Flink个人学习整理-算子篇(三)
Flink个人学习整理-算子篇(三)
转换算子
1、基本算子
【Map】
将数据流中的数据进行转换,形成新的数据流,进一出一
【RichMap】
具有生命周期方法:open()、close(),常用在跟其他数据库交互时,创建链接等
每个slot会被调用一次open,两次close,因为流关闭会触发cancel()方法,会再一次调用关闭
可以获取运行时上下文:GetruntimeContext,常用做状态编程
【FlatMap】
进一个,出0个或多个
【RichFlatMap】
同上
【Filter】
根据规则,将条件为true的数据保留,false的数据丢弃
【RichFilter】
同上
2、控流类
【Split】切割流,1.10标记过时,1.12废弃
【Select】选择流,1.12废弃
// 奇数一个流, 偶数一个流
SplitStream<Integer> splitStream = env
.socketTextStream("localhost", 9999)
.split(new OutputSelector<Integer>() {
@Override
public Iterable<String> select(Integer value) {
return value % 2 == 0
? Collections.singletonList("偶数")
: Collections.singletonList("奇数");
}
});
splitStream
.select("偶数")
.print("偶数");
splitStream
.select("奇数")
.print("奇数");
splitStream
.select("奇数","偶数")
.print("ALL")
env.execute();
【Connect】合流与【Union】合流
【Connect】可以实现左连接、右连接、全连接 (使用状态保存)
将两个不同来源的数据流进行连接,connect算子可以连接两个保持他们类型的数据流,两个数据流被connect之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。
1、两个流中存储的数据类型可以不同
2、只是机械的合并再一起,内部仍然是分离的
3、只能2个流进行connect,不能有第3个流参与
【Union】
对两个或者两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新DataStream
1、union之前两个流的类型必须是一样的,connect可以不一样
2、connect只能操作两个流,union可以操作多个
3、简单滚动聚合类
【sum、min、max、minBy、maxBy】
注:需要在分流后使用
如果流中存储的是POJO或者scala的样例类, 参数使用字段名
如果流中存储的是元组, 参数就是位置(基于0…)
【max / min】
只会改变你所计算的那个字段,其他字段以第一次输出的字段为主
【maxBy / minBy】只能一个字段
maxBy和minBy,会取计算字段相关的那一整条数据
maxBy和minBy可以指定当出现相同值的时候,其他字段是否取第一个。
当最大值相同时,true表示取第一个(默认),false表示取后面一个。
【Reduce】
合并当前的元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,可以自定义放回的数值
注:聚合后结果的类型, 必须和原来流中元素的类型保持一致!
4、process
process算子在很多类型的流上都可以调用
.process(new ProcessFunction<String, Tuple2<String,Integer>>() {
//生命周期方法
@Override
public void open(Configuration parameters) throws Exception {
}
@Override
public void processElement(String value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
// 状态编程:运行时上下文
RuntimeContext runtimeContext = getRuntimeContext();
for (String s : value.split(" ")) {
out.collect(Tuple2.of(s,1));
}
// 定时器
TimerService timerService = ctx.timerService();
// 注册定时器
timerService.registerEventTimeTimer(1010L);
// 获取当前的处理数据的时间
timerService.currentProcessingTime(); //处理时间
timerService.currentWatermark(); //事件时间
// 侧输出流
// ctx.output();
}
})
5、重分区
【KeyBy、Shuffle、Rebalance、Rescale、Global、Forward、Broadcast】
【KeyBy】
先按照key分组, 按照key的双重hash来选择后面的分区
【Shuffle】
随机发
【Rebalance】
轮询 上游跟下游全部的分区 先获取一个随机值,逐次+1 一个分区一个分区发
对流中的元素平均分布到每个区.当处理倾斜数据的时候, 进行性能优化
【Rescale】
上游跟下游进行均分 逐次+1 一个分区一个分区发,若无法均分 则 下游 0 号分区 会多分一个,而且rescale不需要通过网络
【Global】
数据全部返回到 0 号分区
【Forward】
要求前后并行度必须一致
【Broadcast】
广播 每一个并行度都有一份
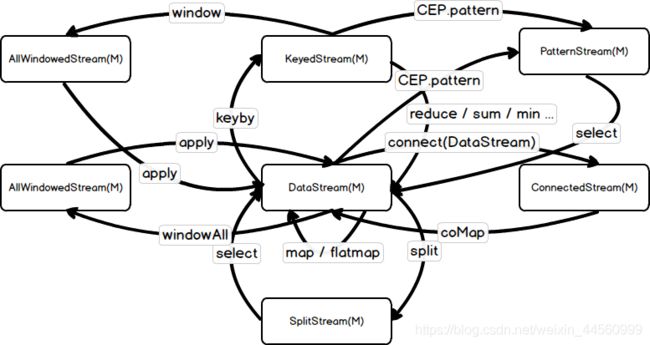
DataStream类型转换总结