从零手写操作系统之RVOS任务同步和锁实现-07
从零手写操作系统之RVOS任务同步和锁实现-07
- 并发与同步
- 临界区、锁、死锁
- 自旋锁
-
- 1.0 版本
- 2.0 版本
-
- 原子指令
- 思路
- 测试
- 3.0 版本
-
- 测试
- 小结
- 其他同步技术
本系列参考: 学习开发一个RISC-V上的操作系统 - 汪辰 - 2021春 整理而来,主要作为xv6操作系统学习的一个前置基础。
RVOS是本课程基于RISC-V搭建的简易操作系统名称。
课程代码和环境搭建教程参考github仓库: https://github.com/plctlab/riscv-operating-system-mooc/blob/main/howto-run-with-ubuntu1804_zh.md
前置知识:
- RVOS环境搭建-01
- RVOS操作系统内存管理简单实现-02
- RVOS操作系统协作式多任务切换实现-03
- RISC-V 学习篇之特权架构下的中断异常处理
- 从零手写操作系统之RVOS外设中断实现-04
- 从零手写操作系统之RVOS硬件定时器-05
- 从零手写操作系统之RVOS抢占式多任务实现-06
并发与同步
并发 指多个控制流同时执行,可能存在下面几种情况
- 多处理器多任务
- 单处理器多任务
- 单处理器任务+中断
同步是为了保证在并行执行的环境中,各个控制流可以有效执行而采用的一种编程技术。
临界区、锁、死锁
- 临界区:在并发的程序执行环境中,所谓临界区(Critical Section)指的是一个会访问共享资源的指令片段,而且当这样的多个指令片段同时访问某个共享资源时可能会引发问题。
- 例如:一个共享设备或者一块共享存储内存
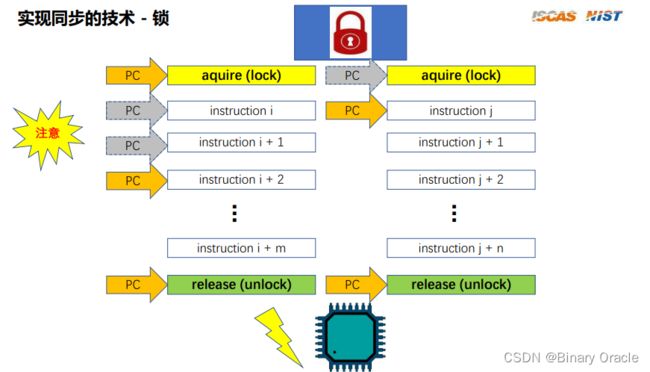
在并发环境下为了有效控制临界区的执行(同步),我们要做的是当有一个控制流进入临界区时,其他相关控制流必须 等待。
锁是一种最常见的用来实现同步的技术:
- 不可睡眠的锁
- 可睡眠的锁
可睡眠与不可睡眠的主要区别在于指令流获取不到锁时,是进入等待挂起状态,还是不断轮询锁查看锁是否被释放,也就是我们常说的自旋锁
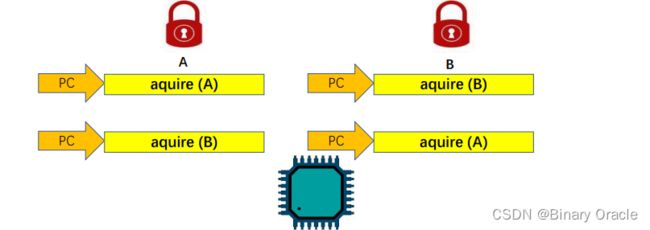
死锁(Deadlock)问题:
- 当控制流执行路径中会涉及多个锁,并且这些控制流执行路径获取(aquire)锁的顺序不同时就可能会发生死锁问题。
- 如何解决死锁:
- 调整获取(aquire)锁的顺序,譬如保持一致。
- 尽可能防止任务在持有一把锁的同时申请其它的锁。
- 尽可能少用锁,尽可能少并发。
自旋锁
1.0 版本

这段逻辑很简单,关键在于spin_lock函数中,获取不到锁,就死循环尝试。
上面这段代码存在什么问题?
- 让我们把spin_lock函数翻译为汇编代码看看
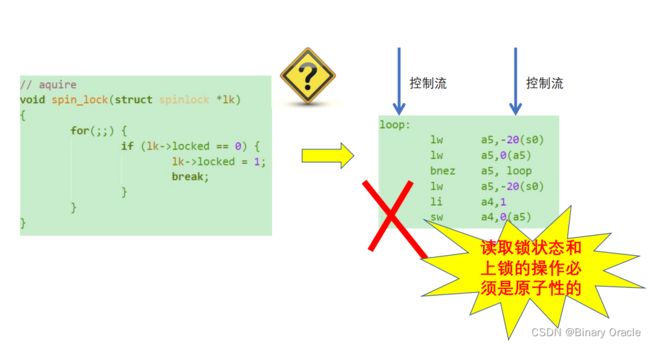
可以看到,问题在于我们读取锁状态和上锁的操作并非原子性的,所以在并发环境下,会产生不一致性问题。
2.0 版本
1.0版本的问题是,由于读取锁和上锁操作非原子性,所以在并发环境下,可能会存在多个指令流同时看见锁处于空闲状态,随后都重复上锁,也就是一把锁同时被多个任务持有。
为了解决这个问题,我们需要引入原子性指令,该指令由硬件提供支持。
原子指令
RV32A 有两种类型的原子操作:
- 内存原子操作(AMO)
- 加载保留/条件存储(load reserved / store conditional)
图 6.1 是 RV32A 扩展指令集的示意图,图 6.2 列出了它们的操作码和指令格式。
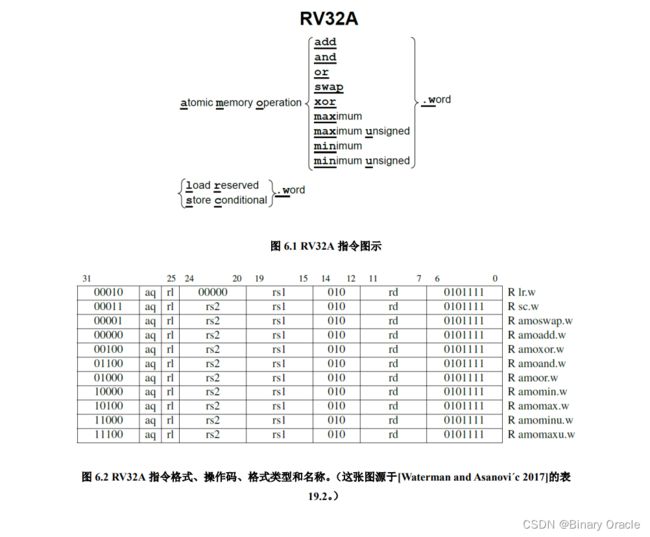
AMO 指令对内存中的操作数执行一个原子操作,并将目标寄存器设置为操作前的内存值。原子表示内存读写之间的过程不会被打断,内存值也不会被其它处理器修改。
AMO 和 LR/SC 指令要求内存地址对齐,因为保证跨 cache 行的原子读写的难度很大。
加载保留和条件存储保证了它们两条指令之间的操作的原子性。
- 加载保留读取一个内存字,存入目标寄存器中,并留下这个字的保留记录。
- 而如果条件存储的目标地址上存在保留记录,它就把字存入这个地址。
- 如果存入成功,它向目标寄存器中写入 0;否则写入一个非0 的错误代码。
为什么 RV32A 要提供两种原子操作呢?
- 因为实际中存在两种不同的使用场景。
编程语言的开发者会假定体系结构提供了原子的比较-交换(compare-and-swap)操作:
- 比较一个寄存器中的值和另一个寄存器中的内存地址指向的值,如果它们相等,将第三个寄
存器中的值和内存中的值进行交换。这是一条通用的同步原语,其它的同步操作可以以它为基础来完成。 - 尽管将这样一条指令加入 ISA 看起来十分有必要,它在一条指令中却需要 3 个源寄存器和 1 个目标寄存器。源操作数从两个增加到三个,会使得整数数据通路、控制逻辑和指令格式都变得复杂许多。
- 不过,加载保留和条件存储只需要两个源寄存器,用它们可以实现原子的比较交换。
使用加载保留和条件存储两个寄存器实现原子的比较交换案例:

a3存放内存中的值,a1存放当前内存中期望的值,a2希望设置到内存中的新值
- 首先,执行加载保留指令LR.W, 从地址寄存器a0指定的内存位置加载一个32位的字(word)到寄存器a3,并在加载期间保留该内存位置的锁定状态。
(将当前内存中的值加载到a3保存)
这条指令执行后,如果成功加载了内存数据并保留了锁定状态,则a3寄存器将存储加载的值。如果加载失败,a3寄存器的内容将保持不变。加载保留指令常用于原子操作和同步原语的实现,以确保在多线程或多核环境下的数据一致性。
- 如果加载成功,下面比较寄存器a3和寄存器a1的值,如果不相等,则进行一个相对偏移为80的条件跳转。
(也就是比较内存中的值和我们传入的值是否相等) - 然后,将寄存器a2的值存储到寄存器a0指定的内存位置中,但仅当寄存器a3的值等于内存位置中的值时才执行存储操作。
(确保内存中的值没有变化) - 将结果写入a3寄存器中,0表示成功,非0表示失败,如果写入失败,跳回到0地址处重试
使用amo原子指令,实现临界区保护案例:
a0可以看做是一个锁指针 lk->locked,其指向的内存中存放locked值

- 初始化锁: 将立即数1加载到寄存器t0中
- 尝试获取锁: 将内存位置a0的值加载到寄存器t1中,然后将寄存器t0的值存储到内存位置a0中
(不由分说,先上锁,然后把锁的原始值返回,由t1寄存器保存)
注意:
- 如果锁已经被任务A加上了,那么任务B此时通过amoswap交换拿到的锁值为1,此时我们设置锁为1是没有影响的,因为锁的值本来就为1
- 如果锁还没被加上,那么任务B此时通过amswap交换拿到的锁值为0,此时我们设置锁为1相当于任务A抢到了锁
- 获取锁失败,则进行重试: 如果t1不为0,则跳到地址4处重试
(如果当前内存中locked值不为0,说明锁已经被其他任务加上了,那么重新尝试获取锁)
注意:
- 对于上面第一种情况而言,由于t1寄存器保存的锁值不为0,说明抢锁失败,需要重试
- 对于上面第二种情况而言,由于t1寄存器保存的锁值为0,说抢锁成功,继续往下执行临界区代码
- 释放锁: 将内存位置a0处的值设置为0
(与x0寄存器做交换,等同于置零,向x0写入是没有意义的,最终表达意思即为: 释放锁)
另外还提供 AMO 指令的原因是,它们在多处理器系统中拥有比加载保留/条件存储更好的可扩展性,例如可以用它们来实现高效的归约。
AMO 指令在于 I/O 设备通信时也很有用,可以实现总线事务的原子读写。这种原子性可以简化设备驱动,并提高 I/O 性能。
思路
经过上面原子指令的介绍,想必各位也知道如何对1.0版本的漏洞进行改进了,下面给出代码:
typedef struct{
int locked;
} spinlock;
int spin_lock(spinlock *lk)
{
while(__sync_lock_test_and_set(&lk->locked,1)!=0);
return 0;
}
int spin_unlock(spinlock *lk)
{
lk->locked=0;
return 0;
}
_sync_lock_test_and_set是c编程库提供的一个原子操作函数,常用于多线程编程中实现互斥锁(mutex)的功能,这个函数在不同的编程语言和平台上可能会有不同的实现方式,但它的目的是原子地测试并设置一个锁的状态。
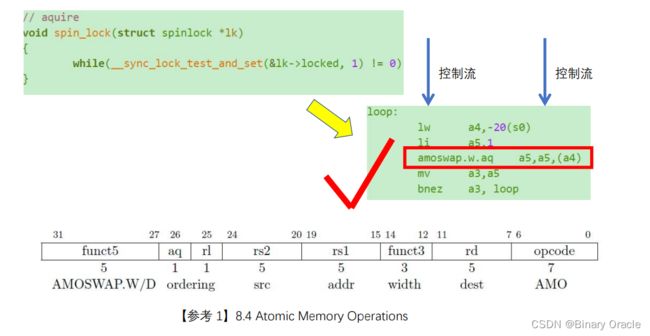
右边是该函数在RISC-V架构下的汇编实现,其利用了我们上面介绍的amoswap原子交换指令:
- 首先,使用a4寄存器存放指向lk->locked值的指针
- 然后将a5寄存器设置为1
- 原子交换a5寄存器和内存位置a4处的值,也就是locked的值
- 将a5寄存器的值赋值给a3
- 判断a3寄存器是否不为0,如果满足条件,就跳到loop处重新执行该流程
上面的流程简单而言就是:
- 获取锁的当前值,同时将锁进行锁定
- 通过锁的当前值,判断锁是否已经被抢占,如果被抢占了,那么上面的锁定其实没有影响,则进入重试阶段
- 如果还没有被抢占,则上面的锁定生效
- 执行临界区代码
- 释放锁
测试
在user.c文件中,我们针对user_task0进行代码改造,来测试对临界区加锁运行的效果:
我们期望的是通过加锁,来确保任务0中五个语句的输出总体来看是连续的
#include "os.h"
#define DELAY 4000
#define USE_LOCK
spinlock lk;
void user_task0(void)
{
uart_puts("Task 0: Created!\n");
while (1) {
#ifdef USE_LOCK
spin_lock(&lk);
#endif
uart_puts("Task 0: Begin ... \n");
for (int i = 0; i < 5; i++) {
uart_puts("Task 0: Running... \n");
task_delay(DELAY);
}
uart_puts("Task 0: End ... \n");
#ifdef USE_LOCK
spin_unlock(&lk);
task_yield();
#endif
}
}
void user_task1(void)
{
uart_puts("Task 1: Created!\n");
while (1) {
#ifdef USE_LOCK
spin_lock(&lk);
#endif
uart_puts("Task 1: Begin ... \n");
for (int i = 0; i < 5; i++) {
uart_puts("Task 1: Running... \n");
task_delay(DELAY);
}
uart_puts("Task 1: End ... \n");
#ifdef USE_LOCK
spin_unlock(&lk);
task_yield();
#endif
}
}
/* NOTICE: DON'T LOOP INFINITELY IN main() */
void os_main(void)
{
task_create(user_task0);
task_create(user_task1);
}
只有在任务0输出完五句后,任务1才会开始输出:

3.0 版本
2.0 版本引入的原子指令实现思路很好,但是对于本门课程而言,由于只使用到了单个hart, 并且导致读取锁和上锁操作非原子性的根本原因在于中断打断我们任务的执行。
所以,在单hart架构下,最简单的保护临界区代码并发安全的方法就是关中断。
#include "os.h"
int spin_lock()
{
//关闭全局中断
w_mstatus(r_mstatus() & ~MSTATUS_MIE);
return 0;
}
int spin_unlock()
{
//开启全局中断
w_mstatus(r_mstatus() | MSTATUS_MIE);
return 0;
}
测试
在user.c文件中,我们针对user_task0进行代码改造,来测试对临界区加锁和不加锁的两种运行效果:
我们期望的是通过加锁,来确保任务0中五个语句的输出总体来看是连续的
- 首先测试不加锁
//将USE_LOCK宏定义注释掉
//#define USE_LOCK
void user_task0(void)
{
uart_puts("Task 0: Created!\n");
while (1) {
//如果不存在USER_LOCK宏定义,那么下面的加锁和解锁代码都会在预处理环节被丢弃
#ifdef USE_LOCK
spin_lock();
#endif
uart_puts("Task 0: Begin ... \n");
for (int i = 0; i < 5; i++) {
uart_puts("Task 0: Running... \n");
task_delay(DELAY);
}
uart_puts("Task 0: End ... \n");
#ifdef USE_LOCK
spin_unlock();
#endif
}
}
void user_task1(void)
{
uart_puts("Task 1: Created!\n");
while (1) {
uart_puts("Task 1: Begin ... \n");
for (int i = 0; i < 5; i++) {
uart_puts("Task 1: Running... \n");
task_delay(DELAY);
}
uart_puts("Task 1: End ... \n");
}
}
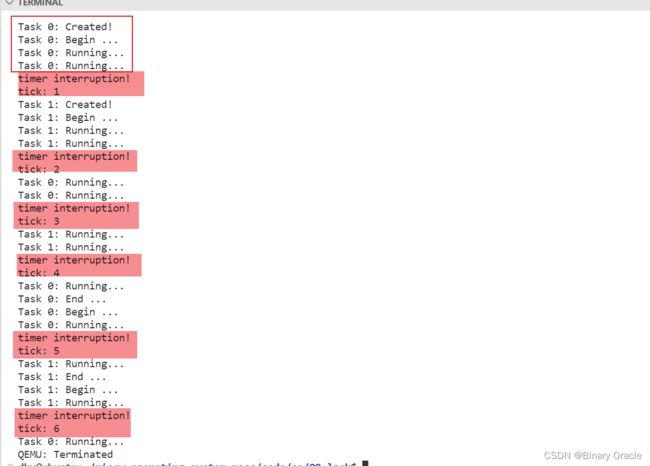
从输出结果可以观察到,任务0和任务1此时都没加锁,临界区代码总是会被中断打断:
- 测试加锁
#define USE_LOCK
void user_task0(void)
{
uart_puts("Task 0: Created!\n");
while (1) {
#ifdef USE_LOCK
spin_lock();
#endif
uart_puts("Task 0: Begin ... \n");
for (int i = 0; i < 5; i++) {
uart_puts("Task 0: Running... \n");
task_delay(DELAY);
}
uart_puts("Task 0: End ... \n");
#ifdef USE_LOCK
spin_unlock();
#endif
}
}
void user_task1(void)
{
uart_puts("Task 1: Created!\n");
while (1) {
uart_puts("Task 1: Begin ... \n");
for (int i = 0; i < 5; i++) {
uart_puts("Task 1: Running... \n");
task_delay(DELAY);
}
uart_puts("Task 1: End ... \n");
}
}
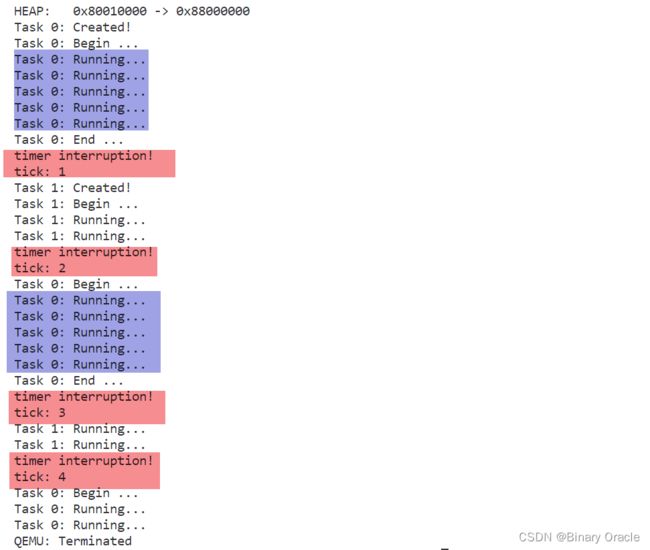
由于任务0的临界区代码都加上了锁,所以输出是连续的,没有受到中断影响:
小结
自旋锁的使用:
• 自旋锁可以防止多个任务同时进入临界区(critical region)
• 在自旋锁保护的临界区中不能执行长时间的操作
• 在自旋锁保护的临界区中不能主动放弃CPU
其他同步技术
