人工智能学习笔记
目录
1 扫盲阶段
2. 数学基础知识
3. 机器学习基础知识
4. 回归
4.1. 观察数据
4.2. 拆分数据集
4.3. 特征表示法
4.4. 特征组合
4.5. 损失
4.6. 拟合程度
4.7. 正则化
4.8. 逻辑回归
5. 分类
6. 神经网络
初探人工智能知识,初步认识数据处理、分类、回归。
1 扫盲阶段
1.1 四类人员
从角色维度分为四类人员
- 了解者:大致了解理论,对结果具有判断能力。
- 开发者:了解理论,根据业务场景选择合适算法,进行机器学习方面的业务开发。
- 实现者:精通理论,实现具体机器学习算法。
- 理论提供者:提出机器学习算法理论。
1.2 人工智能分类
- 数据挖掘:对海量数据进行分析,最终得到一个数据分析的静态结果,通过图表进行体现。
- 机器学习:基于(海量)数据的训练,最终获得一个方程式。后续将新数据应用于方程式,得出一个预测结果。
1.3 海量数据作为基础
1.4 要素
| 模型 | 表示机器学习系统用于进行预测的数据元素之间的数学关系,特征与标签之间的数学关系。 |
| 策略 | 选择模型的依据,评估模型效果的依据,从而得到最优的业务函数. |
| 算法 | 训练过程中用到的算法,如梯度下降 |
1.5 有监督学习
使用已知正确答案的训练样本进行学习,发现数据模型,称为有监督学习。如分类、回归。
1.6 无监督学习
通过不包含任何正确答案的数据来进行预测。识别数据中有意义的模式。聚类技术是一种常用技术,划分自然分组的数据点。

2. 数学基础知识
使用数据矩阵(数据块)表现需要分析的数据。通过数据摘要、数据可视化清晰的表示数据。
2.1. 基础概念:
| 标量 | 单独一个数字,看作只有一个元素的一维数组。 |
| 向量 | 具有一个下标的数组,一维数组。 把向量看作空间中的点,每个元素代表不同坐标轴上的坐标。 |
| 矩阵 | 二维数组,两个索引确定一个元素。 |
| 张量 | 超过两维的多维数组。 |
2.2. 数值摘要、数据降维
涉及的数学概念
计算平均的方式
| 均数mean | sum(数据列)/数据列中记录个数 |
| 众数mode | 数据列中出现最多的数据 |
| 中位数median | 数据列排序后,处于中间位置的数据;偶数个数据时,取中间两数据的均值 |
| 分位数 | 数据列正序排序后,长度*(M/N)位置的数据。 |
评估数据点的离散程度
| 方差 deviation | |
| 标准差 standard deviation | 方差的平方根 |
| 表示离散程度的数字与样本数据点的数量级一致,更适合对数据样本形成感性认知。依然以上述10个点的CPU使用率数据为例,其方差约为41,而标准差则为6.4;两者相比较,标准差更适合人理解。 | |
| 表示离散程度的数字单位与样本数据的单位一致,更方便做后续的分析运算。 | |
| 在样本数据大致符合正态分布的情况下,标准差具有方便估算的特性:66.7%的数据点落在平均值前后1个标准差的范围内、95%的数据点落在平均值前后2个标准差的范围内,而99%的数据点将会落在平均值前后3个标准差的范围内。 | |
| 贝赛尔修正 | 方差和标准差,仅表示运算使用的数据集的离散程度;若想获取数据样本所对应的研究对象的离散程度,需要进行贝赛尔修正。 |
数值摘要
- 把数据表中的所有行(列)精简为几个数字
- 将数据表中几列摘要为一个数字,表示几列间的相关性
数据降维
将数据中很多列变为多列甚至一列,得到的列数据对于每行原数据都是唯一的。就是对每行就行数值摘要,构成新的数据表。
使用每一行数据的哪些属性来做降维呢?
- 最小值
- 第一个四分位数
- 中位数
- 均值
- 第三个四分位数
- 最大值
- 标准差
摘要统计
所有数据在某一列(某一属性)上的特点
2.3. 对数
指数的逆运算。自然对数,以e(近似2.718)为底数,符号为ln。常用对数,以10为底数,符号为log。
用途:
- 当数据非常大时,使用对数进行缩小;
- 当数非常小时,使用(对数+仿射变换)进行放大。例如计算权重。
3. 机器学习基础知识
3.1. 主要的术语
| 标签 | 预测的内容,即简单线性回归的y变量。例如未来小麦的价格、图片中动物类型、音频的含义等。 |
| 特征 | 对标签具有预测能力的数据。 输入的x变量,也可称为功能。一个机器学习项目中特征数量可多可少,可能数百万个,如x1、x2、....、xn。 |
| 样本 | 有标签样本:同时包含特征和标签的样本,用来训练模型。 无标签样本:只包含特征,不包含标签的样本,使用训练后的模型预测该样本的标签。 |
| 数据集 | 由许多样本组成。数据集的大小指样本的数量,多样性指样本的范围,良好的数据集既庞大且多样化。 |
| 模型 | 定义特征和模型之间的关系。 表示机器学习系统用于进行预测的数据元素之间的数学关系。 模型生命周期的两个阶段
|
| 回归 | 回归模型可预测连续值。如房子的价格、点击广告的可能性 |
| 分类 | 分类模型可预测离散值。如垃圾邮件、图片中动物种类 |
3.2. 分析的数据,使用数据矩阵(数据块)表现。
4. 回归
用已知数据集合去预测另一个数据集合,输出是纯粹的数字,数字不代表任何含义。例如:以过去每天的温度预测明天的温度。
4.1. 观察数据
用回归模型关联数值型数据前,先绘制散点图,这样能清晰判断回归模型的线性假设是否成立。
| 散点图 | 用两组数据构成多个坐标点,观察坐标点的分布,判断两个变量之间的某种关联或总结坐标点的分布模式。 |
| 散点图矩阵 | 可同时展示每两个特征之间的关系 |
| 三维散点图 |
4.2. 拆分数据集
| 训练集 | 用于训练模型 |
| 验证集 | 用于验证训练出的多个模型并选择出效果好的模型,降低了过拟合的几率。 |
| 测试集 | 用于检测模型。 |
由图示直观展示不同数据集的作用:

4.3. 特征表示法
4.3.1. 特征工程
特征工程
代表的是一个过程,将原始数据转换为特征的实数向量,以便特征值乘以模型权重。

映射数值
原始数据是数字的,可能不需要特殊处理。

映射分类值
分类值维护一个词汇表,词汇表元素数量为矢量长度,index成对应关系。所以映射分类值得到一个二元向量:匹配到词汇,其对应向量的index元素设置为1;其他元素设置为0.
当单个值为1称为独热编码,多个值为1称为多热编码。有效为每个分类特征值创建布尔值变量,例如词汇A的二元值为1,则使用词汇A的权重。
当词汇矢量很长时,每次只有1或2个index为1,则效率低下。稀疏表示法,只存储非0值。[index]

4.3.2. 数据整理
为什么需要数据整理?
强制实现数据兼容性的转换,将非数值的特征转换为数值,将输入数据大小调整为固定大小。
有助于模型表现更好,文本功能的次元话,标准化的数值特征。
哪里进行数据整理?训练前转换、模型中转换。
如何转换数值数据?例如规范化和分桶。
规范化的意义:
将特征转换为相似的大小,提高性能、训练稳定性、收敛速度。强烈建议对涵盖范围的数字特征(年龄、薪资、人口)进行归一化。
规范化的方式:
| 扩展到某个范围 | 从其自然范围转换为标准范围。例如 数据满足条件:大致知道上下限、数据在范围内大致均匀分布。 例如适用于年龄;而薪资不适用,因为不是均匀分布。 |
| 剪辑 | 设置最大值或最小值以避免离散值,例如高于40度的温度都裁剪为40度。
|
| 对数缩放 | 少数值具有很多点,大多数值有很少点时。
|
| z-score | 公式 (x- u平均值)/标准差 不确定离散数据是否极端时,可以先采用该方式进行规范化。 |
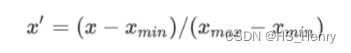


分桶,将(连续)数据转换为分类数据,需要明确如何设置边界以及要运用的分桶方式。
方式1:边界相等的区块,边界固定且包含相同的范围,如0-4,5-9,一些桶包含很多点,有些桶包含很少点。
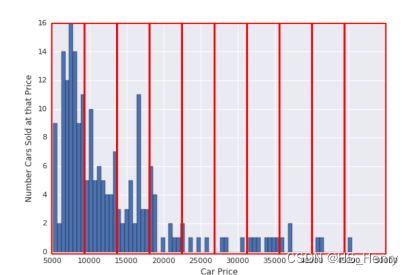
方式2:具有分位数边界的分桶,每个分桶的点数相同,边界不固定,可以包含窄范围或宽范围的值。
如何转换分类数据?
| 词汇表 | 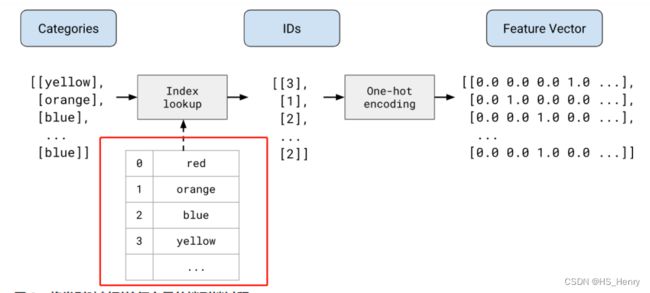 |
| OOV词外匹配 | 将某些离散值归入名为OOV的综合分类,不用浪费时间处理某种离散数值。 |
| 哈希 |
特征词汇表随着时间产生较大变化时,哈希有优势,但是存在冲突。 |

4.4. 特征组合
对与非线性问题,可以创建一个特征组合。特征组合指的是将两个或多个输入的特征相乘,对特征空间中的非线性特征进行编码后得到的合成特征。例如特征组合x3=x1*x2,产生一个线性公式y=b+w1*x1+w2*x2+w3*x3。
特征组合是一种学习高度复杂模型的高效策略。
4.5. 损失
损失,用于衡量模型预测结果的质量,判断预测的准确性。在训练过程和测试过程都会产生损失。
| 线性回归的损失函数是平方损失。 |
|
| 逻辑回归的损失函数是对数损失。 |
如何降低损失?
使用迭代法降低损失,迭代步骤如下:
- 模型中的变量设置初始值,例如模型y=b+wx,设置变量的初始值b=0,w=0.
- 输入特征样本,并根据损失函数计算损失
- 根据损失计算出新的变量值(例如b=0.1,w=0.05),并应用在模型中
- 重复2、3步骤,直到损失停止变化或变化非常缓慢,即模型收敛。
迭代过程的图示:
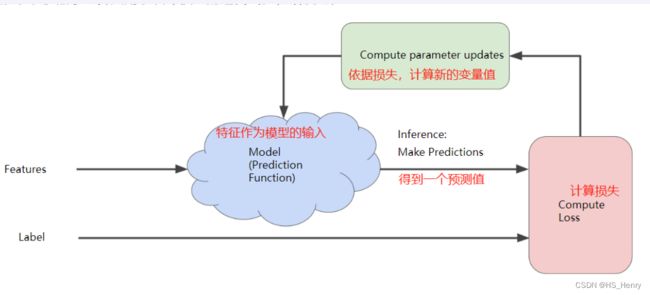
这里要着重描述下一个算法思想:梯度下降算法。
变量与损失之间的关系成碗形。通过一个点的梯度乘以学习速率(步长,超参数)确定下一个点,重复这个步骤,逐渐找到接近最小值的点。例如梯度是2.5,学习速率为0.01,则找距离上一个点0.025的下一个点。

学习速率过小,学习时间很长;学习速率过大,下一点永远在左右弹跳,无法收敛。金发姑娘学习速率与损失函数的平坦程度有关,可以较快的收敛。

4.6. 拟合程度
拟合过程就是模型的训练过程。拟合程度有两种极端情况,分别为过拟合和欠拟合。
| 过拟合 | 过于拟合训练数据,训练误差小,但测试误差大,泛化能力很差。 训练集准确性很高,但是无法很好的泛化到测试集。 |
| 欠拟合 | 模型过于简单,无法拟合训练数据 |
为了避免过拟合和欠拟合,可以采用交叉验证和正则化等措施。
交叉验证,即上述的验证集的作用。
正则化,指的是在拟合效果与模型复杂度之间进行权衡的过程,最终需要在“模型复杂度简单但拟合效果不够好的模型”与“模型复杂度高但拟合效果很好的模型”间进行选择。有助于使用复杂的模型描述数据中隐藏的复杂模式,又不至于过拟合。
影响拟合程度的因素
- 模型是否够强大
- 正则化
- 训练时长
- 数据集是否全面
得到合适拟合程度的方式
- 正则化(L1、L2)
- 早停法
- 随机丢弃法
4.7. 正则化
通过调整并降低复杂模型的复杂度来防止过拟合,这种原则称为正则化。
损失项,衡量模型与数据的拟合度。正则项,衡量模型的复杂度。
正则化的效果为:最小化(损失项+正则项) 。
如何衡量模型复杂度呢?
方式1:模型中所有特征的权重的函数,如L2正则化。所有特征权重的平方的和。w1平方+w2平方+wn平方。绝对值高的特征权重 对 绝对值低的特征权重 复杂。
方式2:具有非零权重的特征总数的函数,如稀疏正则化L1。
| 当特征维度巨大时,最好可以将部分特征将为0,这样就可以删除这些特征。 |
| L2正则化只能让权重接近0,无法减少特征的数量. |
| L1正则化可以让模型中很多特征(信息缺乏的特征,也可能是信息丰富的特征)的权重为0,从而减少特征数量,降低了模型大小. |
| L2降低权重的平方,L1降低|权重|;L2的导数为2*权重,L2的倒数为常数k。L2导数的作用理解为每次移除权重的x%,权重只会接近0;L1导数的作用理解为每次权重减去一个常量,如果减法使权重从 +0.1 变为 -0.2,L1 便会将权重正好设置为 0。 |
4.8. 逻辑回归
逻辑回归是一种概率计算机制,将概率作为输出。
输出的使用方式
- 原样使用,例如预测狗在夜晚叫的概率,逻辑回归模型输出为0.05,则一年内叫的天数为0.05*365.
- 将输出映射为二元分类
逻辑回归如何确保输出值肯定在0-1之间?使用S型函数处理。
举例逻辑回归推断计算

逻辑回归的损失函数是对数损失。
可能选用的正则化方式
- L2
- 早停法,限制训练步数或学习速率,例如某种衡量指标达到某值时,停止迭代。
5. 分类
为了将逻辑回归的输出映射为二元类别,必须人为定义分类阈值、决策阈值。
对于两个类别的预测结果,人为决定阈值右侧正分类,阈值左侧为负分类。
假设二元分类为良性和恶性,认为决定良性作为负分类N,恶性作为正分类P。
- 预测良性,实际良性,称为真负值例。TN
- 预测良性,实际恶性,称为假负例。FN
- 预测恶性,实际恶性,称为真正例。TP
- 预测恶性,实际良性,称为假正例。FP

衡量标准:准确率、精准率、召回率。
准确率是指模型做出的正确预测所占的比例,(TN+TP)/(TN+TP+FN+FP)。
一个疑问:准确率0.91,代表分类效果好吗?
对于类别不平衡的数据集,即正类别标签和负类别标签的数量之间存在明显差异,准确率不能反映全面情况。
精准率,尝试回答 正例识别的正确比例是多少?TP/(TP+FP),上例为:0.5
召回率,正确识别的实际正例比例是多少?TP/(TP+FN),上例为:0.11
评估模型的效果,必须同时考虑精准率和召回率。调整阈值,会影响二者。二者之间是此消彼长的关系。
另一种使用概率方式,贝叶斯。
6. 神经网络
神经网络是构建非线性模型的一种方式。
组成部分
- 至少一组节点,按层分组,类似神经元
- 至少一组权重,每个神经网络层与下一层之间的连接
- 至少一组偏差,层中每个节点一个偏差
- 至少一个激活函数,用于转换每层中每个节点的输出,不同的层可以有不同的激活函数。
训练神经网络的最佳做法
| ReLU激活函数有助于防止梯度消失 | 靠近输入层可称为较低层,这些层的梯度可能变得非常小,逐渐消失,下降到0时,这些层的训练速度非常慢。所以要防止梯度消失 |
| 批量归一化有助于降低梯度下降,降低学习速率 | |
| 降低学习速率有助于方式ReLU单元死亡 | ReLU单元的加权总和为0,ReLU单元停滞。 |
| 丢弃正则化 | 随机为某个梯度步长随机在一个网络中丢弃单元激活。丢弃越多,正则化效果越强。0表示无丢弃正则化。1表示丢弃所有,模型无法学习任何信息。0-1之间的值更有用。 |
7. 机器学习过程
7.1. 问题构建
7.1.1. 确定机器学习是否为解决当前问题的正确方法?
需要了解问题:明确解决问题要达成的目标、判断ML是否为最佳方式、是否有数据集。
7.1.2. 用机器学习术语描述问题
定义理想成效和模型目标
- 理想成效,即功能的效果,如识别欺诈性交易。
- 模型目标,即预测什么,如预测是否持卡人进行交易。
选择合适的模型类型
分类模型可预测输入数据的类别,然后应用根据类别进行决策。
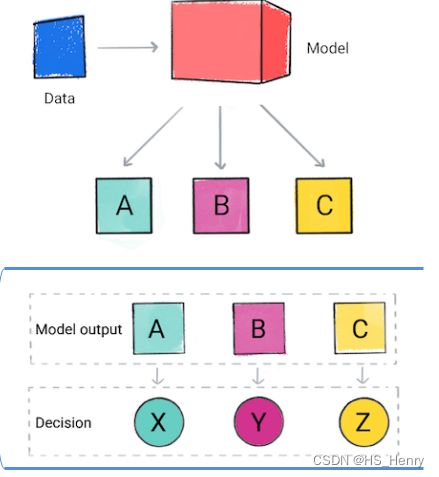
回归模型可预测输入数据放置在数字行中的位置,然后应用根据区间进行决策。

确定模型的输出
明确标签、代理标签
定义成效指标
不是对模型的评估,而是功能效果的衡量,如功能的使用率增加了20%,用户停留时间增加了20%。
7.2. 数据准备与特征工程
7.3. 测试与调试
开发流程\数据调试\模型调试\模型指标\模型优化。
至此,读者已经了解ML的冰山一角了,接下来可以进行实践。