日用品电商销售数据分析
分析报告结论:
1.日用品办公文具的整体销售情况数据持续上升可观,但是对于用户个体的销售金额和商品购买量及次数都集中在区间的低段水平,所以对于此类交易群体,可在丰富日用品产品线例如针对儿童,年轻群体(学生),办公群体等人群设计产品,同时增加促销优惠活动等方式提高转换率和购买率。大部分用户的消费总额和购买总量也都集中刚在低段,为此,产品设计部门可以对商品进行多元文化价值的赋予,可按不同群体喜好丰富日用品办公产品的设计,增强其社交价值属性,提高目标用户的价值需求。
2.根据回归方程,用户购买量与消费金额呈线性关系,线性回归方程为y = -941+447x (其中y:消费金额/元;x:消费数量/个),市场销售部门据此方程设定销售KPI,针对部门的KPI可以粗略的得出需要售出多少数量的日用品办公文具,然后根据销量目标进一步采取营销策略。
3.市场销售部门需要调整各地区的销售策略,并结合利润率情况重点关注利润较高的商品,保证商品货源充足,对于销售利润较低的商品进行调整,市场销售部门还应根据各省市的情况具体分析盈利出现亏损的商品原因并进行针对性地改进,缩减成本,降低损失。
4.根据用户RFM价值模型,用户运营部门对不同的用户价值的用户采取精准策略,对重要发展用户想办法提高消费频率;对重要保持用户需要主动发短信联系。将高质量客户设定为“会员”类型,开设会员服务,专门为高质量会员用户优化购物体验,比如专线接听、特殊优惠等等,注重对用户的忠诚度的培养,比如打卡签到,积分制度,老用户打折制度会员升级制度。
说明:本文是利用Python进行数据分析实战。
目录:
一、分析背景和目的
二、理解数据
三、明确问题
四、分析思路
五、数据清洗
六、构建模型及可视化
七、提出建议
一、分析背景和目的
日用品商品涉及生活的方方面面,是日常生活中接触较多却易被忽视的物品,那么日用品的销售情况如何呢。本文将从商家的日用品销售数据出发,从商铺的角度出发,利用Python进行数据分析,探寻日用品的整体销售和盈利情况,以及该商品的不同价值消费用户分层情况。根据分析结论给出调整策略,促进业务的发展,提升业务的销售额和盈利,为公司创造价值。
二、理解数据
1.导入数据库
#导入数据分析三剑客及pyecharts库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pyecharts.charts import Bar,WordCloud,Pie
plt.rcParams['font.sans-serif']=['SimHei'] #设置字体为黑体
plt.rcParams['axes.unicode_minus']=False #显示符号
%matplotlib inline2.导入数据源
#导入数据源
data=pd.read_excel(r"D:\数据分析\某日用品电商销售数据.xlsx")
#输出数据
data.head()
3.查看原始数据信息
#查看原始数据信息
data.info()
>>>可以看到的有这些数据:订单IFD、订单日期、邮寄方式、国家、地区、省/自治区、细分、客户名称、类别、子类别、制造商、产品名称、数量、销售额、利润及其数据类型等,并且可以看出个别字段存在空值缺失值。
三、明确问题
1.商品的整体及个体的销售情况?
2.利润分布如何?如何提升日用品的销售利润?
3.哪些用户是价值用户,该如何进行维护?
四、分析思路

五、数据清洗
数据清洗按以下流程进行:

1.选择子集
根据分析需要,选取以下字段进行数据分析。
#选择子集-选取需要的字段
data=data.loc[:,['订单ID','订单日期','地区','省/自治区','客户名称','类别','子类别','产品名称','数量','销售额','利润']]
data.head()
2.列名重命名
所有字段名称均为中文名,字段名称清晰明了,故此项不进行。
3.删除重复值
由于数据存在重复值,所以删除重复值,否者影响数据结果的准确度。
#查看重复值并删除
print(data.duplicated().sum())
data.drop_duplicates().tail(5)
4.缺失值处理
#查看缺失值
data.isnull().sum() 
#删除缺失值并确认无缺失值
data=data.dropna()
data.isnull().sum() 
5.一致化处理
观察数据,本数据集均比较一致,订单日期已经是可进行分析的日期格式,但不够细化,为便于分析,对订单日期按年份和月份进行拆解,故在数据表后面增加年份和月份两列。
#新增'年份'和'月份'时间列
data['年份'] = data['订单日期'].dt.year
data['月份'] = data['订单日期'].dt.strftime('%Y%m')
data
注意:利用pandas进行数据分析时,遇到数据类型不正确时要对数据类型进行更改。
6.数据排序
将数据集按利润由大到小进行降序排序
#数据排序
data.sort_values(by='利润',ascending=False).head()
7.异常值处理
观察所有字段数据,未发现异常值,故本项不进行处理。
经过以上数据清洗步骤,清洗后的数据如下所示:

>>>清洗后共有9995行数据,没有空值和缺失值,数据结构完整规范一致。
至此,通过以上数据清洗步骤,得到较干净的数据,后续的分析工作将基于以上清洗的数据进行。
六、构建模型及可视化
6.1用户整体消费描述统计分析
6.1.1每笔订单描述统计分析
#每笔订单的描述统计分析
data.groupby('订单ID')[['数量','销售额','利润']].sum().describe()
从每笔订单的描述统计上看,每笔订单的平均值为7.6,标准差为6,稍有波动,中位数6,四分位数10,每笔订单里面的购买数量大部分都是小于10的,最大值为51。销售额:平均销售额为3257,中位数1591,标准差4423,波动非常大,说明有高额消费用户。利润:利润平均值432,中位数164,标准差1405,波动较大,从利润的描述统计印证有高消费用户。
6.1.2每位用户的描述统计分析
#每位用户的描述统计分析
data.groupby('客户名称')[['数量','销售额','利润']].sum().describe()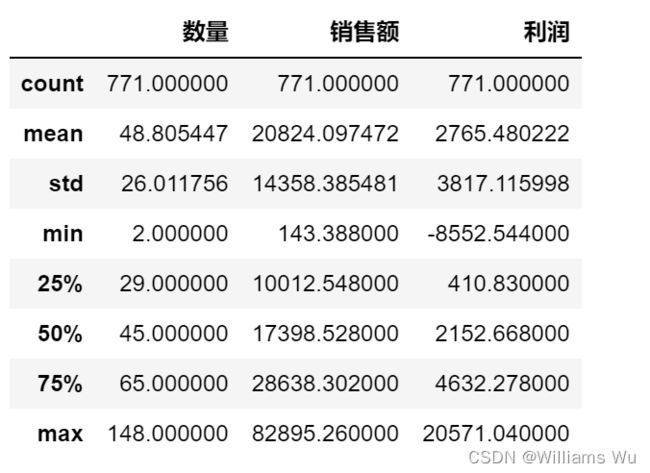
从每个用户的角度看,订单数量:平均订单数量为48.8,标准差为26,说明波动一般,中位数45,四分位数65,大部分的订单数量都是小于65的,最大值为148,是多次购买的用户。销售额:每位用户的平均销售额20824,中位数17398,标准差14358,波动较大。利润:利润平均值2765,中位数2152,标准差3817,波动较大,从用每位用户的订单角度再次印证有高消费用户。
6.2 用户整体销售趋势分析
6.2.1用户年销售趋势
#设置画布大小
plt.figure(figsize=(20,15))
#第1幅子图:年消费额
plt.subplot(221)
data.groupby('年份').销售额.sum().plot(fontsize=25)
plt.xlabel('年份',fontsize=25)
plt.ylabel('消费额/元',fontsize=25)
plt.title('消费额变化趋势(年)',fontsize=25)
#第2幅子图:年消费量
plt.subplot(222)
data.groupby('年份').数量.sum().plot(fontsize=25)
plt.xlabel('年份',fontsize=25)
plt.ylabel('消费数量/个',fontsize=25)
plt.title('消费数量变化趋势(年)',fontsize=25)
#第3幅子图:年消费人数
plt.subplot(223)
data.groupby('年份').客户名称.nunique().plot(fontsize=25)#user_id计算唯一值的总和
plt.xlabel('年份',fontsize=25)
plt.ylabel('消费人数/人',fontsize=25)
plt.title('消费人数变化趋势(年)',fontsize=25)
#第4副子图:年消费次数
plt.subplot(224)
data.groupby('年份').客户名称.count().plot(fontsize=25)
plt.xlabel('年份',fontsize=25)
plt.ylabel('消费次数/次数',fontsize=25)
plt.title('消费次数变化趋势(年)',fontsize=25)
#自动调整子图的尺寸,使之填充整个图像区域
plt.tight_layout()
6.2.2 用户年平均销售趋势
#设置画布大小
plt.figure(figsize=(15,15))
#消费人数num
num = data.groupby(['年份'])['客户名称'].nunique()
#第1幅子图:月平均销售额
#计算公式:平均销售额avg_amount = 总销售额amount/消费人数num
amount = data.groupby(['年份']).销售额.sum()
avg_amount = amount/num
plt.subplot(311)
avg_amount.plot(fontsize=25)
plt.xlabel('年份',fontsize=25)
plt.ylabel('平均销售额/元',fontsize=25)
plt.title('平均销售额变化趋势(年)',fontsize=25)
#第2幅子图:月平均销售数量
#计算公式:平均销售量avg_products = 总销售数量products/消费人数num
products =data.groupby(['年份']).数量.sum()
avg_products = products/num
plt.subplot(312)
avg_products.plot(fontsize=25)
plt.xlabel('年份',fontsize=25)
plt.ylabel('平均销售数量/个',fontsize=25)
plt.title('平均销售量变化趋势(年)',fontsize=25)
#第3幅子图:月平均消费次数
#计算公式:平均消费次数avg_times=销售次数times/销售人数num
plt.subplot(313)
times = data.groupby(['年份']).客户名称.count()
avg_times = times/num
avg_times.plot(fontsize=25)
plt.xlabel('月份',fontsize=25)
plt.ylabel('平均销售次数/次数',fontsize=25)
plt.title('平均销售次数变化趋势(月)',fontsize=25)
plt.tight_layout()
>>>由以上可知,用户整体消费及平均的消费趋势都是逐年稳定上升的,说明日用品整体销售情况较好,逐年增加,按此趋势未来的销量还将持续增长。
6.3用户个体销售数据分析
6.3.1用户销售额分布
data_user=data.groupby('客户名称').sum()
plt.figure(figsize=(15,6))
plt.hist(data_user['销售额'],bins=30)
plt.xlabel('销售额',fontsize=16)
plt.ylabel('客户人数',fontsize=16)
plt.title('用户销售额分布直方图',fontsize=20)
plt.tight_layout()
>>>用户的销售额主要集中与4000元以内,高消费金额的人数非常少,4000元以内消费金额的人数占了大多数比例,符合二八原则。
6.3.2用户销售数量分布
plt.figure(figsize=(15,6))
plt.hist(data_user['数量'],bins=30)
plt.xlabel('销售数量',fontsize=15)
plt.ylabel('客户人数',fontsize=15)
plt.title('用户销售数量分布直方图',fontsize=20)
plt.tight_layout()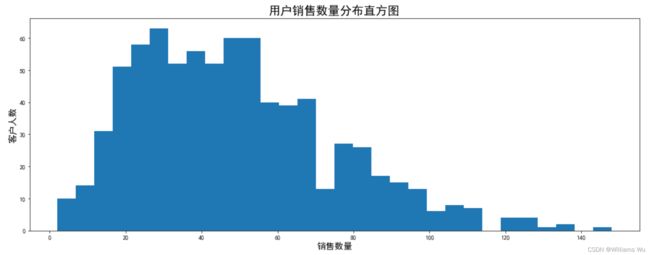
>>>用户销售数量主要分布在80以内,同样占了大多数比例,高消费数量的用户较少,同样符合二八原则。
6.3.3用户销售次数分布直方图
data_times=data.groupby(['客户名称']).count()
plt.figure(figsize=(15,6))
plt.hist(data_times['订单ID'],bins=30)
plt.xlabel('销售次数/次',fontsize=15)
plt.ylabel('客户人数/人',fontsize=15)
plt.title('用户销售次数分布直方图',fontsize=20)
plt.tight_layout()
>>>用户消费次数主要分布在25次以内,高频消费用户较少。
6.3.4用户购买数量和销售金额的线性关系
import seaborn as sns
sns.regplot(x='数量',y='销售额',data=data.groupby('客户名称').sum())
plt.title('销售额与销售数量的关系',fontsize=16)
plt.tight_layout()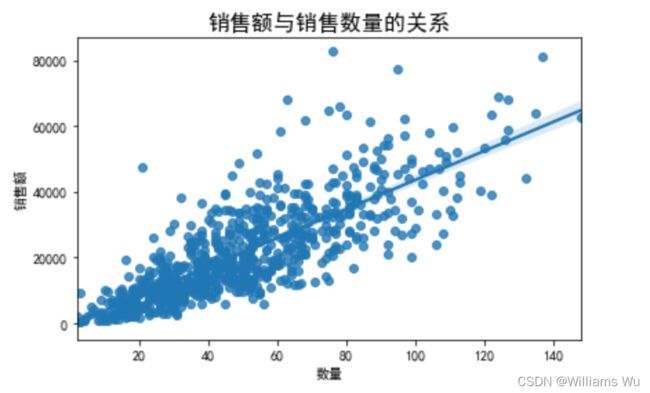
from sklearn.model_selection import train_test_split
data_user=data.groupby('客户名称').sum()
x=np.array(data_user['数量']).reshape(-1,1)
y=np.array(data_user['销售额']).reshape(-1,1)
#划分训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=1)
from sklearn.linear_model import LinearRegression
linreg=LinearRegression()
#训练模型
linreg.fit(x_train,y_train)
print('截距:',linreg.intercept_) #输出截距
print('斜率:',linreg.coef_) #输出斜率
#模型预测
y_pred=linreg.predict(x_test)
from sklearn import metrics
#对模型进行评估
print('线性回归训练集准确率:%.3f'%linreg.score(x_train,y_train))
#用scikit-learn计算MSE:均方误差
print('MSE:',metrics.mean_squared_error(y_test,y_pred))
#用scikit-learn计算RMSE:均方根误差
print('RMSE:',np.sqrt(metrics.mean_squared_error(y_test,y_pred))) 
用户消费金额与产品购买量基本呈线性分布,说明产品购买越多,消费金额也越高。
由以上可知,线性回归方程的表达式为y = -941+447x (其中y:消费金额/元;x:消费数量/个)。
>>>利用这个线性回归方程可以知道如果需要定一个目标需要达到多少消费金额KPI时,就可以算出大概要卖出日用品的数量了,也可以根据卖出的日用品数量对销售金额进行预测。
6.4商品销售数据分析
6.4.1各商品利润分布
将各订单商品的利润进行整体降序排序。
data.sort_values(by='利润',ascending=False).head()
将商品利润按商品类别展开,看看各类别商品的整体销售利润。
data2=data.pivot_table(values=['利润'],index=['类别'],aggfunc=('sum'))
data3=data2.sort_values(by='利润',ascending=False)
data3.plot.bar(figsize=(8,6))
plt.show()
>>>办公用品及技术类商品的利润额相差不大,家具类商品的利润额相对较低。
将利润按商品子类别进行展开,看看具体子类别的利润情况。
data2=data.pivot_table(values=['利润'],index=['子类别'],aggfunc=('sum'))
data3=data2.sort_values(by='利润',ascending=False)
data3.plot.bar(figsize=(20,6))
plt.xlabel('子类别')
plt.ylabel('利润')
plt.title('不同类别商品利润直方图')
plt.show()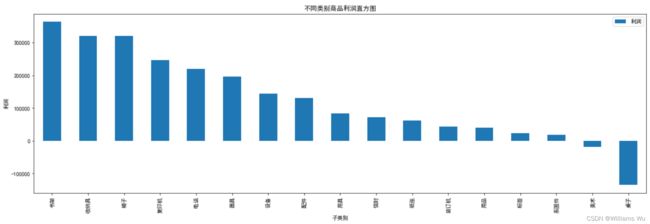
>>>书架、收纳具、椅子的利润TOP3,其中美术及桌子的利润出现负值。
将利润按地区进行展开,看看各地区的利润分布情况。
data2=data.pivot_table(values=['利润'],index=['地区'],aggfunc=('sum'))
data3=data2.sort_values(by='利润',ascending=False)
data3.plot.bar(figsize=(20,6))
plt.xlabel('地区')
plt.ylabel('利润')
plt.title('不同地区的利润直方图')
plt.show()
>>>华东和中南这些发达省市较多的地区的利润较高,西北地区销售利润最低。
西北地区为何销售零利润低?
将西北的利润分布按省市展开,看看西北地区各省市的利润情况。
data1=data.loc[(data['地区']=='西北')]
data2=data1.pivot_table(values=['利润'],index=['省/自治区'],aggfunc=('sum'))
data3=data2.sort_values(by='利润',ascending=False)
data3.plot.bar(figsize=(15,6))
plt.show()
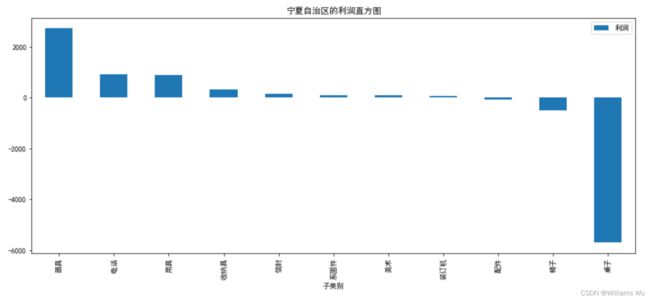
>>>西北地区最发达的陕西省的利润最高,甘肃省的利润值为负,宁夏自治区、青海省利润极低。
data1=data.loc[(data['省/自治区']=='甘肃')]
data2=data1.pivot_table(values=['利润'],index=['子类别'],aggfunc=('sum'))
data3=data2.sort_values(by='利润',ascending=False)
data3.plot.bar(figsize=(15,6))
plt.title('甘肃省的利润直方图')
plt.show()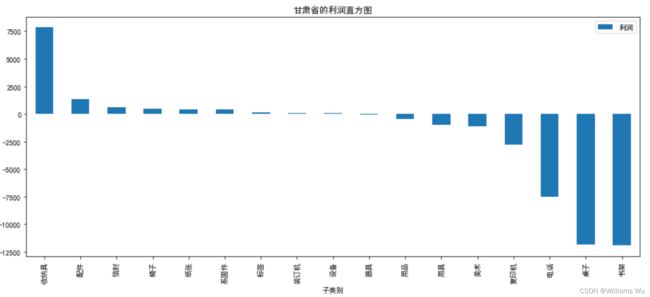
结合各订单商品的利润率情况
data1=data['利润']/data['销售额']
data['利润率']=data1.apply(lambda x:format(x,'.2%'))
data.head() #lambda匿名函数、格式化函数format以及聚合函数apply
>>>在甘肃省做的基本上是亏本生意,只有收纳具的利润较为可观,其他的日用品基本上盈利不大甚至亏本,书架和桌子和电话的盈利损失惨重。而宁夏自治区的器具润论相对较好,桌子的润利损失最多,几乎导致了宁夏的整体利润整体下跌。所以市场销售部门需要对甘肃省的销售策略进行调整,主推收纳具,减少其他日用品商品的销售,同样的办法调整各地区的销售策略,并结合利润率情况重点关注利润较高的商品,保证商品货源充足,对于销售利润较低的商品进行调整,市场销售部门还应根据各省市的情况具体分析盈利出现亏损的商品原因并进行针对性地改进,缩减成本,降低损失。
6.5客户RFM价值模型分析
6.5.1选择模型分析需要的字段
由于RFM模型只有3个指标,首先选取建立模型需要用到的相关指标的数据:
df=data[['订单ID','订单日期','客户名称','销售额']] #字段选择,选择需要的指标
df.head()
6.5.2整合相同ID的订单
由于同一个订单ID被拆分成了了多个,需要对同一个订单ID的订单进行汇总整合。
df=df.groupby(['订单ID','订单日期','客户名称'])['销售额'] #订单整合,将订单ID相同的组合
df=df.agg([np.sum]).reset_index()
df=df[['订单日期','客户名称','sum']].rename(columns={'sum':'销售额'})
df
下面就进行各个指标值的相关计算。
6.5.3计算购买时长
由于购买日期的最后时间是到2020年12月30日,在这里计算每个订单的购买日期到2020年12月31日的时间间隔长度为购买时长,根据购买时长可以确定最近一次的消费时间间隔长度。
df['购买时长']=(pd.to_datetime('2020-12-31')-df['订单日期']).dt.days
df.tail() 
6.5.4分别计算RFM值
#计算RFM值
R0=df.groupby(by=['客户名称'])['购买时长'].aggregate([('最近一次消费时长','min')]) #R值
F0=df.groupby(by=['客户名称'])['客户名称'].aggregate([('消费频次','count')]) #F值
M0=df.groupby(by=['客户名称'])['销售额'].aggregate([('消费金额','sum')]) #M值
#rfm=pd.merge(pd.merge(R0,F0,on='客户名称',how='right'),M0,on='客户名称',how='right')
#rfm=R0.join(F0).join(M0) #第2种求RFM方法
rfm=pd.concat([R0,F0,M0],axis=1) #第3种求RFM方法,这里选取第3种方法
rfm.tail() 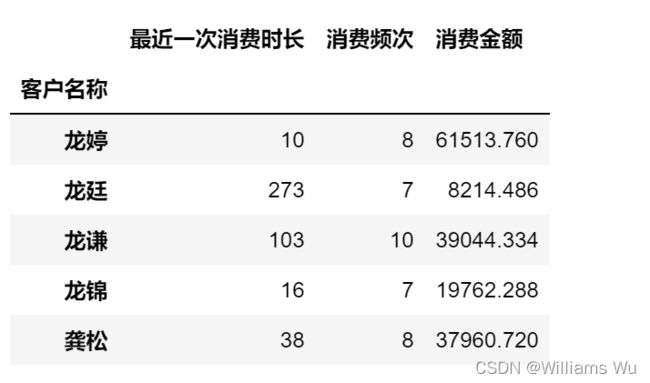
查看RFM值情况
rfm.describe()
6.5.5对指标进行分级,给RFM值进行打分评级
采用5分法分别对RFM值进行打分评级分组,是建模最关键的一步,分组不合理会影响模型的应用效果,由于没有经验数据,所以这里用quantile分位数函数进行分组,将分级后的评分值分别设定为R1、F1、M1。
注意:R值的打分与F值、M值的打分相反,R值越大,最后一次消费时间间隔越长,价值越小,所以打分评级也越低。
#对指标进行分级,给RFM值进行打分评级
bins = rfm.最近一次消费时长.quantile(q=np.linspace(0,1,6),interpolation='nearest')
bins[0] =0
labels =[5, 4, 3, 2, 1]
R1 = pd.cut(rfm.最近一次消费时长,bins,labels=labels); #quantile是分位数函数,cut是切片函数
bins = rfm.消费频次.quantile(q=np.linspace(0,1,6),interpolation='nearest')
bins[0]=0
labels=[1,2,3,4,5]
F1 = pd.cut(rfm.消费频次,bins,labels=labels);
bins = rfm.消费金额.quantile(q=np.linspace(0,1,6),interpolation='nearest')
bins[0]=0
labels=[1, 2, 3, 4, 5]
M1 = pd.cut(rfm.消费金额,bins,labels=labels);
rfm['R1']=R1
rfm['F1']=F1
rfm['M1']=M1
rfm.tail()
6.5.6对RFM总分进行统计分级
对RFM值的指标评分都按比例进行汇总为一个分数,这里认为消费金额更为重要,然后是消费频率,所以这里分别对RFM值按0.2,0.3,0.5的比例进行计算汇总为一个RFM值。
rfm['RFM']=0.2*R1.astype(int)+0.3*F1.astype(int)+0.5*M1.astype(int)
rfm.sort_values(by='RFM') #涉及计算时astype(int)将涉及运算的对象转化为int整数型
6.5.7判断每个用户的价值
根据用户的RFM值给不同价值的用户贴上价值标签,由此得到每个用户的价值标签。
bins = rfm.RFM.quantile(q=[0,0.125,0.25,0.375,0.5,0.625,0.75,0.875,1],interpolation='nearest')
bins[0] =0
labels = ['流失客户','一般维持客户','一般发展客户','潜力客户','重要挽留客户','重要保持客户','重要发展客户','重要价值客户']
rfm['用户分层'] = pd.cut(rfm.RFM,bins,labels=labels)
rfm
6.5.8汇总不同价值用户的人数
df1=rfm.reset_index().dropna() #将不同标签的人进行人数汇总
df1=df1.pivot_table('客户名称',index='用户分层',aggfunc='count')
df1=df1.rename(columns={'客户名称':'人数'}).reset_index()
df1
>>>从RFM模型来看,在8种价值客户中,流失客户人数最多,重要挽留客户人数次之。针对不同价值的用户进行精准运营方案如下表。

根据用户RFM价值模型,精细化地进行用户运营,对不同价值的用户采用不同的运营策略,以此维护好不同价值的用户,并做好用户的留存、活跃等。业务方可以根据结果对客户价值分类运营,降低营销成本,提高ROI。在运营时,针对不同用户,需要采取不同的措施。如针对重要挽留用户,可以通过短信/邮件形式发放大额度电子优惠券,对用户进行召回;针对重要发展用户,精准推送促销活动信息,从而提升用户消费次数,培养用户粘性。
七、提出建议
1.从用户整体和个体销售分析方面,整体销售数据持续上升可观,但是对于用户个体的销售方面需要提升,例如每笔订单的金额和商品购买量及次数都集中在区间的低段水平,高段水平的人数较少,大部分是小金额小批量进行购买,而且日用品办公文具本身的消耗损耗较少,一旦购买使用时间可较长的特点 所以对于此类交易群体,可在丰富日用品产品线例如针对儿童,年轻群体(学生),办公群体等人群设计产品,同时增加促销优惠活动等方式提高转换率和购买率。并且大部分用户的消费总额和购买总量也都集中刚在低段,呈现长尾分布,这个主要是跟用户的具体需求有关,为此,产品设计部门可以对商品进行多元文化价值的赋予,可按不同群体喜好丰富日用品办公产品的设计,增强其社交价值属性,提高用户的价值需求。
2.用户个体消费方面,根据回归方程,用户购买量与消费金额呈线性关系,线性回归方程为y = -941+447x (其中y:消费金额/元;x:消费数量/个)。市场销售部门据此方程制定部门KPI,根据回归方程对相关部门的KPI粗略的得出需要售出多少数量的日用品办公文具,然后根据销量目标进一步采取营销策略。
3.从商品利润情况分析,办公用品及技术类商品的利润额相差不大,家具类商品的利润额相对较低,各类别商品的利润均有60万以上。具体子类别商品利润TOP3的有书架、收纳具、椅子,其中美术及桌子的利润出现负值。从地区上看,华东和中南地区的利润较高,西北地区销售利润最低。市场销售部门需要调整各地区的销售策略,并结合利润率情况重点关注利润较高的商品,保证商品货源充足,对于销售利润较低的商品进行调整,市场销售部门还应根据各省市的情况具体分析盈利出现亏损的商品原因并进行针对性地改进,缩减成本,降低损失。
4.根据用户RFM价值模型,运营部门根据不同的用户价值,对重要价值用户采用VIP会员服务;对重要发展用户想办法提高消费频率;对重要保持用户需要主动发短信联系。将高质量客户设定为“会员”类型,开设会员服务,专门为高质量会员用户优化购物体验,比如专线接听、特殊优惠等等,注重对用户的忠诚度的培养,比如打卡签到,积分制度,老用户打折制度会员升级制度。