一、概述
爬取步骤
第一步:获取视频所在的网页
第二步:F12中找到视频真正所在的链接
第三步:获取链接并转换成机械语言
第四部:保存
二、分析视频链接
获取视频所在的网页
以酷6网为例,随便点击一个视频播放链接,比如:https://www.ku6.com/video/detail?id=udfY7DjsSXbg8ghbDnhUwNTinOY

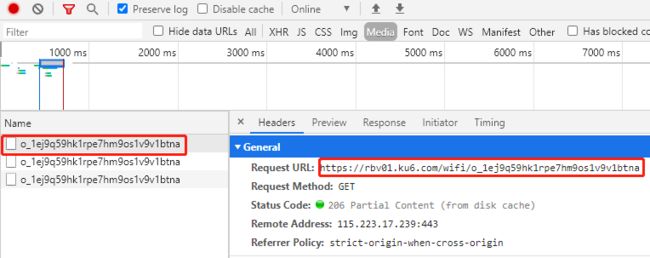
F12中找到视频真正所在的链接
按F12打开工具栏,network-->Media,这里会显示媒体文件

刷新页面,就能看到真正的视频加载链接
获取链接并转换成机械语言
查看网页代码,找到js代码。这里面就可以看到真正的视频链接地址
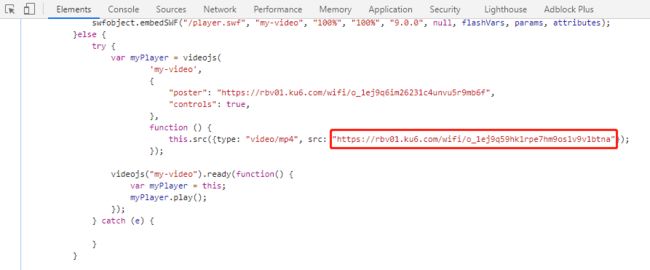
那么通过正则匹配,就可以得到视频地址了。
直接打开这个视频地址,网页可以直接播放。
https://rbv01.ku6.com/wifi/o_1ej9q59hk1rpe7hm9os1v9v1btna
保存
可以直接播放的话,通过requests模块,就可以下载二进制文件了。
三、代码实现
完整代码
# !/usr/bin/python3
# -*- coding: utf-8 -*-
import re
from lxml import etree
import requests
import time
from tqdm import tqdm
import os
from urllib.request import urlopen
def download_from_url(url, dst):
"""
@param: url to download file
@param: dst place to put the file
:return: bool
"""
# 获取文件长度
try:
file_size = int(urlopen(url).info().get('Content-Length', -1))
except Exception as e:
print(e)
print("错误,访问url: %s 异常" % url)
return False
# print("file_size",file_size)
# 判断本地文件存在时
if os.path.exists(dst):
# 获取文件大小
first_byte = os.path.getsize(dst)
else:
# 初始大小为0
first_byte = 0
# 判断大小一致,表示本地文件存在
if first_byte >= file_size:
print("文件已经存在,无需下载")
return file_size
header = {"Range": "bytes=%s-%s" % (first_byte, file_size)}
pbar = tqdm(
total=file_size, initial=first_byte,
unit='B', unit_scale=True, desc=url.split('/')[-1])
# 访问url进行下载
req = requests.get(url, headers=header, stream=True)
try:
with(open(dst, 'ab')) as f:
for chunk in req.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
pbar.update(1024)
except Exception as e:
print(e)
return False
pbar.close()
return True
def DownloadFile(url, name):
"""
下载文件
:param url:
:param name:
:return:
"""
try:
resp = requests.get(url=url, stream=True)
content_size = int(resp.headers['Content-Length']) / 1024
with open(name, "wb") as f:
print("package total size is:", content_size, 'k,start...')
for data in tqdm(iterable=resp.iter_content(1024), total=content_size, unit='k', desc=name):
f.write(data)
print("%s 下载成功"%url)
return True
except Exception as e:
print(e)
print("%s 下载失败" % url)
return False
# 头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
# 访问页面
response = requests.get('https://www.ku6.com/detail/371', headers=headers)
data = response.text
#构造了一个XPath解析对象并对HTML文本进行自动修正
html = etree.HTML(data)
# 获取视频播放链接
html_data = html.xpath('//div[@class="r_box"]/ul/li//a/@href')
# print("html_data", html_data, type(html_data))
# 遍历url
for i in html_data:
url = "https://www.ku6.com%s" % i
print(url)
# 访问url
response_1 = requests.get(url, headers=headers)
data_1 = response_1.text
# 正则匹配视频地址
video = re.findall('type: "video/mp4", src: "(.*?)"',data_1)
video_1 = video[0]
print("video_1", video_1)
x = video_1.split('/')[-1]
# 本地保存视频文件名
name = f'{x}.mp4'
print("name", name)
# 下载视频
download_from_url(video_1, name)
# 这里只演示第一个视频,直接break
break
执行代码,效果如下:

本文参考链接:https://cloud.tencent.com/developer/article/1471132