数据结构03:栈、队列和数组
前言
参考用书:王道考研《2024年 数据结构考研复习指导》
参考用书配套视频:3.1.1_栈的基本概念_哔哩哔哩_bilibili
特别感谢:ChatGPT3.5老师,检查其它同学的作业是从代码里找BUG,检查我的作业是恰恰是相反的...️

封面来源:BING AI老师
考研笔记整理,内容包含栈、队列和数组的基本定义,经典案例:斐波那契数列、括号匹配、表达式求值、树的层次遍历、C#/C++代码写成~考研一起加油~
第1版:查资料、绘制导图、画配图、写Bug、增加注释~
第2版:增加目录、增加封面、增加文章摘要,换了一个清楚一点的思维导图~
目录
前言
目录
思维导图
栈
栈的定义与性质
顺序栈的实现与基本运算
顺序栈定义
顺序栈的存储类型
顺序栈初始化与判断栈空
顺序栈进栈与出栈
顺序栈记录栈顶元素
栈的小案例
顺序栈小案例1:入栈出栈(代码)
链栈小案例1:入栈出栈(代码)
顺序栈小案例2:斐波那契数列(代码)
顺序栈小案例3:括号匹配(代码)
顺序栈小案例4:表达式求值(代码)
顺序共享栈定义
队列
队列的定义与性质
循环队列的实现与基本运算
循环队列定义
循环队列的存储类型
循环队列初始化与判断队空
循环队列入队与出队
链式队列的实现与基本运算
链式队列定义
链队列的存储类型
链队列初始化与判断队空
循环队列入队与出队
队的小案例
队列小案例1:顺序二叉树的层次遍历(代码)
队列小案例2:链式二叉树的层次遍历(代码)
队列小案例3:过河问题(代码)
双端队列定义
数组和特殊矩阵
数组的定义
特殊矩阵
稀疏矩阵
结语
思维导图
思维导图备注:
- 二维数据,也就是矩阵在逻辑结构严格意义上不是线性表,不过存储时可以映射在一维数组上,因此此处列在线性表推广中~
- 串作为第4章的内容,在同系列博文中数据结构04:串的存储结构与KMP算法~~
栈
栈的定义与性质
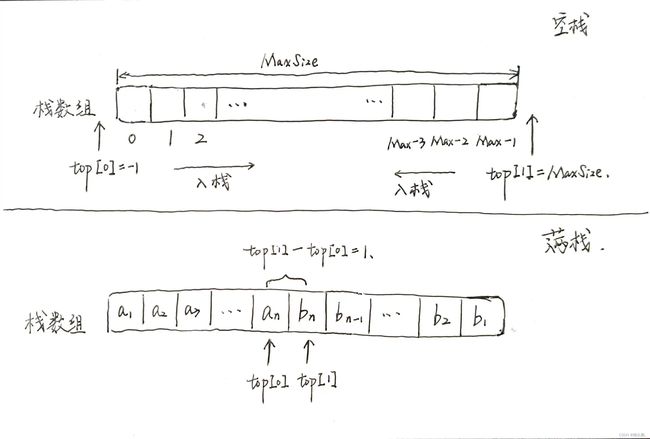
栈的定义:只允许在一端进行插入或者删除操作的线性表。
栈的操作特性:后进先出(Last In First Out, LIFO)。
栈的数学性质:n个不同的元素进展,出栈元素的不同排列个数如下图,该公式成为卡特兰数。
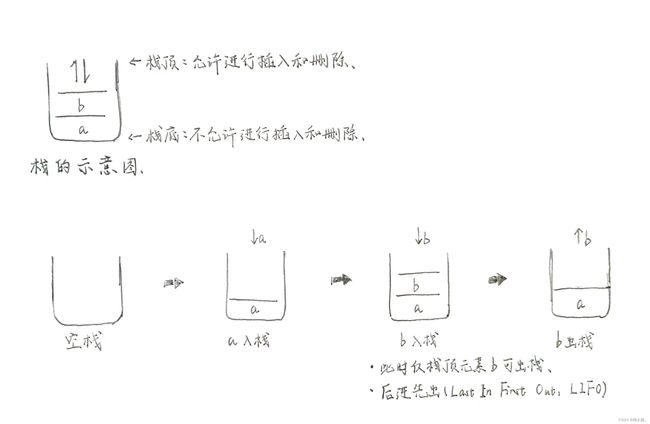
 栈的操作流程大概是这样的~
栈的操作流程大概是这样的~
顺序栈的实现与基本运算
顺序栈定义
采用顺序存储的栈称为顺序栈,它利用一组地址连续的存储单元存放自栈底到栈顶的数据元素,同时附设一个指针(top)指示当前元素的位置。
以下我们先介绍顺序栈基本操作的代码,后面再通过进出栈的小小案例加深理解。
顺序栈的存储类型
存储类型:采用结构体typedef定义顺序栈SqStack,内容包括 栈的最大个数Maxsize、栈中的元素类型 Elemtype(根据实际需要修改)、栈顶指针top。
#define Maxsize 50
//定义栈中元素的最大个数
typedef struct{
Elemtype data[Maxsize];
//存放栈中元素
int top;
//存放栈顶指针
} SqStack;
//定义结构体名称为顺序栈顺序栈初始化与判断栈空
初始化:栈顶指针top指向栈顶元素的位置;如果栈内没有元素,则标注为-1表示栈空,因此,初始化时同样标注栈顶指针top=-1。
void InitStack(SqStack &S) {
S.top = -1;
//初始化栈顶指针-1
}判断栈空:
bool StakeEmpty(SqStack S) {
if(S.top = -1)
return true;
else
return false;
//判断栈顶指针是否为-1
}顺序栈进栈与出栈
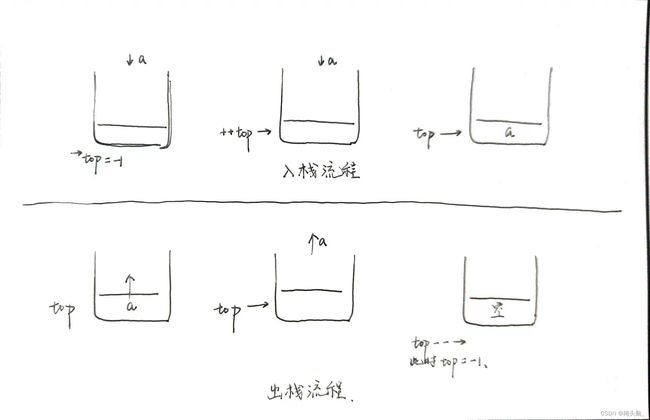
进栈:判断栈是否为满,若栈已满,则拒绝操作;若栈非满,栈顶top指针先+1,然后放入需要的元素。
bool Push(SqStack &S, Elemtype &x) {
//判断栈是否为满
if (S.top == Maxsize - 1)
return false;
//存入元素
S.data[++S.top] = x;
return true;
}出栈:判断栈是否为空,若栈已空,则拒绝操作;若栈非空,栈顶top指针指向的元素先出栈,然后指针-1。
bool Pop(SqStack &S, Elemtype &x) {
//判断栈是否为空
if (S.top == -1)
return false;
//取出元素
x = S.data[S.top--];
return true;
}简单来说就是这个样子:[++S.top],加号在前表示先执行指针移位,再进行赋值操作;[S.top--],减号在后表示先执行出栈操作,再进行指针移位操作~
顺序栈记录栈顶元素
bool Gettop(SqStack S, Elemtype &x) {
//判断栈是否为空
if(S.top = -1)
return false;
//若栈不为空,x记录栈顶元素
x=S.data[S.top];
return true;
}栈的小案例
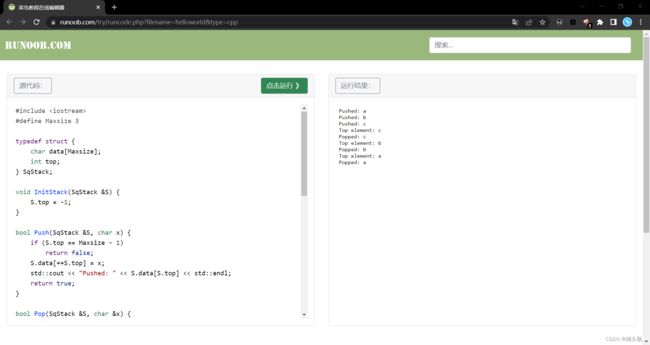
顺序栈小案例1:入栈出栈(代码)
案例:执行一个这样的操作,输入a,b,c三个元素,然后依次输出栈中所有元素直至栈空~
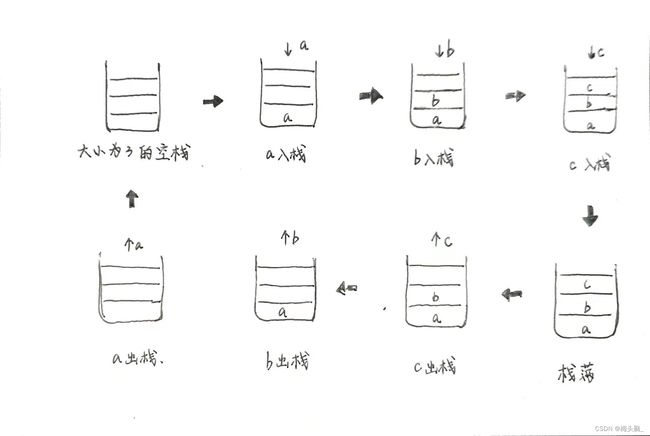
算法思想:初始化顺序栈,封装好初始化InitStake,入栈Push,出栈Pop 以后,增加一个面函数依次调用这些模块,并且增加输出的过程,如下所示~
#include
#define Maxsize 3
typedef struct {
char data[Maxsize];
int top;
} SqStack;
void InitStack(SqStack &S) {
S.top = -1;
}
bool Push(SqStack &S, char x) {
if (S.top == Maxsize - 1)
return false;
S.data[++S.top] = x;
std::cout << "Pushed: " << S.data[S.top] << std::endl;
return true;
}
bool Pop(SqStack &S, char &x) {
if (S.top == -1)
return false;
x = S.data[S.top--];
std::cout << "Popped: " << x << std::endl;
return true;
}
int main() {
SqStack M;
InitStack(M);
char a = 'a', b = 'b', c = 'c';
Push(M, a);
Push(M, b);
Push(M, c);
if (M.top != -1)
std::cout << "Top element: " << M.data[M.top] << std::endl;
char popped;
while (Pop(M, popped)) {
if (M.top != -1)
std::cout << "Top element: " << M.data[M.top] << std::endl;
}
return 0;
} 执行的结果大概是这样子的~
链栈小案例1:入栈出栈(代码)
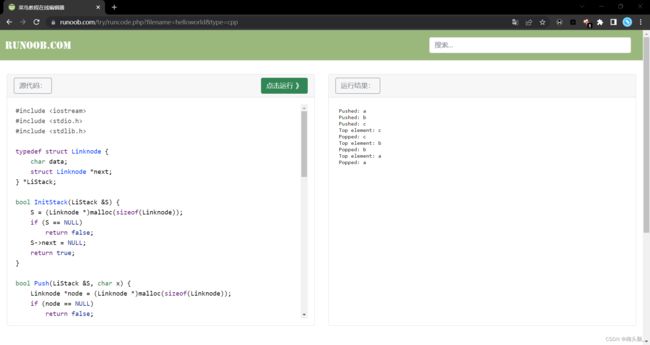
案例:同上,输入a,b,c三个元素,然后依次输出栈中所有元素直至栈空~
算法思想:初始化链栈,封装好初始化InitStake,入栈Push,出栈Pop 以后,增加一个面函数依次调用这些模块,并且增加输出的过程,如下所示~
#include
#include
#include
typedef struct Linknode {
char data;
struct Linknode *next;
} *LiStack;
bool InitStack(LiStack &S) {
S = (Linknode *)malloc(sizeof(Linknode));
if (S == NULL)
return false;
S->next = NULL;
return true;
}
bool Push(LiStack &S, char x) {
Linknode *node = (Linknode *)malloc(sizeof(Linknode));
if (node == NULL)
return false;
node->data = x;
node->next = S->next;
S->next = node;
std::cout << "Pushed: " << x << std::endl;
return true;
}
bool Pop(LiStack &S, char &x) {
if (S->next == NULL)
return false;
Linknode *temp = S->next;
x = temp->data;
S->next = temp->next;
free(temp);
std::cout << "Popped: " << x << std::endl;
return true;
}
int main() {
LiStack M;
if (!InitStack(M)) {
std::cout << "Stack initialization failed!" << std::endl;
return 1;
}
char a = 'a', b = 'b', c = 'c';
Push(M, a);
Push(M, b);
Push(M, c);
if (M->next != NULL)
std::cout << "Top element: " << M->next->data << std::endl;
char popped;
while (Pop(M, popped)) {
if (M->next != NULL)
std::cout << "Top element: " << M->next->data << std::endl;
}
return 0;
}
执行的结果大概是这样子的~
顺序栈小案例2:斐波那契数列(代码)
案例:函数典中典例题斐波那契,F0=0(n=0),F1=1(n=1),Fn=Fn-1+Fn-2(n>0),也就是那个0、1、1、2、3、5、8...的数列~
算法思想1:递归实现~
- 把这个函数F0=0(n=0),F1=1(n=1),Fn=Fn-1+Fn-2(n>0)写成代码的形式并封装;
- 面函数内实现 输入n值 与 输出计算值~
#include
int Fib(int n) {
if (n == 0)
return 0;
else if (n == 1)
return 1;
else
return Fib(n - 1) + Fib(n - 2);
}
int main() {
int i = 0;
printf("Enter a value: ");
scanf("%d", &i);
int result = Fib(i);
printf("Result: %d\n", result);
return 0;
}
递归的算法代码相对简洁,但是执行效率较低,计算的过程中会有重复步骤,递归次数过多可能还会造成栈溢出~
算法思想2:非递归实现~
- 记录当前变量及其前两个变量的值,而后相加~
- 面函数写一个输入的n值和输出的计算值~
#include
int fib(int n) {
if (n <= 1)
return n;
int prev = 0;
int curr = 1;
for (int i = 2; i <= n; i++) {
int next = prev + curr;
prev = curr;
curr = next;
}
return curr;
}
int main() {
int n;
printf("Enter a number: ");
scanf("%d", &n);
int result = fib(n);
printf("Fibonacci number at position %d: %d\n", n, result);
return 0;
}
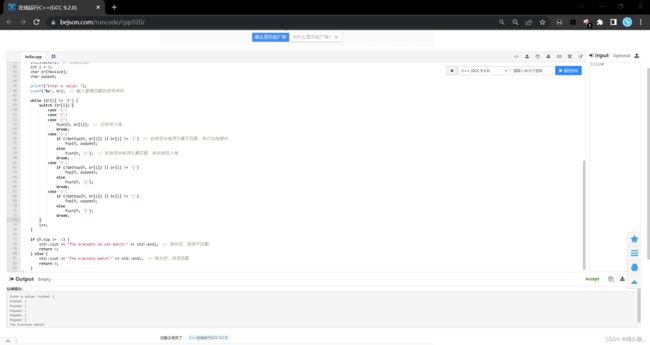
顺序栈小案例3:括号匹配(代码)
案例:以王道书后应用习题01为例,假设一个算数表达式中包括圆括号、方括号和花括号3种类型的括号,编写1个算法来判别表达式中的括号是否配对,以0作为算数表达式的结束符。
算法思想:
- 初始化一个空栈,顺序读入符号;
- 若是左括号,则压入栈顶;
- 若是右括号,则比较栈顶是否有对应的左括号,如果有则消解,如果没有则压入栈顶;
- 算法结束时,如果栈为空则成功,不为空则匹配失败。
#include
#include
#define Maxsize 10
typedef struct {
char data[Maxsize];
int top;
} SqStack;
void InitStack(SqStack &S) {
S.top = -1; // 初始化栈顶指针为-1,表示空栈
}
bool Gettop(SqStack S, char &x) {
if (S.top == -1) // 栈空,无法获取栈顶元素
return false;
x = S.data[S.top]; // 获取栈顶元素的值
return true;
}
bool Push(SqStack &S, char x) {
if (S.top == Maxsize - 1) // 栈满,无法继续入栈
return false;
S.data[++S.top] = x; // 栈顶指针加1,将元素x入栈
std::cout << "Pushed: " << S.data[S.top] << std::endl;
return true;
}
bool Pop(SqStack &S, char &x) {
if (S.top == -1) // 栈空,无法进行出栈操作
return false;
x = S.data[S.top--]; // 将栈顶元素弹出,并将栈顶指针减1
std::cout << "Popped: " << x << std::endl;
return true;
}
int main() {
SqStack M;
InitStack(M); // 初始化栈M
int i = 0;
char br[Maxsize];
char popped;
printf("Enter a value: ");
scanf("%s", br); // 输入需要匹配的括号序列
while (br[i] != '0') {
switch (br[i]) {
case '(':
case '[':
case '{':
Push(M, br[i]); // 左括号入栈
break;
case ')':
if (!Gettop(M, br[i]) || br[i] != '(') // 右括号与栈顶元素不匹配,执行出栈操作
Pop(M, popped);
else
Push(M, ')'); // 右括号与栈顶元素匹配,将右括号入栈
break;
case ']':
if (!Gettop(M, br[i]) || br[i] != '[')
Pop(M, popped);
else
Push(M, ']');
break;
case '}':
if (!Gettop(M, br[i]) || br[i] != '{')
Pop(M, popped);
else
Push(M, '}');
break;
}
i++;
}
if (M.top != -1) {
std::cout << "The brackets do not match!" << std::endl; // 栈非空,括号不匹配
return 0;
} else {
std::cout << "The brackets match!" << std::endl; // 栈为空,括号匹配
return 0;
}
}
在这个网站里测试了一下,应该是能跑的~~ 在线运行C++(GCC 9.2.0)
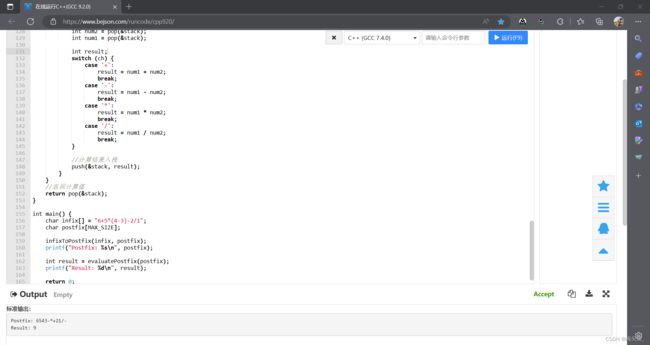
顺序栈小案例4:表达式求值(代码)
案例:6+5*(4-3)-2/1
备注:这在我眼里真的算是小难题了,很没有出息地希望这个不会考,不然我真的会写废草纸...::>_<::
算法思想:
- 初始化三个空栈~
| 栈expreesion | 读取 整理后缀表达式~ | 栈expreesion+symbol: 转换中缀表达式→后缀表达式~ |
| 栈symbol | 暂存 运算符、括号~ | |
| 栈operation | 完成 表达式求值~ | - |
- 转换表达式:后缀表达式为数字在前,运算符在后的形式,这个有一点复杂,可以参考【C语言】后缀表达式转换(中缀->后缀)_人在圣朱尼佩洛的博客-CSDN博客~
- 表达式求值:循环,从前向后扫描后缀表达式:(1)若为数字,则压入栈中;(2)若为运算符,则弹出两个数字A和B,运算 数字A<运算>数字B,并将计算结果压回栈x 中。
- 循环结束,弹出结果。
以下是整理中缀转后缀的过程,因为看大佬的博客很迷茫,就花了点时间推了一下...

写代码总是出现编译错误,改掉编译错误又出现执行错误,整个人是崩溃的...已经在这道题上浪费了半天,emm...浪费这么长的时间解决1个问题真的已经是考研大忌,等我去新手村练级刷经验以后再回来挑战boss~~
所以我这边放两份稿件:第1段是会出现执行错误的问题,作为留底日后修改,也烦请路过的小伙伴指正;第2段是ChatGPT完全重写的可以运行的代码~
//注:该段代码运行有问题,执行报错
#include
#include
#include
//算式栈expression,存放后缀表达式
typedef struct {
char e[10];
int top;
} expression;
//符号栈Symbol,暂存后缀表达式的部分运算符
typedef struct {
char s[10];
int top;
} symbol;
//计算栈Opration,用于计算后缀表达式
typedef struct {
int n[10];
int top;
} operation;
//声明全局变量
operation operationStack;
expression expressionStack;
symbol symbolStack;
//运算符的优先级:【'*'、'/'】 > 【'+'、'-'】 > 【其它】
int replace(char a) {
switch (a) {
case '+': return 1;
case '-': return 1;
case '*': return 2;
case '/': return 2;
default: return 0;
}
}
//运算符的优先级比较:temp为当前待定运算符,top为符号栈Symbol的栈顶运算符
int compare(char top, char temp) {
return (replace(top) >= replace(temp)) ? 1 : 0;
}
//后缀表达式转换
void reversePolish(char ex[]) {
for (int i = 0; ex[i] != '\0'; i++) {
if (ex[i] <= '9' && ex[i] >= '1') {
//若字符为0-9,直接添加到算式栈 expression
expressionStack.e[++expressionStack.top] = ex[i];
} else {
//若符号栈Symbol 为空,当前运算符压入符号栈Symbol
if (symbolStack.top == -1) {
symbolStack.s[++symbolStack.top] = ex[i];
continue;
}
//若当前运算符为 '(',当前运算符压入符号栈Symbol
if (ex[i] == '(') {
symbolStack.s[++symbolStack.top] = ex[i];
continue;
}
//若当前运算符为')',则将符号栈Symbol'('与')'之间的运算符出栈 压入算式栈 expression
if (ex[i] == ')') {
while (symbolStack.s[symbolStack.top] != '(') {
expressionStack.e[++expressionStack.top] = symbolStack.s[symbolStack.top];
symbolStack.top--;
}
symbolStack.top--;
continue;
}
//比较运算符栈顶运算符symbol.s[symbol.top],与待定运算符ex[i]的优先级
if (compare(symbolStack.s[symbolStack.top], ex[i])) {
//若栈顶运算符symbol.s[symbol.top]>待定运算符ex[i],将待定运算符ex[i]添加到符号栈symbol栈顶
symbolStack.s[++symbolStack.top] = ex[i];
/*若栈顶运算符symbol.s[symbol.top]≤待定运算符ex[i],
将运算符Symbol栈顶运算符出栈,压入算式栈 expression,并将当前ex[i]压入运算符栈,再与前一位运算符比较,
循环上述操作,直到运算符栈顶运算符Symbol优先级大于它的前一位运算符*/
} else {
expressionStack.e[++expressionStack.top] = symbolStack.s[symbolStack.top];
symbolStack.s[symbolStack.top] = ex[i];
while (!compare(symbolStack.s[symbolStack.top - 1], symbolStack.s[symbolStack.top]) && symbolStack.top > 0) {
expressionStack.e[++expressionStack.top] = symbolStack.s[symbolStack.top - 1];
symbolStack.s[symbolStack.top - 1] = symbolStack.s[symbolStack.top];
symbolStack.top--;
}
}
}
}
//扫描到最后末位之后,将运算符栈Symbol剩余的运算符依次出栈并压入数据算式栈expression
while (symbolStack.top != -1) {
expressionStack.e[++expressionStack.top] = symbolStack.s[symbolStack.top];
symbolStack.top--;
}
}
//输出后缀表达式
void printList() {
for (int i = 0; i <= expressionStack.top; i++) {
printf("%c", expressionStack.e[i]);
}
printf("\n");
}
//计算后缀表达式
int operate(char ex[]) {
for (int i = 0; ex[i] != '\0'; i++) {
//若字符为0-9,直接添加到计算栈Opration
if (ex[i] <= '9' && ex[i] >= '1') {
operationStack.n[++operationStack.top] = ex[i];
//若为运算符,则位于计算栈Opration栈顶的2个数字退栈
} else {
int num1 = operationStack.n[operationStack.top--];
int num2 = operationStack.n[operationStack.top--];
int sum = 0;
//执行退栈两个元素的运算
switch (ex[i]) {
case '+': sum = num1 + num2; break;
case '-': sum = num1 - num2; break;
case '*': sum = num1 * num2; break;
case '/': sum = num1 / num2; break;
}
//运算结果存入栈中
operationStack.n[++operationStack.top] = sum;
//输出运算结果
printf("%d\n", sum);
}
}
//返回运算结果
return operationStack.n[operationStack.top];
}
int main() {
expressionStack.top = -1; //初始化栈
symbolStack.top = -1;
operationStack.top = -1;
char ex[20] = "6+5*(4-3)-2/1";
reversePolish(ex);
printList(); //输出后缀表达式
int result = operate(ex); //运算后缀表达式
printf("Result: %d\n", result);
return 0;
} //注:该段代码是ChatGPT生成的,完全可以运行[注释是我加的或许会有问题]
#include
#include
#include
#include
#define MAX_SIZE 100
//定义顺序栈
typedef struct {
char data[MAX_SIZE];
int top;
} Stack;
//初始化顺序栈
void initializeStack(Stack* stack) {
stack->top = -1;
}
//入栈操作
void push(Stack* stack, char value) {
if (stack->top == MAX_SIZE - 1) {
printf("Stack overflow\n");
exit(1);
}
stack->data[++stack->top] = value;
}
//出栈操作
char pop(Stack* stack) {
if (stack->top == -1) {
printf("Stack underflow\n");
exit(1);
}
return stack->data[stack->top--];
}
//检查栈顶元素
char peek(Stack* stack) {
if (stack->top == -1) {
printf("Stack is empty\n");
exit(1);
}
return stack->data[stack->top];
}
//检查空栈
int isEmpty(Stack* stack) {
return stack->top == -1;
}
//运算符优先级定义
int precedence(char op) {
if (op == '+' || op == '-')
return 1;
if (op == '*' || op == '/')
return 2;
return 0;
}
//中缀转后缀表达式
void infixToPostfix(const char* infix, char* postfix) {
//声明局部栈,初始化
Stack stack;
initializeStack(&stack);
int infixLength = strlen(infix);
int postfixIndex = 0;
//从左到右遍历中缀表达式,存入字符串
for (int i = 0; i < infixLength; i++) {
char ch = infix[i];
//如果是字符,存入后缀表达式
if (isdigit(ch)) {
postfix[postfixIndex++] = ch;
} else if (ch == '(') {
//如果是左括号,直接入栈
push(&stack, ch);
} else if (ch == ')') {
//如果是右括号,运算符栈不为空且栈顶不为'('
while (!isEmpty(&stack) && peek(&stack) != '(') {
//栈顶元素出栈并记入表达式
postfix[postfixIndex++] = pop(&stack);
}
//如果是右括号,运算符栈不为空且栈顶为'('
if (!isEmpty(&stack) && peek(&stack) == '(')
//栈顶元素出栈
pop(&stack);
} else {
//如果是普通运算符,比较优先级,若当前运算符大于栈顶运算符则入栈,若小于等于运算符则出栈,循环检查
while (!isEmpty(&stack) && precedence(ch) <= precedence(peek(&stack))) {
postfix[postfixIndex++] = pop(&stack);
}
push(&stack, ch);
}
}
//若执行完毕运算符栈stack不为空,则全部出栈
while (!isEmpty(&stack)) {
postfix[postfixIndex++] = pop(&stack);
}
postfix[postfixIndex] = '\0';
}
//计算后缀表达式
int evaluatePostfix(const char* postfix) {
//声明局部栈,初始化
Stack stack;
initializeStack(&stack);
//记录后缀表达式字符串长度
int postfixLength = strlen(postfix);
//将当前后缀表达式的字符串记入ch
for (int i = 0; i < postfixLength; i++) {
char ch = postfix[i];
//如果字符串ch是数字
if (isdigit(ch)) {
//入栈
push(&stack, ch - '0');
//如果是字符串,执行相应的运算
} else {
int num2 = pop(&stack);
int num1 = pop(&stack);
int result;
switch (ch) {
case '+':
result = num1 + num2;
break;
case '-':
result = num1 - num2;
break;
case '*':
result = num1 * num2;
break;
case '/':
result = num1 / num2;
break;
}
//计算结果入栈
push(&stack, result);
}
}
//返回计算值
return pop(&stack);
}
int main() {
char infix[] = "6+5*(4-3)-2/1";
char postfix[MAX_SIZE];
infixToPostfix(infix, postfix);
printf("Postfix: %s\n", postfix);
int result = evaluatePostfix(postfix);
printf("Result: %d\n", result);
return 0;
} 第二段代码的运算结果如下~
不知为什么,码完以后瞬间释怀,更胸无大志地觉得它不会考了~
普通的顺序栈就到此结束了~话说,顺便提一下,为了节省空间,还有一种特殊的栈是共享栈~
顺序共享栈定义
利用栈底位置相对不变的特性,可让两个顺序栈共享一个一位数组空间,将两个栈的栈底分别设置在空间的两端,两个栈顶向共享空间的中间延伸~
队列
队列的定义与性质
队列的定义:只允许在表的一端进行插入,而在表的另一端进行删除操作的线性表。
队列的操作特性:先进先出(First In First Out, FIFO)。
队列的操作流程大概是这样的~

队列的基本操作:
初始情况,Q.front=Q.rear=0;入队,将值送到队尾元素,再指针+1;出队,取队头元素,再指针+1。可以看出,指针有加无减,如果有多次出入队的操作,可能队伍还没有满,但是指针却缓缓升天了~
所以为了避免指针乱跑的现象,有大佬想出了取余运算,让队列的指针只能在MaxSize的范围内来回打转,这样存储结构上虽然是线性的,但在逻辑结构上却是环形的~
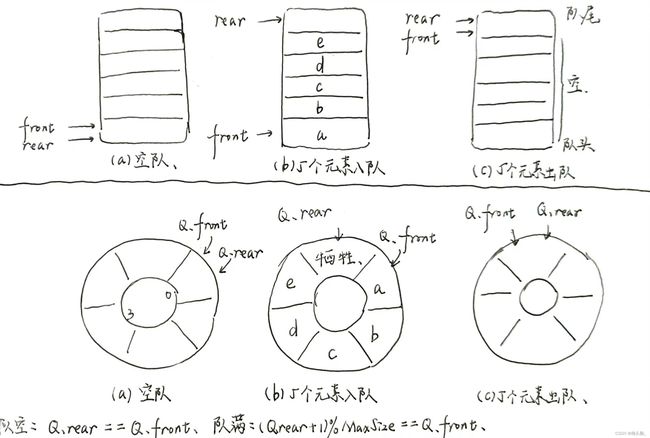
另外,为了区分队满和队空的情况,通常牺牲掉1个单元,以区分两个指针间的算数关系~
循环队列的实现与基本运算
循环队列定义
将顺序队列臆造为一个环状的空间,即把存储队列元素的表从逻辑上视为1个环,称为循环队列。
- 初始时:Q.front=Q.rear=0。
- 队首指针进1:Q.front=(Q.front+1)%MaxSize
- 队尾指针进1:Q.rear=(Q.rear+1)%MaxSize
- 队列长度:(Q.rear+MaxSize-Q.front)%MaxSize
- 队满条件:(Q.rear+1)%MaxSize==Q.front
- 队空条件:Q.rear==Q.front
循环队列的存储类型
存储类型:采用结构体typedef定义顺序栈SqQueue,内容包括 队列的最大个数Maxsize、队列中的元素类型 Elemtype(根据实际需要修改)、队首队尾指针first、rear。
#define Maxsize 50
//定义队列中元素的最大个数
typedef struct{
Elemtype data[Maxsize];
//存放队列元素
int front,rear;
//存放队头指针和队尾指针
} SqQueue;
//定义结构体名称为顺序队循环队列初始化与判断队空
初始化:队首指针front与队尾指针rear指向0的位置;如果Q.front==Q.rear,则表示队空。
void InitQueue(SqQueue &Q) {
Q.rear=Q.front=0;
//初始化队首、队尾指针
}判断队空:
bool StakeEmpty(SqQueue Q) {
if(Q.rear==Q.front) return true;
else return false;
}循环队列入队与出队
入队:判断队是否为满,若队已满,则拒绝操作;若队非满,队尾指针存入元素,然后rear+1。
这个操作顺序好像和栈是正好相反的,因为循环队列的队尾rear指向队尾元素后一位~不过栈和队列的操作顺序都是约定俗成的,而不是固定唯一标准答案~
bool EnQueue(SqQueue &Q, Elemtype x) {
//判断队是否为满
if ((Q.rear+1)%Maxsize == Q.front) return false;
//存入元素后,队尾指针+1取模
Q.data[Q.rear] = x;
Q.rear = (Q.rear+1)%Maxsize;
return true;
}出队:判断队是否为空,若队已空,则拒绝操作;若队非空,队首指针指向的元素先记录,然后指针first+1。
bool DeQueue(SqQueue &Q, Elemtype &x){
//判断队是否为空
if (Q.rear == Q.front) return false;
//取出元素后,队首指针+1取模
x = Q.data[Q.rear];
Q.rear = (Q.rear+1)%Maxsize;
return true;
}链式队列的实现与基本运算
链式队列定义
队列的链式表示成为链队列,它实际上是一个同时带有队头和队尾指针的单链表。头指针指向队头结点,尾指针指向队尾结点。操作和单链表基本是一致的~
单链表的操作→数据结构02:线性表[顺序表+链表]_梅头脑_的博客-CSDN博客
- 初始时:Q.front=Q.rear,Q.front->next=null
- 队首指针进1:Q.front=Q.front->next
- 队尾指针进1:Q.rear=Q.rear->next
- 队列长度:(1)初始化时 int length记录表长;或(2)纯遍历 while(p!=NULL){p=p->next;i++;}
- 队满条件:单链表为大数据而生,基本不会存在队满的情况
- 队空条件:Q.rear==Q.front
链队列的存储类型
存储类型:采用结构体typedef定义顺序栈LinkQueue,内容包括 队列中的结点类型Linknode、队首队尾指针*LinkQueue。
typedef struct{
//定义结点数据元素类型
Elemtype data;
//定义结点指针
struct LinkNode *next;
} LinkNode;
typedef struct{
//定义队首、队尾指针
LinkNode *first,*rear;
}*LinkNode链队列初始化与判断队空
初始化:队首指针front与队尾指针rear指向0的位置;如果Q.front==Q.rear,则表示队空。
void InitStack(SqQueue &Q) {
Q.rear=Q.front=0;
//初始化队首、队尾指针
}判断队空:
bool StakeEmpty(SqQueue Q) {
if(Q.rear==Q.front) return true;
else return false;
}循环队列入队与出队
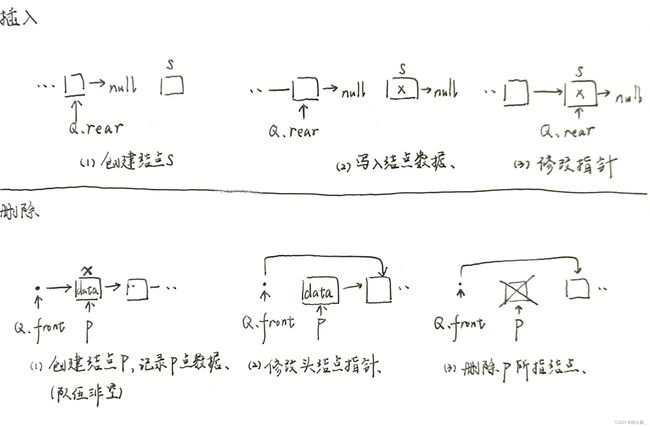
入队:同单链表—在队尾创建一个新节点~因为不用判断队满条件,甚至函数类型都从bool都变成了void~
void EnQueue(LinkQueue &Q, Elemtype x) {
//创建结点,存入元素
LinkNode *S=(LinkNode *)malloc(sizeof(LinkNode));
s->data=x;s->next=NULL;
//链接队尾元素,修改队尾指针位置
Q.rear->next=s;
Q.rear=s;
}出队:判断队是否为空,若队已空,则拒绝操作;若队非空,操作同单链表—删除头节点~
bool DeQueue(LinkQueue &Q, Elemtype &x) {
//判断队空条件
if(Q.front==Q.rear) return false;
//创建删除结点的指针,指向头节点以后
LinkNode *p=Q.front->next;
//记录数据结点
x=p->data;
Q.front->next=p->next;
//判断首尾是否为同一结点
if(Q.rear==p) Q=rear=Q.front;
free(p);
return true;
}队的小案例
队列小案例1:顺序二叉树的层次遍历(代码)
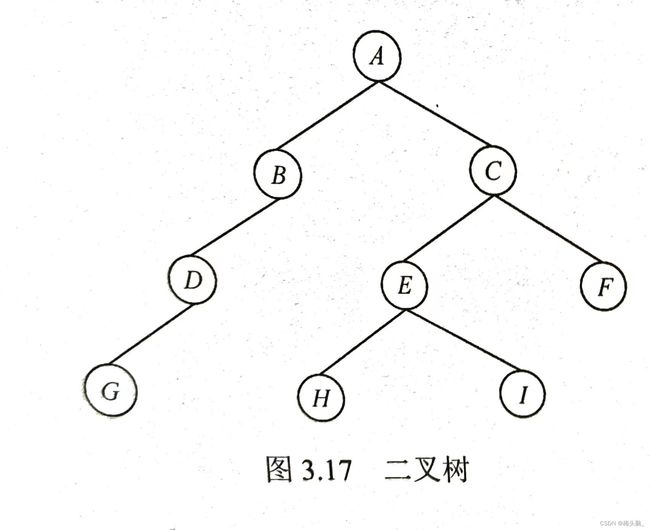
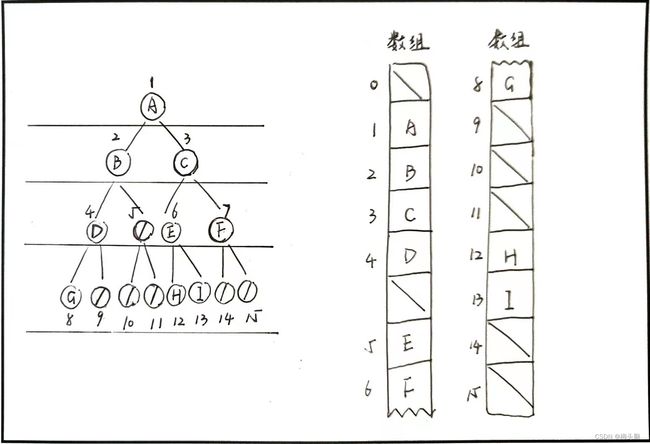
案例:以王道教材书图3.17为例,层次遍历这棵二叉树~
算法思想:
- 建立1个数组存放二叉树,根据题目数有4层,数组长度为对应的满二叉树长度2^(4)=16;
- 按照对应结点下标顺序存储二叉树,空结点位保持记为0,数组a[0]不计位;
- 载入队列封装函数,然后以下两个步骤2择1~
- 建立1个队列,根节点入队,顺序表遍历...虽然这个好像不需要队列也行,需遍历所有(含无效)结点~
- 建立2个队列,分别记录结点的值与位序。根节点入队,记录值与位序。若队非空,循环执行下列步骤:访问队列的队首结点a[i],若有左孩子a[2i],则左孩子的入队,记录值与位序;若有右孩子结点a[2i+1],则右孩子入队,记录值与位序。此方法可仅遍历有效结点~
以下是4-1,顺序遍历数组的代码...虽然是能运行的...
#include
#define AMaxsize 16
#define Maxsize 10
typedef struct {
char data[Maxsize];
int front, rear;
} SqQueue;
void InitQueue(SqQueue &Q) {
Q.rear = Q.front = 0;
}
bool EnQueue(SqQueue &Q, char x) {
if ((Q.rear + 1) % Maxsize == Q.front)
return false;
Q.data[Q.rear] = x;
Q.rear = (Q.rear + 1) % Maxsize;
return true;
}
bool DeQueue(SqQueue &Q, char &x) {
if (Q.rear == Q.front)
return false;
x = Q.data[Q.front];
Q.front = (Q.front + 1) % Maxsize;
return true;
}
void LevelTraversal(char tr[]) {
SqQueue Q;
InitQueue(Q);
int j = 1;
while (tr[j] != '\0') {
if (isalpha(tr[j])) {
EnQueue(Q, tr[j]);
}
j++;
}
while (Q.rear != Q.front) {
char x;
DeQueue(Q, x);
std::cout << x << " ";
}
std::cout << std::endl;
}
int main() {
char a[AMaxsize];
for (int i = 1; i < AMaxsize; i++) {
std::cout << "Enter a character: ";
std::cin >> a[i];
}
LevelTraversal(a);
return 0;
}
执行的结果大概是这样子的~

以下是4-2,用两个队列访问数组的代码,执行的效果与上面这张图是一模一样的~
#include
#include
#define AMaxsize 16
#define Maxsize 5
void SequentialTraversal(char tr[]) {
std::queue contentQueue; // 存储节点的内容的队列
std::queue indexQueue; // 存储节点的位序的队列
int j = 1; // 从根节点开始遍历
contentQueue.push(tr[j]); // 将根节点的内容加入内容队列
indexQueue.push(j); // 将根节点的位序加入位序队列
while (!contentQueue.empty()) {
char content = contentQueue.front(); // 取出内容队列的队首节点内容
int index = indexQueue.front(); // 取出位序队列的队首节点位序
contentQueue.pop(); // 队首节点出队
indexQueue.pop(); // 队首节点出队
std::cout << content << " "; // 输出节点内容
int leftChild = 2 * index; // 计算左子节点的位序
if (isalpha(tr[leftChild])) { // 如果左子节点存在
contentQueue.push(tr[leftChild]); // 将左子节点的内容加入内容队列
indexQueue.push(leftChild); // 将左子节点的位序加入位序队列
}
int rightChild = 2 * index + 1; // 计算右子节点的位序
if (isalpha(tr[rightChild])) { // 如果右子节点存在
contentQueue.push(tr[rightChild]); // 将右子节点的内容加入内容队列
indexQueue.push(rightChild); // 将右子节点的位序加入位序队列
}
}
std::cout << std::endl;
}
int main() {
char a[AMaxsize];
for (int i = 1; i < AMaxsize; i++) {
std::cout << "Enter a character: ";
std::cin >> a[i];
}
SequentialTraversal(a);
return 0;
}
队列小案例2:链式二叉树的层次遍历(代码)
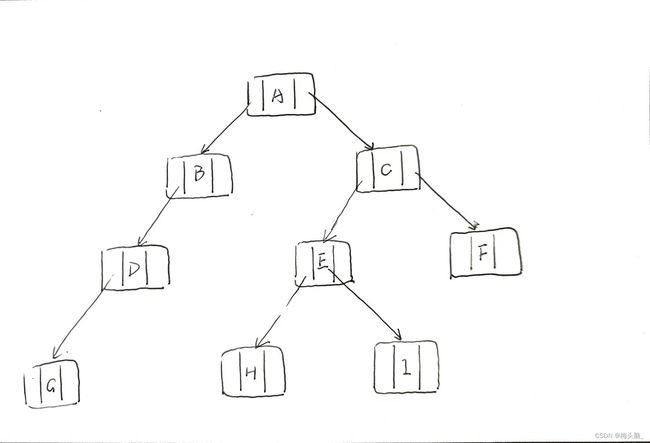
案例:同上~
算法思想:
- 建立链式二叉树;建立1个队列;
- 将根结点加入队列;
- 若队非空,循环执行下列步骤:队首元素出队并访问该结点;若有左孩子结点,则结点入队;若有右孩子结点,则结点入队。
#include
#include
struct BiTNode {
char data;
struct BiTNode* lchild;
struct BiTNode* rchild;
};
typedef struct BiTNode* BiTree;
BiTree newBiTree() {
BiTree root = new BiTNode();
root->data = 'A';
root->lchild = new BiTNode();
root->lchild->data = 'B';
root->rchild = new BiTNode();
root->rchild->data = 'C';
root->lchild->lchild = new BiTNode();
root->lchild->lchild->data = 'D';
root->rchild->lchild = new BiTNode();
root->rchild->lchild->data = 'E';
root->rchild->rchild = new BiTNode();
root->rchild->rchild->data = 'F';
root->lchild->lchild->lchild = new BiTNode();
root->lchild->lchild->lchild->data = 'G';
root->rchild->lchild->lchild = new BiTNode();
root->rchild->lchild->lchild->data = 'H';
root->rchild->lchild->rchild = new BiTNode();
root->rchild->lchild->rchild->data = 'I';
return root;
}
void SequentialTraversal(BiTree root) {
if (root == nullptr) return;
std::queue contentQueue; // 创建名为'contentQueue'的队列
contentQueue.push(root); // 将根节点加入内容队列
while (!contentQueue.empty()) {
BiTNode* node = contentQueue.front(); // 取出内容队列的队首节点
contentQueue.pop(); // 队首节点出队
std::cout << node->data << " "; // 输出节点内容
if (node->lchild != nullptr) { // 如果左子节点存在
contentQueue.push(node->lchild); // 将左子节点加入内容队列
}
if (node->rchild != nullptr) { // 如果右子节点存在
contentQueue.push(node->rchild); // 将右子节点加入内容队列
}
}
std::cout << std::endl; // 输出换行
}
int main() {
// 构建一个示例二叉树
BiTree tree = newBiTree();
SequentialTraversal(tree);
return 0;
}
执行的结果大概是这样子的~

队列小案例3:过河问题(代码)
案例:一位农夫带着一头狼,一只羊和一筐白菜过河,河边有一条小船,农夫划船每次只能载狼、羊、白菜三者中的一个过河。农夫不在旁边时,狼会吃羊,羊会吃白菜。问农夫该如何过河。
备注:这个部分大概不会考,看见算法思想的那一刻我是崩溃的,脑子已经宕机。只是在找案例时忽然想到了这个题目,有点好奇解法,因此是由ChatGPT老师直接生成的答案~
算法思想:
- 创建一个队列,用于存储每个可能的状态。每个状态表示农夫、狼、羊和白菜的位置。
- 初始状态是农夫、狼、羊和白菜都在起始岸(A岸),船也在A岸。
- 将初始状态加入队列。
- 从队列中取出一个状态,检查是否为目标状态(即农夫、狼、羊和白菜都在对岸,船也在对岸)。
- 如果是目标状态,表示找到了过河的方案,结束搜索。
- 如果不是目标状态,继续下面的步骤。
- 遍历所有可能的动作:
- 农夫单独过河(农夫带上船)
- 农夫带狼过河
- 农夫带羊过河
- 农夫带白菜过河
- 对于每个动作,检查是否合法(狼不吃羊,羊不吃白菜):
- 如果合法,生成新的状态,表示动作后的状态,并将其加入队列。
- 如果不合法,舍弃该动作。
- 重复步骤4-6,直到队列为空或找到目标状态为止。
#include
#include
#include
// 定义状态结构体,表示农夫、狼、羊和白菜的位置
struct State {
bool farmer; // 农夫的位置,true表示在对岸,false表示在起始岸
bool wolf; // 狼的位置
bool sheep; // 羊的位置
bool cabbage; // 白菜的位置
std::string path; // 存储路径,记录过河的每个动作
// 构造函数
State(bool f, bool w, bool s, bool c, const std::string& p)
: farmer(f), wolf(w), sheep(s), cabbage(c), path(p) {}
};
// 检查状态是否合法,狼不吃羊,羊不吃白菜
bool isValidState(const State& state) {
// 检查狼是否吃羊
if (state.wolf == state.sheep && state.farmer != state.wolf) {
return false;
}
// 检查羊是否吃白菜
if (state.sheep == state.cabbage && state.farmer != state.sheep) {
return false;
}
return true;
}
// 过河问题的解决函数
void solveRiverCrossing() {
// 初始化初始状态
State initial(true, true, true, true, "");
// 创建队列和哈希集合
std::queue stateQueue;
std::unordered_set visited;
// 将初始状态加入队列和哈希集合
stateQueue.push(initial);
visited.insert(initial.path);
while (!stateQueue.empty()) {
// 取出队列中的状态
State current = stateQueue.front();
stateQueue.pop();
// 检查是否为目标状态
if (!current.farmer && !current.wolf && !current.sheep && !current.cabbage) {
// 输出找到的解决方案
std::cout << "Solution found: " << current.path << std::endl;
return;
}
// 农夫单独过河
if (current.farmer) {
State newState(!current.farmer, current.wolf, current.sheep, current.cabbage, current.path + "F-> ");
if (isValidState(newState) && visited.find(newState.path) == visited.end()) {
stateQueue.push(newState);
visited.insert(newState.path);
}
} else {
State newState(!current.farmer, current.wolf, current.sheep, current.cabbage, current.path + "<-F ");
if (isValidState(newState) && visited.find(newState.path) == visited.end()) {
stateQueue.push(newState);
visited.insert(newState.path);
}
}
// 农夫带狼过河
if (current.farmer == current.wolf) {
State newState(!current.farmer, !current.wolf, current.sheep, current.cabbage, current.path + "FW-> ");
if (isValidState(newState) && visited.find(newState.path) == visited.end()) {
stateQueue.push(newState);
visited.insert(newState.path);
}
}
// 农夫带羊过河
if (current.farmer == current.sheep) {
State newState(!current.farmer, current.wolf, !current.sheep, current.cabbage, current.path + "FS-> ");
if (isValidState(newState) && visited.find(newState.path) == visited.end()) {
stateQueue.push(newState);
visited.insert(newState.path);
}
}
// 农夫带白菜过河
if (current.farmer == current.cabbage) {
State newState(!current.farmer, current.wolf, current.sheep, !current.cabbage, current.path + "FC-> ");
if (isValidState(newState) && visited.find(newState.path) == visited.end()) {
stateQueue.push(newState);
visited.insert(newState.path);
}
}
}
// 如果队列为空,表示无解
std::cout << "No solution found." << std::endl;
}
int main() {
solveRiverCrossing();
return 0;
}
普通队列就到此结束了~还有一种是双端队列,基本是选填在考,考那种输入输出受限的队列,“不可能出现的序列”的,逻辑相关知识点无关的题目~
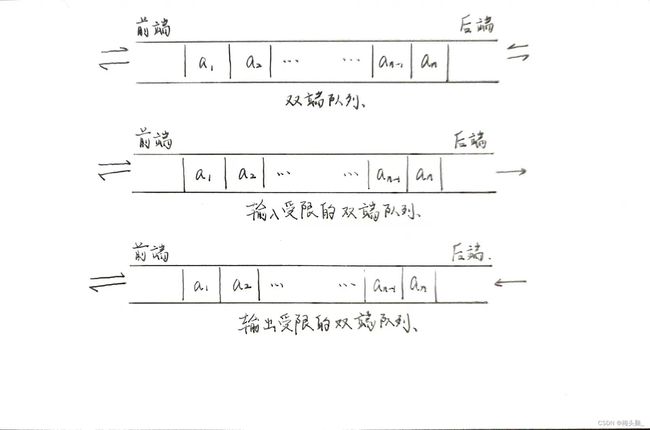
双端队列定义
双端队列:是指允许两端都可以进行入队和出队操作的队列。
输出受限的双端队列:允许在一端进行插入和删除,但是另一端只允许插入的双端队列。
输入受限的双端队列:允许在一端进行插入和删除,但是另一端只允许删除的双端队列。
数组和特殊矩阵
数组的定义
数组:是由n(n≥1)个相同类型的数据元素构成的有限序列。
数组与线性表的关系:数组是线性表的推广。一维数组可视为1个线性表;二维数组可视为其元素也是定长线性表的线性表,以此类推。
特殊矩阵
对称矩阵:对1个n阶矩阵A中的任意1个元素ai,j都有ai,j=aj,i(1≤i,j≤n)。
三角矩阵:下三角矩阵中,上三角的所有元素为同一常量。
三对角矩阵:也称带状矩阵。对于n阶矩阵A中的任意一个元素ai,j,当| i - j |>1时,有ai,j=0(1≤i,j≤n)。

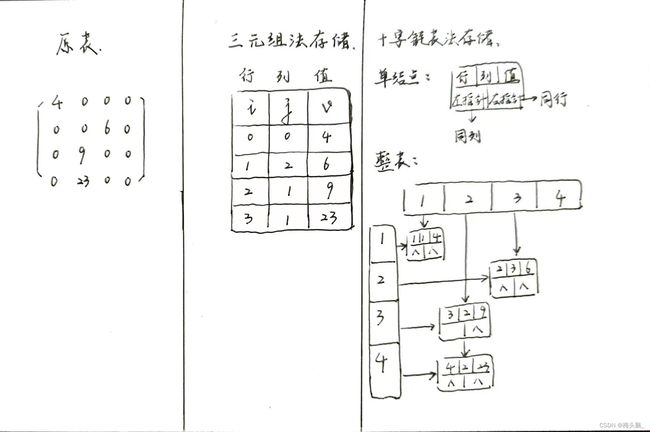
稀疏矩阵
稀疏矩阵:矩阵中非零元素的个数t,相对矩阵元素的个数s来说非常少,即s>>t的矩阵称为稀疏矩阵。
存储方式:三元组法与十字链表法。[了解即可好像也不怎么考]~
结语
博文写得模糊或者有误之处,欢迎小伙伴留言讨论与批评~️
话说这两天改代码到了一种看见代码就会陷入呆滞的程度~
码字不易,若有所帮助,可以点赞支持一下博主嘛?感谢~