《C和指针》读书笔记(第八章 数组)
目录
- 0 内容简介
- 1. 一维数组
-
- 1.1 数组名
- 1.2 下标引用
- 1.3 指针与下标
- 1.4 指针的效率
- 1.5 数组和指针
- 1.6 作为函数参数的数组名
- 1.7 声明数组参数
- 1.8 初始化
- 1.9 不完整的初始化
- 1.10 自动计算数组长度
- 1.11 字符数组的初始化
- 2. 多维数组
-
- 2.1 存储顺序
- 2.2 数组名
- 2.3 下标
- 2.4 指向数组的指针
- 2.5 作为函数参数的多维数组
- 2.6 初始化
- 2.7 数组长度自动计算
- 3. 指针数组
- 4. 总结
0 内容简介
在C语言中,数组有着举足轻重的地位。而数组和指针千丝万缕的联系,也让其在求职,学习和工作中成为技术探讨的焦点。计算机编程语言群星璀璨,为何C语言数组在多年面试中的热度居高不下?它究竟有什么样的神奇魅力?今天我们就一起来探讨相关话题。
先来看看本篇的主要内容(章节编号与书中一致)。有一个宏观上的把握。
1. 一维数组
一维数组是最常见的数组,也是最常用的数组,在实际的开发中,为了便于迭代和阅读,有时会将多个数组拆分成多个一维数组。
1.1 数组名
一维数组的数组名是一个指针常量,指向数组的第一个元素,可以参考下面的程序:
#include 打印输出:

1.2 下标引用
除了优先级以外,下标引用和间接访问完全一致。可以参考下面的程序:
#include 打印输出:

从上面的程序可以看出,指针p此时指向了数组的第2个元素,所以p[-1]会指向数组的第一个元素。
1.3 指针与下标
指针与下标,都是访问数组元素的有效方式,然而下标绝不会比指针更有效率,但指针有时会比下标更有效率,因牵扯到底层指令,在此不做展开。
1.4 指针的效率
指针有时比下标更有效率,前提是它们被正确地使用。因牵扯到底层指令,在此不做展开。
1.5 数组和指针
数组和指针并不是相等的。在声明数组的时候,已经分配好了内存,而在声明指针的时候,只知道其指向的数据类型,并不知道指向的具体地址,或者是没有任何意义的地址。
比方说有下面两个声明:
int a[5];
int *p;
我们可以通过下面的程序进行验证
#include 打印输出:
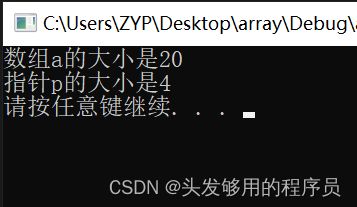
可以看到,在经过编译后,一个int类型的数据占4个字节,这个时候系统已经为数组分配好了所有的内存;而指针p,我们只知道其指向一个int类型的变量,然而并不知道具体指向了哪个变量。
1.6 作为函数参数的数组名
当一个数组名作为参数传递给一个函数时,传递给函数的是一份该指针的拷贝。函数如果进行了下标引用,实际上就是对这个指针执行间接访问操作,并且通过这种间接访问,函数可以访问和修改调用程序的数组元素。
可以参考如下的程序:
#include 1.7 声明数组参数
有一个有趣的问题,当我们把一个数组当做参数传递给函数的时候,正确的函数形参应该怎样的呢?应该声明为一个指针还是数组?
严格意义上来说都是正确的。可参考以下代码
#include 打印输出:
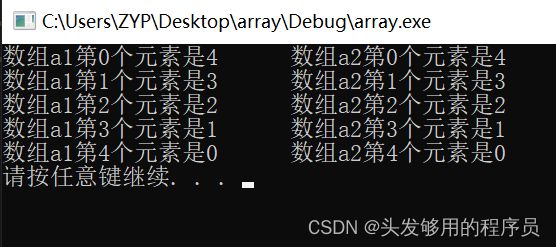
从上述例子可以看出,两种初始化从效果上来说是等同的。但是要说更加准确,应该是使用指针。因为实参实际上是个指针,而不是数组。
1.8 初始化
当数组的初始化局部于一个函数(或代码块)时,应该仔细考虑一下,在程序的执行流每次进入该函数(或代码块)时,每次对数组进行重新初始化是否值得。如果答案是否定的,就把数组声明为static,这样数组的初始化只需要在程序开始前执行一次。
关于static关键字,可以参考这篇文章:static关键字详解(C/C++)
1.9 不完整的初始化
所谓的不完整初始化,是指在数组初始化的时候,如果我们只对部分元素赋值,那么,剩下的元素会自动被赋值为0。可以参考下面的代码:
#include 打印输出:
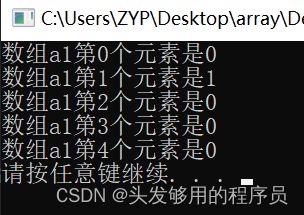
可以看到,没有初始化的几个元素,会被自动初始化为0,但这种自动初始化是有限制的,只能自动化地赋值后面的元素,不能赋值前面和中间的元素。
1.10 自动计算数组长度
如果在数组定义的时候就进行了初始化,那么不必指定数组长度,参考下面的例子:
#include 打印输出:
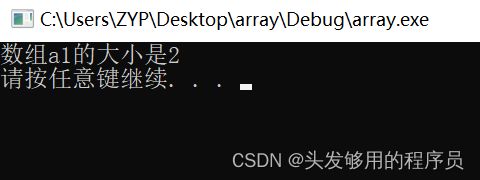
1.11 字符数组的初始化
字符数组有两种初始化方式,一种是常规的初始化,比如:
char a1[] = {'0','1'};
还有另一种方式,方便快捷,就是像字符串的定义方式类似:
char a2[] = "01";
其实这两者并不完全等同,在第二种初始化方式中,默认多了一个‘\0’,所以数组a2有3个元素。可以参考下面的测试代码:
#include 打印输出:
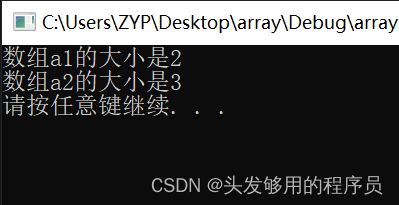
C 语言中并不存在字符串这个数据类型,而是使用字符数组来保存字符串。
2. 多维数组
多维数组是二维以及二维以上的数组,其中最常用的是二维数组。需要注意的是多维数组的元素存储顺序。以及元素的访问方式等。
当出现多维数组时,若再采用指针、或者指针和下标结合的方式去访问数组元素,将是稍微有点难度的问题。
2.1 存储顺序
在C语言中,多维数组的元素存储顺序按照最右边的下标率先变化的原则,称为行主序。
#include 打印输出:
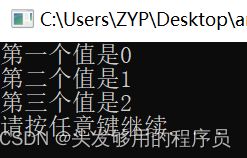
从上面的例子可以看出,当指针增长的时候,指向的是数组按照最右侧率先变化的顺序的元素。而当一行扫描结束的时候,会自动指向下一行,继续访问。
2.2 数组名
一维数组名的值是一个指针常量,指向一个元素,而多维数组第一维的元素是另一个数组。例如下面的声明:
int matrix[3][10];
可以看作是一个一维数组,包含了3个元素,每个元素是包含10个整形元素的数组。
或者可以看本文后续的章节,慢慢体会就自然会明白。
2.3 下标
如果要标识一个多维数组的某个元素,必须按照与数组声明时相同的顺序为每一维都提供一个下标,而且都单独位于一对方括号内。
#include 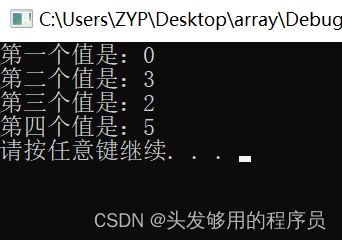
上面这个例子可能稍微有点难,按照指针移动的方向,仔细琢磨琢磨就可以想清楚。
2.4 指向数组的指针
指向多维(二维)数组的指针,应当如何定义呢?
int matrix[ROW][COL] = {{0,1,2},{3,4,5}};
int(*p)[COL] = matrix;
我们定义了一个指针p,指向了一个拥有COL个元素的数组。当把p与一个整数值相加时,该整数值首先根据整形值的长度进行调整,然后再执行加法。参考下面的例子。
#include 打印输出:

可以看到,直接利用p指针执行间接访问,肯定访问到的是第0行的第0个元素((*(*p)))。而在对p直接进行加1操作的时候,移动的是一个一维数组,然后再间接访问,所以得到的是数组第1行的第0个元素,也就是*(*(p + 1))这样的表达式;但如果间接访问一次之后在加1,则首先访问到的是二维数组的第0行,再加1自然就是第0行第一个元素,也就是上述(*(*p) + 1)表达式;最后一个表达式(*(*(p + 1) + 1))自然不言而喻了。
2.5 作为函数参数的多维数组
多维(二维)数组作为函数参数的时候,函数声明也与一维数组有所不同。有两种声明方式:
方式1:
void func1(int(*mat)[5])
方式2:
void func2(int mat[][5])
这两种声明方式,在效果上是等同的,两种都可以。从以下的程序中就可以证明这一点:
#include 打印输出:
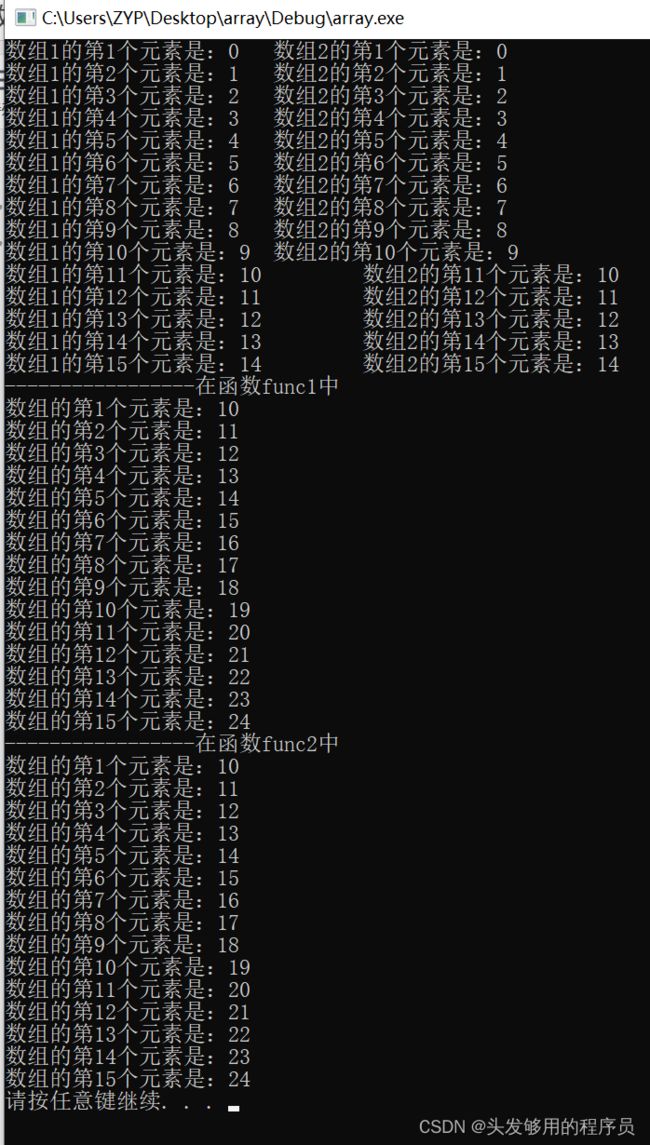
上述例子,定义了2个3*5的二维数组,进行相同的初始化,然后分别传到两个函数进行处理,这两个函数仅仅是形参的声明方式不一样。两个函数对原来数组的每个元素进行加10处理,得到了相同的结果。
所以,这两种声明方式在效果上是等同的。
2.6 初始化
多维(二维)数组的初始化有两种常见的形式。
- 一种是直接给每个元素赋储值
- 一种是用花括号隔开每个维度,并赋值
两种方式都是正确的,只是第二种有方式有两个好处:
- 利于阅读
- 方便初始化,每个子初始列表都可以省略尾部的几个值(不完整的初始化列表)。
参考下面的程序:
#include 打印输出:
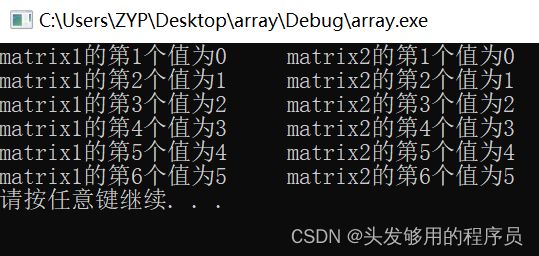
从上面的例子可以看出,这两种形式,从实现效果上来说,是一致的。
2.7 数组长度自动计算
在多维数组中,只有第1维才能根据初始化列表缺省地提供。剩下的几个维必须显式地写出,这样编译器就能推断出每个子数组维数的长度。例如:
#include 打印输出:

所以此时即使不写第1个维度的值,编译器在运行的时候,也可以根据初始化的值,以及花括号自动推断出来该维度的值。
3. 指针数组
指针数组很好理解,就是一个数组中的元素是指针,至于该指针指向什么样的数据,是由用户自己定义的。
比如下面这个例子,用指针数组存储了指向字符串(更严谨地说是字符数组)的指针。
#include 打印输出如下:
上述的例子中,用数组存储了若干个字符数组的指针数组。然后实现了多个字符串的匹配功能。
或者用二维数组也可以实现,但是需要提前知道最长字符串的大小。
4. 总结
数组与指针的关系,不可能一两句话说清楚,需要在具体开发中慢慢体会,理解。
数组的元素可以通过下标和指针两种方式进行访问,而指针往往更加高效。
指针数组在开发中也会比较常用,而数组元素也不仅仅只会指向字符串(字符数组),也有可能指向结构体变量等数据类型。
----------------------------------------------------------------end----------------------------------------------------------------