Sentinel 实战-集群限流
集群流控
假如你的应用有多个实例,那么你设置了限流的规则之后,每一台应用的实例都会生效相同的流控规则,如下图所示:
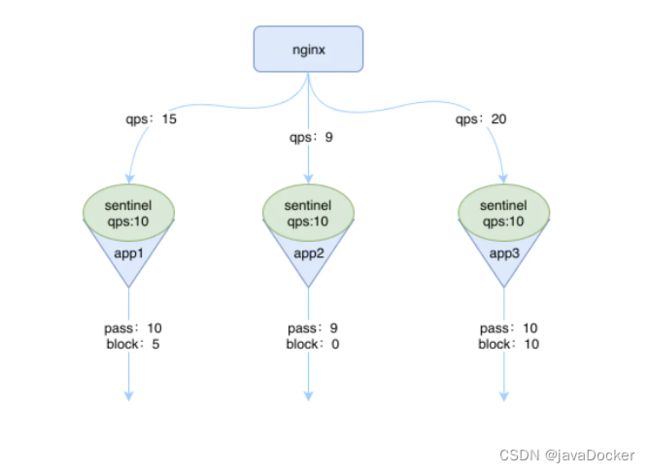
假设我们设置了一个流控规则,qps是10,那么就会出现如上图所示的情况,当qps大于10时,实例中的 sentinel 就开始生效了,就会将超过阈值的请求 block 掉。
上图好像没什么问题,但是细想一下,我们可以发现还是会有这样的问题:
- 假设集群中有 10 台机器,我们给每台机器设置单机限流阈值为 10 qps,理想情况下整个集群的限流阈值就为 100 qps。不过实际情况下路由到每台机器的流量可能会不均匀,会导致总量没有到的情况下某些机器就开始限流。
- 每台单机实例只关心自己的阈值,对于整个系统的全局阈值大家都漠不关心,当我们希望为某个 api 设置一个总的 qps 时(就跟为 api 设置总的调用次数一样),那这种单机模式的限流就无法满足条件了。
基于种种这些问题,我们需要创建一种集群限流的模式,这时候我们很自然地就想到,可以找一个 server 来专门统计总的调用量,其它的实例都与这台 server 通信来判断是否可以调用。这就是最基础的集群流控的方式。
原理
这个专门的用来统计数据的称为 Sentinel 的 token server,其他的实例作为 Sentinel 的 token client 会向 token server 去请求 token,如果能获取到 token,则说明当前的 qps 还未达到总的阈值,否则就说明已经达到集群的总阈值,当前实例需要被 block,如下图所示:

集群流控中共有两种身份:
- token client:集群流控客户端,用于向所属 token server 通信请求 token。集群限流服务端会返回给客户端结果,决定是否限流。
- token server:即集群流控服务端,处理来自 token client 的请求,根据配置的集群规则判断是否应该发放 token(是否允许通过)。
而单机流控中只有一种身份,每个 sentinel 都是一个 token server。
需要注意的是,集群限流中的 token server 是单点的,一旦 token server 挂掉,那么集群限流就会退化成单机限流的模式。在 ClusterFlowConfig 中有一个参数 fallbackToLocalWhenFail 就是用来确定当 client 连接失败或通信失败时,是否退化到本地的限流模式的。
Sentinel 集群流控支持限流规则和热点规则两种规则,并支持两种形式的阈值计算方式:
- 集群总体模式:即限制整个集群内的某个资源的总体 qps 不超过此阈值。
- 单机均摊模式:单机均摊模式下配置的阈值等同于单机能够承受的限额,token server 会根据连接数来计算总的阈值(比如独立模式下有 3 个 client 连接到了 token server,然后配的单机均摊阈值为 10,则计算出的集群总量就为 30),按照计算出的总的阈值来进行限制。这种方式根据当前的连接数实时计算总的阈值,对于机器经常进行变更的环境非常适合。
部署方式
token server 有两种部署方式:
- 一种是独立部署,就是单独启动一个 token server 服务来处理 token client 的请求,如下图所示:
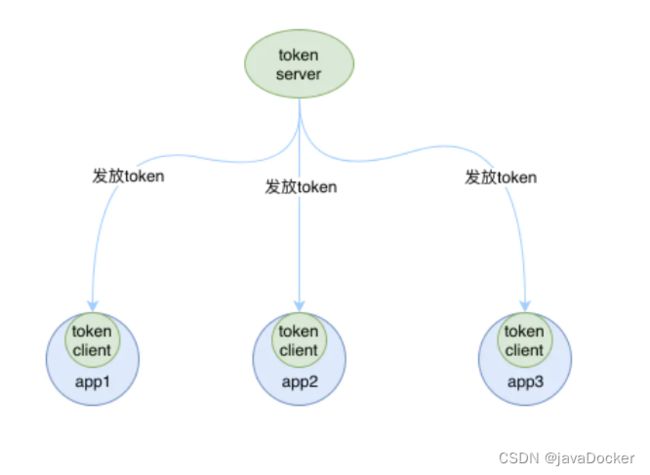
如果独立部署的 token server 服务挂掉的话,那其他的 token client 就会退化成本地流控的模式,也就是单机版的流控,所以这种方式的集群限流需要保证 token server 的高可用性。
- 一种是嵌入部署,就是在多个 sentinel-core 中选择一个实例设置为 token server,随着应用一起启动,其他的 sentinel-core 都是集群中 token client,如下图所示:
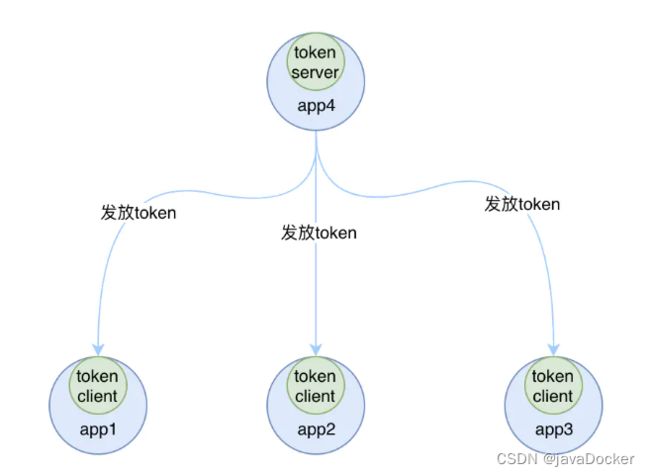
嵌入式部署的模式中,如果 token server 服务挂掉的话,我们可以将另外一个 token client 升级为token server来,当然啦如果我们不想使用当前的 token server 的话,也可以选择另外一个 token client 来承担这个责任,并且将当前 token server 切换为 token client。Sentinel 为我们提供了一个 api 来进行 token server 与 token client 的切换:
http://:/setClusterMode?mode= 其中 mode 为 0 代表 client,1 代表 server,-1 代表关闭。
注意事项
集群流控能够精确地控制整个集群的 qps,结合单机限流兜底,可以更好地发挥流量控制的效果。
还有更多的场景等待大家发掘,比如:
- 在 API Gateway 处统计某个 api 的总访问量,并对某个 api 或服务的总 qps 进行限制
- Service Mesh 中对服务间的调用进行全局流控
- 集群内对热点商品的总访问频次进行限制
尽管集群流控比较好用,但它不是万能的,只有在确实有必要的场景下才推荐使用集群流控。
另外若在生产环境使用集群限流,管控端还需要关注以下的问题:
- Token Server 自动管理(分配/选举 Token Server)
- Token Server 高可用,在某个 server 不可用时自动 failover 到其它机器
常见的限流算法
计数器算法指在一段时间内,进行计数,与阀值进行比较,如果超过了阀值则进行限流操作,到了时间临界点,将计数器清零进行重新基数,即单位时间段内可访问请求的次数进行控制。计数器算法是一种比直观简单的限流算法,常用于应用服务对外提供的接口层面。
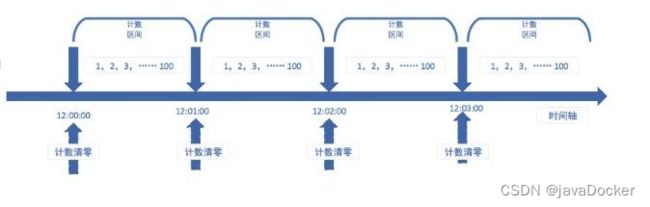
由于计数器算法存在时间临界点缺陷,因此在时间临界点左右的极短时间段内容易遭到攻击。比如设定每分钟最多可以请求100次某个接口,如12:00:00-12:00:59时间段内没有数据请求,而12:00:59-12:01:00时间段内突然并发100次请求,而紧接着跨入下一个计数周期,计数器清零,在12:01:00-12:01:01内又有100次请求。那么也就是说在时间临界点左右可能同时有2倍的阀进行请求,从而造成后台处理请求过载的情况,导致系统运营能力不足,甚至导致系统崩溃。
滑动窗口算法是指把固定时间片进行划分,并且随着时间的流逝进行移动,通过这种方式可以巧妙的避开计数器的临界点的问题。也就是说这些固定数量的可以移动的格子,将会进行计数判断阀值,因此格子的数量影响着滑动窗口算法的精度。
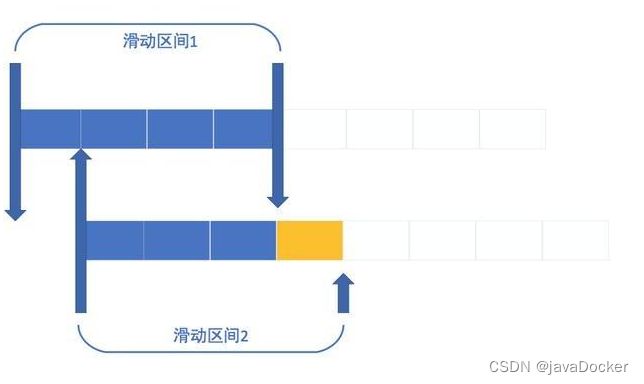
滑动窗口算法可以有效的规避计数器算法中时间临界点的问题,但是仍然存在时间片段的概念。同时滑动窗口算法计数运算也相对计数器算法比较耗时。时间片段越精确,流量控制越精密,从而导致计算耗时越长。
漏桶算法设计思路比较直观简单,即水(请求)以不确定的速率先进入到漏桶里,然后漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率。因此漏桶算法在这方面比滑动窗口而言,更加先进。

漏桶算法需要设定两个参数,一个是桶的容量大小用,用来决定最多可以存放多少水(请求),一个是水桶漏的大小,即出水速率,即出水速率决定单位时间向服务器请求的平均次数。因此漏桶算法存在如下两个问题:
漏桶的漏出速率是固定的参数,所以即使网络中不存在资源冲突(没有发生拥塞),漏桶算法也不能使流突发到端口速率提高。因此漏桶算法对于存在突发特性的流量来说缺乏效率。漏桶的漏出速率是固定的参数同时水桶容量大小限制,那么意味着如果瞬时流量增大且超过水桶水桶容量的话,将有部分请求被丢弃掉(也就是所谓的溢出)。
令牌桶算法令牌桶算法是和水桶算法效果一样但方向相反的算法。随着时间流逝,系统会按恒定时间间隔往桶里加入制定数量的水,如每100毫秒往桶里加入1000毫升的水,如果桶已经满了就不再加了(说明:令牌桶算法和漏桶算法相反,漏桶算法是按照客户请求的数量往漏桶中加水的,而令牌桶算法是服务器端控制往桶里加水的)。当有新请求来临时,会各自从桶里拿走一个令牌,如果没有令牌可拿了就阻塞或者拒绝服务。
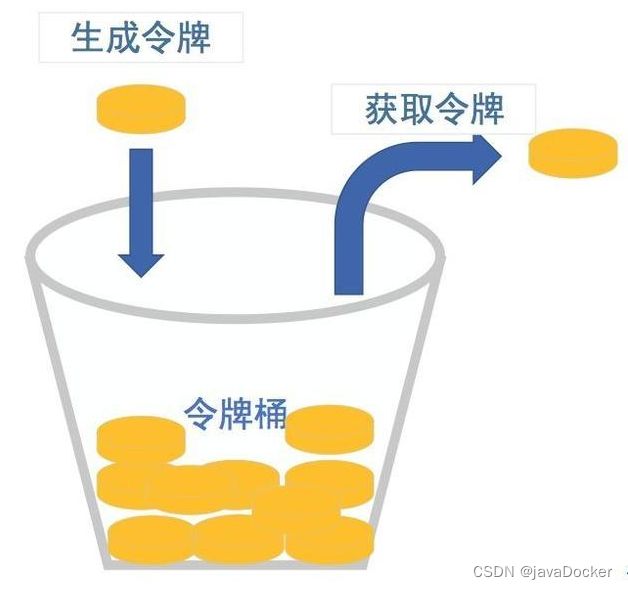
令牌桶算法的优点如下:
服务器端可以根据实际服务性能和时间段改变改变生成令牌的速度和水桶的容量。 一旦需要提高速率,则按需提高放入桶中的令牌的速率。生成令牌的速度是恒定的,而请求去拿令牌是没有速度限制的。这意味着当面对瞬时大流量,该算法可以在短时间内请求拿到大量令牌,而且拿令牌的过程并不是消耗很大的事情。算法总计:以上四种算法均可以达到流量控制的目的,不论是对于令牌桶拿不到令牌被拒绝,还是漏桶的水满了溢出,都是为了保证大部分流量的正常使用,而牺牲掉了少部分流量,这是符合设计规范和运营需求且合理的算法。如因极少部分流量需要保证可能导致系统达到极限而挂掉,则得不偿失。