Julia两天极速入门学习笔记
目录
-
- 一. Julia 基础规则用法
- 二. Julia 数组和矩阵
- 三. Julia 元组
- 四. Julia 数据类型
- 五. 基本运算函数
- 六. 复数运算
- 七. 字符串
- 八. Julia 函数
- 九. 流程控制
- 十. 异常处理
- 十一. Julia 字典
- 十二. Julia set
- 十三. Julia Dates
- 十四. Julia IO
- 十五. Julia 宏
- 最后
一. Julia 基础规则用法
- 规则和python相同,区分大小写。
- 单行注释用 # ,多行注释用#= … =#。
二. Julia 数组和矩阵
- Julia数组格式与python声明格式相同,不同点在与 Julia数组的大小和类型不固定,可以在一个数组中容纳多个数据类型。
- 可以直接填入各种数值(Any),也可以先声明数组类型,再写入相应类型的数值。
例如 arr = Int64[1,2,3] 或者arr = String[“adadd”,“vbbbb”] - 数组可以利用Array提前声明类型及维度(修改默认的类型和维度)
- 数组还具有丰富的填充功能。fill!(A, x)—用值 x 填充数组 A。fill(x, dims…)—一个被值 x 填充的 Array。
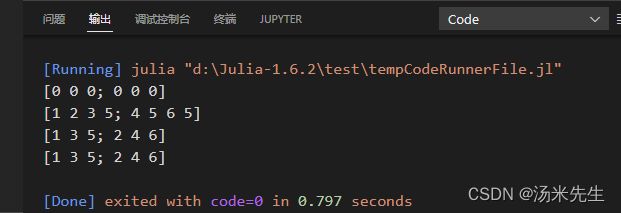
#声明两行三列
arr = Array{Int64}(undef,2,3)
println(arr)
#对arr变量进行修改
arr = [1 2 3;4 5 6]
println(arr)
arr = [[1;2] [3;4] [5;6]]
println(arr)
运行结果
4. 省略号也可以用来创建数组
arr1 = [1:10]
println(arr1)
arr1 = [1:10...]
println(arr1)

数组的生成:
- 使用collect函数和rang函数
range的形参有 sart,stop,length,step。
length表示数组元素的数量。
arr = collect(range(1,step=2,stop=10))
println(arr)
- 使用推导式和生成器创建数组(for循环)
arr = [n*2 for n in 1:10]
println(arr)

三. Julia 元组
元组和数组差不多,从表面上看,一个是(),一个是[],元组的分隔符用 , 。
相比较,Julia元组在用法上元组要方便许多。
元组的创建与合并,代码如下
#元组创建第一种方式,key和vulue分开写
key_shape = (:key1,:key2)
value_shape = ((1,2,3),(4,5,6))
item = NamedTuple{key_shape}(value_shape)
println(item)
println(item.key1)
#元组创建第二种方式,key和vulue一起写
item1 = (key3 = (100,200),key4 = (1,2,3),key5 = (0000))
println(item1)
println(item1.key3)
#合并元组
item1_all = merge(item,item1)
println(item1_all)
元组的函数运用
function testFunc(x;y=20,z)
println("x=$x,y=$y,z=$z")
end
item = (y=200,z=30)
testFunc(1;item...)
运行结果


需要注意,当两个元组的key值相同时,前面的key-value将会取代后面的值。而当某一个元组被当作参数传入函数中时,元组中的key会释放出来,当作函数的参数之一 ,当传入参数有冲突的时候,后出入的参数会覆盖掉前面传入的参数。
四. Julia 数据类型
Julia整数
c语言中的 long long int 也只是 -263~ 264-1
面对溢出现象使用big()函数
类型转换用 T(x)强转,或者使用 convert函数转换。

浮点类型


五. 基本运算函数
算数运算符
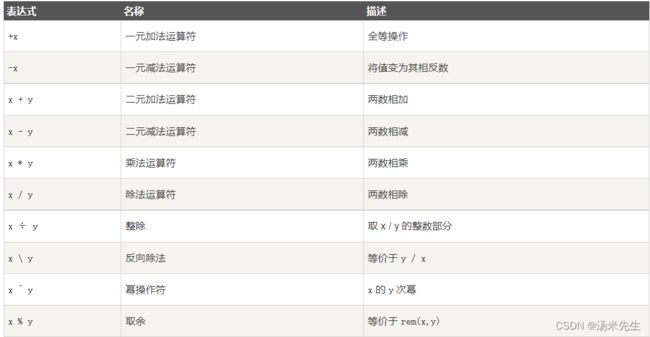
逻辑运算符

关系运算符
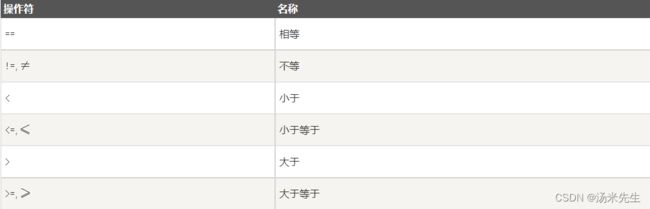
位运算符

赋值运算符

六. 复数运算
a = 2*(1+im)
println(real(a)) #取实
println(imag(a)) #取虚
println(a)
上方代码中的2*(1+im)为 复数,1为实数,im为虚数
七. 字符串
str = "hello"
println(str[begin])
println(str[end])
输出结果
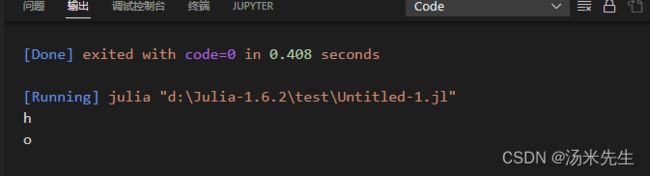
字符串相当于是一个集合,各个字母为一个元素 ,可以根据索引输出各个字符。
可以 通过SubString进行字符串截取
str1 = SubString(str,1,3)
得到输出结果 为hel
东西不多,直接上代码
str = "hello"
println(str[begin])
println(str[end])
# 按照索引截取字符串片段
str1 = SubString(str,1,3)
println(str1)
str2 = "world"
#合并插入字符串
str_all = string(str,',',str2)
println(str_all)
#$符号后的会被当成插入其值于字符串中的表达式
println("1+1=$(1+1)")
#查询字符,可以用first,也可以用last。
println(findfirst(isequal('e'),str_all))
#重复输出字符串
println(repeat("abc,",10))
#插入字符串
sstr = ["nike","tom","jek"]
println(join(sstr,"小明","小红"))
一些字符串函数 :
firstindex(str) - 给出可用来索引到 str 的最小(字节)索引(对字符串来说这总是 1,对于别的容器来说却不一定如此)。
lastindex(str) - 给出可用来索引到 str 的最大(字节)索引。
length(str) - str 中的字符个数。
length(str, i, j) - str 中从 i 到 j 的有效字符索引个数。
ncodeunits(str) - 字符串中代码单元(码元)的数目。
codeunit(str, i) - 给出在字符串 str 中索引为 i 的代码单元值。
thisind(str, i) - 给定一个字符串的任意索引,查找索引点所在的首个索引。
nextind(str, i, n=1) - 查找在索引 i 之后第 n 个字符的开头。
prevind(str, i, n=1) - 查找在索引 i 之前第 n 个字符的开始。
八. Julia 函数
函数普通用法
#递归函数
function test1(x)
x+=1
if x >10
return true
else
println(x)
return test1(x)
end
end
println(test1(1))
返回值有多个,使用元组
function test(i,j)
i+j,i+222
end
println(test(1,2))

#简易函数,当函数中只有一个表达式时可以用
f(x,y) = x+y
println(f(1,2))
#有意思的是,函数功能也能被传递
g = f
println(g(2,3))
#一些Unicode 字符也可以当作是函数名称,也就意味着汉字和一些其他国家的字体也能当作函数的名称
函数(x,y)=x+y
println(函数(2,2))
#也可以通过::来限制函数的返回值类型
函数1(x,y):: Int8 = x*y
println(typeof(函数1(2,2)))
#参数默认值,带默认值的参数写在后面,没有默认值的写在前面,顺序不对会报错,也可以将二者用;分割开,形成关键字函数,即在输入函数值的时候可以进行关键字KEY=value匹配,这样做的好处就是可以设置很多个形参,也不怕参值匹配错误。
function fun1(a,c;b=10)
println("a=$a,b=$b,c=$c")
end
fun1(1,2)
fun1(b=11,1,2)
#匿名函数,顾名思义匿名函数没有函数名字,但有函数的形参。以箭头->标注。
a=x->x*2
println(a)
#有参匿名函数
a1 = map(round,[1,2,3])
a2 = map(x->x*2,[1,2,3])
println(a1)
println(a2)
#无参匿名函数,主要用于延迟计算。
#get(()->time(),dict1,key)
#Julai语言还支持三目运算符,可嵌套
#Map通常会和匿名函数一起运用的,包含一个匿名函数,转换为一个新的集合。
#filter通常也和匿名函数一起运用,其中的匿名函数多为筛选条件,返回通过筛选条件的集合
arr = filter(x->x % 3 ==0,[1,2,3,4,5,6])
println(arr)
九. 流程控制
#流程控制
#begin...end使用,跟函数有些相似,执行一串命令集,返回最终结果.
z = begin
x=1
x+=1
x=x*2
end
println(z)
#链的表达,与上面原理相同
z = (x=1;x+=1;x*=2)
println(z)
#也可以二者结合使用
#条件表达式,for 与 while用法与python中的用法差异不大。
function func(x)
if (x>100)
println("大数")
elseif (x<10)
println("小数")
else
println("中数")
end
end
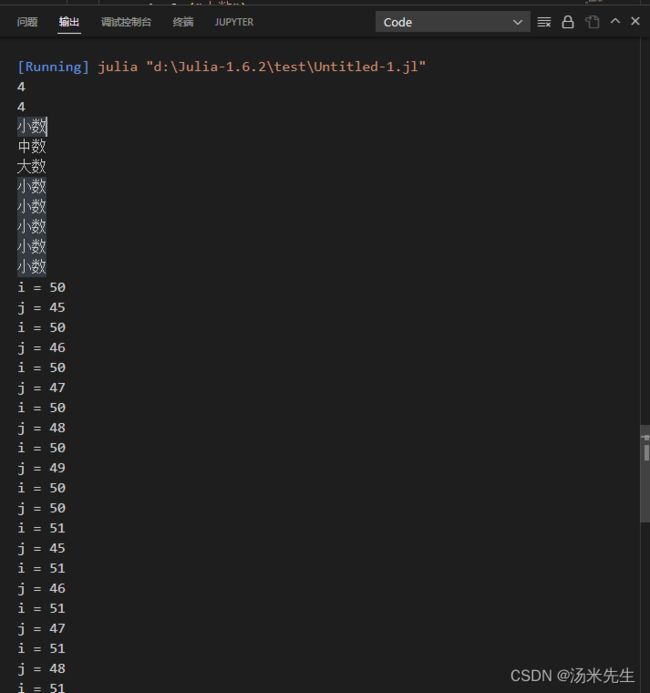
for i in [1,50,101]
func(i)
end
for i = 1:5
func(i)
end
#嵌套for循环
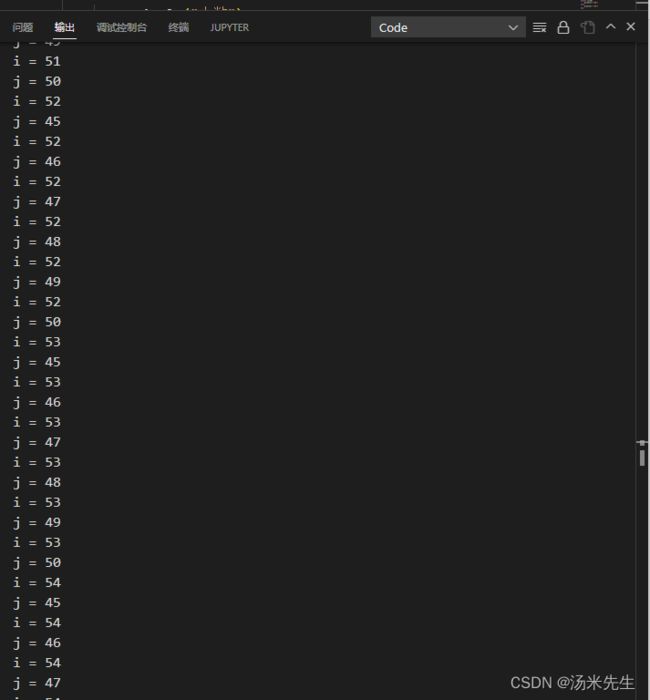
for i = 50:55,j=45:50
#println((i,j))
@show(i,j)
end
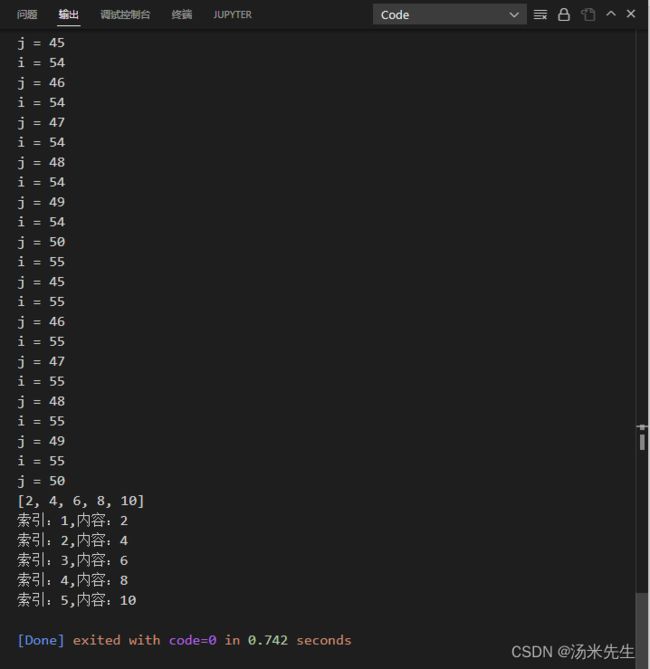
#推导式,有点像上面提到过的map,但是这个明显可以灵活运用。
arr = [i*2 for i in 1:5]
println(arr)
#花样遍历,可以遍历想要的内容,具体都有哪些属性,要看enumerate。
arr1 = ["a","b","c"]
for (index,value) in enumerate(arr)
println("索引:$index,内容:$value")
end
运行结果

十. 异常处理
#异常处理
#具有try-catch-finally用于捕捉异常,跟python用法相同。
try
a=a/0
catch e
println("出错了")
finally
println("结束")
end
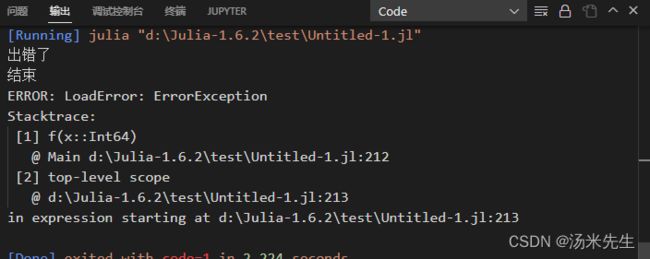
#也有throw 抛出异常的功能,但是这个抛出异常后还是会中断程序。
f(x)=x/0:throw(ErrorException)
f(1)
运行结果
十一. Julia 字典
#Julia字典和集合 与python中的字典和集合差不多
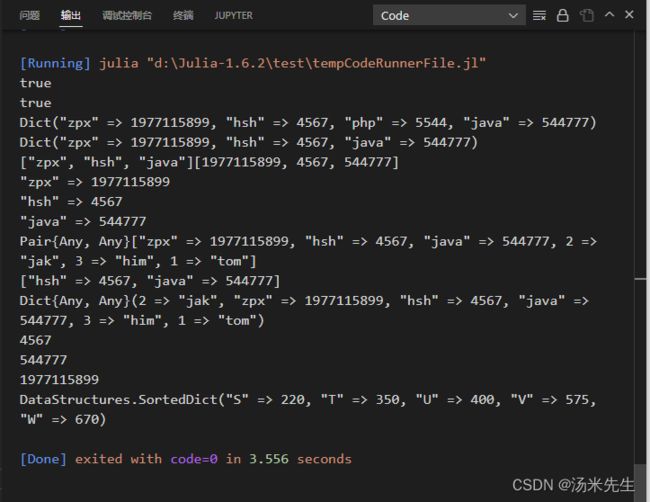
dict = Dict("zpx"=>1977115899,"hsh"=>4567,"php"=>5544)
#查询key
println(haskey(dict,"zpx")) #true and false
#查询key=>value
println(in(("zpx"=>1977115899),dict))
#添加key=>value
dict["java"]=544777
println(dict)
#删除
delete!(dict,"php")
println(dict)
#获取所有的key和value
println(keys(dict),values(dict))
#迭代
for d in dict
println(d)
end
#字典并集与差集
dict1 = Dict(1=>"tom",2=>"jak",3=>"him","zpx"=>1977115899)
println(union(dict,dict1)) #并
println(setdiff(dict,dict1)) #差
#合并字典,跟并集功能相同
println(merge(dict,dict1))
#排序
for value in sort(collect(values(dict)))
println(value)
end
#导入第三方库排序
import DataStructures
runoob_dict = DataStructures.SortedDict("S" => 220, "T" => 350, "U" => 400, "V" => 575, "W" => 670)
println(runoob_dict)
运行结果
十二. Julia set
#set集合,是一个无序列表,跟数列不同的是无序的即存入数据没有顺序,没有索引,部分方法跟字典相似
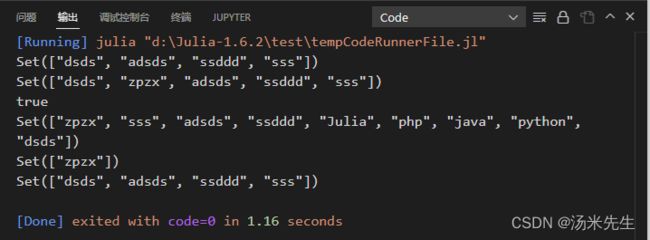
arrs = Set(["sss","dsds","adsds","ssddd"])
println(arrs)
#添加元素
push!(arrs,"zpzx")
println(arrs)
#查询元素
println(in("zpzx",arrs))
#求两个set集合的交、并、差集
arrs1 = Set(["java","php","python","Julia","zpzx"])
println(union(arrs,arrs1)) #并
println(intersect(arrs,arrs1)) #交
println(setdiff(arrs,arrs1))
运行结果
十三. Julia Dates
没啥特殊的,就是时间的格式什么的,代码在这可以测试看看
import Dates
println(Dates.Time(Dates.now()))
println(Dates.Date(2022,8,4))
println(Dates.today())
println(Dates.now(Dates.UTC))
date = Dates.DateTime("20220126 060000","yyyymmdd HHMMSS")
println(date)
println(time())
now = Dates.now()
println(now)
运行截图

十四. Julia IO
#文件写入
open("D:/Julia-1.6.2/test/test.txt","w") do io
write(io,"hello,world!\n你好,世界!")
end;
#文件读取
txt = open("test.txt")do file
read(file,String)
end
println(txt)
#逐行读取——readlines(中文会乱码)
file1 = open("test.txt")
txt1 = readlines(file1,keep=true)
close(file1)
println(txt1)
#逐行读取——eachline
open("test.txt") do file
for ln in eachline(file)
println("$(length(ln)),$(ln)")
end
end
#获取文件状态
for n in fieldnames(typeof(stat("test.txt")))
println(n,":",getfield(stat("test.txt"),n))
end
运行结果

十五. Julia 宏
宏提供了一种机制,可以将生成的代码包含在程序的最终主体中。宏在Julia的语法中有一个专门的字符 @ 。
macro sayhello(name)
return :(println("hello,",$name))
end
@sayhello("human")
运行结果

在这个例子中,编译器会把所有的 @sayhello 替换成:
:( println("Hello",$name) )
最后
本人是在菜鸟教程上学习的,本篇博客有部分代码与其相似,部分截图也来自于菜鸟教程,但不是照抄,写下了自己的一些理解感悟。省略了一些,只保留了经典简短的代码案例,希望可以帮到大家。