爬取豆瓣以及王者所有英雄信息实验报告(小生不才,记得点赞加关注)
- 实验任务
- 准备工作
- 学习网络爬虫相关知识和Python编程语法
- 学习爬虫需要调用的模块用法
- python爬虫练习实验
- 练习urllib、bs、re、xlwt库的调用(了解requests第三方库)
- 熟悉网络爬虫流程
- 实验内容
任务1(70分):爬取豆瓣电影Top250的基本信息,包括电影的名称(中英文名称分开或者存储为一列都可以)、豆瓣评分、评价数、电影链接,并自动存储生成excel表格。
url:豆瓣电影 Top 250
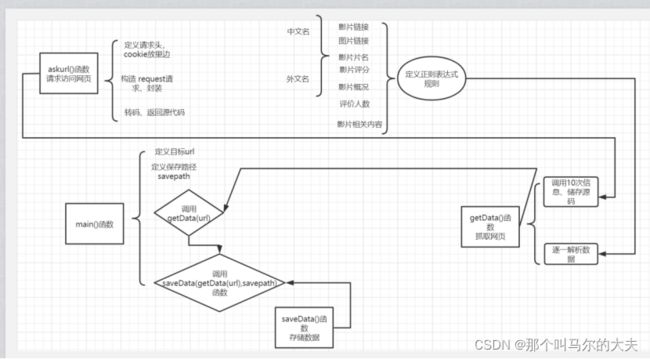
此实验需要定义四大模块:主函数模块、url请求模块、抓取数据模块、存储数据模块
其关联思路如下图:
实验代码:
1、导入必要的库
from bs4 import BeautifulSoup
import re
import urllib.request,urllib.error
import xlwt

#定义主函数模块
def main():
baseurl = "https://movie.douban.com/top250?start="
datalist= getData(baseurl)
savepath=".\\豆瓣电影top250.xls"
saveData(datalist,savepath)
# 定义url链接,调用getData函数,定义存储路径,存入数据。
#定义正则表达式
#获取链接的规则
findLink = re.compile(r'')
#影片图片的链接
findimagesrc= re.compile(r'
#影片篇名
findtitle= re.compile(r'(.*?)')
#影片评分
findrating= re.compile(r'')
#评价人数
findjugde= re.compile(r'(\d*)人评价')
#影片概况
findintro= re.compile(r'(.*)')
#找到影片的相关内容
findnr= re.compile(r' (.*?)
#爬取网页模块
def getData(baseurl):
datalist= []
for i in range(0,10):#调用获取页面信息的函数重复十次
url = baseurl + str(i*25)
html=askURL(url) #保存获取到的网页的源码
# 2逐一解析数据
soup= BeautifulSoup(html,"html.parser")
for item in soup.find_all("div",class_="item"):#查找符合要求的字符串,形成列表
# print(item)#测试查看电影全部信息
data=[]
item= str(item)
#获取影片详情链接
link= re.findall(findLink,item)[0]
data.append(link) # 添加链接
image= re.findall(findimagesrc,item)[0]
data.append(image)
titles = re.findall(findtitle, item) # 片名可能只有一个中文名,没有外国名
if (len(titles) == 2):
ctitle = titles[0] # 添加中文名
data.append(ctitle)
otitle = titles[1].replace("/", "") # 添加外国名
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findrating, item)[0]
data.append(rating) # 添加评分
jugdenum = re.findall(findjugde, item)[0]
data.append(jugdenum) # 添加评价人数
inq = re.findall(findintro, item)
if len(inq) != 0:
inq = inq[0].replace("。", "") # 去掉句号
data.append(inq)
else:
data.append(" ")
bd = re.findall(findnr, item)[0]
bd = re.sub('
bd = re.sub('/', ' ', bd)
data.append(bd.strip())
datalist.append(data) # 把处理好的一部电影信息添加进去
return datalist
#定义请求模块
def askURL(url):
head = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
request = urllib.request.Request(url,headers=head)
# 构造请求 封装
html=""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
请求头所需要的cookie信息:
#定义保存模块
def saveData(datalist,savepath):
print("爬取中...")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 创建workboook
sheet = book.add_sheet('豆瓣电影top250',cell_overwrite_ok=True) # 创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外文名","评分","评价数","概况",'相关信息')
for i in range(0,8):
sheet.write(0,i,col[i])
for i in range(0,250):
print("第%d条"%(i+1))
data= datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j])
book.save(savepath)#保存
main()
print("爬取完毕")
第一个for 循环:将八个标题名称录入excel表格;
第二个嵌套for循环:将250条信息逐行录入,其中,datalist列表中包含250个小列表,每个小列表都有这八个属性信息,故先从i=0开始,将datalist[0]元素赋给data,再逐步将data里八个元素数据填入到相应的位置,以此类推...
结果截图:

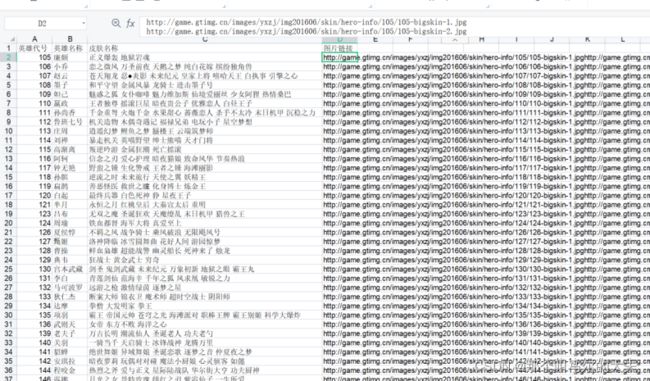
任务2(30分):将爬取到的王者荣耀所有英雄名称、皮肤名称与对应图片链接地址利用xlwt库,生成xls文件保存。
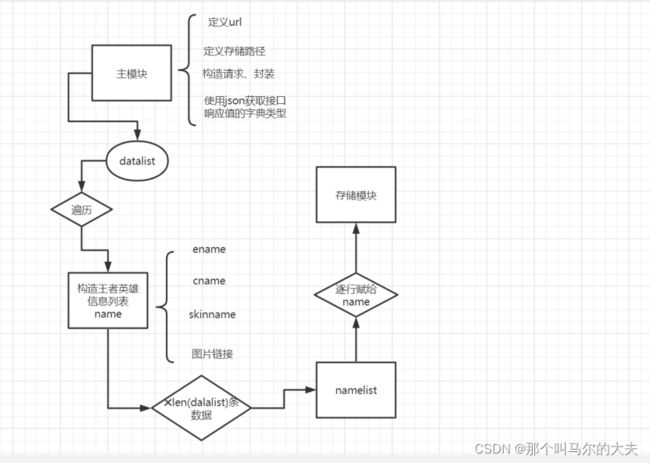
此实验需要定义四大模块:主模块、获取数据模块、构造英雄列表模块、存储数据模块
其关联思路如下图:
实验代码:
import requests
import xlwt
import pprint
#其中,pprint模块可使打印出来的数据结构更加完整,方便阅读。
#定义url链接、保存路径、封装请求
baseurl = "https://pvp.qq.com/web201605/js/herolist.json"
savepath="D:\\dataspace\\王者.xls"
headers={"user-agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Mobile Safari/537.36"}
responce= requests.get(url=baseurl,headers=headers)
datalist = responce.json()
print(datalist)
datalist = responce.json()
pprint.pprint(datalist)
#构造存放所有王者英雄信息列表
namelist = []
for i in datalist:
print('单件信息\n',i)
#构造存放单条王者英雄信息的列表
name= []
ename = i['ename'] #
cname = i['cname']
try:
skinname=i.get("skin_name","").split("|")
#由于这一列属性有bug,对skinname进行异常值处理
except Exception as e:
print(e)
name.append(ename)#把ename添加到name列表里
name.append(cname)#把cname添加到name列表里
#为了使最后录入表格的数据之间有间隙,便于查看,因此先对列表数据字符串化,用空格分隔
skinstr= " ".join(skinname)
name.append(skinstr)#把字符串化的皮肤名添加到name列表里
#定义存放图片url的列表
urllist=[]
for skinnum in range(1,len(skinname)+1):
skin_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + str(ename) + '/' + str(ename) + '-bigskin-' + str(skinnum) + '.jpg'
urllist.append(skin_url)
urlstr = "\n".join(urllist)
name.append(urlstr)#把字符串化的urlstr存放到name列表里
print(urllist)
print('字符串',urlstr)
namelist.append(name)#逐条添加王者英雄的信息
print('列表1\n',name)
# print('列表2\n',namelist)
#定义存储模块
def saveData(datalist,savepath):
print("爬取中...")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 创建workboook
sheet = book.add_sheet('王者荣耀图鉴',cell_overwrite_ok=True) # 创建工作表
col = ("英雄代号","英雄名称","皮肤名称","图片链接")
for i in range(0,4):
sheet.write(0,i,col[i])
for i in range(0,len(datalist)):
print("第%d条"%(i+1))
name= namelist[i]
for j in range(0,4):
sheet.write(i+1,j,name[j])
# sheet.write(i+1,1,skinname1[i])
# sheet.write(i + 1, 2,urllist[i])
book.save(savepath)#保存
saveData(datalist,savepath)
第一个for 循环:将四个标题名称录入excel表格;
第二个嵌套for循环:将所有英雄信息逐行录入,其中,datalist列表中包含所有英雄信息,每个小列表都表示一个英雄的信息(包括编号、英雄名称、皮肤名称以及图片链接)。故先从i=0开始,将namelist[0]元素赋给name,再逐步将name里四个元素数据填入到相应的位置,以此类推...
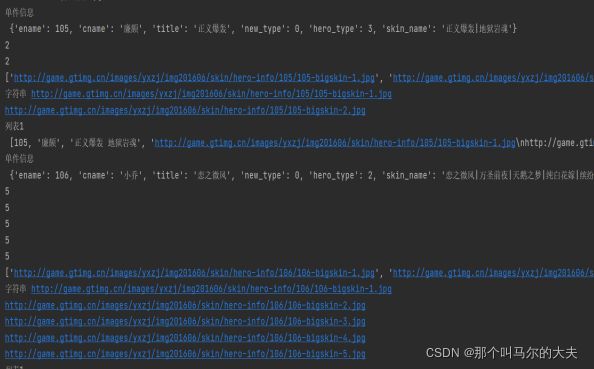
结果截图:


3.实验总结
(目的:记录实验中遇到的错误,分析为什么错,加深对新学函数与python语法的理解)
- 知识总结
- 网络爬虫相关知识
基本流程:

所需模块汇总:
urllib请求返回网页
urllib.request.open(url[,data,[timeout,[cafile,[capth[,cadefault,[context]]]]]])
可以打开HTTP(主要)、HTTPS、FTP、协议的URL
函数返回对象有三个额外的方法:
geturl() 返回response的url信息 常用与url重定向
info()返回response的基本信息
getcode()返回response的状态代码
re模块:正则表达式
规则:

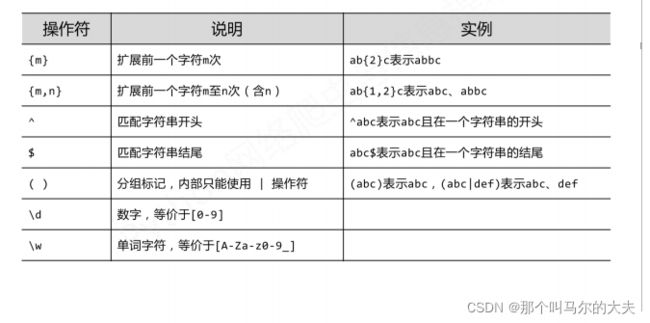
主要功能函数:


BeautifulSoup模块:
创建beautifulsoup4对象:
file = open(‘文件路径’, ‘rb’) 注:rb以二进制文件形式打开
html = file.read() #读取二进制文件
bs=BeautifulSoup(html,’html.parser’) #用自带的解析器来解析文件

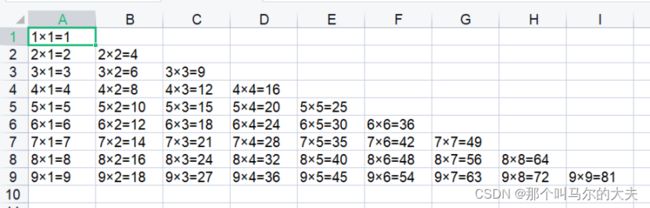
xlwt库的使用
代码:
import xlwt
workbook = xlwt.Workbook(encoding="utf-8")#创建workboook
worksheet =workbook.add_sheet('sheet1')#创建工作表
for i in range(0,9):
for j in range(0,i+1):
worksheet.write(i,j,format("%d×%d=%d"%(i+1,j+1,(i+1)*(j+1)))) #写入数据,第一行参数‘行’,第二个参数‘列’
workbook.save('student.xls')
结果截图:
- 遇到的问题及解决方法
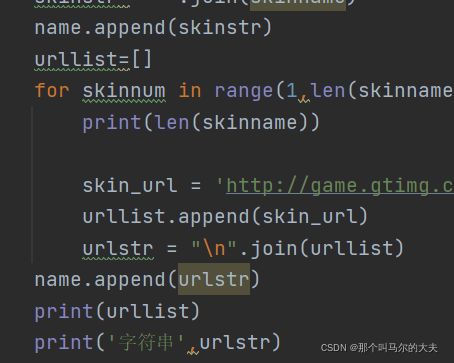
问题1:在任务二中,爬取皮肤名称时最后的excel中图片链接都是一样的。
解决:原因在于我开始将urllist存放链接的列表放在最外层了,导致for循环结束后,默认是最后一串的链接,所以将urllist放入第一层for循环里。
问题2:在任务二中,爬取皮肤名称时遇到key error 键值错误。
解决:原因是由于王者官网自身的bug,马超那一栏没有参数,故用try except语句排除故障。
