)(5)find_elements(By.PARTIAL_LINK_TEXT, "a链接") # 通过PARTIAL_LINK_TEXT找元素,不唯一,部分匹配。
link_text=driver.find_elements(By.PARTIAL_LINK_TEXT, "a链接") # 通过PARTIAL_LINK_TEXT找元素,不唯一,部分匹配
print(link_text)(6)find_elements(By.TAG_NAME, "div") # 通过TAG_NAME找元素,不唯一。
div=driver.find_elements(By.TAG_NAME, "div") # 通过TAG_NAME找元素,不唯一。
print(div)(7)driver.find_elements(By.NAME, "iframe_name") # 通过NAME找元素,不唯一。
iframe_name=driver.find_elements(By.NAME, "iframe_name") # 通过TAG_NAME找元素,不唯一。
print(iframe_name)(8)driver.find_elements(By.XPATH, "") # 通过XPATH找元素,不唯一。
# div=driver.find_elements(By.XPATH, "/html/body/a") #以/开始的为绝对路径 匹配body里面的所有的子元素a标签,不包括孙元素a标签
# div=driver.find_elements(By.XPATH, "/html/body/*") #匹配body里面的所有的子元素,不包括孙元素
# div=driver.find_elements(By.XPATH, "/html/body//*") #匹配body里面的所有的子孙元素
# div=driver.find_elements(By.XPATH, "/html/body/a|/html/body/b") #匹配body里面的所有的子元素a或标签
# div=driver.find_elements(By.XPATH, "/html/body//a") #匹配body里面的所有的子孙元素a标签
# div=driver.find_element(By.XPATH, "/html/body/a[1]") #匹配body里面的第一个子孙元素a标签,下标从1开始
# div=driver.find_elements(By.XPATH, "//*") #以//开始的为相对路径 匹配所有元素
# div=driver.find_elements(By.XPATH, "//a") #匹配所有位置的a标签
# div=driver.find_elements(By.XPATH, "//*[@class='div_class']") #匹配所有位置属性为class值为div_class的标签
# div=driver.find_elements(By.XPATH, "//*[@class='div_class' and @title='div_title']") #匹配所有位置属性为class值为div_class 而且属性为title值为div_title的标签
# div=driver.find_elements(By.XPATH, "//div[@class='div_class']") #匹配所有div标签属性为class值为div_class的标签
# div=driver.find_elements(By.XPATH, "//div[text()='div块标签']") #匹配所有div标签文本text()值为"div块标签"的标签
# div=driver.find_elements(By.XPATH, "//div[contains(@class,'div_')]") #匹配所有div的属性class包含div_的标签
# div=driver.find_elements(By.XPATH,"//div[@class='list']//div[contains(@class,'content')]") #先找到所有div的属性classlist的标签 然后匹配其子孙元素下面所有的div的属性class包含content的标签
# div=driver.find_elements(By.XPATH,"//span[contains(text(),'content')]")#匹配所有div的文本内容包含content的标签
# div=driver.find_elements(By.XPATH, "/html/body/child::*") #匹配body里面的所有的子元素标签
# div=driver.find_elements(By.XPATH, "//p/parent::*") #匹配所有p标签的父标签
# div=driver.find_elements(By.XPATH, "//p/following-sibling::*") #匹配所有p标签之后的兄弟节点
# div=driver.find_elements(By.XPATH, "//p/preceding-sibling::*") #匹配所有p标签之前的兄弟节点 4、driver常用方法、属性
(1)get(url): 访问url地址。
(2)ChromeOptions():设置启动项。
(3)close(): 关闭当前标签页。
(4)quit(): 关闭浏览器。
(5)refresh(): 刷新当前页面。
(6)page_source: 获取当前页渲染后的源代码。
print(driver.page_source)(7)current_url: 获取当前页面的url。
print(driver.current_url)(8)switch_to.frame(iframe):切换到iframe页面,不然定位不到iframe页面里面的元素。
iframe=driver.find_element(By.ID, "iframe_id")
driver.switch_to.frame(iframe)#切换到iframe
iframe_div_id=driver.find_element(By.ID, "iframe_div_id")
print(iframe_div_id,iframe_div_id.text)(9)switch_to.default_content()#从iframe切回到主页面。
driver.switch_to.default_content()#切回到主页面(10)execute_script("alert('alert弹窗')")#执行JS代码。
driver.execute_script("alert('alert弹窗')") 5、元素常用的方法、属性
(1)clear(): 清空对象中的内容。
driver.find_element(By.ID, "div_id").clear()(2)click(): 单击对象。
driver.find_element(By.ID, "div_id").click()(3)get_attribute("attribute"): 返回该属性名的值,如果不存在,则返回None。
print(driver.find_element(By.ID, "div_id").get_attribute("class"))
print(driver.find_element(By.ID, "div_id").get_attribute("id"))
print(driver.find_element(By.ID, "div_id").get_attribute("title"))
print(driver.find_element(By.ID, "div_id").get_attribute("style"))(4)send_keys(value): 给对象元素输入数据。
driver.find_element(By.CSS_SELECTOR, "[name=firstname]").send_keys("hello")
(5)text: 获取当前元素的文本内容。
print(driver.find_element(By.ID, "div_id").text)(6)driver.execute_script("arguments[0].scrollIntoView();", textarea_id)#滚动页面到textarea_id元素可见。
textarea_id=driver.find_element(By.ID, "textarea_id")
driver.execute_script("arguments[0].scrollIntoView();", textarea_id)#滚动页面到textarea_id可见(7)Keys类,模拟键盘按键,需要导入from selenium.webdriver.common.keys import Keys。
driver.find_element(By.CSS_SELECTOR, "[name=firstname]").send_keys(Keys.SHIFT,"a")
(8)ActionChains()动作链,需要导入from selenium.webdriver.common.action_chains import ActionChains。
调用ActionChains()方法时,不会立即执行,而是将该操作按顺序存放在队列里,当调用perform()方法时,队列中操作就会依次执行。
ActionChains()支持鼠标的所有操作,包括单击、双击、点击鼠标右键、拖拽等等。
action=ActionChains(driver)#创建动作链
action.move_to_element(textarea_id)#移动到textarea_id元素上
action.click(textarea_id)#点击textarea_id元素
action.send_keys_to_element(textarea_id,"hello world")#给textarea_id传入文本内容
# action.context_click()#点击鼠标右键
action.send_keys_to_element(textarea_id,Keys.CONTROL,"a")
action.send_keys_to_element(textarea_id,Keys.SHIFT,"a")
action.perform()#执行链中的所有动作6、selenium等待方式
(1)time.sleep() 强制等待,需要导入time模块。
time.sleep()(2)implicitly_wait(time) 隐式等待,最多等待time毫秒直到元素出现,默认值为0。
为了调试需要写一个js,需要3秒后出现目标元素。
implicitly_wait(5) 等待5秒直到目标元素出现,不然就抛出异常。
driver.implicitly_wait(5)
div_id_id=driver.find_element(By.ID, "div_id_id")
print(div_id_id.text)(3)WebDriverWait(driver, timeout, poll_frequency) 显式等待。
WebDriverWait(driver, timeout, poll_frequency).until(method, message) 。直到某种条件成立才继续执行。timeout为超时时间,poll_frequency为间隔查询时间,method为方法,message为超时的错误提示信息。
①例如查询ID为div_id_id的元素是否出现。其中 lambda my_driver: driver.find_element(By.ID, "div_id_id")为可调用的方法,可以用 lambda 快速创建一个函数。超时找不到则提示“找不到div_id_id”。
WebDriverWait(driver, 5, 0.5).until(lambda my_driver: driver.find_element(By.ID, "div_id_id"),message="找不到div_id_id")#是否出现目标元素
②例如使用 Expected Conditions 方法判断是否满足某种条件。需要导入from selenium.webdriver.support import expected_conditions库。 expected_conditions库包含有很多判断方法。为了调试需要JS在6秒后改变元素属性以满足需求。
# lambda 定义函数是否出现目标元素
# WebDriverWait(driver, 5, 0.5).until(lambda my_driver: driver.find_element(By.ID, "div_id_id"),message="找不到div_id_id")
# 判断HTML的标题title_contains("title")是否包含"title"。
# WebDriverWait(driver, 6, 0.5).until(expected_conditions.title_contains("title"),message="错误提示信息")
# 判断HTML的标题title_is("title")是否为"title"。
# WebDriverWait(driver, 6, 0.5).until(expected_conditions.title_is("title变更"),message="错误提示信息")
#判断元素是否可点击
# WebDriverWait(driver, 6, 0.5).until(expected_conditions.element_to_be_clickable((By.ID, "button_id")))
# 判断元素是否出现,不一定可见
# WebDriverWait(driver, 6, 0.5).until(expected_conditions.presence_of_element_located((By.ID, "div_id_id")))
# 判断元素是否出现,且可见
# WebDriverWait(driver, 6, 0.5).until(expected_conditions.visibility_of_element_located((By.ID, "div_id_id")))
注意:presence_of_element_located() 函数传入的参数是locator,locator=(By.ID, "button_id"),而不是元素。
WebDriverWait(driver, timeout, poll_frequency).until_not(method, message) ,参数与until一致。直到某种条件从成立变成不成立时才继续执行,前提是条件要先成立,不然没效果。
WebDriverWait(driver, 6, 0.5).until_not(expected_conditions.element_to_be_clickable((By.ID, "button_id2")))
7、pageLoadStrategy页面加载策略
driver.get(url) 获取页面资源时,当前页面的加载状态 document.readyState 有三个值:正在加载loading、可交互 interactive、完成 complete。默认情况下,在 complete 状态之前,WebDriver都将延迟 driver.get() 的响应或 driver.navigate().to()的调用。意思就是如果获取的URL页面有大量图片、js、css的时候,需要等待全部加载完成才能进行下一步。
可以设置pageLoadStrategy加载策略,满足特定条件就进行下一步节省时间。WebDriver有三种页面加载策略:即pageLoadStrategy有三种取值。(1)normal:默认值,等待整个页面的加载,WebDriver保持等待,直到返回load事件。(2)eager:WebDriver保持等待,直到完全加载并解析了HTML文档,该策略无关 css 、图片和 js 的加载。(3)none:WebDriver仅等待至初始页面下载完成。
设置方法一:
option = webdriver.ChromeOptions()
option.set_capability("pageLoadStrategy", "eager")
设置方法二:
options = webdriver.FirefoxOptions()
webdriver.DesiredCapabilities.FIREFOX['pageLoadStrategy'] = 'normal'注:方法二好像设置不了Chrome浏览器的 pageLoadStrategy,需要用方法一。
8、遇到的问题
(1)Message: element click intercepted:元素点击被拦截。原因在于目标元素被其他元素覆盖,或者目标元素不在当前显示页面,需要滑动到该元素。
解决办法:第一种可以用js代码直接点击元素:broswer.execute_script("arguments[0].click();", element),其中arguments[0]就是传入的element元素,等同于element.click()。
第二种方法可以用ActionChains()类:ActionChains(broswer).move_to_element(element).click(element).perform()。先移动焦点到element元素然后点击。此方法在无界面运行时可能会出现 [object HTMLXXXXElement] has no size and location问题,建议使用第一种方法。
(2)Message: element not interactable:元素不可点击。原因在于需要移动焦点到该元素然后才能点击。
解决办法:第一种可以用js代码直接点击元素:broswer.execute_script("arguments[0].click();", element),其中arguments[0]就是传入的element元素,等同于element.click()。第二种方法可以用ActionChains()类:ActionChains(broswer).move_to_element(element).click(element).perform()。先移动焦点到element元素然后点击。此方法在无界面运行时可能会出现 [object HTMLXXXXElement] has no size and location问题,建议使用第一种方法。
(3)Message: stale element reference: element is not attached to the page document。所引用的元素已过时,不再依附于当前页面。出现这种情况是因为当前页面进行了刷新或跳转或翻页,定位不到目标元素了。
解决方法:重新定位目标元素。
(4)Message: element not interactable。元素不可交互。出现这种情况是因为点击速度过快,页面没有加载完目标元素或者目标元素被遮挡。
解决方法:等待目标元素出现再操作。或者用ActionChains让目标元素显示再操作。
9、selenium 上传本地文件
selenium驱动浏览器上传本地文件时需要与文件资源管理器进行交互,例如点击页面的 "上传文件" 后会弹出文件资源管理器选择文件,选中文件点击打开后会直接调用上传文件接口直接上传文件。
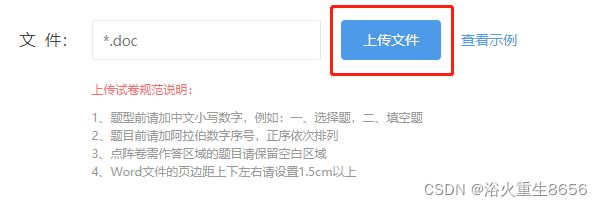
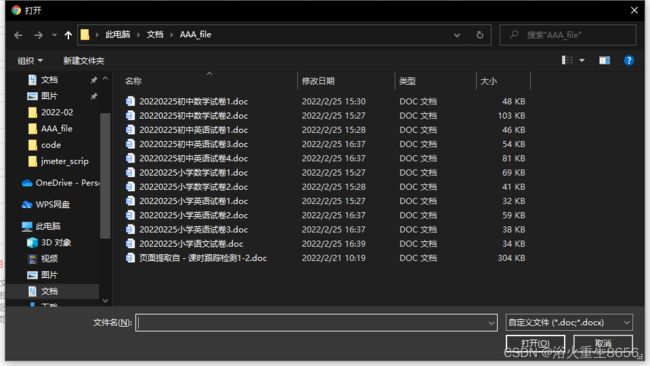
这种方式selenium是无法操作资源管理器的。这就需要借助第三方工具 pywin32 库。直接 pip install pywin32 就可以了。具体操作如下:
方法一:点击打开文件资源管理器选择文件时,光标的焦点会在文件路径输入框里,这样就可以用 pywin32 库操作键盘,将文件地址粘贴到输入框且点击enter键,这样就可以操作上传文件了。如果想获取操作更多的文件可以用 os库的 os.listdir(dir) 获取指定目录下的文件 ,遍历或者随机上传文件。
win32api .keybd_event(bVk, bScan, dwFlags, dwExtraInfo),bVk为虚拟键码, bScan为硬件扫描码,一般设置为0即可,dwFlags为标志位, 0 表示该键被按下,KEYEVENTF_KEYUP 表示该按键被释放, dwExtraInfo为与按键相关的附加的32位值,一般设置为0即可。
常用的虚拟键码如下:
VK_CODE = {'backspace': 0x08,
'tab': 0x09,
'enter': 0x0D,
'shift': 0x10,
'ctrl': 0x11,
'alt': 0x12,
'esc': 0x1B,
'page_up': 0x21,'page_down': 0x22,
'end': 0x23,'home': 0x24,
'left_arrow': 0x25,'up_arrow': 0x26,'right_arrow': 0x27,'down_arrow': 0x28,
'del': 0x2E,
'0': 0x30,'1': 0x31,'2': 0x32,'3': 0x33,'4': 0x34,'5': 0x35,'6': 0x36,'7': 0x37,'8': 0x38,'9': 0x39,
'a': 0x41,'c': 0x43,'v': 0x56,'x': 0x58,'z': 0x5A,
'F5': 0x74,'F11': 0x7A,'F12': 0x7B}Python代码片段:
path=r"C:\Users\Lenovo\Documents\AAA_file"
file_list=os.listdir(path)#获取AAA_file目录下的所有文件
file_path=path+"\\"+file_list[random.randint(0,len(file_list))]#随机一份文件 拼接文件路径
#复制内容到剪切板
win32clipboard.OpenClipboard()
win32clipboard.EmptyClipboard()
win32clipboard.SetClipboardText(file_path)
win32clipboard.CloseClipboard()
# 按下Ctrl+V键
win32api.keybd_event(0x11, 0,0, 0)#ctrl键被按下
win32api.keybd_event(0x56, 0,0, 0)#V键被按下
win32api.keybd_event(0x56, 0, win32con.KEYEVENTF_KEYUP, 0)#V键被释放
win32api.keybd_event(0x11, 0, win32con.KEYEVENTF_KEYUP, 0)#ctrl键被释放
# 按下enter键
win32api.keybd_event(0x0D, 0,0, 0)#enter键被按下
win32api.keybd_event(0x0D, 0, win32con.KEYEVENTF_KEYUP, 0)#enter键被释放
方法二:借助第三方工具 pywin32 库直接操作资源管理器。点击打开文件资源管理器选择文件时,文件资源管理器的句柄为#32770,然后利用 win32api.mouse_event点击具体的坐标点实现选择文件。这种方法比较死板,只能点击坐标点。pywin32 库是个很强大的API,有时间可以研究一下,实现点击元素。
hwnd = win32gui.FindWindow("#32770", None) # 根据窗口类名获取窗口句柄
# win32gui.SetForegroundWindow(hwnd)#根据句柄置顶窗口
rect = win32gui.GetWindowRect(hwnd) # 获取当前窗口位置
win32api.SetCursorPos((rect[0] + 85, rect[1] + 200)) # 设置鼠标在文档位置
time.sleep(1)
win32api.mouse_event(win32con.MOUSEEVENTF_LEFTDOWN | win32con.MOUSEEVENTF_LEFTUP, 0, 0, 0, 0) # 鼠标左键一行单击两行双击
win32api.SetCursorPos((rect[0] + 560, rect[1] + 144)) # 设置鼠标在目录位置
time.sleep(1)
win32api.mouse_event(win32con.MOUSEEVENTF_LEFTDOWN | win32con.MOUSEEVENTF_LEFTUP, 0, 0, 0, 0) # 鼠标左键一行单击两行双击
win32api.mouse_event(win32con.MOUSEEVENTF_LEFTDOWN | win32con.MOUSEEVENTF_LEFTUP, 0, 0, 0, 0) # 鼠标左键一行单击两行双击