【人工智能】— 学习与机器学习、无/有监督学习、强化学习、学习表示
【人工智能】— 学习与机器学习、无/有监督学习、强化学习、学习表示
- 上一章
- Bayesian Networks
- 本章:观测学习
- 学习
- 学习元素
- 机器学习概论
-
- 机器学习对什么有用
- 自动语音识别
- 计算机视觉
- Information retrieval—信息检索
- 机器学习
-
- 机器学习:定义
- 电子邮件过滤问题
- 学习类型
-
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
- 在机器学习中表示“对象”
- 特征向量表示
- 关键要素
上一章
Bayesian Networks
贝叶斯网络提供了一个自然的表示方式,用于描述(因果引起的)条件独立性。
- 拓扑结构 + 条件概率表 = 联合分布的紧凑表示。
- 通常易于领域专家构建。
- 通过变量消除进行精确推断:
- 在有向无环图上的时间复杂度是多项式级别的,但在一般图上为 NP-hard。
- 空间复杂度与时间复杂度相同,非常敏感于拓扑结构。
- Naive Bayes 模型是一种特殊的贝叶斯网络。
本章:观测学习
观测学习是机器学习的一种方法,其目标是从数据中推断出未知的模型或概率分布。观测学习通常包括数据收集、选择假设空间、使用学习算法选择最优模型、评估和调整等步骤。它可以应用于多种任务,包括分类、回归、聚类、降维和异常检测等。观测学习的优点是可以自动学习模型,无需手动指定模型的形式或参数。常见的观测学习算法包括决策树、神经网络、支持向量机、朴素贝叶斯、最大熵模型和隐马尔可夫模型等。
学习
学习在人工智能和机器学习中扮演着重要的角色,它允许智能体从经验中提取知识和信息,并将其应用于新的任务和环境中。学习可以分为有监督学习、无监督学习和强化学习等不同类型,每种类型都有其独特的应用和算法。学习的重要性在于它可以使智能体适应不断变化的环境和任务,而不需要重新编写程序或重新设计系统。尽管学习有很多优点,但也存在一些挑战和限制,例如需要大量的数据和计算资源来训练模型,需要考虑数据偏差和过拟合等问题,还需要平衡探索和利用等问题。
学习元素
设计学习元素受以下因素的影响:
- 需要学习哪些性能元素的组成部分。
- 可用于学习这些组成部分的反馈信息是什么。
- 用于这些组成部分的表示方法是什么。
学习元素是机器学习系统的核心组成部分,包括算法、模型和数据等组成部分。学习元素的目的是让智能体能够从经验中学习知识和信息,以优化其性能和决策。学习元素的设计需要考虑到任务和环境,并根据具体情况进行调整和优化。反馈信息、算法和模型的选择、以及表示方法也是学习元素设计的重要因素。
机器学习概论
机器学习对什么有用
自动语音识别
现在,大多数语音识别器或翻译器都能学习——你使用它们越多,它们就越聪明
计算机视觉
例如物体、人脸和笔迹识别

Information retrieval—信息检索
阅读、消化和分类庞大的文本数据库对人类的网页检索来说太多了
(检索) 分类(分类) 聚类(聚类) 页面之间的关系
机器学习
机器学习是一个交叉学科的领域,涵盖了数学、计算机科学、工程学、统计学、认知科学、心理学、计算神经科学、经济学等领域。
其目的是通过利用数据来训练模型或算法,以便能够自动化地完成某些任务,并且能够从经验中不断改进自身的性能。
机器学习涉及的模型和算法包括线性回归、逻辑回归、决策树、支持向量机、神经网络、贝叶斯网络、隐马尔可夫模型、聚类、降维等。通过学习机器学习,可以掌握一些重要的概念、技术和工具,为今后的学习和实践打下基础。
机器学习:定义
Tom Mitchell(1998)提出了机器学习的定义:如果一个计算机程序在某个任务T上的性能,通过某种性能度量P,随着经验E的增加而提高,那么它就可以说是从经验E中学习到了任务T。
这个定义强调了机器学习的本质:通过从数据中获取知识和经验,来提高计算机程序在某些任务上的性能。其中,任务T可以是各种各样的,包括分类、回归、聚类、识别等;性能度量P可以是准确率、精确率、召回率、F1值、AUC值等;经验E可以是训练数据、验证数据、测试数据等。
电子邮件过滤问题
假设您的电子邮件程序观察您标记为垃圾邮件或非垃圾邮件的邮件,并基于此学习如何更好地过滤垃圾邮件。在这种情况下,任务T是什么?
A. 将电子邮件分类为垃圾邮件或非垃圾邮件。
B. 观察您标记为垃圾邮件或非垃圾邮件的邮件。
C. 正确分类为垃圾邮件/非垃圾邮件的电子邮件数量(或比例)。
D. 以上都不是——这不是一个机器学习问题。
答案:A. 将电子邮件分类为垃圾邮件或非垃圾邮件。
学习类型
假设有一个智能体或机器,它接收到一系列的感知输入: x 1 , x 2 , x 3 , x 4 , . . . x_1, x_2, x_3, x_4, ... x1,x2,x3,x4,...
监督学习
在监督学习中,机器还会收到所需的输出 y 1 , y 2 , . . . y_1, y_2, ... y1,y2,...,其目标是在给定新输入的情况下学习生成正确的输出。这被称为监督学习。在这种类型的学习中,机器被提供带有标签的示例,目标是学习一个将输入映射到输出的函数。常见的示例包括图像分类和语音识别。
无监督学习
在无监督学习中,没有给出所需的输出 y 1 , y 2 , . . . y_1, y_2, ... y1,y2,...,但智能体仍然希望构建一个可以用于推理、决策、预测和通信等目的的 x x x 模型。目标是发现输入数据中的模式、结构和关系。示例包括聚类、降维和异常检测。
半监督学习
半监督学习是监督学习和无监督学习的结合。在这种类型的学习中,机器被提供一些带标签的示例和一些无标签的示例。目标是学习一个可以推广到新的、未见过的示例的函数。当标记数据稀缺或昂贵时,这种类型的学习非常有用。
强化学习
强化学习是一种学习类型,智能体在与环境交互并获得奖励或惩罚的形式的反馈时进行学习。目标是学习一个策略,以在复杂、动态的环境中最大化预期的累积奖励。这种类型的学习在机器人、游戏和其他需要学习在复杂、动态环境中做出决策的应用程序中使用。
在机器学习中表示“对象”
- 一个例子或实例 x x x 代表一个特定的对象
- 通常用一个 d d d 维特征向量 x = ( x 1 , . . . , x d ) ∈ R d x = (x_1, . . . , x_d) \in \mathbb{R}^d x=(x1,...,xd)∈Rd 表示 x x x
- 每个维度称为特征或属性
- 特征可以是连续或离散的
- x x x 是特征空间中的一个点,维度为 d d d
- 对象的抽象表示。忽略任何其他方面(例如,两个具有相同体重和身高的人可能被认为是相同的)
特征向量表示
-
对于文本文档:
- 词汇表的大小为 d d d (大约100,000个词)
- “词袋模型”:计算每个词汇项的出现次数
- 通常会删除停用词:the、of、at、in等
- 特殊的“未知词汇”(OOV)条目可以捕获所有未知词汇
-
对于图像:
- 像素、颜色直方图等
- 通过卷积进行特征提取
-
对于软件:
- 执行概况:每行代码执行的次数
-
对于银行账户:
- 信用评级、余额、最近一天、一周、一个月、一年的存款次数、取款次数等
-
对于你和我:
- 医学检测1、检测2、检测3等
关键要素
-
数据
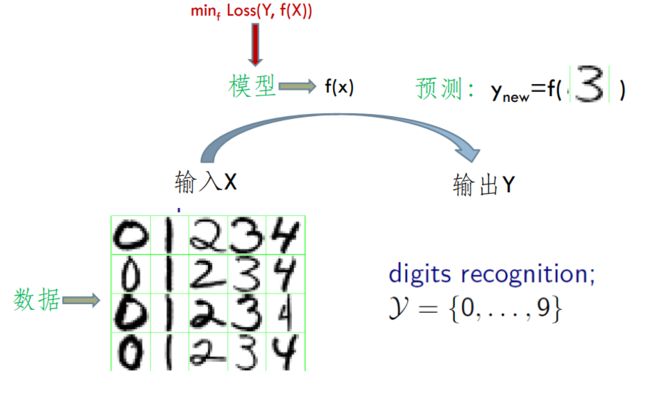
数据集 D D D 包含 N N N 个数据点:
D = { x 1 , x 2 , . . . , x N } D = \{x_1, x_2, ..., x_N\} D={x1,x2,...,xN} -
预测
我们通常希望基于观察到的数据集进行预测。
给定 D D D,我们能否预测 x N + 1 x_{N+1} xN+1? -
模型
为了进行预测,我们需要做一些假设。我们通常可以用模型的形式来表达这些假设,其中包含一些参数。
给定数据 D D D,我们从中学习模型参数 θ \theta θ,从而可以预测新的数据点。