MySQL详细教程 这一篇就够啦!
本文摘自微信公众号 程序员GitHub: 从入门到入土:MySQL完整学习指南,包教包会!
1. SQL介绍
SQL(Structured Query Language),语义是结构化语言,是一门ANSI的标准计算机语言。
2. 数据库介绍
1. 数据库
数据库(database)是 保存一个文件或一组文件的容器。
2. 数据库管理系统
数据库管理系统(Database Manage System),用来管理数据库的,比如MySQL、Access、DB2、Informix、Server、Oracle、Sybase等等。
3. 表
表是一种结构化的文件,可以用来存储特定类型的数据。
每个表的 表名是唯一,不可重复。
4. 列和数据类型
列是表中的一个字段,一个表由多个列组成;每个列都由特定的数据类型,只能存放指定数据类型的数据。
数据类型是限定表中的每个列只能存储特定类型的数据,常见的数据类型有整型、数字、文本、字符串、日期 等。
5. 行
行是表中的一条记录。
6. 主键
主键是每行的唯一标识,特性是主键,不能为空、不能重复、不能修改。
7. 行号
行号指表中每个行的行号。
3. 基本检索
安装MySQL和使用 Navicat 连接数据库。
新建一张学生表student,列分别是id、名称name、年龄age、学生信息info。
建表语句:
CREATE TABLE IF NOT EXISTS `student` (
`id` INT AUTO_INCREMENT,
`name` VARCHAR (100) NOT NULL,
`age` INT NOT NULL,
`info` VARCHAR (40) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ENGINE=InnoDB设置存储引擎,CHARSET指定编码格式
向表中插入数据:
INSERT INTO `student` (id,name,age,info) VALUES (1,'user1',18,'大一新生');
INSERT INTO `student` (id,name,age,info) VALUES (2,'user2',20,'毕业生');
INSERT INTO `student` (id,name,age,info) VALUES (3,'user3',27,'社会人士');
INSERT INTO `student` (id,name,age,info) VALUES (4,'user4',17,'高三学子');
1. select关键字
SQL都是由许多关键字(keyword)组成的语句,关键字是数据库的保留字,用户不能将其当做建表的表名、字段等;表中的数据检索使用select关键字作为开头进行查询数据库表的信息。
2. 检索单个字段
SELECT name FROM student;
user1
user2
user3
user4
3. SQL语句注意点
- 多SQL语句一起执行使用分号
;隔开; - 拼写语句时表的关键字建议使用大写,表的字段和表名使用小写;
- 为了容易阅读,建议将SQL分成多行;
- SQL语言也是使用英文字母,不要开中文,以免造成符号错误不容易被发现;
- SQL语句默认不区分大小写
- SQL语句表名或字段名可以不加引号,如果加引号需要用 ` 而不能用单双引号;
- SQL语句字段名对应的value值使用单双引号都可以。
4. 检索多个字段
SELECT name,age FROM student;
user1 18
user2 20
user3 27
user4 17
5. 检索所有字段
SELECT * FROM student;
1 user1 18 大一新生
2 user2 20 毕业生
3 user3 27 社会人士
4 user4 17 高三学子
- 通配符
*表示返回表中的所有列,不是必须不建议使用通配符,会影响数据库性能。
6. distinct 去重
distinct表示区分,指检索出来的行是唯一(去重),其放在列的最前面;
如果使用了关键字distinct,其作用于后面的所有列。
- 添加一列已存在的数据:
INSERT INTO `student` (id,name,age,info) VALUES (5,'user4',17,'高三学子');
- 然后查询
SELECT DISTINCT name,age FROM student;
user1 18
user2 20
user3 27
user4 17
- user4被过滤一条
7. 限制条数
access 和 sql server:
SELECT TOP 2 FROM student;
TOP 2表示限制返回前2行
postgresql、SQLLite、和MySQL:
SELECT name FROM student LIMIT 2;
-
LIMIT 2表示限制返回前2行 -
执行结果:
user1 user2
DB2:
SELECT name FROM student FETCH FIRST 2 ROWS ONLY;
FETCH FIRST 2 ROWS ONLY表示只抓取前2行数据
8. 偏移
SELECT name FROM student LIMIT 1 OFFSET 1;
-
表示查询列名称来自学生表 限制条数1,偏移值1;
-
意思就是查询学生表中的第二行数据;
-
offset表示跳跃或者偏移 -
执行结果:
user2
MySQL和MariaDB简化形式:
SELECT name FROM student LIMIT 1,2;
-
表示查询字段名称来自学生表,限制2条,偏移1条;
-
注意顺序
-
执行结果:
user2 user3
4. 顺序检索
1. ORDER BY 子句
SELECT name,age FROM student ORDER BY age;
-
检索字段名称,年龄来自学生表按照列年龄排序;
-
注意 默认是升序
ASC; -
ORDER BY子句通常在语句末尾 -
执行结果:
user4 17 user4 17 user1 18 user2 20 user3 27
2. 多列排序
SELECT name,age FROM student ORDER BY age DESC, name ASC;
-
查询名称,年龄来自学生表,按年龄降序,名称升序进行排序;
-
关键字
DESC(descending)指降序,字母默认Z-A, -
ASC(ascending)指升序,字母默认A-Z; -
多列情况下,每个列后面指定使用
DESC,使用逗号,隔开。如果不写,默认升序。 -
执行结果:
user3 27 user2 20 user1 18 user4 17 user4 17
3. 按位排序 DESC和ASC
SELECT name,age FROM student ORDER BY 2 DESC, 1 ASC;
-
按位指查询字段的位置,2对应字段age,1对应字段name,结果和多列排序一致
-
执行结果:
user3 27 user2 20 user1 18 user4 17
5. 过滤检索
SQL语句中过滤条件(filter condition)的关键字是WHERE,跟在表名后面。
1. WHERE语句操作符
不同数据库管理系统,其支持的操作符略有不同。
| 操作符 | 说明 |
|---|---|
| = | 等于 |
| > | 大于 |
| < | 小于 |
| != | 不等于 |
| <> | 不等于 |
| >= | 大于等于 |
| <= | 小于等于 |
| !< | 不小于 |
| !> | 不大于 |
| BETWEEN | 在中间 |
| IS NULL | 为空 |
2. 单条件过滤 WHERE
SELECT * FROM student WHERE name = 'user1'
-
输出结果:
1 user1 18 大一新生
3. 多条件过滤 AND和OR
使用 AND 或 OR 子句:
AND连接表达式表示过滤条件都为真的数据;OR连接表达式表示匹配过滤条件任意一个
AND示例:
SELECT * FROM student WHERE age >= 18 AND age <= 23;
-
条件:学生年龄大于等于18 并且 学生年龄小于 23
-
执行结果:
1 user1 18 大一新生 2 user2 20 毕业生
OR示例:
SELECT * FROM student WHERE age >= 18 OR age <= 23;
- 条件:学生年龄大于等于18 或 学生年龄小于 23
AND和OR示例:
SELECT * FROM student WHERE age >= 18 AND (age <= '23' OR id >= 2);
-
使用
OR和AND时应明确过滤条件,用小括号括起来,因为数据库管理系统按顺序执行,不用括号括起来很容易造成语义错误; -
过滤条件:查询年龄大于18 并且 (年龄大于等于23或id大于等于2) 的数据
-
查询结果:
1 user1 18 大一新生 2 user2 20 毕业生 3 user3 27 社会人士
4. 范围查询 BETWEEN
SELECT * FROM student WHERE age BETWEEN 18 AND 23
-
查询年龄在18到23之间的(包含18和23)
-
查询结果:
1 user1 18 大一新生 2 user2 20 毕业生
5. 空值查询 IS NULL
SELECT * FROM student WHERE age IS NULL
-
数据库表不填充数据默认为空(
NULL),当然也可给指定类型的列设置默认值 -
过滤条件:查询年龄为空的数据
-
查询结果(因为
insert的数据age都有值,所以返回为空):空
6. IN操作
SELECT * FROM student WHERE age IN (18,20,27);
-
查询条件:年龄在 18 或 20 或 27 的数据
-
IN是范围查询,匹配小括号中指定的任意值,功能跟OR类似,一个IN相当于好多个OR -
查询结果:
1 user1 18 大一新生 2 user2 20 毕业生 3 user3 27 社会人士
7. NOT操作符
SELECT * FROM student WHERE NOT age = 20;
-
NOT操作符表示否定,跟在WHERE后面,功能类似<> -
查询结果:
1 user1 18 大一新生 3 user3 27 社会人士 4 user4 17 高三学子 5 user4 17 高三学子
NOT和IN的查询:
SELECT * FROM student WHERE NOT age IN (20, 27);
-
查询条件:年龄不在 20 或 27 中的数据
-
执行结果:
1 user1 18 大一新生 4 user4 17 高三学子 5 user4 17 高三学子
6. 通配符检索
1. 通配符的介绍
通配符:组成匹配模式的特殊字符串。检索文本的通配符用在关键字LIKE后面。
2. 通配符 %
匹配字符前:
SELECT * FROM student WHERE name LIKE '%er2'
-
查询条件:名称以任意字符开头、以
er2结尾的数据 -
%代表任意个任意字符串,包含0但不包含null -
查询结果:
2 user2 20 毕业生
匹配字符后:
SELECT * FROM student WHERE name LIKE '%o%';
- 查询条件:名称以任意字符开头和任意字符结尾、字符中包含
s的数据
3. 通配符 _
通配符_匹配一个字符串。在Access数据库中不是_而是?
SELECT * FROM student WHERE name LIKE '_ser3';
-
查询条件:匹配名称
ser3前边一个任意字符的数据: -
执行结果:
3 user3 27 社会人士
4. 通配符 []
通配符[]匹配一个位置一个字符,里面可以存放多个字符,关系是or,模式匹配时只占用一个位置。Access、SQL Server支持
[24]普通查询:
SELECT * FROM student WHERE name REGEXP '[24]';
-
查询条件:查询
name包含 2 或 4 的数据 -
返回结果:
2 user2 20 毕业生 4 user4 17 高三学子 5 user4 17 高三学子
[2-4]范围查询:
SELECT * FROM student WHERE name REGEXP '[2-4]';
-
查询条件:查询
name包含 在2 到 4的数据,也就是name中含2或3或4的数据 -
返回结果:
2 user2 20 毕业生 3 user3 27 社会人士 4 user4 17 高三学子 5 user4 17 高三学子
7. 字段基本操作
1. 字段拼接
SELECT CONCAT('你好啊',name,'今天天气怎样?') FROM student WHERE id = 1;
-
CONCAT: 合并(拼接)多个数组或多个字符串成一个字符串 -
不同的数据库管理系统其使用的方式略有差别:
- MySQL使用
concat函数 - postgresql使用
|| - Access和SQL server使用
+
- MySQL使用
-
执行结果:
你好啊user1今天天气怎样?
2. 去除空白字符串
SELECT RTRIM(' 哥,今天管饱 ') FROM student WHERE id=1;
SELECT LTRIM(' 哥,今天管饱 ') FROM student WHERE id=1;
SELECT TRIM(' 哥,今天管饱 ') FROM student WHERE id=1;
-
RTRIM(str)函数去掉右边的空字符串; -
LTRIM(str)函数去掉左边的空字符串; -
TRIM(str)函数去掉两边的空字符串。 -
运行结果:
哥,今天管饱 # 左边有空字符串 哥,今天管饱 # 后边有空字符串 哥,今天管饱 # 两边都没有空字符串
3. 别名 as
# 给字段起别名
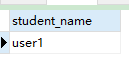
SELECT name as student_name FROM student WHERE id=1
# 给表起别名
SELECT name FROM student as s WHERE id=1
# 给字段和表起别名
SELECT name as student_name FROM student as s where id=1
- 执行结果(只体现了字段别名):
4. 计算
| 操作符 | 说明 |
|---|---|
| * | 乘 |
| + | 加 |
| - | 减 |
| / | 除 |
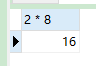
SELECT 2 * 8;
- 结果:
8. 聚集函数的使用
先创建三张表并添加数据:
- 顾客表:
CREATE TABLE IF NOT EXISTS `customer` (
`user_id` INT AUTO_INCREMENT COMMENT '顾客id',
`username` VARCHAR( 255 ) NULL COMMENT '顾客名称',
`telephone` VARCHAR( 255 ) NULL COMMENT '顾客电话',
PRIMARY KEY ( `user_id` )
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO customer (`user_id`, `username`, `telephone`) VALUES (1, 'zxzxz', '1327');
INSERT INTO customer (`user_id`, `username`, `telephone`) VALUES (2, 'youku1327', '1996');
- 商品表
CREATE TABLE IF NOT EXISTS `product` (
`product_id` INT AUTO_INCREMENT COMMENT '商品id',
`product_name` VARCHAR ( 255 ) NULL COMMENT '商品名称',
`price` VARCHAR ( 255 ) NULL COMMENT '商品价格',
PRIMARY KEY ( `product_id` )
);
INSERT INTO product ( `product_id`, `product_name`, `price` ) VALUES ( 1, '苹果', '5' );
INSERT INTO product ( `product_id`, `product_name`, `price` ) VALUES ( 2, '梨', '4' );
INSERT INTO product ( `product_id`, `product_name`, `price` ) VALUES ( 3, '香蕉', '3' );
- 订单表
CREATE TABLE IF NOT EXISTS `order` (
`id` INT NOT NULL AUTO_INCREMENT COMMENT'订单id',
`user_id` INT NULL COMMENT '客户id',
`product_id` INT NULL COMMENT '商品id',
`order_name` VARCHAR(255) NULL COMMENT '订单名称',
PRIMARY KEY (`id`)
);
INSERT INTO `order` (`id`, `user_id`, `product_id`, `order_name`) VALUES(1, 1, 1, '乖乖订单');
INSERT INTO `order` (`id`, `user_id`, `product_id`, `order_name`) VALUES(2, 2, 2, '悦悦订单');
INSERT INTO `order` (`id`, `user_id`, `product_id`, `order_name`) VALUES(3, 1, 3, '可可订单');
聚集函数的定义:将一些行的数据运行某些函数,返回一个期望值。
1. avg() 平均值
avg()函数计算行的数量,通过计算这些行的特定列值和,计算出平均值(特定列值之和/行数=平均值)。使用时注意其会忽略列值为null的行:
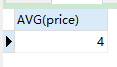
SELECT AVG(price) FROM product;
-
语句分析:查询价格平均值来自商品表
(5+4+3)/3=4; -
结果:
2. count() 计算行数
count()函数计算行数,count(*)计算所有行的数目,count("column")会忽略column为NULL的行数:
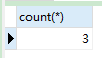
SELECT count(*) FROM product;
-
语句分析:查询总函数来自商品表
-
结果:
3. max() 列值的最大值
max()函数返回特定列值的最大值,忽略特定列为NULL的行:
SELECT MAX(price) FROM product;
-
语句分析:查询价格的最大值来自商品表
-
结果:
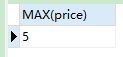
4. min() 列值的最小值
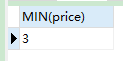
min()函数返回特定列的最小值,忽略特定列为NULL的行:
SELECT MIN(price) FROM product;
-
语句分析:查询价格的最小值来自商品表
-
结果:
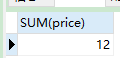
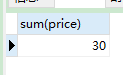
5. sum() 特定列的和
sum()返回特定列的和,忽略特定列为NULL的行:
SELECT SUM(price) FROM product;
-
语句分析:查询价格的总和来自商品表
-
结果:
9. 分组数据
分组定义:按照特定的列进行分组查询,使用GROUP BY子句进行分组查询。
注意:
SELECT后面的列必须出现在group by子句后面,否则报语法错误;- 通常
group by子句的位置是where条件之后,order by子句之前。
1. 分组求和
插入一条梨的数据(peoduct_id为4):
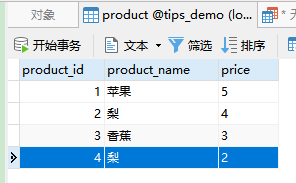
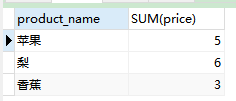
SELECT product_name, SUM(price) FROM product GROUP BY product_name;
-
语句分析:先根据商品名称分为三组 苹果、梨、香蕉;再根据不同的分组求和
-
结果:
2. 分组过滤
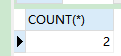
SELECT COUNT(*) FROM `order` GROUP BY user_id HAVING COUNT(*) > 1;
-
语句分析:查询订单表,根据用户id分组,过滤条件条数大于2
-
注意:
having与where其实差别不大:where通常当做标准的过滤条件having用作分组过滤条件- 有的数据库管理系统
having不支持别名作为分组过滤条件中的一部分
-
结果:
3. 分组排序
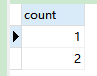
SELECT COUNT(*) as count FROM `order` GROUP BY user_id ORDER BY count;
-
语句分析:查询订单表,根据客户id分组,根据 行数 排序
-
注意点:经过分组后结果看似经过排序,其实并不能确保是排序后的结果,所以要排序一定要使用
order by子句 -
结果:
10. 子查询
子查询:在查询中嵌套查询。
注意:子查询只能返回单列,若企图返回多列会报语法错误。
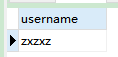
SELECT username FROM customer WHERE user_id = ( SELECT user_id FROM `order` WHERE order_name = '乖乖订单' );
- 语句分析:先看括号里面的,查询
order表的user_id,赋给括号外的user_id,然后查询customer表的username。 - 结果:
11. 联结表
联结表,就是关联表查询,主要功能是能在多表中使用一条SQL检索出期望值,但实际库表中是存在的,只在查询期间存在。
分类:
- 内连接和外连接使用的
join关键字 - 联结表会返回一对多、一对一、多对多关系
- 联结表不建议超过三张表以上
1. 简单链接
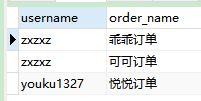
SELECT username,order_name FROM customer,`order` WHERE customer.user_id = `order`.user_id;
- 语句分析:查询
customer和order两张表(username来自customer表,order_name来自order表)中user_id相等的数据,返回username和order_name - 注意:简单联结
where子句后面必须带上两张表的联结关系,否则会出现笛卡尔集(比如3行数据联结另一张表3行数据会产生3*3=9条) - 结果:
2. 内联结
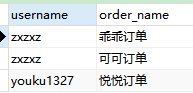
内连接(inner join) 又称等值联结,其查询结果跟之前的简单联结一致。
SELECT username,order_name FROM customer INNER JOIN `order` ON (customer.user_id = `order`.user_id);
- 语句分析:跟之前的简单联结稍微不同的是 等值条件 是放在
on关键字之后,在等值条件后面还可以进行where子句过滤条件查询 - 结果:
3. 自然联结
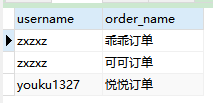
自然联结与标准的联结不同就是只返回值唯一的列,不会返回重复的列。
1. 自然联结示例
SELECT username,order_name FROM customer INNER JOIN `order` ON (customer.user_id = `order`.user_id);
- 结果:
2. 非自然联结
SELECT * FROM customer INNER JOIN `order` ON (customer.user_id = `order`.user_id);
- 结果:

重复的是user_id。
4. 外联结
1. 右外联结
右外联结是相对于OUTER JOIN右边的表,查询出右边表的所有数据和根据等值条件匹配左边表的数据,如果左边表的数据不匹配,那么其返回列的值是NULL充当。
SELECT * FROM `order` RIGHT OUTER JOIN customer ON (customer.user_id = `order`.user_id);
- 结果:

2. 左外联结
左外联结是相对于OUTER JOIN左边的表,查询出左边表的所有数据和根据等值条件匹配右边表的数据,如果右边表的数据不匹配,那么其返回列的值是NULL充当。
SELECT * FROM customer LEFT JOIN `order` ON customer.user_id = `order`.user_id);
- 结果:

左右外联结的区别:其实没什么不同,只是查询表顺序不一致,通过置换表的相对位置可查询出一样的结果。
12. 组合查询
组合查询:又称为“复合操作”,可以执行多条select语句,其查询的结构是一致的,返回查询结果。
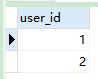
SELECT user_id FROM customer UNION SELECT user_id FROM `order`;
-
结果:
-
语句分析:
union关联的字段或者聚合函数在两张表中必须是相同的,其默认会将结果进行去重处理 -
如果不去重可使用
union all:
SELECT user_id FROM customer UNION ALL SELECT user_id FROM `order`;
- 结果:
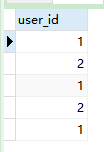
- 语句分析:等同于将客户表和订单表的用户id都合并为一个并集查询出来,而且不去重;如果对组合语句进行排序,默认是会作用于组合后的数据字段排序,而不是作用于其中的一条查询语句
13. 插入
插入数据库记录是使用insert关键字,能将一条语句插入数据库,高级的可以组合select关键字实现插入查询的结果集,插入整张表。
- 建表语句:
CREATE TABLE IF NOT EXISTS `user` (
`id` INT NOT NULL AUTO_INCREMENT COMMENT '用户id',
`name` VARCHAR(255) NULL COMMENT '用户名',
`telephone` VARCHAR(11) NULL COMMENT '手机号',
PRIMARY KEY (`id`)
);
1. 插入一条完整数据
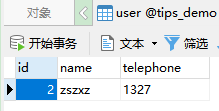
INSERT INTO `user`(id,`name`,telephone) VALUES (2,'zszxz','1327');
-
语句分析:插入数据到
user表,字段分别是id,name,telephone,值分别是2,‘zszxz’,‘1327’ -
INTO可以忽略不写,但不建议,因为在数据库管理系统间会出现移植性问题; -
还有字段也可以忽略不写,但不建议,容易造成插入数据出错;
-
字段的位置和值的位置是一一对应,如果有的位置没值可用
NULL代替 -
结果:
2. 插入部分数据
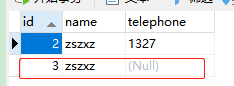
INSERT INTO user (id,name) VALUES (3, ‘zszxz’);
-
语句分析:插入数据到
user表,字段分别是id,name,值分别是3,zszxz,没有插入telephone字段 -
结果:
3. 插入检索数据
将查询的结果插入另一张表,可使用insert select关键组合成一条语句实现。
INSERT INTO `user` (id,`name`) SELECT id,`name` FROM student WHERE id = 4;
-
语句分析:插入到
user表,字段分别是id,name,值是查询字段id,name来自student表,条件是id等于4。列顺序一致,建议使用名称匹配 -
结果:
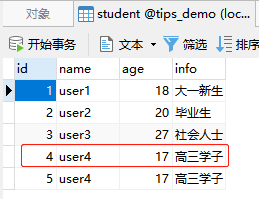
-
student表id=4的数据
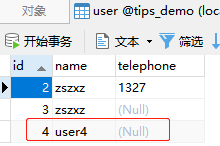
- 插入到user表中的数据
4. 复制表
检索一张表的数据全部插入另一张表。有两种方法,但不同的数据库管理系统支持不同,具体如下:
MySQL:
CREATE TABLE student_copy AS SELECT * FROM student;
-
语句分析:创建表
student_copy数据结构来源查询所有字段来自student表 -
错误SQL:
SELECT id,
nameINTO student_copy FROM student;
14. 更新
更新数据库的行使用update关键字,更新操作是个很危险的操作,在每次执行前都应该检查是否丢了where子句。
1. 更新所有行
UPDATE student_copy set age = 20;
- 语句分析:更新
student_copy表,设置字段age值为20,可看到表中所有age都变成了20; - 如果有多个字段需要更新,使用 逗号 隔开
结果:
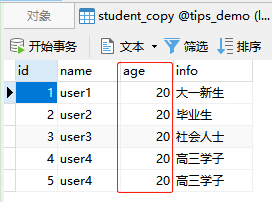
2. 更新特定的行
UPDATE student_copy SET age = 18 where id=4;
-
语句分析:更新
student_copy表,设置学生的age等于18条件是id等于4 -
结果:
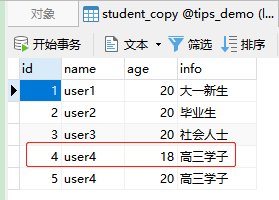
3. 更新来自查询的结果集
UPDATE student_copy INNER JOIN student on student.id = student_copy.id SET student_copy.age = student.age, student_copy.`name` = student.`name`;
- 语句分析:更新
student_copy表关联student表,条件是student表的id等于student_copy表的id,设置student_copy表的age是student表的age,name是student表的name。
15. 删除表
删除表中的行可使用delete关键字,可删除特定的行或全部,使用时先看是否丢了where子句。
1. 删除整张表数据
DELETE FROM student_copy;
- 语句分析:删除全部行,来自
student_copy表
2. 删除特定的行
DELETE FROM student WHERE id = 4;
- 语句分析:删除 行 来自
student表条件是id等于4
3. 更新和删除的建议
- 每次进行操作前检查是否丢失
where子句 - 每次操作前最好先使用
select语句验证
16. SQL分类操作
1. SQL分类
sql对数据库的操作分为三种类型,如果学会这三种SQL语言熟练对数据库操作,是登堂入室;如果学会数据库高级操作,说明对数据库有一定的使用经验;如果学会对数据库进行优化,分库分表,读写分离等操作,说明对数据库到了专家级别。
DDL:数据定义语言(Data Define Language),定义数据的结构。比如:create、drop、alter操作DML:数据管理语言(Data Manage Language),增删改查。比如:insert、delete、update、select操作DCL:数据控制语言(Data Control Language),对权限、事务等的控制。比如:grant(授权)、revoke(取回授权)、commit、roolback等。
2. 数据库基本操作
1. 连接数据库
mysql -h 地址 -P 端口 -u 用户名 -p 密码
mysql -h 192.168.0.127 -P 3306 -u root -p root
2. 查看当前数据库
SELECT DATABASES();
3. 显示用户活动线程
SHOW PROCESSLIST;
4. 显示系统变量
SHOW VARIABLES;
5. 显示当前时间,用户,数据库版本号
SELECT now(), user(), version();
6. 创建数据库
CREATE DATABASE[IF NOT EXISTS] 数据库名 [数据库选项]
- 数据库选项:
- CHARACTER SET 字符集名称
- COLLATE 排序规则名称
create database demo;
7. 删除数据库
DROP DATABASE [IF EXISTS] 数据库名;
drop database demo;
3. 建表语句
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] [库名.]表名(表的结构定义) [表选项]
-
其中
TEMPORARY表示临时表,中括号内容都表示可选,在正规的数据库版本管理开发会经常使用到。 -
字段的修饰如下数据类型:
- 非空 | 空约束:
[NOT NULL | NULL] - 默认值:
[DEFAULT default_value] - 自动增长:
[AUTO_INCREMENT] - 唯一键 | 主键:
[UNIQUE[KEY] | [PRIMARY KEY]] - 备注:
[COMMENT 'string']
- 非空 | 空约束:
-
表选项一般就是制定数据库引擎和字符集:
ENGINE=InnnoDB DEFAULT CHARSET=utf8 COMMENT=‘顾客表’
-
示例:
CREATE TABLE IF NOT EXISTS `customer` (
`id` INT AUTO_INCREMENT COMMENT '主键',
`customer_name` VARCHAR( 255 ) NULL COMMENT '顾客名称',
`gender` varchar(255) NULL COMMENT '性别',
`telephone` VARCHAR( 255 ) NULL COMMENT '电话号码',
`register_time` timestamp NULL DEFAULT NULL COMMENT '注册时间',
PRIMARY KEY ( `user_id` )
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='顾客表';
4. 修改表结构
1. 查看所有表
SHOW TABLES
2. 查看指定数据库的表
SHOW TABLES FROM 数据库名
SHOW TABLES FROM demo_database;
3. 删除表
DROP TABLE [IF EXISTS] 表名;
drop table op;
4. 清空表(清空数据)
TRUNCATE [TABLE] 表名
5. 复制表结构
CREATE TABLE 表名 LIKE 要复制的表名;
create table op like `order`;
6. 复制表结构和数据
CREATE TABLE 表名 [AS] SELECT * FROM 要复制的表名;
CREATE TABLE op AS SELECT * FROM `order`;
7. 常见的alter操作
- 追加一列(追加至末尾)
alter table [数据库名.]表名 add [column] 字段 数据类型;
alter table `order` add column `year` year;
- 增加到第一列
alter table [数据库名.]表名 add [column] 字段 数据类型 first;
- 增加一列到指定字段名后
alter table [数据库名.]表名 add [column] 字段 数据类型 after 另一个字段;
- 修改字段名的数据类型
alter table [数据库名.]表名 modify [column] 字段名 新的数据类型;
alter table `order` modify column `gender` tinyint;
- 修改表字段的数据类型,并且移动至第一列
alter table [数据库名.]表名 modify [column] 字段名 数据类型 first;
- 修改表字段的数据类型,并且移动至指定字段后面
alter table [数据库名.]表名 modify [column] 字段名 数据类型 after 另一个字段名;
- 修改表字段的名称
alter table [数据库名.]表名 change [column] 旧字段名 新字段名 数据类型;
- 添加主键
alter table [数据库名.]表名 ADD PRIMARY KEY (
字段名);
alter table `order` add primary key (`id`);
- 添加唯一键
alter table [数据库名.]表名 ADD UNIQUE [索引名] (字段名)
- 添加索引
alter table [数据库名.]表名 ADD INDEX [索引名] (字段名)
- 删除一列
alter table [数据库名.]表名 drop [column] 字段名
alter table `order` drop column `gender`;
- 删除索引
alter table [数据库名.]表名 DROP INDEX 索引名
- 删除主键
alter table [数据库名.]表名 DROP PRIMARY KEY
- 删除外键
alter table [数据库名.]表名 DROP FOREIGN KEY 外键
17. 视图
1. 视图的概念
视图是一张虚表,本质上SQL的检索语句,不存储任何的数据成分。
视图好处:
- 简化查询SQL,直接对视图进行查询,不用管视图具体生成的细节;
- 可用表的部分成为视图,保护数据,开放用户权限时,可只开放视图,而不开放实体表;
- 修改数据结构,可直接对已有的表建立视图,使用不同的表名、字段名称。
说明:
- 对视图的操作只能停留在查询上
- 如果是单表生成的视图还可以进行插入数据;如果是多表关联生成的视图,插入不会起作用
- 任何时候如果关联3张表以上就是不符合规范,严重的拖累查询性能。视图也是如此,使用复杂的嵌套视图和多表关联也会极大的降低查询性能
2. 视图的规范
- 视图是虚表,有表的部分特性:视图名 唯一,与表名类似
- 如果非管理员用户,创建视图必须有创建权限
- 视图本质是查询语句,故视图可以嵌套,可与其他表进行联结
- 视图不能有索引和触发器
3. 视图语句
视图需要MySQL5.0以上才支持
1. 创建视图与创建表类型
create view语句用于创建视图
2. 显示视图创建语句
show create view viewName
3. 删除视图
drop view viewName
4. 更新视图
create or replace view
4. 视图操作
1. 新建简单的视图示例
create view `view_order` as SELECT `id`,`order_name`,`year` FROM `order`;
- 使用
order表的id、order_name、year三个字段组成视图,as后面就是查询语句,也可以是子查询、多表关联等复杂的查询语句
2. 查询视图,其使用本质与查询表一样
SELECT * FROM `view_order`;
3. 向视图中插入数据,插入的数据直接插入到实体表order中
INSERT INTO `view_order` (`order_name`,`year`) VALUES ('小可可的订单',2021);
4. 删除视图
drop view `view_order`;
5. 小结
- 视图本质是查询语句,可对一些简单的数据统计做成视图
- 如果是开放权限给第三方公司,使用视图查询部分实体表的数据作为开放的表也是对视图的合理应用
- 可将简单的表联结成视图,简化开发
- 视图是虚表,只拥有表的部分功能
18. 存储过程
1. 存储过程的概念
概念:使用多条语句完成业务的操作。简单的定义存储过程就是多条SQL的集合。
特点:
- 使用存储过程能简化复杂的单条SQL,相比于单条复杂的SQL极大提高了性能;
- 如果表结构发生变化,只需改变存储过程使用到SQL语句的表名,如果业务逻辑发生变化,只需跳转存储过程即可,具有很强的灵活性;
- 建立一次存储过程即可使用,不用反复建立,保证开发人员使用到都是相同的存储过程,保证数据可靠性
- 总的来说就是:使用存储过程简单、灵活、安全可靠、性能好
2. 存储过程语法
1. 创建存储过程
Create PROCEDURE 存储过程名称 (参数列表)
begin
过程体
end;
2. 参数列表
IN输入
IN var1 Declmal(6,2)
OUT输出
IN var2 Decimal(6,2)
INOUT输入输出
IN var3 Decimal(6,2)
3. 变量
declare 变量名称 变量类型 [default value]
4. 执行存储过程
call 存储过程名称
5. 删除存储过程
DROP PROCEDURE 存储过程名称
6. 赋值
使用 set 和 select into 语句为变量赋值
set @var := 20
select sum(price) into total from table_name
7. if语句
f 条件 then
表达式
[elseif 条件 then
表达式]
...
[else
表达式]
end if;
8. case语句
CASE 值 WHTN 匹配值 THEN 结果
[WHEN 匹配值 THEN 结果]
......
[ELSE 结果]
END
9. while语句
[开始标签:]while 条件 do
循环体
[结尾标签]
end while;
10. loop语句
[开始标签:] loop
语句体
[结尾标签]
end loop;
11. iterate/leave语句
通过标签可以实现:
iterate表示迭代leave表示离开
12. repeat语句
repeat
--循环体
until 循环条件
end repeat;
知识点:如果用命令行学习,在写多行SQL时 使用 //可实现换行。
3. 存储过程实例
准备张表order_detail并插入几条数据
CREATE TABLE `order_detail` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`detail_name` varchar(255) DEFAULT NULL COMMENT '订单明细',
`price` decimal(10,2) DEFAULT NULL COMMENT '价格',
`oid` int(11) DEFAULT NULL COMMENT '订单id',
PRIMARY KEY (`id`)
)
1. 无参存储过程
- 查看订单明细的所有订单名称,跟普通的查询语句没区别
CREATE PROCEDURE slelect_detail ( ) BEGIN
SELECT
detail_name
FROM
order_detail;
END;
- 再调用存储过程
CALL slelect_detail ( );
-
此时就会打印内容:
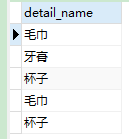
-
删除存储过程
DROP PROCEDURE slelect_detail;
2. 带入参储存过程示例
- 查询
oid为动态的所有订单明细名称,考虑到oid为动态,需要用户输入,故将oid作为入参:
CREATE PROCEDURE slelect_detail ( IN order_id INT ) BEGIN
SELECT
detail_name
FROM
order_detail
WHERE
oid = order_id;
END;
- 调用存储过程,只查询
oid为1的用户的订单明细名称
call slelect_detail(1);
- 打印内容如下:
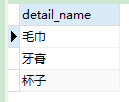
- 删除存储过程
DROP PROCEDURE slelect_detail;
3. 带入参和出参的存储过程示例
- 查询任意用户的订单明细的所有金额:定义入参订单
id为order_id,输出总金额为total
CREATE PROCEDURE slelect_toatal_money ( IN order_id INT, OUT total DECIMAL ( 8, 2 ) )
BEGIN
SELECT
sum( price ) INTO total
FROM
order_detail
WHERE
oid = order_id;
END;
- 调用存储过程示例
CALL slelect_toatal_money ( 1, @total );
- 查询
order_id为1总金额示例
SELECT @total;
- 输出结果:
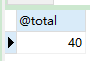
- 删除存储过程
drop PROCEDURE slelect_toatal_money;
4. if语句示例
使用控制流程,实现复杂的存储过程。
对输入的order_id自动加5,然后判断var是否小于7,如果是就查询订单明细价格,否则查询订单明细价格总和:
create procedure slelect_toatal_money(IN order_id INT)
begin
-- 定义变量
declare var int;
-- 赋值
set var= order_id+5;
-- if 判断
if var<7 then
select price from oder_detail where oid = order_id;
else
select sum(price) from oder_detail where oid = order_id;
end if;
end;
- 调用
CALL slelect_toatal_money(1);
-
查询结果:
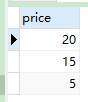
-
调用
CALL slelect_toatal_money(2);
- 查询结果:
- 删除存储过程
DROP PROCEDURE slelect_toatal_money;
5. while 语句示例
- 对 变量
var进行判断,如果var<7就指向查询价格语句,并且var进行自增
CREATE PROCEDURE slelect_toatal_money(IN order_id INT)
BEGIN
-- 定义变量
DECLARE var INT;
-- 赋值
SET var = order_id + 5;
-- while
while var < 7 DO
SELECT price FROM order_detail WHERE oid = order_id;
SET var = var + 1;
END WHILE;
END;
- 调用示例
CALL slelect_toatal_money ( 1 );
- 输出:
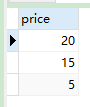
6. case语句示例
- 下边语句实现的效果与上面
if语句实现效果一致:
CREATE PROCEDURE slelect_toatal_money(IN order_id INT)
BEGIN
-- 定义变量
DECLARE var INT;
-- 赋值
SET var := order_id;
-- case 判匹配
CASE var
WHEN 1 THEN
SELECT price FROM order_detail WHERE oid = order_id;
WHEN 2 THEN
SELECT SUM(price) FROM order_detail WHERE oid = order_id;
END CASE;
END;
- 调用示例
call slelect_toatal_money(1);
- 结果:
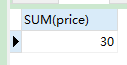
- 调用示例
CALL slelect_toatal_money(2);
- 结果:
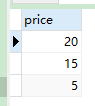
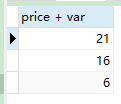
7. loop语句
- 如果
var小于3就计算价格+var的值
CREATE PROCEDURE slelect_toatal_money(IN order_id INT)
BEGIN
-- 定义变量
DECLARE var INT;
-- 赋值
SET var := order_id;
-- loop
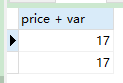
select_loop : LOOP
SELECT price + var FROM order_detail WHERE oid = order_id;
SET var = var + 1;
-- 跳出循环
IF var > 3 THEN
LEAVE select_loop;
END IF;
END loop;
END;
- 调用示例
CALL slelect_toatal_money(1);
- 结果会输出 3组结果:
- 调用示例
CALL slelect_toatal_money(2);
- 结果:
8. repeat
repest与while不同之处:while在执行之前检查条件;repest在执行之后检查条件:
CREATE PROCEDURE slelect_toatal_money(IN order_id INt)
BEGIN
-- 定义变量
DECLARE var INT;
-- 赋值
SET var = order_id + 5;
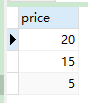
-- repeat循环
REPEAT
SELECT price FROM order_detail WHERE oid = order_id;
SET var = var + 1;
UNTIL var > 7
END REPEAT;
END;
- 调用示例
CALL slelect_toatal_money(1);
- 结果 会出现 2组相同 结果:
知识点:
loop、while、repeat、iterate都是循环loop、while、repeat功能几乎相同iterate可通过标签的形式调用循环,与leave语句使用方式一样
19. 游标
1. 游标的概念
游标本质:查询后的结果集。对查询的结果集进行前一行或后一行类似的操作时就可以使用到游标
2. 游标的语法
1. 语法
- 定义游标: declare 游标名称 cursor for 查询语句;
- 打开游标: open 游标名称
- 对查询的结果集(游标)进行检索行至变量提供使用
- 关闭游标: close 游标名称
2. 举例
create procedure 存储过程名称()
begin
– 游标 –
– xx名称,打开游标后抓取每行,将结果赋值给name
declare name varchar(20);
– 创建游标
declare 游标名称 cursor for 查询语句;
– 打开游标
open 游标名称;
– 对查询的结果集(即游标)进行检索行至变量提供使用
fetch 游标名称 into name;
select name;
– 关闭游标
close 游标名称;
end;
– 调用存储过程
call 存储过程名称;
–删除存储过程
drop procedure 存储过程名称;
3. 使用游标
1. 简单的使用游标
需求:查询oid为1的订单明细名称的结果集作为游标
- 打开游标后抓取每行将结果赋值给变量
name
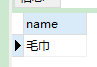
CREATE PROCEDURE printName()
BEGIN
-- 订单名称
DECLARE name VARCHAR(20);
-- 创建游标
DECLARE cur CURSOR FOR SELECT detail_name FROM order_detail WHERE oid = '1';
-- 打开游标
OPEN cur;
FETCH cur INTO name;
SELECT name;
-- 关闭游标
CLOSE cur;
END;
- 调用存储过程
CALL printName;
- 打印结果只有一条数据,说明上述方式只在游标中抓取到一条数据,而且是表里面行号最小的行:
2. 在循环中使用游标
- 将 查询oid为1 的结果集赋值给游标,通过游标抓取每行将订单明细名称和价格分别赋值给变量
name和detail_price,在循环无法继续时会出现SQLSTATE '02000',即此通过变量continue时设置done为1代表true,此时循环结束,跳出循环:
DROP PROCEDURE IF EXISTS printDetail;
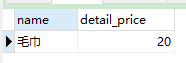
CREATE PROCEDURE printDetail()
BEGIN
-- 订单名称
DECLARE name varchar(20);
-- 价格
DECLARE detail_price DECIMAL(8,2);
-- 结束标志变量(默认为假)
DECLARE done boolean DEFAULT 0;
-- 创建游标
DECLARE cur CURSOR FOR SELECT detail_name, price FROM order_detail WHERE oid='1';
-- 指定游标循环结束时的返回值
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
-- 打开游标
OPEN cur;
-- 循环游标数据
detail_loop:LOOP
-- 根据游标当前指向的一条数据
FETCH cur INTO name, detail_price;
SELECT name, detail_price;
-- 判断游标的循环是否结束
IF done THEN
-- 跳出游标循环
LEAVE detail_loop;
END IF;
END LOOP;
-- 关闭游标
CLOSE cur;
END;
- 调用存储过程:
CALL printDetail();
- 查询结果:(不足是会多遍历最后一行,如果要精细处理还是需要自定义标志位进行跳出循环)
20. 触发器
1. 触发器的概念
触发器:当表发生改变的时候触发的动作。
例子:当往表中插入数据时,此时表发生了改变,现在想要在每次插入数据前检测所有的入参是否都是小写。此时就可以用触发器检测。
经上面分析得知,使用一个基本的触发器,至少表要发生改变,还要满足一个被触发的事件。
表发生改变通常指 增删改,其动作可以发生在增删改之前或之后,触发事件就是我们需要写的过程:
- update(after/before)
- insert(after/before)
- delete(after/before)
2. 触发器的基本语法
- 创建触发器:create trigger 触发器名称 出发动作 on 表名 for each row [触发事件]
- 删除触发器:drop trigger 触发器名称;
- 查看触发器:show trigger;
知识点:
- 触发器是依赖于表创建,没有表就没有触发器。比如视图、临时表都不是真实的表,它们是没有触发器;
- 一般来说每个表都有触发器的限制,一般最多支持6个不同类型的触发器;
- 使用触发器会频繁的改变表的每行,故其十分影响性能,特别对一些更新频率比较快的大表,如果设置触发器就非常占用系统资源;
- 一般来说触发器用在表变动较小的小表,不使用触发器就立即删除。
3. insert触发器示例
1. 创建触发器
创建一个触发器getPrice作用于order_detail表的每行,每当插入数据之后就查询这条订单明细的价格赋值给变量 @price。
NEW是一张虚表,记录着被插入数据的行,因此能在NEW表中获取每次插入的数据。
-- insert 触发器
CREATE TRIGGER getPrice AFTER INSERT ON order_detail FOR EACH ROW SELECT NEW.price INTO @price;
-- 检测插入触发器
INSERT INTO `order_detail`(`detail_name`,`price`,`oid`) VALUES ('脸盆',20.00,2);
SELECT @price;
- select @price 结果:
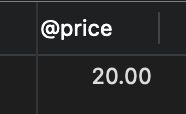
2. 删除触发器
DROP TRIGGER getPrice;
4. update触发器示例
将插入后触发器改为更新后的触发器,只需改动after insert为after update即可。
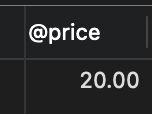
UPDATE `order_detail` SET `price` = 30.00 WHERE `id` = 2;
SELECT @price;
- 查询结果:
-- 删除触发器
DROP TRIGGER getPrice;
将更新触发器的NEW表改为OLD表
CREATE TRIGGER getPrice AFTER UPDATE ON order_detail FOR EACH ROW SELECT OLD.price INTO @price;
更新价格为40
UPDATE `order_detail` SET `price` = 40.00 WHERE `id` = 2;
此时查询价格为30,说明OLD表触发的是原始数据值
SELECT @price;
知识点:
- 更新触发器主要是要搞懂OLD存放原始数据
- NEW存放即将更新的数据
- NEW表可以设置更改值,而OLD表是只读
5. delete触发器
将 更新触发器 改为 delete触发器。之前省略了begin、end,如果是多条执行语句则需要加上:
CREATE TRIGGER getPrice AFTER DELETE ON order_detail FOR EACH ROW
BEGIN
SELECT OLD.price INTO @price;
END;
删除之前的SQL数据
DELETE FROM order_detail WHERE `id` = 2;
- 此时
id=2的数据被删除
查询价格为40,OLD表存放的是将要被删除的数据:
SELECT @price;
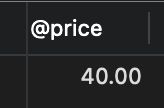
21. 用户操作
有关用户账号的信息储存MySQL的mysql数据库,故如果需要查看用户信息,则需要进入mysql数据库。
1. 查看用户信息
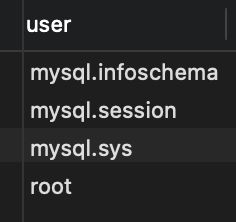
user表存储了所有的登录账号,使用MySQL库查询user表中的user:
USE mysql;
SELECT `user` FROM user;
- 打印结果:
2. 创建用户
CREATE USER 用户名 IDENTIFIED BY [PASSWORD] 密码;
示例:创建用户 Jason,并指定密码为 Python:
CREATE USER Jason IDENTIFIED BY 'Python';
然后
SELECT `user` FROM user;
查询结果
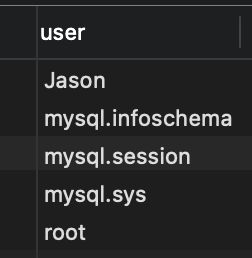
3. 重命名用户
RENAME USER 旧用户名 TO 新用户名;
示例:重命名用户Jason为Silence:
RENAME USER Jason TO Silence;
然后
SELECT `user` FROM user;
查询结果
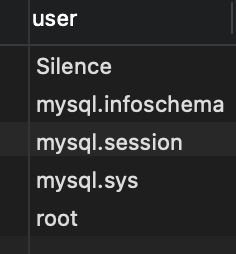
4. 删除用户
DROP USER 用户名;
示例:删除用户Silence:
DROP USER Silence;
然后查询结果则没有Silence用户了。
5. 更改密码
SET PASSWORD FRO 用户名 = PASSWORD(‘密码’)
示例:为用户Jason更改密码为py
SET PASSWORD FOR Jason = PASSWORD('py');
22. 权限操作
1. 查看用户权限
SHOW GRANTS FOR 用户名;
示例:查看用户Jason拥有的权限
SHOW GRANTS FOR Jason;
- 打印:
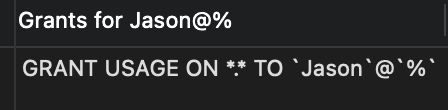
- 查询出一条权限,但
USAGE表示根本没有权限。
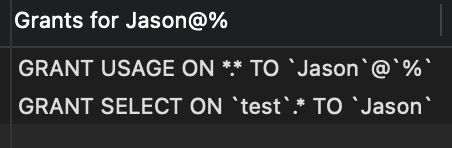
2. 赋予权限
GRANT 权限 ON 表名 TO 用户名 [IDENTIFIED BY [PASSWORD] ‘password’]
常见的权限:all、create、drop、insert、update、select。
示例:给用户Jason分配test库中所有表的查询权限
查看权限变成2条:
3. 撤销权限
REVOKE 权限列表 ON 表名 FROM 用户名;
示例:撤销用户Jason对test库里所有表的查询操作
REVOKE SELECT ON test.* FROM Jason;
4. 权限列表
使用授权,撤销权限时可参考如下权限列表:
| 权限 | 说明 |
|---|---|
| ALL | 除 GRANT OPTION 外的所有权限 |
| ALTER | 使用ALTER TABLE |
| ALTER ROUTINE | 使用 ALTER PROCEDURE 和 DROP PROCEDURE |
| CREATE | 使用 CREATE TABLE |
| CREATE ROUTINE | 使用 CREATE PROCEDURE |
| CREATE TEMPORARY TABLES | 使用CREATE TEMPORARY TABLE |
| CREATE USER | 使用CREATE USER、DROP USER、RENAME USER和REVOKE ALL PRIVILEGES |
| CREATE VIEW | 使用CREATE VIEW |
| DELETE | 使用DELETE |
| DROP | 使用DROP TABLE |
| EXECUTE | 使用CALL和存储过程 |
| FILE | 使用SELECT INTO OUTFILE和LOAD DATA INFILE |
| GRANT OPTION | 使用GRANT和REVOKE |
| INDEX | 使用CREATE INDEX和DROP INDEX |
| INSERT | 使用INSERT |
| LOCK TABLES | 使用LOCK TABLES |
| PROCESS | 使用SHOW FULL PROCESSLIST |
| RELOAD | 使用FLUSH |
| REPLICATION CLIENT | 服务器位置的访问 |
| REPLICATION SLAVE | 由复制从属使用 |
| SELECT | 使用SELECT |
| SHOW DATABASES | 使用SHOW DATABASES |
| SHOW VIEW | 使用SHOW CREATE VIEW |
| SHUTDOWN | 使用mysqladmin shutdown(用来关闭MySQL) |
| SUPER | 使用CHANGE MASTER、KILL、LOGS、PURGE、MASTER和SET GLOBAL。还允许mysqladmin调试登录 |
| UPDATE | 使用UPDATE |
| USAGE | 无访问权限 |
23. MySQL架构与锁
1. MySQL架构概览
MySQL的层级大概可以分为3类:
- 第一层:连接层,只要负责MySQL的数据库连接,安全认证的功能;
- 第二层:MySQL核心层面,主要功能包括:MySQL的查询,缓存,执行计划,优化等;
- 第三层:引擎层,为MYSQL指定不同的引擎将达到不同的数据操作效果。
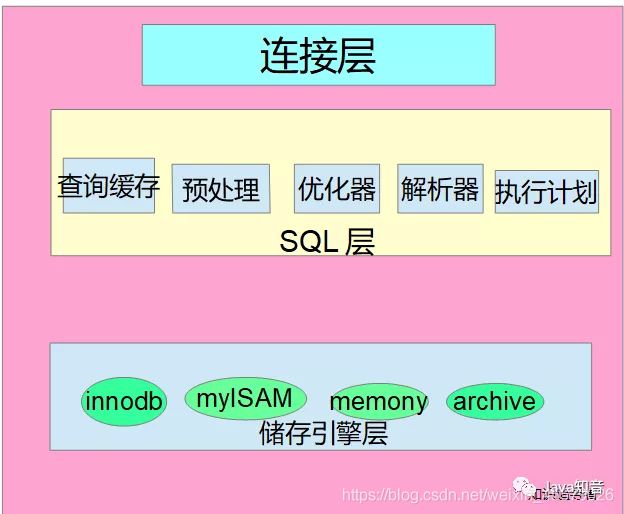
2. Query Cache
MySQL的Query Cache是基于hash值计算进行匹配的缓存机制。在大数据量的情况下如果开启Query Cache会频繁的计算Hash,会增加性能的消耗,得不偿失,在生产环境建议关闭该选项。
可使用语句:show VARIABLES like '%query_cache%'查看Query Cache是否关闭。主要关注参数query_cache_type是否关闭(OFF关闭,ON开启),不用过于关注缓存分配大小的query_cache_size参数。
3. 读锁
MySQL中根据不同的引擎,主要出现三类锁的情况:表锁、读锁、写锁。
读锁:也是共享锁,即多用户状态下同一时间对资源的读取互不影响,但不能对数据进行修改等操作。
使用场景:一般情况下手动给一条或某个范围内(一般是用在存储过程)的数据加上读锁。
读锁语法示例:
select 字段 from 表名 [where 条件] lock in share mode;
4. 写锁
写锁:是"排他锁",也称"独立锁"。
使用场景:一般是写入数据的情况,一个用户如果获得写锁,其他用户将不能获取写锁或读锁,直到该用户执行完操作并释放锁。
使用方式:在执行语句后加for update语句
写锁语法示例:
select 字段 from 表名 [where 条件] for update;
5. 锁粒度
锁粒度:对资源锁定范围的一个程度,使用不同的锁定策略达到并发性能较优的结果。
锁粒度使用策略情况分为:行锁、表锁、页锁。
1. 表锁
概念:对整张表进行加锁。
优缺点:
- 优点:性能开销较小,加锁的速度较快
- 缺点:锁粒度大,并发低
手动加表锁语法示例:
lock table 表名
释放锁:
unlock tables 表名
2. 行锁
概念:对行进行锁定。
优缺点:
- 优点:能够最大支持并发量,故锁粒度最小
- 缺点:加锁速度慢,性能消耗大,会出现死锁
行锁的种类:
- 记录锁(主键或者唯一索引)
- 间隙锁(GAP),一般用于查询条件是范围情况下,而非相等条件
- 记录锁和间隙锁的组合(next-key lock)
3. 页锁
通常情况下遇不到页锁,其开销和加锁时间介于表锁和行锁之间,会出现死锁,锁定粒度介于表锁和行锁之间。
知识点:
- MyISAM和Memory引擎支持表锁,会自动给select、update、insert、delete自动加表锁
- InnoDB支持表锁和行锁,会自动给update、insert、delete语句的数据加排他锁,select语句不加锁
4. 乐观锁
乐观锁基于版本号实现。
注意点:条件必须是主键,读取时将数据版本号读出,更新数据时,版本号加1,将查询的数据进行对比,如果版本号不一致就是过期数据。
查询示例:
select id,value,version from 表名 where id=#{id}
更新示例:
update 表名 set value=2,version=version+1 where id=#{id} and version=#{version}
5. 悲观锁
表锁、行锁、读写锁都是悲观锁。
6. 引擎简介
MySQL支持多种引擎,主流使用的引擎是InnoDB,其次是MyISAM,特殊情况下使用Memory。
1. InnoDB
使用最广泛的引擎,也是最重要的引擎。
存储性能:
- InnoDB是可重复读的事务隔离级别,但其实现了
next key lock,防止 的幻读 出现 - 基于聚簇索引实现
- 主要组成结构为内存结构、线程、磁盘文件组
2. MyISAM
MyISAM在早期版本是MySQL的默认引擎,在MySQL5.1之后不再使用。
特点:不支持事务,不支持行锁,默认表锁,并发量低
3. Memory
存储内容都是存放在引擎当中。
特点:
- 优点:支持Hash和Btree索引,其数据读取快
- 缺点:服务器如果出现故障重启后就会造成数据丢失
24. 锁等待
锁等待,就是session(事务会话,开启一个事务代表一个会话) A 对某行数据获取独占锁(一般就是写锁),然后session B 对相同的行进行获取独占锁就发生了锁等待。MySQL有一个保留参数innodb_lock_wait_timeout指定死锁的时间,如果超过死锁等待时间就是报异常。
示例:
- session A 执行如下语句,开启事务,更新索引为1的语句;此时session A 获取了id=1这条语句的写锁权限:
begin
update `order` set `year`='2021' where id='1';
- session B执行如下语句,跟上面的语句一样,由于id=1这条数据的写锁已经被session A获取,故会发生锁等待的情况:
begin
update `order` set `year`='2021' where id='1';
- 等待50秒,报异常:
lock wait timeout exceeded; try restarting transaction
- 查看默认锁等待语句
show BARIABLES like 'innodb_lock_wait_timeout'
25. 死锁
1. 死锁的产生
两个以上的会话在抢占资源过程中,产生互相等待的情况。
死锁建立在锁等待的基础上,session A 获取id=1的写锁,session B 获取id=2的写锁,此时由于索引不同,顾不会发生锁等待现象;当session A 尝试获取id=2的写锁时,由于id=2已经被session A获取,此时产生锁等待,由于 sessionA 和 session B 同时都在锁等待状态,产生了等待对方释放锁,故会产生死锁。
示例:
- session A 执行语句,获取id=1的写锁权限:
BEGIN;
UPDATE `order` SET `year`='2021' WHERE id=1;
- session B 执行语句,获取id=2的写锁权限:
BEGIN;
UPDATE `order` SET `year`='2022' WHERE id=2;
- session A 执行语句,尝试获取id=2的写锁权限,进入锁等待状态:
UPDATE `order` SET `year`='2022' WHERE id=2;
- session B 执行语句,尝试获取id=1的写锁权限,进入锁等待状态:
update `order` set `year`= '2022' where id = '1';
当 B 进入 锁等待后就直接报死锁异常
Deadlock found when trying to get lock; try restarting transaction
2. 查看死锁
可使用 show engine innodb status 查看死锁
......
*** (1) TRANSACTION: // 事物A
TRANSACTION 253507, ACTIVE 474 sec starting index read
mysql tables in use 1, locked 1 // 已经使用一个锁
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 17001, OS thread handle 139824777217792, query id 2191731 ......
root updating
update `order` set `year`= '2022' where id = '2'//执行得语句
*** (1) WAITING FOR THIS LOCK TO BE GRANTED: // 等待锁释放获取锁
RECORD LOCKS space id 65 page no 3 n bits 80 index PRIMARY of table `zszxz`.`order` trx id 253507 lock_mode X locks rec but not gap waiting
.....
*** (2) TRANSACTION: // 事物 B
TRANSACTION 253508, ACTIVE 425 sec starting index read
mysql tables in use 1, locked 1 // 已经使用一个锁
3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 17002, OS thread handle 139824778569472, query id 2191735 ......
root updating
update `order` set `year`= '2022' where id = '1'//执行得语句
*** (2) HOLDS THE LOCK(S): //持有锁
RECORD LOCKS space id 65 page no 3 n bits 80 index PRIMARY of table `zszxz`.`order` trx id 253508 lock_mode X locks rec but not gap
......
*** (2) WAITING FOR THIS LOCK TO BE GRANTED: // 等待锁释放获取锁
RECORD LOCKS space id 65 page no 3 n bits 80 index PRIMARY of table `zszxz`.`order` trx id 253508 lock_mode X locks rec but not gap waiting
......
字母代表锁的类型如下:
- 共享锁(S)
- 排他锁(X)
- 意向共享(IS)
- 意向排他(IX)
- gap lock(GK) 间隙锁,锁定一个范围,不包括当前记录本身
- RECORD LOCKS 代表记录锁
可以看出上面的语句(1)代表 事务A,MySQL线程ID17001,(2)代表 事务B,MySQL线程ID17002,事务A与B都在等待对方释放锁,产生了死锁。
知识点:
- 查看表锁:
show status like 'table%';
解决死锁:
- 查找到死锁线程,杀死MySQL死锁的线程(kill命令)
- 如果事务未提交,直接回滚事务
3. 如何避免死锁
- 在死锁容易产生的表使用表锁不会产生死锁;
- 避免交叉使用相同的锁。