大数据分析案例-基于LightGBM算法构建银行客户流失预测模型

♂️ 个人主页:@艾派森的个人主页
✍作者简介:Python学习者
希望大家多多支持,我们一起进步!
如果文章对你有帮助的话,
欢迎评论 点赞 收藏 加关注+
喜欢大数据分析项目的小伙伴,希望可以多多支持该系列的其他文章
| 大数据分析案例-基于随机森林算法预测人类预期寿命 |
| 大数据分析案例-基于随机森林算法的商品评价情感分析 |
| 大数据分析案例-用RFM模型对客户价值分析(聚类) |
| 大数据分析案例-对电信客户流失分析预警预测 |
| 大数据分析案例-基于随机森林模型对北京房价进行预测 |
| 大数据分析案例-基于RFM模型对电商客户价值分析 |
| 大数据分析案例-基于逻辑回归算法构建垃圾邮件分类器模型 |
| 大数据分析案例-基于决策树算法构建员工离职预测模型 |
| 大数据分析案例-基于KNN算法对茅台股票进行预测 |
| 大数据分析案例-基于多元线性回归算法构建广告投放收益模型 |
| 大数据分案例-基于随机森林算法构建返乡人群预测模型 |
| 大数据分析案例-基于决策树算法构建金融反欺诈分类模型 |
目录
1.项目背景
2.项目简介
2.1项目说明
2.2数据说明
2.3技术工具
3.算法原理
4.项目实施步骤
4.1理解数据
4.2数据预处理
4.3探索性数据分析
4.3.1流失客户比例
4.3.2性别对客户流失率的影响
4.3.3年龄对流失率的影响
4.3.4产品数量对流失率的影响
4.3.5地理因素对流失率的影响
4.3.6客户状态对流失率的影响
4.3.7相关关系分析
4.4特征工程
4.5模型构建
4.6模型评估
4.7特征重要性评分
4.8模型预测
5.实验总结
1.项目背景
随着金融市场的不断发展和竞争的加剧,银行需要不断了解其客户,并为其提供更好的服务和体验,以保持客户忠诚度并减少客户流失。因此,预测银行客户流失成为了一个备受关注的问题。
客户流失对银行的影响非常大。根据世界银行的数据,客户流失率每下降 10%,银行的收入和利润就会相应增长。然而,客户流失的原因很多,包括客户服务体验、银行产品、价格、地理位置等多个方面。因此,为了更好地预测客户流失,银行需要使用各种技术和方法来分析和评估这些因素。
LightGBM 是一种基于 GBDT(Gradient Boosting Decision Tree) 算法的机器学习模型,其具有高效、易用、可扩展等优点,因此在机器学习领域中被广泛应用。本项目旨在使用 LightGBM 算法构建一个银行客户流失预测模型,以帮助银行更好地了解其客户,预测客户流失风险,并提供个性化的服务和建议,以提高客户满意度和忠诚度。
本项目的研究背景主要包括以下几个方面:
-
银行客户流失预测是一个备受关注的问题。随着金融市场的不断发展和竞争的加剧,银行需要不断了解其客户,并为其提供更好的服务和体验,以保持客户忠诚度并减少客户流失。
-
LightGBM 是一种高效的机器学习模型,适用于大规模数据集的分析和预测。因此,使用 LightGBM 算法构建银行客户流失预测模型是一个可行的选择。
-
本项目旨在帮助银行更好地了解其客户,预测客户流失风险,并提供个性化的服务和建议,以提高客户满意度和忠诚度。这将有助于提高银行的竞争力和盈利能力。
综上所述,基于 LightGBM 算法构建银行客户流失预测模型的项目具有重要的现实意义,可以为银行提供有价值的客户洞察和预测模型,帮助银行更好地留住客户并提高客户满意度和忠诚度。
2.项目简介
2.1项目说明
本项目旨在分析银行客户流失数据,找出客户流失的原因,挖掘影响流失率的因素,最后使用机器学习算法构建银行客户流失预测模型,帮助企业及时针对即将流失的用户进行挽回。众所周知,与保留现有客户相比,签入新客户的成本要高得多。银行了解是什么导致客户做出离开公司的决定是有利的。客户流失预防使公司能够制定忠诚度计划和保留活动以保留尽可能多的客户。
2.2数据说明
本数据集来源于Kaggle,数据集共有10000条,18个特征变量,各个变量具体含义如下:
1.RowNumber—行编号
2.CustomerId—客户ID
3.Surname—客户姓氏
4.CreditScore—信用评分
5.Geography—客户的地理位置
6.Gender—性别
7.Age—年龄
8.Tenure—客户成为银行客户的年限
9.Balance—余额
10.NumOfProducts—客户通过银行购买的产品数量
11.HasCrCard—客户是否有信用卡
12.IsActiveMember—客户是否是活跃状态
13.EstimatedSalary—银行估算客户的薪资
14.Exited—客户是否流失
15.Complain—客户有无投诉。
16.Satisfaction Score—客户为解决投诉而提供的分数
17.Card Type—客户持有的卡片类型
18.Points Earned—客户使用信用卡赚取的积分
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
LightGBM算法基本原理
GBDT算法的基本思想是把上一轮的训练残差作为下一轮学习器训练的输入,即每一次的输入数据都依赖于上一次训练的输出结果。因此,这种训练迭代过程就需要多次对整个数据集进行遍历,当数据集样本较多或者维数过高时会增加算法运算的时间成本,并且消耗更高的内存资源。
而XGBoost算法作为GBDT的一种改进,在训练时是基于一种预排序的思想来寻找特征中的最佳分割点,这种训练方式同样也会导致内存空间消耗极大,例如算法不仅需要保存数据的特征值,还需要保存特征排序的结果;在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大,特别是当数据量级较大时,这种方式会消耗过多时间。
为了对这些问题进行优化,2017年微软公司提出了LightGBM算法(Light Gradient Boosting Machine),该算法也是基于GBDT算法的改进,,但相较于GBDT、XGBoost算法,LightGBM算法有效地解决了处理海量数据的问题,在实际应用中取得出色的效果。LightGBM算法主要包括以下几个特点:直方图算法(寻找最佳分裂点、直方图差加速)、Leaf-wise树生长策略、GOSS、EFB、支持类别型特征、高效并行以及Cache命中率优化等。
(1)直方图Histogram算法(减少大量计算与内存占用)
XGBoost算法在进行分裂时需要预先对每一个特征的原始数据进行预排序,而直方图Histogram算法则是对特征的原始数据进行“分桶#bin”,把数据划分到不同的离散区域中,再对离散数据进行遍历,寻找最优划分点。这里针对特征值划分的每一个“桶”有两层含义,一个是每个“桶”中样本的数量;另一个是每个“桶”中样本的梯度和(一阶梯度和的平方的均值等价于均方损失)。
可以看出,通过直方图算法可以让模型的复杂度变得更低,并且特征“分桶”后仅保存了的离散值,大大降低内存的占用率。其次,这种“分桶”的方式从某种角度来看相当于对模型增加了正则化,可以避免模型出现过拟合。
值得注意的是,直方图算法是使用了bin代替原始数据,相当于增加了正则化,这也意味着有更多的细节特征会被丢弃,相似的数据可能被划分到相同的桶中,所以bin的数量选择决定了正则化的程度,bin越少惩罚越严重,过拟合的风险就越低。

另外,在LightGBM直方图算法中还包括一种直方图作差优化,即LightGBM在得到一个叶子的直方图后,能够通过直方图作差的方式用极小的代价得到其兄弟叶子的直方图,如上图所示,当得到某个叶子的直方图和父节点直方图后,另一个兄弟叶子直方图也能够很快得到,利用这种方式,LightGBM算法速度得到进一步提升。
(2)带深度限制的Leaf-wise的叶子生长策略(减少大量计算、避免过拟合)
GBDT与XGBoost模型在叶子生长策略上均采用按层level-wise分裂的方式,这种方式在分裂时会针对同一层的每一个节点,即每次迭代都要遍历整个数据集中的全部数据,这种方式虽然可以使每一层的叶子节点并行完成,并控制模型的复杂度,但也会产生许多不必要搜索或分裂,从而消耗更多的运行内存,增加计算成本。
而LightGBM算法对其进行了改进,使用了按叶子节点leaf-wise分裂的生长方式,即每次是对所有叶子中分裂增益最大的叶子节点进行分裂,其他叶子节点则不会分裂。这种分裂方式比按层分裂会带来更小的误差,并且加快算法的学习速度,但由于没有对其他叶子进行分裂,会使得分裂结果不够细化,并且在每层中只对一个叶子不断进行分裂将增大树的深度,造成模型过拟合[25]。因此,LightGBM算法在按叶子节点生长过程中会限制树的深度来避免过拟合。
(3)单边梯度采样技术 (减少样本角度)
在梯度提升算法中,每个样本都有不同梯度值,样本的梯度可以反映对模型的贡献程度,通常样本的梯度越大贡献给模型的信息增益越多,而样本的梯度越小,在模型中表现的会越好。
举个例子来说,这里的大梯度样本可以理解为“练习本中的综合性难题”,小梯度样本可以理解为“练习本中的简单题”,对于“简单题”平时做的再多再好,而“难题”却做的很少,在真正的“考试”时还是会表现不好。但并不意味着小梯度样本(“简单题”)就可以直接剔除不用参与训练,因为若直接剔除小梯度样本,数据的分布会发生改变,从而影响模型的预测效果。
因此,LightGBM算法引入了单边梯度采样技术(Gradient-based One-Side Sampling,GOSS),其基本思想就是从减少样本的角度出发,利用样本的梯度大小信息作为样本重要性的考量,保留所有梯度大的样本点(“保留所有难题”),对于梯度小的样本点(“简单题”)按比例进行随机采样,这样既学习了小梯度样本的信息,也学习了大梯度样本的信息(“平时难题都做,简单题做一部分,在面临真正的考试时才可能稳定发挥,甚至超水平发挥”),在不改变原始数据分布的同时,减小了样本数量,提升了模型的训练速度。
(4)互斥特征捆绑(减少特征角度)
高维度的数据通常是非常稀疏的,并且特征之间存在互斥性(例如通过one-hot编码后生成的几个特征不会同时为0),这种数据对模型的效果和运行速度都有一定的影响。
通过互斥特征捆绑算法(Exclusive Feature Bundling,EFB)可以解决高维度数据稀疏性问题,如下图中,设特征1、特征2以及特征3互为互斥的稀疏特征,通过EFB算法,将三个特征捆绑为一个稠密的新特征,然后用这一个新特征替代原来的三个特征,从而实现不损失信息的情况下减少特征维度,避免不必要0值的计算,提升梯度增强算法的速度。

总的来说,LightGBM是一个性能高度优化的GBDT 算法,也可以看成是针对XGBoost的优化算法,可以将LightGBM的优化用公式表达,如下式:LightGBM = XGBoost + Histogram + GOSS + EFB

4.项目实施步骤
4.1理解数据
首先导入银行客户流失数据
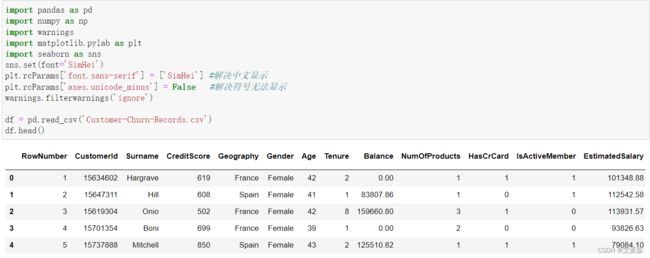
查看数据大小 ,数据共有10000行18列
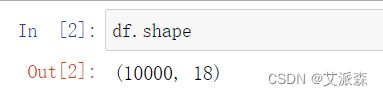
查看各变量的数据类型
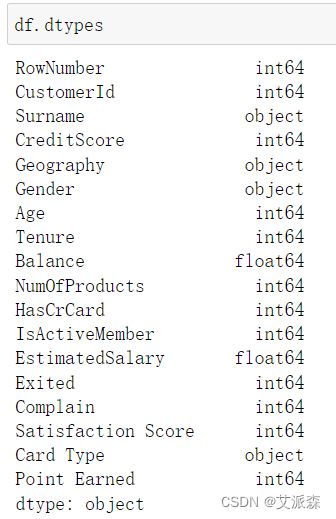
查看数据基本信息
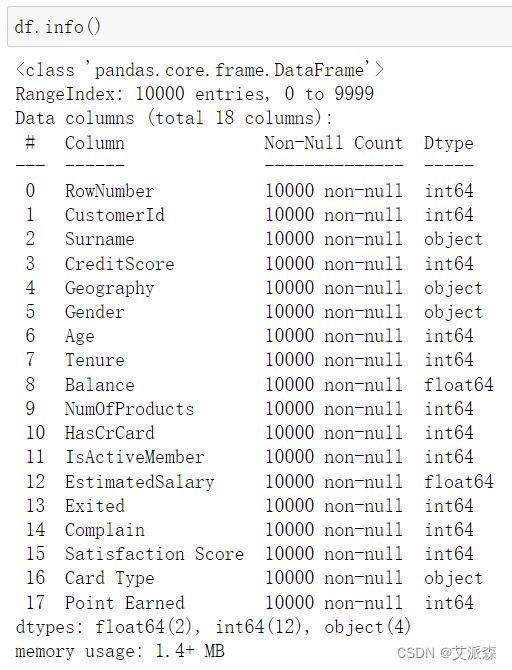
从基本信息中,我们发现了各变量都不存在缺失值
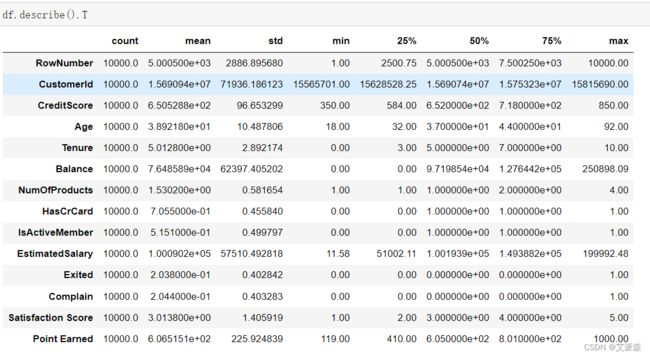
查看数值型变量的描述性统计
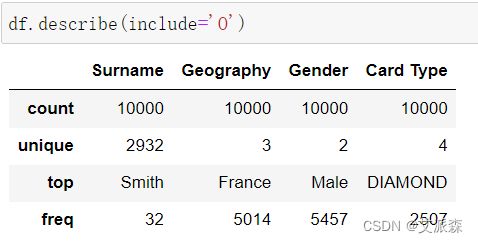
查看非数值型变量的描述性统计
4.2数据预处理
前面我们发现了数据不存在缺失值,现在使用any来检测数据是否存在重复值
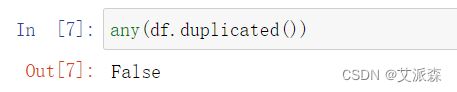
结果为False,说明数据集不存在重复值,也就不需要进行处理。
4.3探索性数据分析
4.3.1流失客户比例
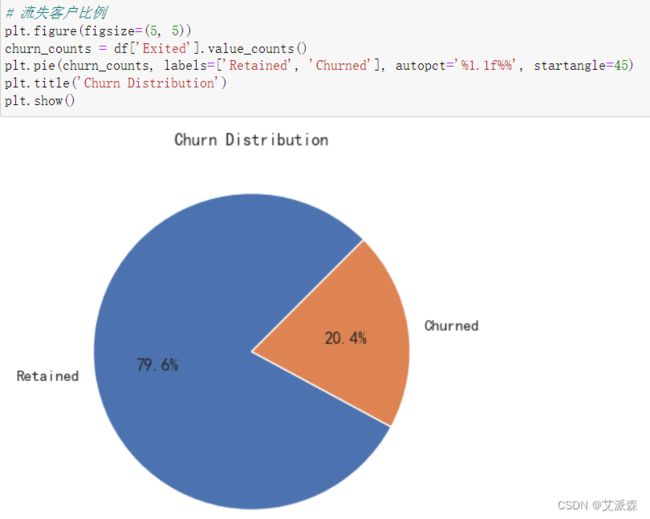
从结果看出,流失客户占比为20%,流失比例还是较高的。
4.3.2性别对客户流失率的影响
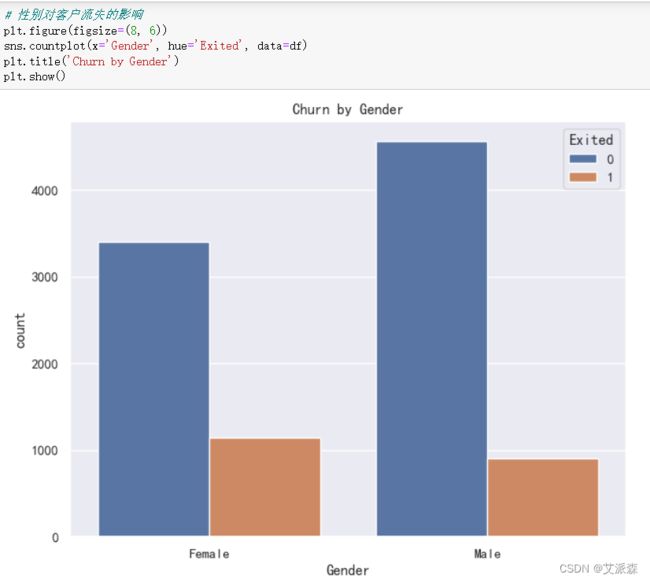
从结果发现性别对于流失率似乎没有什么影响。
4.3.3年龄对流失率的影响
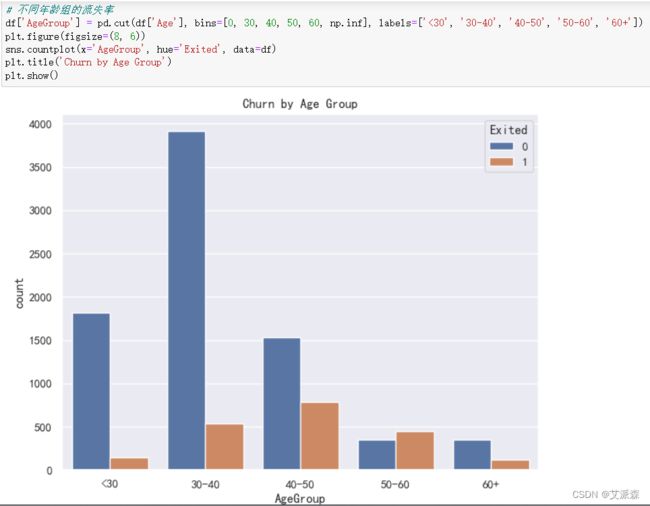
50-60岁的顾客流失最多,其次是40-50岁的顾客,主要流失客户都为中老年人。
4.3.4产品数量对流失率的影响
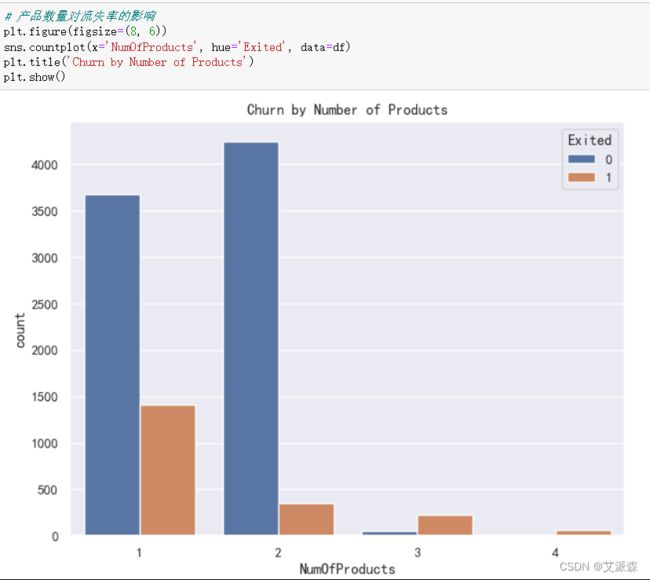
客户持有的产品数量会影响客户的流失。拥有较少产品的客户可能不太可能流失,而拥有更多产品的客户可能有更高的流失率。需要进一步的分析来了解具体的关系。
4.3.5地理因素对流失率的影响
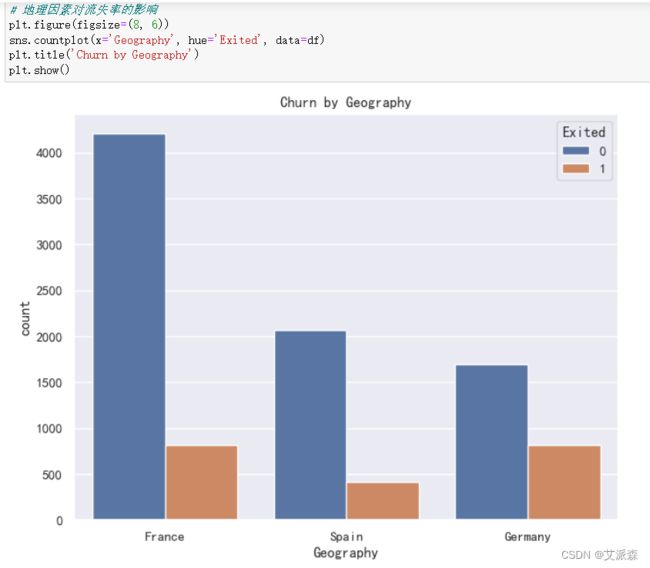
德国在拥有相对较高的流失客户数量方面表现突出。
4.3.6客户状态对流失率的影响
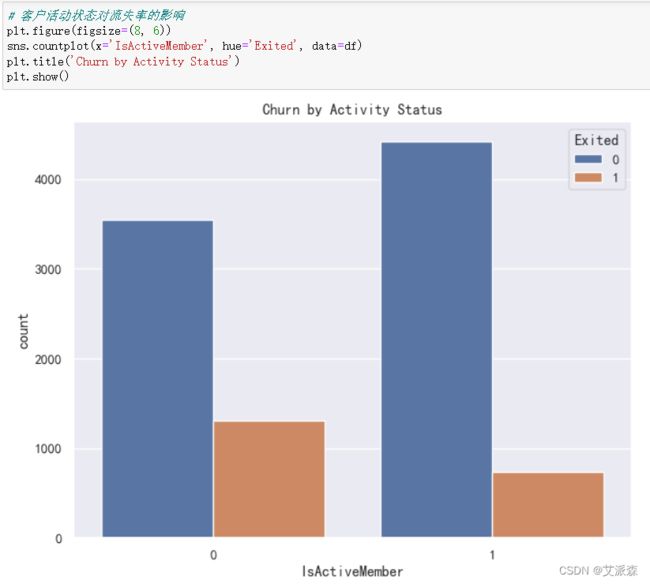
客户活动状态是另一个重要因素。与不活跃的会员相比,活跃会员的流失率似乎更低。这表明,参与和活跃的客户更有可能留在银行。
4.3.7相关关系分析

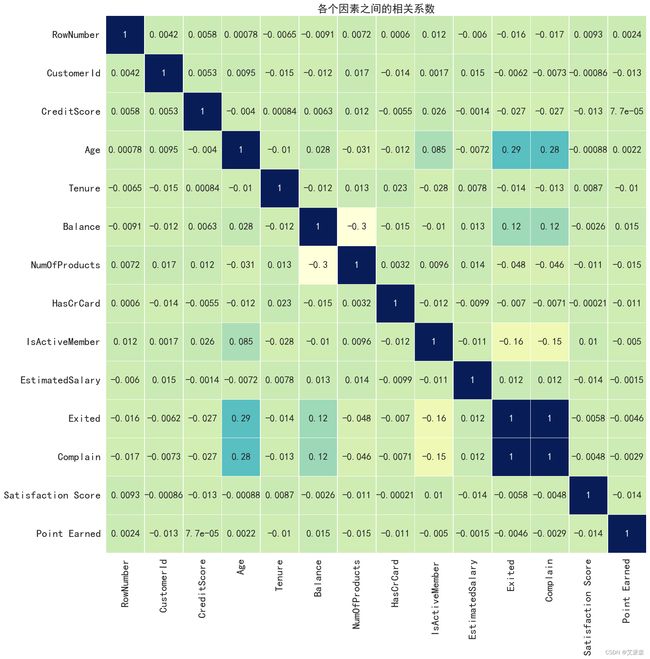
4.4特征工程
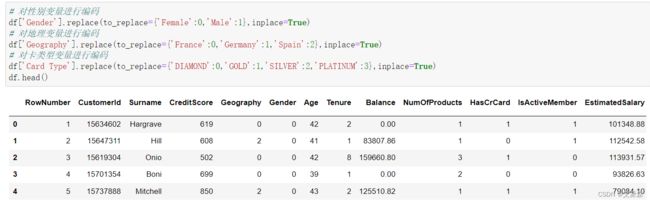
在建模之前,我们需要对非数值型变量进行编码处理,才能让模型识别,所以这里我们需要对性别、地理位置、卡类型进行编码处理。
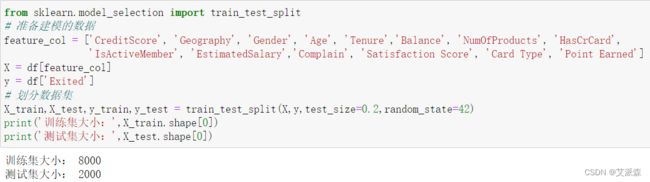
在编码完后,我们需要准备建模用到的数据,首先是特征挑选,由于原数据集前三列特征对建模没用,所以我们不选择它,然后使用Exited作为目标变量,最后拆分数据集为训练集和测试集并打印划分后的数据集大小。
4.5模型构建
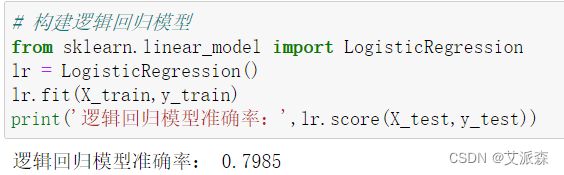
构建逻辑回归模型
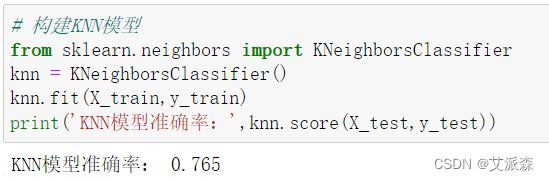
构建KNN模型
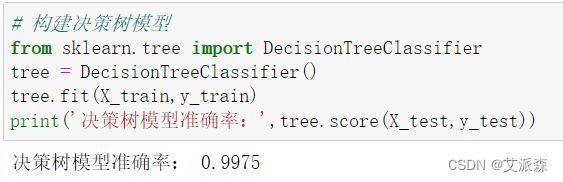
构建决策树模型
构建LightGBM模型,注意该模型需要pip安装
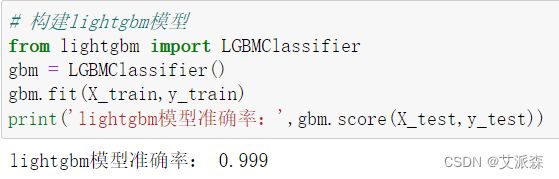
对比上面构建的4个模型,我们发现LightGBM模型的准确率最高,为0.999,几乎接近100%,所以我们选择其作为我们最终的模型。
4.6模型评估
对lightgbm模型进行评估,输出各项指标并作出ROC曲线
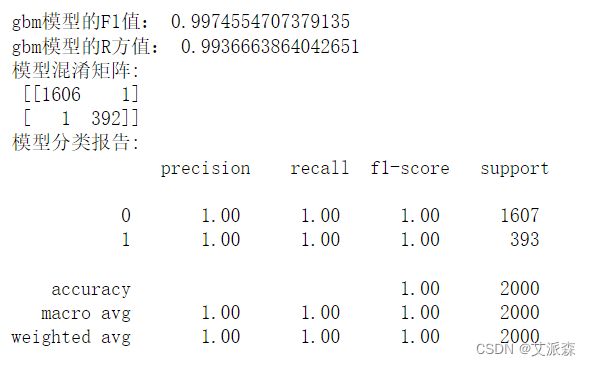
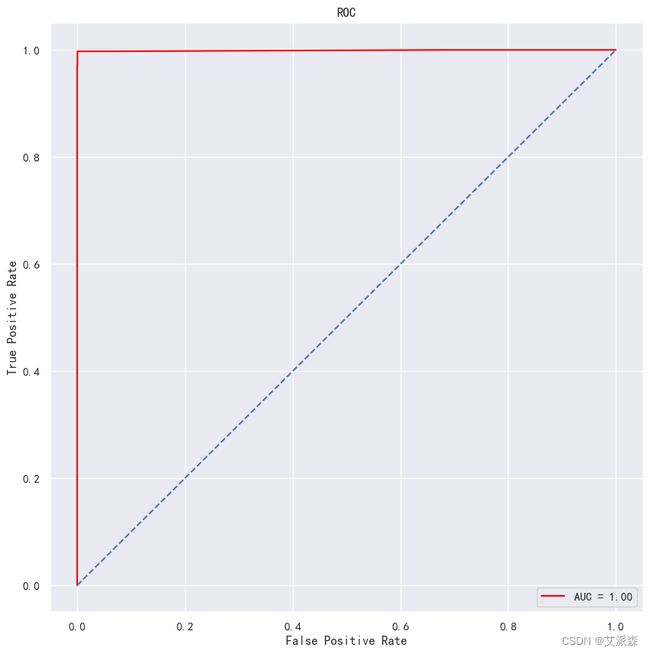
从各项指标均可看出模型效果非常不错!
4.7特征重要性评分

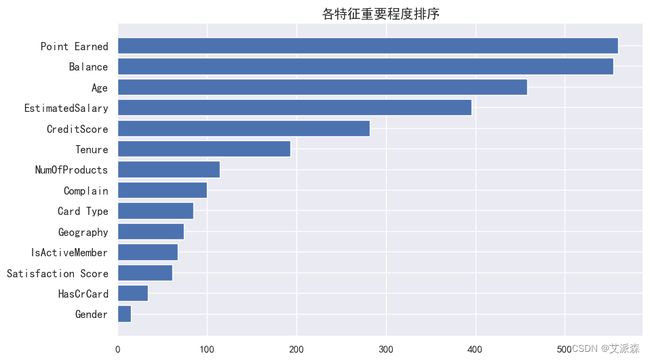
从特征重要性结果看出,客户使用信用卡赚取的积分、余额、年龄、估算薪资对于客户流失的影响程度最大,所以银行业需要针对这几项因素进行改善。
4.8模型预测
随机挑选10条预测结果进行检查,发现全部预测正确!
5.实验总结
本次实验中,我们首先使用可视化的方法探究了影响客户流失率的因素,接着通过构建模型,我们最终选择LightGBM算法来构建客户流失预测模型,模型的准确率接近100%,效果很好!最后我们也根据模型的重要性评分,找出了影响客户流失最重要的因素,银行需要针对这几个因素进行改善弥补,进而降低客户流失率。
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
import pandas as pd
import numpy as np
import warnings
import matplotlib.pylab as plt
import seaborn as sns
sns.set(font='SimHei')
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
warnings.filterwarnings('ignore')
df = pd.read_csv('Customer-Churn-Records.csv')
df.head()
df.shape
df.dtypes
df.info()
df.describe().T
df.describe(include='O')
any(df.duplicated())
# 流失客户比例
plt.figure(figsize=(5, 5))
churn_counts = df['Exited'].value_counts()
plt.pie(churn_counts, labels=['Retained', 'Churned'], autopct='%1.1f%%', startangle=45)
plt.title('Churn Distribution')
plt.show()
# 性别对客户流失的影响
plt.figure(figsize=(8, 6))
sns.countplot(x='Gender', hue='Exited', data=df)
plt.title('Churn by Gender')
plt.show()
看起来男女的流失率相对相似。
# 不同年龄组的流失率
df['AgeGroup'] = pd.cut(df['Age'], bins=[0, 30, 40, 50, 60, np.inf], labels=['<30', '30-40', '40-50', '50-60', '60+'])
plt.figure(figsize=(8, 6))
sns.countplot(x='AgeGroup', hue='Exited', data=df)
plt.title('Churn by Age Group')
plt.show()
50-60岁的顾客流失最多,其次是40-50岁的顾客。
# 产品数量对流失率的影响
plt.figure(figsize=(8, 6))
sns.countplot(x='NumOfProducts', hue='Exited', data=df)
plt.title('Churn by Number of Products')
plt.show()
客户持有的产品数量会影响客户的流失。拥有较少产品的客户可能不太可能流失,而拥有更多产品的客户可能有更高的流失率。需要进一步的分析来了解具体的关系。
# 地理因素对流失率的影响
plt.figure(figsize=(8, 6))
sns.countplot(x='Geography', hue='Exited', data=df)
plt.title('Churn by Geography')
plt.show()
德国在拥有相对较高的流失客户数量方面表现突出。
# 客户活动状态对流失率的影响
plt.figure(figsize=(8, 6))
sns.countplot(x='IsActiveMember', hue='Exited', data=df)
plt.title('Churn by Activity Status')
plt.show()
客户活动状态是另一个重要因素。与不活跃的会员相比,活跃会员的流失率似乎更低。这表明,参与和活跃的客户更有可能留在银行。
# 分析各因素之间的相关关系
fig = plt.figure(figsize=(18,18))
sns.heatmap(df.corr(),vmax=1,annot=True,linewidths=0.5,cbar=False,cmap='YlGnBu',annot_kws={'fontsize':18})
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
plt.title('各个因素之间的相关系数',fontsize=20)
plt.show()
# 对性别变量进行编码
df['Gender'].replace(to_replace={'Female':0,'Male':1},inplace=True)
# 对地理变量进行编码
df['Geography'].replace(to_replace={'France':0,'Germany':1,'Spain':2},inplace=True)
# 对卡类型变量进行编码
df['Card Type'].replace(to_replace={'DIAMOND':0,'GOLD':1,'SILVER':2,'PLATINUM':3},inplace=True)
df.head()
from sklearn.model_selection import train_test_split
# 准备建模的数据
feature_col = ['CreditScore', 'Geography', 'Gender', 'Age', 'Tenure','Balance', 'NumOfProducts', 'HasCrCard',
'IsActiveMember', 'EstimatedSalary','Complain', 'Satisfaction Score', 'Card Type', 'Point Earned']
X = df[feature_col]
y = df['Exited']
# 划分数据集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
print('训练集大小:',X_train.shape[0])
print('测试集大小:',X_test.shape[0])
# 构建逻辑回归模型
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train,y_train)
print('逻辑回归模型准确率:',lr.score(X_test,y_test))
# 构建KNN模型
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X_train,y_train)
print('KNN模型准确率:',knn.score(X_test,y_test))
# 构建决策树模型
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier()
tree.fit(X_train,y_train)
print('决策树模型准确率:',tree.score(X_test,y_test))
# 构建lightgbm模型
from lightgbm import LGBMClassifier
gbm = LGBMClassifier()
gbm.fit(X_train,y_train)
print('lightgbm模型准确率:',gbm.score(X_test,y_test))
from sklearn.metrics import f1_score,r2_score,confusion_matrix,classification_report,auc,roc_curve
# 模型评估
y_pred = gbm.predict(X_test)
print('gbm模型的F1值:',f1_score(y_test,y_pred))
print('gbm模型的R方值:',r2_score(y_test,y_pred))
print('模型混淆矩阵:','\n',confusion_matrix(y_test,y_pred))
print('模型分类报告:','\n',classification_report(y_test,y_pred))
# 画出ROC曲线
y_prob = gbm.predict_proba(X_test)[:,1]
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, y_prob)
roc = auc(false_positive_rate, true_positive_rate)
plt.figure(figsize=(10,10))
plt.title('ROC')
plt.plot(false_positive_rate,true_positive_rate, color='red',label = 'AUC = %0.2f' % roc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],linestyle='--')
plt.axis('tight')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
# 特征重要性评分
feat_labels = X_train.columns[0:]
importances = gbm.feature_importances_
indices = np.argsort(importances)[::-1]
index_list = []
value_list = []
for f,j in zip(range(X_train.shape[1]),indices):
index_list.append(feat_labels[j])
value_list.append(importances[j])
plt.figure(figsize=(10,6))
plt.barh(index_list[::-1],value_list[::-1])
plt.yticks(fontsize=12)
plt.title('各特征重要程度排序',fontsize=14)
plt.show()
# 模型预测
res = pd.DataFrame()
res['真实值'] = y_test
res['预测值'] = y_pred
res.sample(10)