【卷积神经网络】Lesson 4--人脸识别和风格转换
课程来源:吴恩达 深度学习课程 《卷积神经网络》
笔记整理:王小草
时间:2018年6月12日
1. 人脸识别
1.1 什么是人脸识别
人脸识别大家都不陌生,最常见的例子就是上班打卡,不再是刷卡,而是朝着屏幕刷一下脸,门就开了。
先来看一看人脸验证(face verification)和人脸识别的区别(face recognition)有什么区别呢?
face verification:
输入一张图片,以及这张图片对应的任务姓名或者工号
输出的是验证输入的这张图片是否是对应姓名或工号的那个人。
face recognition:
数据库里存好了K个人的照片
输入一张图片
如果这张图片在K个人中出现,则输出姓名或工号
以个问题有难度是因为要解决“一次学习(one-shot learning)”的问题
1.2 one-shot学习
one-shot learning的意思是,在绝大多数人脸识别应用中,你需要通过单单一张图片就去识别这个人,但深度学习只有一个样例的时候,它的表现并不好。
来来来,让我们用一个例子来说明,并讨论如何解决这个问题~
假设现在数据库里用公司的4个员工的图片:

现在门口来了一个人,并由摄像机传输进她的一张照片:

要一次性就识别出这人其实就是二号小姐姐,是公司的员工,给她自动开门。
又来了一个人:

又要识别出这人不是公司的员工。
这需要人脸识别的算法学习一个example,然后就能识别这个人。大多数人脸识别的场景中都有这个一次学习的需求。
那么要怎么做呢?你可能会想到这样一个笨办法:将四张图片一起喂给卷积神经网络进行学习与训练,输出5分类别,分别是4个员工和什么都不是。但是!卷积神经网络区区4张图片还不够塞牙缝,那么小的数据集完全不足以去训练稳健神经网络。而且!一旦有一个新的员工加入了,你就得重新训练你的卷积神经网络,因为此时的输出有6个类别了。
那么真的要怎么做呢?–>学习一个”similaruty” function,即:
d(image1, image2) = degree of difference between images
输入两张图片,输出两张图片的差异程度。
如果 d(image1, image2) <= τ,则预测这两张图片为同一个人,否则为不同的人。
于是上面这个案例,小姐姐来敲门,摄像机传输她的照片到后台,将照片与后台的4张员工照片分别做相似性计算,如果相似性高于阀值,则通过,否则不是员工,不开门。
这就是一次学习,只需要一个人的一张图片,即一个样本,就能通过similarity function识别出是否为同一个人。
1.3 siamese 网络
实现one-shot learning的方法之一就是使用siamese网络。来自论文:
[Taigman et.al.,2014.DeeoFace closing the gap to human level performace]
首先输入image1:

通过卷积神经网络到最后一个全连接层,假设最后一层全连接的输出是128维的向量,则其实就表示一张图片被转换成了128维的向量来表征,以f(xi)表示
接着输入iamge2:

同理,也结果同样的神经网络,最后输出一个128维的向量,以f(xj)表示
现在我们只需要去计算上面两张图片的向量的相似度(如欧氏距离)就可以得到两张人脸图片的相似度,从而判别是否为同一个人。:
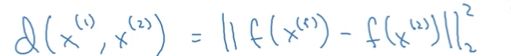
以上网络就叫做siamese神经网络。那么如何训练这个网络呢?
1.4 triplet损失
如何定义损失函数才能训练siamese网络的参数呢?
要想通过学习神经网络的参数,来得到优质的人脸图片编码,方法之一,就是使用三元组损失(triplet loss)函数,然后应用梯度下降。来自论文:
[Schroff et.al.,2015,Facenet:A unified embedding for face recognition and clustering]
1.4.1 构建样本与损失函数
首先构建样本,一个样本有三张图片组成,分别是:
Anchor(目标图片)

Positive(与目标图片为同一个人的另一张图片,正样本):

Negtive(与目标图片为不同人的图片,负样本):

要训练一个神经网络,使得同一个人的图片差异性低于不同人的图片:
![]()
之所以要加个a,是为了避免两者差异性都=0的情况。这个a也叫做间隔(merge),是人工设定的一个值,可以根据实际需求,调大或调小。
因此损失函数可以写成:

要使得损失尽可能小,就要使得
![]()
尽量要小于0才行。
代价函数可以写成:

1.4.2 构建训练集的原则
加入有10000张图片,里面共1000个人,如何从你的数据集中获取出anchor,positive, negtive三张图片组成样本集呢?就像这样:

无论怎么构建样本集,都要遵循一个原则,就是构建尽量有难度的样本集让模型训练,假设negative的图片是随机从数据集中选择,那么势必很大概率上anchor与negative的差异会很大,因为差异很大,因此模型随便一学就能分辨出它们的差异,然后这样训练出的神经网络,当在实际场景中遇到很像但是又不同的两个人时,就迷茫了。因此在构建样本时,一定要尽量让anchor与negative尽量相似,这样模型在训练的时候才能绞尽脑汁去学习如何分辨它们。
1.5 面部验证与二分类
本小节要讲的是如何将人脸识别当做一个二分类问题。
向两个网络同时输入两张图片,前面的东东一直不变,直到最后f(x)输出的时候,将两个向量一起给一个逻辑回归单元,最后输出一个二分类结果,1表示同一个人,0表示不同人。

那么逻辑回归单元如何处理的呢?计算过程如下

即将两个128维的向量,求对应元素差值的绝对值和作为sigmoid函数的输入值。若激活函数的输出大于阀值则输出0,否则为1.
以上求对应元素差值的绝对值和也可以换成如下公式:

在实际场景中,公司员工的图片的向量是实现计算好存储着的,当有图片进来对比时,只需要让图片走一遍以上神经网络,然后用输出的向量编码与已经存储好的目标图像的向量编码一起进入逻辑回归单元做二分类即可。
2. 神经风格转移
相关论文与论文详细解读,可见笔者另一篇笔记:
https://blog.csdn.net/sinat_33761963/article/details/53521292
2.1 什么是神经风格转移
给出两张图片,将第一张图片的内容(C),和第二张图片的风格(S)结合在一起,形成一张新的图片(G),就成为风格转移,即图二梵高画的风格转换到了图一的内容上了。

再比如,迁移毕加索的风格:

2.2 深度神经网络在学什么
在正是进入正题之前,我们先来了解一下卷积网络中深度较大的层真正在做什么呢,这有助于我们理解如何实现风格迁移。
假如你训练了一个深层神经网络,如下图是一个轻量级的Alex net:

你希望看到不同层之前隐藏单元的计算结果,那么你可以这样做:
2.2.1 浅层学到了什么
你可以在layer1上选择一个unit,假设你遍历了训练集,然后找出一个图片最大化地激活了特定的运算单元。在layer1,只能看到小部分卷积神经,要画出是哪些图块最大化了激活值,只有一小图块是有意义的:

你会发现都是这样的线,意味着在初期神经网络学习到了这样的线或者边缘。
对同一层的其他unit重复以上步骤,会得到9个不同的代表性的神经元,每个不同的图片块都最大化地激活了

可以看到,在神经网络的浅层,通常回去找一些简单的特征,比如边缘或者颜色阴影。
以上内容来自论文[Zeiler and Fergus.,2013,Visualizig and understanding convolutional networks]
2.2.2 深层学到了什么
在深层中,神经单元会看到更全面的图片,在极端的情况下,可以假设每一个像素都会影响到深层神经网络的输出。
下面是从layer1逐渐加深之后的最大激活图片块的可视化输出:

可见,第二层好像输出了更多信息,比如形状,layer3学习到了更具体的东西(人类,汽车轮子等)…到layer5输出的是很明确的物体的图像了。
2.3 代价函数
要构建一个风格迁移系统,首先要为生成的图像定义代价函数。代价函数分成两部分内:
内容代价函数–用于度量生成的图片的内容与提供Content的图片的内容是否一样。
风格代价函数–用于度量生成的图片的风格与提供style的图片的风格是否一样。
然后利用两个权重系数α和β,将以上两个代价函数进行加权求和,得到最终的代价函数。
![]()
生成新图像的过程如下:
(1)初始化新图像,随机生成100*100*3的图像G(尺寸根据你自己需要决定)
(2)利用梯度下降来最小化代价函数J(G),从而不断修改G中的像素值,使得G变成一张具备C的内容,具备S的风格的图片。
2.3.1 内容代价函数
(1)选择一个隐层l计算图片内容
2.2节中了解了神经网络不同的深浅的层其实在学不同的东西,那么要从某个层里计算并输出图片的内容,该选哪个层呢?这个层既不能太深又不能太浅。
(2)选择一个预训练的的卷积神经网络(如VGG)
(3)分别将生成的新图片G,与提供内容的图片C,计算预训练网络中第l层的输出:![]()
(4)若以上两个输出相似,则两个图片在内容上也相似。
因此内容代价函数可以写成:
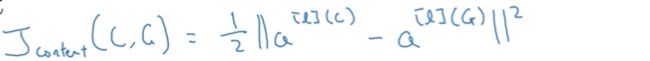
2.3.2 风格代价函数
(1)假如你选择了l层的输出来衡量style
(2)将style定义成channels之间激活值的相关系数
相关系数如何计算呢?
对于一个卷积的输出:

nH是高,nW是宽,nC是channel的数目。将channel用不同颜色表示:

每一层channel其实就对应着学习一类图片特征,若有9个channel,这可对应如下9类特征组:

同理,我们将初始化的新图片也输入同样的神经网络,在l层输出会得到:
现在通过同样的方式去计算他们的风格的表征,从而比较差异性。
![]()
i,j,k分别表示长,宽,channel坐标,G[l]的由来是l层的nc个channel分别两项相乘求相似性,得到nc*nc的矩阵。
以下是风格图片的风格矩阵
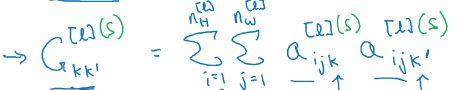
同理,可以得到新图片的风格矩阵:

将以上两个风格矩阵可求风格代价函数:

于是总的代价函数:
