【论文精读CVPR_2022】High-resolution Face Swapping via Latent Semantics Disentanglement
【论文精读CVPR_2022】High-resolution Face Swapping via Latent Semantics Disentanglement
- 0、前言
- Abstract
- 1. Introduction
- 2. Related Work
-
- 2.1 Face Swapping.
- 2.2 Generative Prior.
- 3. Method
-
- 3.1. Overview
- 3.2. Class-Specific Attributes Transfer
- 3.3. Background Transfer
- 3.4. Loss Functions
-
- 3.4.1 Adversarial loss.
- 3.4.2 Identity-preservation loss.
- 3.4.3 Landmark-alignment Loss.
- 3.4.4 Reconstruction Loss.
- 3.4.5 Style-transfer Loss.
- 3.4.6 Final Objective.
- 3.5. Video Face Swapping
-
- 3.5.1 Code Trajectory Constraint.
- 3.5.2 Flow Trajectory Constraint.
- 4. Experiments
-
- 4.1. Implementation Details
- 4.2. Datasets
- 4.3. Comparison on CelebA-HQ Dataset
-
- 4.3.1 Qualitative Comparison.
- 4.3.2 Quantitative Comparison.
- 4.4. Comparison on FaceForensics++ Dataset
- 4.5. Ablation Study
- 4.6. Face Swapping on High-resolution Videos
- 5. Conclusion and Discussions
-
- 5.1 Limitations.
- 5.2 Potential Negative Impact.
- 个人思考与总结

0、前言
Yangyang Xu, Bailin Deng, Junle Wang, Yanqing Jing, Jia Pan, Shengfeng He
论文地址:https://arxiv.org/abs/2203.15958
GitHub地址:https://github.com/cnnlstm/fslsd_hires
整个方法的Pipeline:
首先:我们有源面 x s x_s xs 和目标面 x t x_t xt输入预训练的 pSp 编码器,反转获得它们的 W + W+ W+潜在码 w s = ( g s , h s ) w_s = (g_s,h_s) ws=(gs,hs)和 w t = ( g t , h t ) w_t=(g_t,h_t) wt=(gt,ht),其中 g s , g t g_s,g_t gs,gt为结构部分, h s , h t h_s,h_t hs,ht为外观部分。(这里选前7个向量作为结构部分,其余为外观部分)
其次:将源面 x s x_s xs 和目标面 x t x_t xt输入需要训练的landmark encoder即 E l e ( ⋅ , ⋅ ) E_{le}(\cdot,\cdot) Ele(⋅,⋅),得到源地标 l s l_{s} ls和目标地标 l t l_{t} lt,从而通过 n → = E l e ( l s , l t ) \overrightarrow{{n}} = E_{le}(l_{s},l_{t}) n=Ele(ls,lt)得到 n → \overrightarrow{{n}} n(structure transfer latent direction)。然后通过改变源脸的结构部分潜码获得结果脸的结构潜码 g ^ s = g s + n → \widehat{g}_{s} = {g}_{s} + \overrightarrow{{n}} g s=gs+n,外观部分直接用目标脸的。故得到最终的结果脸潜码: w ^ s = C a t ( g ^ s , h t ) \widehat{w}_{s} = Cat(\widehat{g}_{s},{h}_{t}) w s=Cat(g s,ht)。其输入StyleGAN生成器,即可获得side-output swapped face y s y_{s} ys。
再者: y s y_{s} ys无法保证保留目标脸的背景属性,故这里只保留了其StyleGAN生成器的每个上采样块产生的特征 F s = { f s 0 , f s 1 , . . . f s N } F_s = \{f^0_s,f^1_s,...f^N_s\} Fs={fs0,fs1,...fsN},然后将目标面 x t x_t xt输入一个编码器 E t E_t Et也得到对应的特征 F t = { f t 0 , f s 1 , . . . f s N } F_t = \{f^0_t,f^1_s,...f^N_s\} Ft={ft0,fs1,...fsN},其中 f t i f^ i_t fti与 f s i f^i_s fsi具有相同的维度,表示相同分辨率下目标人脸图像的细节。最后我们只需将每个 f t i f^ i_t fti的内脸区域通过一个mask替换为 f s i f^i_s fsi的内脸区域即可。最终输出为 y f = D e c ( F t , F s , m t ) y_{f} = Dec(F_t,F_s,m_t) yf=Dec(Ft,Fs,mt)
然后:损失函数包括最终人脸 y f y_{f} yf与目标脸 x t x_t xt的对抗损失,常规的身份损失,对齐 y s y_{s} ys, y f y_{f} yf和 x t x_{t} xt的地标对齐损失,常规的重建损失(当 x s = x t x_s = x_t xs=xt时惩罚 y s 、 y f y_s、y_f ys、yf 和 x t x_t xt 之间的偏差),风格迁移损失(为外观属性迁移提供更强的指导)。
最后:这篇文章的还一个贡献是对于视频人脸交换的,其对潜在空间(限制结构潜码的变化)和图像空间(限制图像内容变化)施加两个时空约束。如果将换脸方法单独用于视频的每一帧,则会导致相邻帧之间的结果不一致,并导致诸如闪烁之类的伪影,此类伪影在高分辨率下尤为明显。(本文是第一个可行的高分辨率视频换脸方案)
Abstract
1.方法介绍:我们提出了一种新的高分辨率的人脸交换方法使用固有的先验知识inherent prior knowledge的预训练GAN模型。
2. 现有的问题:尽管之前的研究可以利用生成先验generative priors来产生高分辨率的结果,但它们的质量可能会受到潜在空间纠缠语义的影响。
3. 解决方法:我们利用生成器的渐进式特性,明确地解开潜在语义,从浅层导出结构属性,从深层导出外观属性。
通过引入地标驱动的结构转移潜方向,进一步分离了结构属性中的身份和姿态信息。
解纠缠的潜在代码产生丰富的生成特征,结合特征混合来产生合理的交换结果。
4. 视频贡献:我们进一步将我们的方法扩展到视频人脸交换,通过对潜在空间和图像空间施加两个时空约束。
5. 实验:大量实验表明,该方法在幻觉hallucination质量和一致性方面优于目前最先进的图像/视频人脸交换方法。
代码可以在https://github.com/cnnlstm/FSLSD_HiRes找到。
1. Introduction
人脸交换是指将源人脸图像中的身份信息传递到目标人脸图像中,同时保留目标图像中的面部表情、头部姿态、光照和背景等属性。
由于其广泛的潜在应用,如电脑游戏、特效、隐私保护等,受到了计算机视觉和图形界的广泛关注[13,22,41,42]。
【换脸介绍】
人脸交换的主要挑战是识别高度纠缠的目标人脸属性和源身份信息,以实现自然外观的交换。
早期的工作如[8]取代了人脸区域的像素,并依赖于源和目标在姿态和光照方面的相似性。
基于3D的方法[14,28,37]将3D模型拟合到人脸上,可以处理大的姿态变化,但拟合受环境影响较大,因此不稳定。
另一些著作引入了生成对抗网络(generative adversarial networks, GANs)来幻象目标属性[24,26,35]由于其强大的生成能力。
【换脸历史背景】
尽管已经取得了很大的进展,但由于端到端框架的压缩表示[7,26,34]、对抗训练[5]的不稳定性以及GPU内存大小的限制,现有的许多基于GAN的方法在高分辨率人脸上都不能很好地工作。
最近,Zhu等人[55]利用预先训练好的高分辨率GAN模型的固有先验知识,提出了在StyleGAN的潜在空间中进行高分辨率人脸交换的MegaFS[20,21]。
它学习将源图像和目标图像的反向潜码进行组合,并将融合后的代码直接输入StyleGAN生成器生成交换后的结果。
然而,由于身份和属性在潜空间中高度纠缠,在没有明确引导的情况下组装两个潜码并不能同时保证源身份的传递和目标属性的保留。
此外,潜伏码中嵌入的细微细节在组装后容易被稀释,因此,它们交换后的表面往往呈现模糊的外观,一些细微细节缺失(见图1c和图1f为例)。
为了获得潜在空间的语义解纠缠,我们认为人脸特征应该以特定类别的方式转移。
从直观上看,人脸的结构属性(如面部形状、姿势和表情)应该与外观属性(如光照和肤色)区别对待。
交换后的面孔在产生目标图像的外观属性时应保留源身份。
这样的分离处理需要在结构和外观特征之间进行适当的分解。
【端到端框架的压缩表示、对抗训练的不稳定性以及GPU内存大小的限制,现有的许多基于GAN的方法在高分辨率人脸上都不能很好地工作,而MegaFS的身份和属性在潜空间中高度纠缠,这往往使结果呈现模糊的外观与一些细微细节缺失】
本文对StyleGAN的潜在语义进行了研究。
StyleGAN是一个噪声到图像,粗到细的生成过程,我们利用它的渐进式本质来分解交换的关键因素,如姿势,表情和外观。
给定反向的源代码,我们通过推导结构转移潜方向来解耦结构(姿态和表情)属性与身份。
方向是由源和目标地标决定的,并作为一个潜在的空间操作来转移结构。
另一方面,外观属性是在更深的层中控制的。
因此,我们将目标的外观代码与深层结构传递的源代码进行重组。
通过这种方式,集成的潜在代码保留了来自源的身份属性,同时具有目标的外观和结构。
这个解开的潜在代码被输入到StyleGAN生成器,以产生生成特征。
这种丰富的先验知识在所有尺度上与目标特征进行聚合,有效地消除了明显的混合伪影。
【具体操作】
此外,我们将我们的模型扩展到视频人脸交换,其中我们从源人脸图像和目标人脸视频生成交换的人脸视频。
由于将我们的模型直接应用于每个视频帧会导致不连贯伪影,我们对解纠缠结构和外观语义施加了两个时空约束。
首先,我们要求交换面的帧间结构变化与目标面的变化保持一致。
这是通过在浅层(代表结构变化)的潜在偏移方面加强交换和目标面之间的相似性来实现的。
其次,我们对输出视频中相邻帧之间的图像内容变化采用线性假设。
这两个约束有效地保证了框架间的一致性。
在几个人脸交换方法的基准上进行的大量实验表明,与最先进的方法相比,本交换方法具有更好的性能。
据我们所知,这是第一个可行的高分辨率视频换脸方案。
【第一个可行的高分辨率视频换脸方案,施加了两个约束】
综上所述,我们的贡献有三个方面:
- 我们提出了一个高分辨率换脸的新框架。我们解开了一个预先训练的StyleGAN的潜在语义,使源身份的转移,同时保留目标的外观和结构。
- 我们定制了两个新的约束来加强交换面视频的一致性,包括一个限制相邻帧潜在码之间偏移量的代码轨迹约束,以及一个在RGB空间工作的流轨迹约束,以保证视频的平滑性。
- 在多个数据集上的实验展示了我们方法的最新结果,这可能会成为人脸伪造检测的新高分辨率测试用例。
2. Related Work
2.1 Face Swapping.
换脸一直是一个活跃的研究课题。
早期的作品如[8]只能处理相同姿势的主题。
基于3D的方法将3D模板与源和目标人脸相匹配,以更好地处理大的姿态变化[14,28,37]。
Face2Face[45]将双线性人脸模型与源人脸和目标人脸进行匹配,以传递表情,并通过额外的步骤合成逼真的嘴型。
然而,基于3D的方法不能处理像照明和样式这样的外观属性。
最近,许多作品都引入了用于换脸的GANs。
RSGAN[35]处理潜在空间中的面部和头发区域,并通过替换潜在表征进行交换。
同样,FSNet[34]对人脸区域和非人脸区域进行编码,形成不同的潜码。
FSGAN[36]同时进行人脸再现和交换。
最近,Faceshifter[26]分别对源身份和目标属性进行编码。
但由于对抗训练的不稳定,端到端框架的压缩表示等原因,它们都无法在高分辨率下交换人脸。最近,Naruniec等人的[33]交换人脸具有较高的分辨率,但他们的模型是特定于受试者的。
MegaFS[55]利用了预先训练的StyleGAN的先验知识[20,21]。
该算法将源和目标的人脸反转到潜伏空间,然后设计人脸转移块来组装潜伏码。
然而,身份和属性在潜在空间中纠缠不清,在没有明确引导的情况下组装两个潜在码是不够的。
相反,我们建议以一种特定于类的方式来传递属性。
【说明了现有方法的不足:基于3D的方法不能处理像照明和样式这样的外观属性,由于对抗训练的不稳定,端到端框架的压缩表示等原因,它们都无法在高分辨率下交换人脸,等】
2.2 Generative Prior.
生成模型在合成高质量图像方面显示出巨大的潜力[10,16,19 - 21]。
研究表明,预训练GAN的潜在空间编码了丰富的语义信息。
因此,许多作品利用生成模型中隐藏的先验知识进行语义编辑、图像翻译、超分辨率等[4、17、39、40、50、52]。
特别是,Gu等人[17]提出了一种GAN反演方法用于图像着色和语义编辑,而其他一些作品[11,31,54]使用预先训练的StyleGAN进行图像超分辨率。
最近,生成先验也被引入换脸。
除了MegaFS[55]外,Nitzan等人的[38]在潜在空间中通过全连接网络将属性从一张脸转移到另一张脸。
与这些工作不同的是,我们将目标属性以一种更详细的方式传递给源脸。
我们将属性分解为结构属性和外观属性,充分利用生成模型的可解性和可编辑性。
【生成先验,就是利用预训练模型StyleGAN】
3. Method
3.1. Overview
给定两幅高分辨率人脸图像,我们的目标是构造一幅包含源人脸 x s x_s xs的身份和目标人脸 x t x_t xt的姿态、表情、光照、背景等属性的人脸图像。
为此,我们首先使用StyleGAN生成器构造一个侧输出交换面,方法是在重用目标的外观属性的同时,在潜在空间中混合源和目标的结构属性(第3.2节)。
为了进一步传递目标人脸的背景,我们使用编码器从目标图像中生成多分辨率特征,并将其与StyleGAN生成器上采样块中的相应特征进行混合。
混合的特征被送入解码器,合成最终交换后的人脸图像(第3.3节)。
图2为我们的管道概述。
使用一组损失函数对网络进行训练,这些函数增强了所需的属性,如源身份和目标外观的保存(第3.4节)。
我们还将我们的方法扩展到视频人脸交换,使用额外的时空约束来加强一致性(第3.5节)。
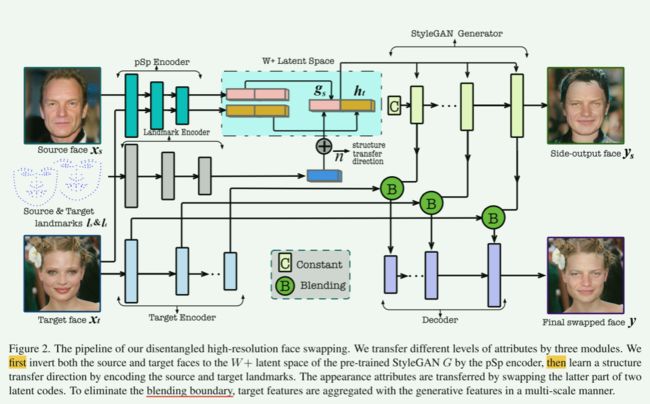
我们解纠缠的高分辨率面部交换的管道。
我们通过三个模块传输不同级别的属性。
我们首先通过 pSp 编码器将源面和目标面都反转到预训练 StyleGAN G G G 的 W + W+ W+ 潜在空间,然后通过对源和目标地标进行编码来学习结构转移方向。
外观属性通过交换两个潜在代码的后半部分来传递。
为了消除混合边界,目标特征以多尺度方式与生成特征聚合。
3.2. Class-Specific Attributes Transfer
人脸图像通常包含不同类别的属性。
例如,姿势和表情与面部结构有关,而灯光和颜色与外观有关。
以前的人脸交换技术,如FaceShifter[26]和MegaFS[55],在将属性转换到输出图像时,并没有明确区分不同类型的属性。
相反,我们认为,将结构和外观属性分开传递是有益的:
输出的结构属性可以由源图像和目标图像中的对应属性共同确定,以获得与目标人脸相同的姿态和表情,同时保留源人脸的身份。
同时,目标人脸的外观属性可以直接重用,在输出中实现相似的人脸外观。
【将属性分类传递】
为此,我们注意到最先进的生成模型 StyleGAN[20, 21]为此类分离处理提供了合适的表示。
特别是,要使用 StyleGAN 生成器,通常的做法是在扩展的潜在空间 W + W+ W+ 中编码图像,其中潜在代码由多个高维向量组成,每个对应于 StyleGAN 的每个输入层[3, 40]。
正如 [40, 51]中所述,StyleGAN 的不同输入层对应不同级别的细节。
因此,我们将对应于浅层的潜在代码的前 K K K个向量视为结构属性的编码。
对应于更深层的其余向量用于外观。
对于 1024 × 1024 1024 \times 1024 1024×1024 图像,潜在代码由 18 个不同的 512 维向量组成,我们遵循[40]并选择前 7 个向量作为结构部分。
通过这种分离,可以分别传输潜代码的结构部分和外观部分。
具体来说,我们首先使用预训练的 pSp 编码器[40]反转源面 x s x_s xs 和目标面 x t x_t xt 以获得它们的 W + W+ W+ 潜在代码 w s = ( g s , h s ) w_s = (g_s,h_s) ws=(gs,hs) 和 w t = ( g t , h t ) w_t=(g_t,h_t) wt=(gt,ht),其中 g s , g t g_s,g_t gs,gt为结构部分, h s , h t h_s,h_t hs,ht为外观部分。
为了构建具有与目标的姿势和表情相同的源身份的交换面的结构属性,我们注意到它们应该从源结构属性获得,考虑到源和目标之间的姿势和表情差异并进行修改。
因此,我们通过应用从源结构和目标结构获得的结构转移潜在方向 n → \overrightarrow{{n}} n 来计算交换面的潜在代码的结构部分 g ^ s \widehat{g}_s g s:
g ^ s = g s + n → . \begin{equation} \widehat{g}_{s} = {g}_{s} + \overrightarrow{{n}}. \end{equation} g s=gs+n.为了推导 n → \overrightarrow{{n}} n,我们注意到面部结构可以由面部标志指示。
因此,我们训练了一个地标编码器 E l e ( ⋅ , ⋅ ) E_{le}(\cdot,\cdot) Ele(⋅,⋅),它从源地标 l s l_{s} ls 和目标地标 l t l_{t} lt的热图编码生成 n → \overrightarrow{{n}} n :
n → = E l e ( l s , l t ) . \overrightarrow{{n}} = E_{le}(l_{s},l_{t}). n=Ele(ls,lt).为了将目标人脸的外观属性转移到交换后的人脸,我们直接重用目标潜在代码的外观部分 h t h_t ht。
然后它与 g ^ s \widehat{g}_{s} g s 重新整合,形成交换面的潜在代码:
w ^ s = C a t ( g ^ s , h t ) , \begin{equation} \widehat{w}_{s} = Cat(\widehat{g}_{s},{h}_{t}), \end{equation} w s=Cat(g s,ht),其中 C a t ( ⋅ , ⋅ ) Cat(\cdot,\cdot) Cat(⋅,⋅) 表示串联运算符。
该代码被输入到预训练的 StyleGAN 生成器中,以获得侧输出side-output交换面 y s y_{s} ys。
【分离latent codes为结构部分和外观部分,结构部分由源脸修改而来,外观部分直接用目标脸的】
3.3. Background Transfer
对于人脸交换应用,目标人脸的背景也需要保留在输出图像中。
对于在 Sec.3.2中计算的交换面 y s y_s ys,这通常不能得到保证。
一种常见的解决方案是应用泊松混合作为后处理,将交换的内面与目标图像混合。
然而,这会导致内面部边界周围出现不自然的外观。
【背景处理】
为了解决这个问题,我们丢弃了侧输出面 y s y_s ys,但保留了 StyleGAN生成器来自公式(2)的潜在代码 w ^ s \widehat{w}_{s} w s 的每个上采样块产生的特征 F s = { f s 0 , f s 1 , . . . f s N } F_s = \{f^0_s,f^1_s,...f^N_s\} Fs={fs0,fs1,...fsN}。
我们注意到 F s F_s Fs 可以被视为来自侧面输出面部图像的不同细节级别的表示。
因此,我们将编码器 E t E_t Et 应用于目标面 x t x_t xt,使其层生成相应的特征 F t = { f t 0 , f s 1 , . . . f s N } F_t = \{f^0_t,f^1_s,...f^N_s\} Ft={ft0,fs1,...fsN},其中 f t i f^ i_t fti与 f s i f^i_s fsi具有相同的维度,表示相同分辨率下目标人脸图像的细节。
然后,我们通过将内脸区域的 f t i f^i_t fti 的组件替换为 f s i f^i_s fsi 中的对应特征来聚合每对对应的特征 ( f s i , f t i ) (f^i_s, f^i_t) (fsi,fti)。
所有聚合的特征都被送入解码器以产生最终的人脸图像 y f y_f yf,它可以写成:
y f = D e c ( F t , F s , m t ) , y_{f} = Dec(F_t,F_s,m_t), yf=Dec(Ft,Fs,mt),其中 D e c ( ⋅ , ⋅ , ⋅ ) Dec(\cdot,\cdot,\cdot) Dec(⋅,⋅,⋅) 表示解码器, m t m_t mt 是目标人脸图像的内面具。
通过这种方式,解码器在多级特征中传输背景,这不仅消除了显式背景混合的需要,而且使代码 w ^ s \widehat{w}_{s} w s 能够专注于面部区域并促进属性转移。
【通过提取side-output swapped face和目标脸的对应特征,以及目标脸mask进行属性的保留,操作是保留侧交换脸的脸部区域,其他用目标脸的。】
3.4. Loss Functions
我们定制了几个应用于侧输出交换面 y s y_{s} ys 或最终面 y f y_{f} yf 的损失,以实现高效的属性传输,如下所述。
我们还在最终输出上引入了风格保留损失,以缩小交换后的风格与目标之间的风格差距。
3.4.1 Adversarial loss.
我们利用对抗性损失来实现最终交换面孔和真实面孔之间的分布对齐。
特别是,我们将最终人脸 y f y_{f} yf 与目标人脸对齐,损失如下:
L a d v = E y f ∼ P Y f [ − log ( D f ( y f ) ) ] , \begin{equation*} {L}_{adv} = \underset{y_{f} \sim P_{Y_{f}}}{\mathbb{E}} [-\log( D_{f}(y_{f}))], \end{equation*} Ladv=yf∼PYfE[−log(Df(yf))],其中 P Y f P_{Y_{f}} PYf 表示最终人脸的分布。
将最终人脸与真实目标人脸 x t x_t xt 区分开来的鉴别器 D f D_{f} Df 是用损失训练的
L D f = E y f ∼ P Y f [ − log ( 1 − D f ( y f ) ] + E x t ∼ P X t [ − log ( D f ( x t ) ] , \begin{equation*} {L}_{D_{f}} = \underset{y_{f} \sim P_{Y_{f}}}{\mathbb{E}} [-\log( 1- D_{f}(y_{f})] + \underset{x_t \sim P_{X_t}}{\mathbb{E}} [-\log(D_{f}(x_t)] , \end{equation*} LDf=yf∼PYfE[−log(1−Df(yf)]+xt∼PXtE[−log(Df(xt)],其中 P X t P_{X_{t}} PXt 表示真实面孔的分布。
3.4.2 Identity-preservation loss.
为了保留源人脸的身份,我们为最终人脸 y f y_f yf 和源人脸 x s x_s xs 引入身份保留损失:
L i d = 1 − cos ( Φ i d ( y f ) , Φ i d ( x s ) ) , \begin{equation*} {L}_{id} = 1 - \texttt{cos}(\Phi_{id}(y_f),\Phi_{id}(x_s)), \end{equation*} Lid=1−cos(Φid(yf),Φid(xs)),其中 Φ i d ( ⋅ ) \Phi_{id}(\cdot) Φid(⋅)是人脸识别的预训练ArcFace网络[15], cos ( ⋅ , ⋅ ) \texttt{cos}(\cdot, \cdot) cos(⋅,⋅)表示余弦相似度。
3.4.3 Landmark-alignment Loss.
由于我们使用面部标志来表示结构属性,因此我们引入以下损失来对齐侧输出交换面 y s y_s ys、最终面部 y f y_f yf 和目标面部 x t x_t xt 的标志:
L l m k = ∥ E l m k ( y s ) − E l m k ( x t ) ∥ 2 + ∥ E l m k ( y f ) − E l m k ( x t ) ∥ 2 , \begin{equation*} {L}_{lmk} = \|E_{lmk}(y_s)-E_{lmk}(x_t)\|_2 + \|E_{lmk}(y_f)-E_{lmk}(x_t)\|_2, \end{equation*} Llmk=∥Elmk(ys)−Elmk(xt)∥2+∥Elmk(yf)−Elmk(xt)∥2,其中 E l m k ( ⋅ ) E_{lmk}(\cdot) Elmk(⋅) 是预训练的地标估计器[47]和 ∥ ⋅ ∥ 2 \|\cdot\|_2 ∥⋅∥2 表示 ℓ 2 \ell_2 ℓ2 范数。
3.4.4 Reconstruction Loss.
直观地说,如果源面 x s x_s xs 和目标面 x t x_t xt 是同一幅图像,网络应该为侧输出交换面 y s y_s ys 和最终面 y f y_f yf 重建该图像。
因此,我们遵循 pSp[40]并使用像素相似度和感知相似度来定义重建损失,当 x s = x t x_s = x_t xs=xt 时惩罚 y s 、 y f y_s、y_f ys、yf 和 x t x_t xt 之间的偏差:
L r e c = { ∥ y f − x t ∥ 2 + α ∥ F ( y f ) − F ( x t ) ∥ 2 + ∥ y s − x t ∥ 2 + α ∥ F ( y s ) − F ( x t ) ∥ 2 , if x s = x t , 0 , otherwise , \begin{align*} &{L}_{rec} = \nonumber\\ & \begin{cases} \|y_f - x_t\|_2 + \alpha \|F(y_f) - F(x_t)\|_2 & \\ ~ + \|y_s - x_t\|_2 + \alpha \|F(y_s) - F(x_t)\|_2, & \text{if}~x_s = x_t,\\ 0, &{\text{otherwise}}, \end{cases} \end{align*} Lrec=⎩ ⎨ ⎧∥yf−xt∥2+α∥F(yf)−F(xt)∥2 +∥ys−xt∥2+α∥F(ys)−F(xt)∥2,0,if xs=xt,otherwise,其中 F ( ⋅ ) F(\cdot) F(⋅) 是感知特征提取器, α \alpha α 是平衡像素相似度和感知相似度项的权重。
我们在实验中设置 α = 0.8 \alpha=0.8 α=0.8。
3.4.5 Style-transfer Loss.
正如在 Sec.3.2中提到的,我们在潜在空间中传输外观属性。
但是,如果源人脸和目标人脸的风格差异太大,简单的潜在代码替换可能无法有效减少风格差异。
受 BeautyGAN[27]的启发,我们通过直方图映射创建一个引导人脸图像 H M ( y f , x t ) \mathrm{HM}(y_f,x_t) HM(yf,xt),并通过以下损失将最终人脸 y f y_f yf 与引导人脸对齐:
L s t = ∥ y f − H M ( y f , x t ) ∥ 2 . \begin{equation*} {L}_{st} = \|y_f - \mathrm{HM}(y_f,x_t) \|_2. \end{equation*} Lst=∥yf−HM(yf,xt)∥2.与简单的潜在代码替换相比,这为外观属性迁移提供了更强的指导。
【通过损失函数加强外观属性迁移,看看消融实验?】
3.4.6 Final Objective.
训练我们模型的最终损失函数是上述损失的加权组合:
L t o t a l = λ 1 L a d v + λ 2 L i d + λ 3 L l m k + λ 4 L r e c + λ 5 L s t , \begin{equation} {L}_{total} = \lambda_1 {L}_{adv} + \lambda_2 {L}_{id} + \lambda_3 {L}_{lmk} + \lambda_4 {L}_{rec} + \lambda_5 {L}_{st}, \end{equation} Ltotal=λ1Ladv+λ2Lid+λ3Llmk+λ4Lrec+λ5Lst,其中 λ 1 , λ 2 , λ 3 , λ 4 , λ 5 \lambda_1, \lambda_2, \lambda_3, \lambda_4, \lambda_5 λ1,λ2,λ3,λ4,λ5 是损失项的权重。
3.5. Video Face Swapping
我们的方法可以扩展到视频换脸。
给定一个源人脸 x s x_s xs 和一系列具有 M M M 个连续帧的目标人脸 S t = { x t 0 , x t 1 , . . . , x t M − 1 } S_t=\{x_{t}^0,x_{t}^1,...,x_{t}^{M- 1}\} St={xt0,xt1,...,xtM−1},我们想得到一个交换后的人脸序列 Y = { y 0 , y 1 , . . . , y M − 1 } Y=\{y^0,y^1,...,y^{M-1}\} Y={y0,y1,...,yM−1}。
大多数现有作品将基于图像的人脸交换方法分别应用于每个视频帧,这会导致相邻帧之间的结果不一致,并导致诸如闪烁之类的伪影。此类伪影在高分辨率下尤为明显。
为了解决这个问题,我们需要在结构和外观方面强制相邻帧之间的一致性,以便这些属性在帧之间平滑变化。
现有的时间一致性工作[9, 25]只考虑了外观一致性,不能直接用于换脸。
我们分别为潜在空间和图像空间提出了两个时空约束,以实现结构和外观的一致性。
【潜在空间和图像空间的两个时空约束,以实现不同视频帧之间结构和外观的一致性。】
3.5.1 Code Trajectory Constraint.
由于目标帧的结构属性变化平稳,我们可以通过要求它们在结构属性上具有与目标相似的变化来强制交换面部帧的结构一致性。
为此,我们注意到两个相邻帧中潜在代码的结构部分之间的偏移可以被视为结构属性变化的指示。
因此,我们使用以下损失来来增强目标视频和输出视频在潜空间中结构码的相似轨迹:
L c t = ∑ k = 1 M ∥ ( g ^ s k − g ^ s k − 1 ) − ( g t k − g t k − 1 ) ∥ 2 , \begin{equation*} {L}_{ct} = \sum\nolimits_{k=1}^{M} \left\|(\widehat{g}_{s}^{k} - \widehat{g}_s^{k-1}) - ({g}_{t}^{k} - {g}_t^{k-1})\right\|_2, \end{equation*} Lct=∑k=1M (g sk−g sk−1)−(gtk−gtk−1) 2,其中 g t k {g}_{t}^k gtk 表示目标框架 x t k x_{t}^k xtk 的潜在代码的结构部分, g ^ s k \widehat{g}_{s}^{k} g sk 表示使用 Eq.(1)从 x s x_{s} xs 和 x t k x_{t}^k xtk 获得的交换面的结构代码。
【用潜在代码的结构属性部分约束相邻帧之间的变化】
3.5.2 Flow Trajectory Constraint.
对于外观一致性,我们遵循局部线性模型[30, 32]假设相邻帧之间变化均匀1。
具体来说,我们将交换后的人脸序列中从帧 y f i y_f^{i} yfi 到附近帧 y f j y_f^{j} yfj 的光流表示为:
f i ⇒ j = Φ ( y f i , y f j ) , \begin{equation*} f_{i \Rightarrow j} = \Phi(y_f^{i},y_f^{j}), \end{equation*} fi⇒j=Φ(yfi,yfj),其中 Φ ( ⋅ , ⋅ ) \Phi(\cdot,\cdot) Φ(⋅,⋅) 是预训练的 PWC-Net[44]用于流量预测。
从局部线性假设来看,交换后的人脸序列中两个相邻帧之间的密集对应关系可以通过在两帧之间插值前向流和后向流来近似,这会导致以下损失:
L f t = ∑ k ∥ ( f k ⇒ k + 2 + f k + 2 ⇒ k ) / 2 − f k ⇒ k + 1 ∥ 2 . \begin{equation*} {L}_{ft} = \sum\nolimits_{k} \| (f_{k \Rightarrow k+2} + f_{k+2 \Rightarrow k})/2 - f_{k \Rightarrow k+1} \|_2. \end{equation*} Lft=∑k∥(fk⇒k+2+fk+2⇒k)/2−fk⇒k+1∥2.我们注意到 L f t {L}_{ft} Lft 实际上是光流的时间拉普拉斯算子的 ℓ 1 / ℓ 2 \ell_1/\ell_2 ℓ1/ℓ2 范数。
这促进了在大多数帧上具有小拉普拉斯算子的序列,同时允许在某些帧上具有大拉普拉斯算子[6],这允许在时间上分段平滑的运动序列。
【外观一致性约束】
4. Experiments
4.1. Implementation Details
我们利用在分辨率为 1024 × 1024 1024\times 1024 1024×1024的FFHQ 数据集[20]上预训练的 StyleGAN2 生成器[21]。
pSp 编码器也在该数据集上进行了预训练。
我们使用 pSp 的修改作为我们的地标(结构的更多细节可以在补充材料中看到)。
我们使用 Adam 优化器[23]以 1 × 1 0 − 4 1 \times 10^{-4} 1×10−4 的学习率训练模型, 1 s t 1_{st} 1st 和 2 n d 2_{nd} 2nd moment 估计的指数衰减率分别为 β 1 = 0.9 {\beta}_1 = 0.9 β1=0.9 和 β 2 = 0.999 {\beta}_2 = 0.999 β2=0.999,以及 ϵ = 1 × 1 0 − 8 {\epsilon} = 1 \times 10^{-8} ϵ=1×10−8。
批量大小设置为 8,模型经过 500,000 次迭代训练。
我们根据经验将 Eq.(3) 中的权重设置为 λ 1 = 1 \lambda_{1}=1 λ1=1, λ 2 = 2 \lambda_{2}=2 λ2=2, λ 3 = 0.1 \lambda_{3}=0.1 λ3=0.1, λ 4 = 2 \lambda_{4 }=2 λ4=2 和 λ 5 = 0.2 \lambda_{5}=0.2 λ5=0.2。
我们使用四个 Tesla V100 GPU 在 Pytorch 中实现我们的方法。
训练整个模型大约需要两天时间。
【实验设置细节】
4.2. Datasets
Datasets. 我们在以下三个数据集上评估我们的模型:(应该是两个)
- CelebA-HQ 包含 30,000 张名人面孔,分辨率为 1024 1024 1024 × \times × 1024 1024 1024[19]。由于质量上乘,在很多人脸编辑作品中得到了广泛的应用。
- FaceForensics++ 包含从 YouTube 下载的 1,000 个原始谈话视频,并使用 5 种换脸方法进行操作[42]。该数据集可作为许多换脸作品的基准。
Evaluation Metrics. 我们在定量实验中使用了几个指标。 ID retrieval rate,用基于余弦相似度的top-1身份匹配率衡量,表示身份保存能力。
对于一些实验,我们遵循 MegaFS[55]并计算ID similarity,这是使用 CosFace[46]交换的人脸与其对应源之间的余弦相似度,以降低计算成本。
The pose error and the expression error分别是姿势和表情特征向量之间的 ℓ 2 \ell_2 ℓ2 距离,分别使用预训练的估计器[12,43]在交换和目标面上,这表示传递结构属性的能力。
The Fr e ˊ \'{e} eˊchet Inception Distance (FID) [18]计算真实人脸和交换图像分布之间的 Wasserstein-2 距离,它衡量交换人脸的图像质量。
4.3. Comparison on CelebA-HQ Dataset
4.3.1 Qualitative Comparison.
我们首先在高分辨率 CelebA-HQ 数据集[19]上进行实验。
我们将我们的方法与以 1024 1024 1024 × \times × 1024 1024 1024 分辨率交换人脸的 MegaFS[55] 进行比较,定性比较结果如图3所示。
我们可以看到 MegaFS 生成的人脸往往具有模糊的外观,没有生动的细节。
这是因为他们只对低维潜在代码执行面部交换而没有明确的分离,这很容易稀释细节的潜在编码。
【MegaFS 生成的人脸往往具有模糊的外观,没有生动的细节。】
此外,在他们的结果中,面部区域和背景之间存在明显的界限。
相比之下,我们的方法利用来自 StyleGAN 生成器的多分辨率空间特征并将它们与来自目标解码器的背景特征聚合,这有助于保留高质量的面部细节。
此外,MegaFS 没有将目标属性有效地传输到输出,尤其是当源和目标之间存在较大的语义差距时。
例如,在 Fig.3的第二行中,MegaFS 无法从目标传输照明或样式,因为这些属性在源和目标之间存在很大差异。
相比之下,由于我们解开的属性转移,我们的结果更有效地保持了目标属性。
对于图3第四行左侧的结果,我们还可以看到 MegaFS 没有保留源身份,与源相比错误地放大了眼睛。
这是因为身份和属性在潜在空间中高度纠缠,而 MegaFS 中缺乏显式解纠缠会导致不令人满意的结果。
相反,我们分别传输不同级别的属性,这有助于维护源身份和目标属性。
【细粒度分析MegaFS的缺点】

定性比较换脸对1024×1024的分辨率。我们可以看到MegaFS总是将模糊的人脸与背景呈现出明显的边界。此外,它们不能在交换过程中有效地保存源身份。同时,当源和目标之间的外观属性较大时,无法将目标传递到输出中。相反,我们的方法可以在保持身份不变的情况下,按照需要传递结构和外观属性。放大看最好的景色。
4.3.2 Quantitative Comparison.
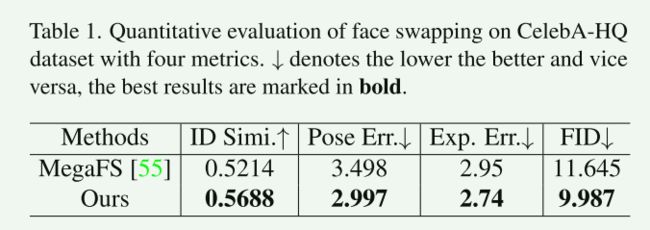
我们还对 CelebA-HQ 数据集进行了定量比较。
我们遵循 MegaFS 并在 300,000 个交换面孔上进行比较以进行公平比较。
Tab.1显示了每种方法的评估指标的平均值。
我们的方法在身份保存和属性转移方面都具有更强的能力。
此外,我们的结果具有较低的 FID,这表明我们交换的面孔比 MegaFS 的面孔更真实。
【定量比较都好】
4.4. Comparison on FaceForensics++ Dataset
为了与其他只能应用于低分辨率图像的换脸方法进行比较,我们进一步在 Face-Forensics++ 数据集上评估我们的方法。
Fig.4给出了与 MegaFS 以及三种基于非 GAN 先验和低分辨率方法的定性比较结果:FaceSwap[2]、Deepfakes[1]和 FaceShifter[26]。
我们可以看到,FaceSwap 和 MegaFS 会导致明显的混合边界或伪影,而我们的方法可以消除它们,因为我们的背景传输。
然而,我们的交换结果的质量不如 Fig.3中的高分辨率面部交换那么高。
这可能是由于领域差距:我们方法中使用的 styleGAN 生成器和 pSp 编码器都在高分辨率数据上进行了预训练,而来自 FaceForensics++ 的大部分数据的分辨率较低。
低分辨率和高分辨率数据集之间的大域差距可能会降低我们方法的性能。
【低分辨率数据集比较】
我们还对该数据集进行定量评估。
特别是,我们遵循 MegaFS[55]从每个视频中均匀采样 10 帧,然后由 MTCNN[53]进行处理。
在过滤掉重复的身份后,我们得到了 885 个视频,总共 88500 帧。
Tab.2显示了不同方法的评估指标的平均值。
我们可以看到我们的方法更有效地保留了目标姿势和表情,这要归功于我们的结构属性传输将地标作为输入并为最终交换的人脸提供强大的指导信号。
同时,我们的模型在 ID 检索率方面低于 FaceShifter 和 MegaFS。
我们推测这是由于如上所述的低分辨率图像和高分辨率图像之间的域差距,这使得我们的反演模型在保留低分辨率图像的身份信息方面效果较差。
【低分辨率身份保存效果较差】


4.5. Ablation Study
在本节中,我们执行消融研究并使用 CelebA-HQ 数据集来评估我们的分离方法在传输属性方面的有效性。
我们使用 MegaFS 作为基线,因为它们仅在两个潜在代码上交换面孔,而没有分离属性。
我们进一步包括了我们方法的三个变体,并对模块和损失函数进行了修改。
对于第一个变体 (Var.1),我们保持源代码 w s w_s ws 的外观部分不变以生成侧输出面,并丢弃样式转移损失和外观转移的潜在代码交换操作,即没有明确的转移指导有助于外观属性。
对于第二个变体 (Var.2),我们丢弃了背景传输模块,直接将侧输出人脸与目标人脸图像混合作为最终输出。
不同变体与基线之间的定性比较如图5所示。
我们可以看到 MegaFS 基线导致模糊的面孔和清晰的边界。
如前所述,这是由于潜在代码中高度纠缠的身份和属性,这可能导致传输过程中的信息丢失。
第一个变体呈现了不自然的样式,它验证了我们的外观属性传输的必要性,它在交换过程中提供了明确的外观指导。
由于缺少融合多分辨率特征的背景传输模块,第二个变体在交换的面部区域和背景之间呈现出显着的混合边界(参见 2 n d 2_{nd} 2nd 和 3 r d 3_{rd} 3rd 样本)从源头和目标进行自然融合。
同时,我们的目标编码器-解码器结构也可以容忍源和目标之间的结构差异,并产生最终合理的结果。
由于我们解开的属性转移,我们最终交换的面孔呈现了来自目标的成功语义转移,并且源身份得到了很好的保留。
【这里并没有给出Style-transfer Loss的单独消融实验,而是与结构潜码一起变化的。】

4.6. Face Swapping on High-resolution Videos
Fig.6显示了我们的方法在高分辨率视频上的定性结果。
将我们的方法单独应用于每个帧会导致相邻帧之间的不连贯,而我们的代码和流轨迹约束会大大提高连贯性和视觉质量。

5. Conclusion and Discussions
介绍:我们提出了一种基于预训练的StyleGAN固有先验知识的高分辨率人脸交换方法。方法:我们将属性分为结构属性和外观属性,并在解纠缠的潜在空间中将它们分别转换。
我们提出了一种landmark 编码器,它可以预测结构属性转移的潜在方向。
将转移的潜码生成的StyleGAN生成特征与目标图像编码器的多分辨率特征进行聚合,传递背景信息,生成高质量的结果。视频:通过增加两个时空约束,我们进一步将该方法扩展到视频人脸交换。实验:大量的实验证明了解纠缠属性转移在幻觉质量和一致性方面的优越性。
5.1 Limitations.
由于我们将属性转移到StyleGAN的潜在空间中,所以结果的质量很大程度上依赖于GAN反演方法。
特别是,如果反演没有为源和目标面生成忠实的潜在码,则结果不能保证保持源的身份。
我们的方法将所有目标的外观属性转移到结果图像中,不支持源图像和目标图像的选择性转移。
这种细粒度fine-grained的控制可能对某些应用程序(如内容创建)有益,但需要进一步理清不同类别的外观属性之间的关系。
这可以成为进一步研究的一个途径。
(E4S: Fine-grained Face Swapping via Regional GAN Inversion也许是因此而做的。)
5.2 Potential Negative Impact.
虽然这不是这项工作的目的,但真实的面部交换可能会被误用在深度伪造相关的应用程序中。
通过模型的门控释放和能够识别CNN生成的图像[48]的伪造检测方法,可以降低风险。
此外,我们的方法还可以用于生成新的高分辨率测试用例,用于基准测试和进一步开发伪造检测技术[42]。
个人思考与总结
- 首先:这篇文章的主要贡献是提出将StyleGAN的潜码进行分离,而不是直接进行融合,即对属性进行了分类。也即是不断的细粒度的进行换脸。
- 其次:选择性转移,也即可以进行人脸编辑可以参考这篇E4S: Fine-grained Face Swapping via Regional GAN Inversion。
- 其实也有很多可以改进的地方,例如光照,遮挡,身份等的迁移等。
这里为了简单起见我们遵循局部线性假设,我们也可以遵循加速度感知假设[29, 49]以更好地逼近真实世界的场景运动。 ↩︎