requests模块----这是一个强硬的手段,有多强呢?看看你就知道了
目录
requests的作⽤
发送简单的get请求
发送带header的请求
发送POST请求
cookies参数的使⽤
cookie和session区别
使⽤代理
设置请求超时时间
请求SSL证书
_____________________________________________________
开始了
requests模块简单介绍
1.requests模块作为爬⾍中最常⽤的⼀个模块,一个让爬虫小白能快速接受的模块,
简单了解一下我们访问网页的情况
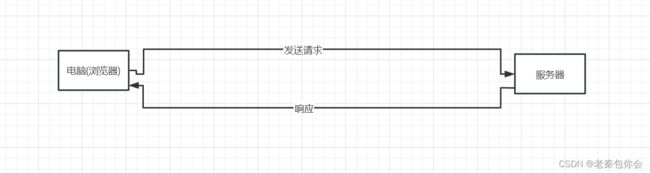
我们是通过发送请求给服务器,然后服务器响应返回数据,而requetst就是模拟浏览器发送请求,
简单理解为:发送⽹络请求,返回相应数据
下面开始使用requests前我把我的思路以画图的形式表达出来:
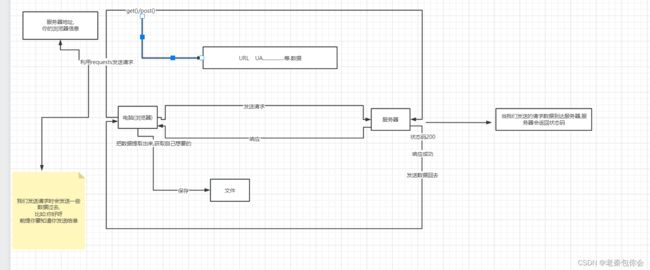
下面我们要干事情,要先知道怎么干,第一步:
下载模块requests:

发送简单的get请求
下面开始我们的简单代码:
url="https://www.baidu.com/?tn=02003390_19_hao_pg"
import requests
url="https://www.baidu.com/?tn=02003390_19_hao_pg"
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
# 发送请求
response=requests.get(url)
print(response)
response.encoding="utf-8"
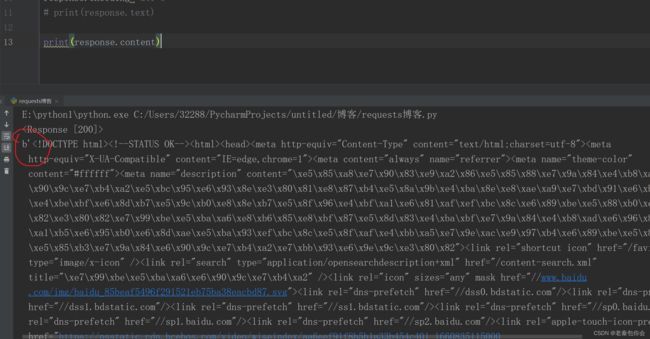
print(response.text)

encoding是为了设计返回数据编码格式和接受的数据编码格式相一致
text是获取服务器返回数据html 类型为字符串
获取数据的还有content json()
返回响应状态码
返回部分请求头
返回全部请求头
content 获取数据(返回字节数据)
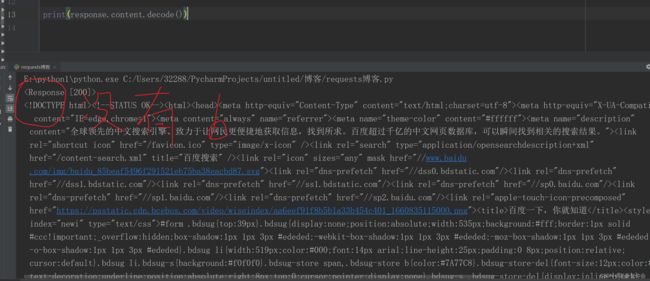
content.decode() 等同于 text 返回类型为字符串
把字节转换为字符串
json()就是把json数据转换成python的数据类型
下面代码如下:
import requests
url="https://www.woaifanyi.com/api/2.0/save/?ajaxtimestamp=1685158773961"
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
data={
"source": "你好",
"from": "1",
"to": "2"
}
# 发送请求
response=requests.post(url,data=data,headers=header)
print(response)
print(response.json())
print(response.request.headers)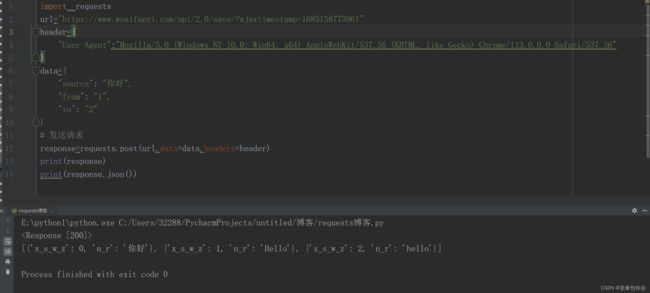
这里用到了post(),这个和get()的大致用法相同 唯一不同的就是data参数
返回响应对应的 请求头
response.request.headers
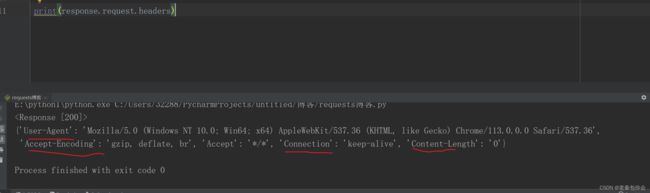
返回全部响应头
headers

发送带header的请求
可以看出上面返回的是一个部分HTML的数据,但实际却是比这个多了很多
为了防止出现这样的情况,我们可以加一个请求头
import requests
url="https://www.baidu.com/?tn=02003390_19_hao_pg"
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
# 发送请求
response=requests.get(url,headers=header)
print(response)
response.encoding="utf-8"
print(response.text)这样就可以获取整个页面的数据,但只是获取到静态页面的数据,动态的数据靠这个却很难(后面我会发出怎么获取动态页面的数据)
发送POST请求
前面json()时候我用来post()来演示
这里不花费时间
cookies参数的使⽤
cookie可以理解为用户信息,就好比我们登录QQ时有段时间不会让我们手动登录,就是因为qq软件有我们的cookie信息
使用:可以加在header里面一起发送过去
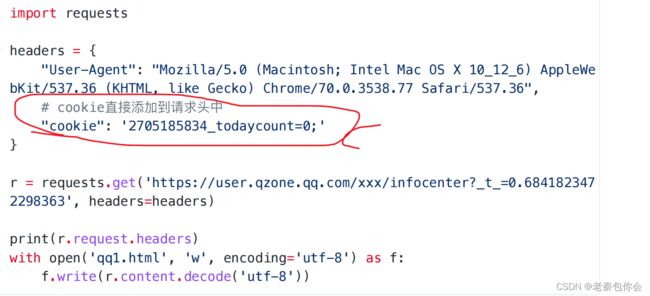
代码如下:
有些小可爱可能觉得写cookie有一点难写,这个网址可以解决 ,https://spidertools.cn/#/formatHeader
import requests
url="http://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_web_fanyi&sign=0d2d6b4f80839676"
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"cookie":"XXXXXXXXXXX"
}
# 发送请求
response=requests.get(url,headers=header)
print(response)
response.encoding="utf-8"
# print(response.text)
# print(response.content.decode())
# print(response.status_code)
# print(response.json())cookie和session区别
使⽤代理
代理IP可以分为三类
import requests
url="http://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_web_fanyi&sign=0d2d6b4f80839676"
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"cookie":"XXXXXXXXXXX"
}
proxies={
"http":"http://117.191.11.112",
"https":"http://117.191.11.112"
}
# 发送请求
response=requests.get(url,headers=header,proxies=proxies)
print(response)
response.encoding="utf-8"当代理IP不行时会报错:

在请求的时候,代理IP请求时间太长了,有写小可爱就会烦了,所有我们可以添加一个响应时间,最多等待多久
设置请求超时时间
import requests
url="http://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_web_fanyi&sign=0d2d6b4f80839676"
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"cookie":"XXXXXXXXXXX"
}
proxies={
"http":"http://117.191.11.112",
"https":"http://117.191.11.112"
}
# 发送请求
response=requests.get(url,headers=header,proxies=proxies,timeout=10)
print(response)
response.encoding="utf-8"timeout=10 代表最多等待10秒 ! ! ! 不是强行等待10秒
请求SSL证书
response = requests.get('https://inv-veri.xxxx.gov.cn/',verify=False)