MySQL 中 “索引” 和 “查询” 的优化以及 JOIN 原理
目录
1、关于索引优化
常见的索引失效以及相关的优化
关于覆盖索引
2、关于查询优化
情况一(左外连接)
情况二(内连接)
3、谈谈 JOIN 原理
3.1 Simple Nested-Loop Join 【简单】嵌套循环连接
3.2 Index Nested-Loop Join 【索引】嵌套循环连接
3.3 Block Nested-Loop Join 【块】嵌套循环连接
3.4 JOIN 原理总结
1、关于索引优化
-
常见的索引失效以及相关的优化
计算、函数、类型转换(自动或手动) 都会导致索引失效
#1、关于函数失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc'; #索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%'; #索引优化生效
#2、关于计算失效
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 900001; #索引失效
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 900000; #索引优化生效
#3、关于类型转换失效
# 其中 name 是 varchar 类型
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name = 123; #索引失效,存在隐式函数转换
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name = '123'; #索引优化生效
#4、关于范围条件右边索引失效
#最终还是要根据 SQL 中优化器调优后的执行顺序来进行判断
create index idx_age_name_classid on student(age,name,classid); #添加索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age = 30 AND student.classId>20 AND student.name = 'abc'; #索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age = 30 AND student.name ='abc' AND student.classId>20; #索引优化生效
#5、is null可以使用索引,is not null无法使用索引
#索引失效,因为 IS NOT NULL 相当于直接全表查询,遍历树
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL; #索引优化生效
#6、like以通配符%开头索引失效
#索引失效,因为没有明确的开头查询条件,相当与遍历树,不满足最左原则
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE '%ab%';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE 'ab%'; #索引优化生效
-
关于覆盖索引
什么是覆盖索引?
- 索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它 不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数 据,那就不需要读取行了。一个索引包含了满足查询结果的数据就叫做覆盖索引。
- 我们也可以这样理解。它是非聚集复合索引的一种形式,它包括在查询里的Select、Join和Where子句用到的所有列(即建索引的字段正好是覆盖查询条件中所涉及的字段,也即,索引包含了查询正在查找的数据)
注意事项:
之前举例的索引失效 SQL 语句,进行添加索引时,也并不一定会失效(要看你索引怎么加),而会使用覆盖索引;因为 SQL 的优化器会在 firesort 和 使用索引 之间进行权衡,估算成本
优点:
- 避免 InnoDB 进行二次查询,也就是避免回表
- 可以把随机的 IO 变成顺序的 IO ,以提高查询的效率
缺点:
- 索引字段的维护 总是有代价的。因此,在建立冗余索引来支持覆盖索引时就需要权衡考虑了。这是业务DBA,或者称为业务数据架构师的工作。
索引使用建议:

2、关于查询优化
-
情况一(左外连接)
此时,type 作为驱动表,book作为被驱动表
两表进行添加索引时,由于这里默认指定了驱动表与被驱动表,所以 SQL 优化器以指定为主
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
#这里进行添加索引优化
ALTER TABLE book ADD INDEX Y (card); #可以避免全表扫面
ALTER TABLE `type` ADD INDEX X (card); #无法避免全表扫面
如图所示:
结果 type 中,驱动表 book 为 index ,而被驱动表 type 为 ref

-
情况二(内连接)
由于这里是进行的内连接,并没有明确指定驱动表和被驱动表,此时,SQL 优化器会自动根据具体的情况进行选择(根据 SQL 的执行成本进行决定)
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
#这里进行添加索引优化
ALTER TABLE book ADD INDEX Y (card);
ALTER TABLE `type` ADD INDEX X (card); 如图所示:
结果 type 中,由于之前没有指明驱动表,这里经过 SQL 优化器的成本估算,将表 type 作为了去驱动表,而将表 book 作为了被驱动表

3、谈谈 JOIN 原理
JOIN 方式连接多个表,本质就是各个表之间的数据的循环匹配;在 MySQL5.5 之前,用的就是嵌套循环(Nested Loop Join);若表中的数据非常大,则 join 所关联的执行时间会很长。在 MySQL5.5 之后,用的是 BNLJ 算法来进行优化嵌套执行
3.1 Simple Nested-Loop Join 【简单】嵌套循环连接
这里是将 A表 中取出一条数据,然后与 B表 进行遍历,将匹配的结果放到 result 中,以此类推
驱动表A 中的每一条记录都与 驱动表B 中的数据进行判断
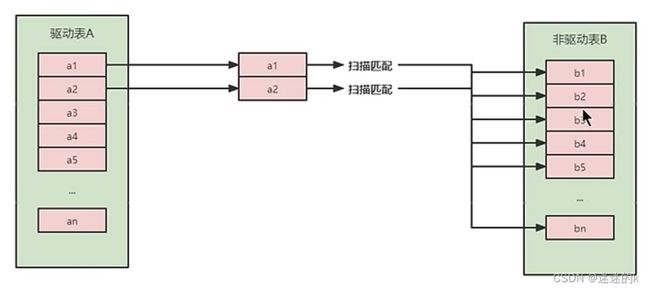
显然,这种方式进行嵌套循环的效率是非常低的
3.2 Index Nested-Loop Join 【索引】嵌套循环连接
这里,索引嵌套的优化思路主要的为了 减少内层表数据的匹配次数(B + 树)
将外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录去进行比较,这样就极大的减少了对内层表的匹配次数

这里需要注意的是:
- 如果索引不是主键索引,则需要进行一次回表查询
- 若是主键索引,则效率 yyds
若表中没有进行添加索引或者因为 SQL 语句导致索引失效,则这种方式就属于摆设了,就又回到简单嵌套查询连接那里了;不过不要慌,还提供了接下来的一种方式 φ(* ̄0 ̄)
3.3 Block Nested-Loop Join 【块】嵌套循环连接
- 虽然说跟 Simple Join 一样,没有进行添加索引,但是,Block 不再像 Simple 是逐条获取驱动表的数据,而是 分成一块一块的获取;
- 同时,引入了 JOIN BUFFER 缓冲区,将驱动表 JOIN 相关的部分数据列缓存到 JOIN BUFFER 中
- 在全表扫描时,被驱动表中的每一条数据一次性的和 JOIN BUFFER 中所有的驱动表记录进行匹配,这里将 Simple Join 中多次比较合并成了一次,降低了 IO 的次数,从而提高了访问效率

注意事项:
- 这里缓存的不只是关联表的列,SELECT 后面的列也会被缓存起来
- 在一个有 N 个 JOIN 关联的 SQL 中,会分配 N-1 个 JOIN BUFFER
- 查询的时候尽量减少不必要的字段,以让 JOIN BUFFER 中可以存放更多的列
3.4 JOIN 原理总结
以上的几种嵌套循环连接的整体效率比较:INLJ > BNLJ > SNLJ
- 用小结果集驱动大结果集,以减少 IO 次数
#推荐,t1 作为驱动表,t2 作为被驱动表
select t1.b,t2.* from t1 straight_join t2 on t1.b=t2.b where t2.id <= 100;
#不推荐,t2 作为驱动表,t1 作为被驱动表
select t1.b,t2.* from t2 straight_join t1 on t1.b=t2.b where t2.id <= 100; - 为被驱动表匹配的条件增加索引(减少内层表中循环匹配的次数)
- 增大 JOIN BUFFER SIZE 的大小(一次缓存的越多,扫表的次数就越少)
- 减少驱动表不必要的字段查询(字段越少,JOIN BUFFER 所缓存的数据就越多)
这里需要知道的是,8.0版本的 MySQL 废弃了 BNJL ,用 Hash Join 进行替代

Nested Loop 与 Hash Join 对比图:
