Spark安装部署:Standalone模式
Spark安装部署:Standalone模式
文章目录
-
- Spark安装部署:Standalone模式
- 1、实验描述
- 2、实验环境
- 3、相关技能
- 4、知识点
- 5、实现效果
- 6、实验步骤
- 7、总结
1、实验描述
- 以spark Standalone的运行模式安装Spark集群
- 实验时长:
- 45分钟
- 主要步骤:
- 解压安装Spark
- 添加Spark 配置文件
- 启动Spark 集群
- 运行测试用例
2、实验环境
- 虚拟机数量:3(一主两从,主机名分别为:master、slave01、slave02)
- 系统版本:Centos 7.5
- Hadoop版本:Apache Hadoop 2.7.3
- Spark版本:Apache Spark 2.1.1
3、相关技能
- Spark Standalone安装部署
4、知识点
- 常见linux命令的使用
- 通过修改.bash_profile文件配置spark
- 验证spark standalone安装
- 向集群提交application运行
- spark webui的使用
5、实现效果
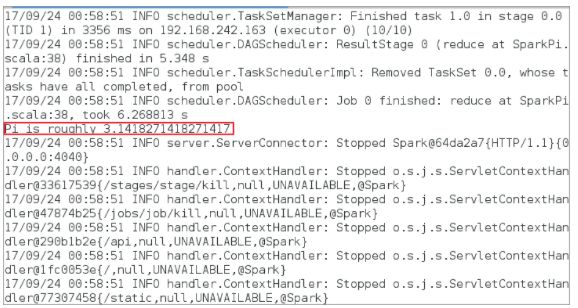
运行 计算Pi 示例最终效果如下图:
6、实验步骤
前提:已经在集群中成功安装部署Hadoop集群
6.1在master节点上解压spark压缩包
6.1.1打开linux命令行终端(桌面上点鼠标右键,选择“打开终端”)
6.1.2命令行终端中,切换到spark压缩包所在目录/home/zkpk/tgz/spark
[zkpk@master ~]$ cd /home/zkpk/tgz/spark
6.1.3将spark压缩包解压缩到用户的根目录
[zkpk@master spark]$ tar -xzvf spark-2.1.1-bin-hadoop2.7.tgz -C /home/zkpk
6.2查看解压出的spark目录中的内容
6.2.1返回用户要目录
[zkpk@master spark]$ cd
6.2.2进入解压出的spark目录
[zkpk@master ~]$ cd spark-2.1.1-bin-hadoop2.7/
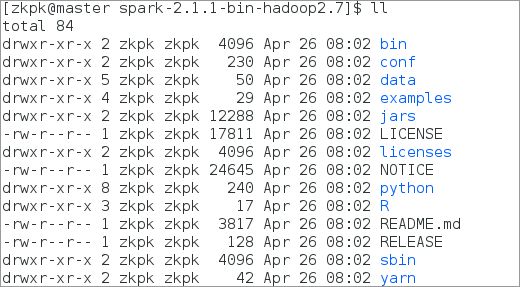
6.2.3查看此目录内容
[zkpk@master spark-2.1.1-bin-hadoop2.7]$ ll
6.3配置环境变量
6.3.1回退到用户根目录
[zkpk@master spark-2.1.1-bin-hadoop2.7]$ cd
6.3.2vim编辑.bash_profile文件
[zkpk@master ~]$ vim .bash_profile
6.3.3添加spark相关信息,然后保存退出
export SPARK_HOME=/home/zkpk/spark-2.1.1-bin-hadoop2.7export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
6.3.4运行source命令,重新编译.bash_profile,使添加变量生效
[zkpk@master ~]$ source ~/.bash_profile
6.3.5slave01、slave02也是执行如上配置
6.3.5.1将.bash_profile文件分别拷贝到slave01、slave02的/home/zkpk目录
[zkpk@master ~]$ cd [zkpk@master ~]$ scp .bash_profile slave01:/home/zkpk[zkpk@master ~]$ scp .bash_profile slave02:/home/zkpk
6.3.5.2source使修改生效
[zkpk@master ~]$ ssh slave01 #远程登录slave01[zkpk@slave01 ~]$ source .bash_profile[zkpk@slave01 ~]$ exit #退出远程登录[zkpk@master ~]$ ssh slave02 #远程登录slave02[zkpk@slave02 ~]$ source .bash_profile[zkpk@slave02 ~]$ exit #退出远程登录
6.4修改slaves文件
6.4.1进入spark的配置文件目录
[zkpk@master ~]$ cd spark-2.1.1-bin-hadoop2.7/conf/
6.4.2将conf目录中的slaves.template文件重命名为slaves
[zkpk@master conf]$ mv slaves.template slaves
6.4.3将slaves原内容替换为如下内容,并保存退出
slave01slave02
6.5修改conf目录中的spark-env.sh文件
6.5.1重命名文件spark-env.sh.template为spark-env.sh
[zkpk@master conf]$ mv spark-env.sh.template spark-env.sh
6.5.2将如下内容添加到spark-env.sh文件,并保存退出
export SPARK_MASTER_HOST=master #设置运行master进程的节点export SPARK_MASTER_PORT=7077 #设置master的通信端口export SPARK_WORKER_CORES=1 #每个worker使用的核数export SPARK_WORKER_MEMORY=1024M #每个worker使用的内存大小export SPARK_MASTER_WEBUI_PORT=8080 #master的webui端口export SPARK_CONF_DIR=/home/zkpk/spark-2.1.1-bin-hadoop2.7/conf #spark的配置文件目录 export JAVA_HOME=/usr/java/jdk1.8.0_131/ #jdk安装路径
6.6将经过配置的spark主目录远程拷贝到另外两个从节点
6.6.1切换到用户根目录
[zkpk@master conf]$ cd
6.6.2远程拷贝spark主目录到slave01
[zkpk@master ~]$ scp -r spark-2.1.1-bin-hadoop2.7/ zkpk@slave01:/home/zkpk
6.6.3远程拷贝spark主目录到slave02
[zkpk@master ~]$ scp -r spark-2.1.1-bin-hadoop2.7/ zkpk@slave02:/home/zkpk
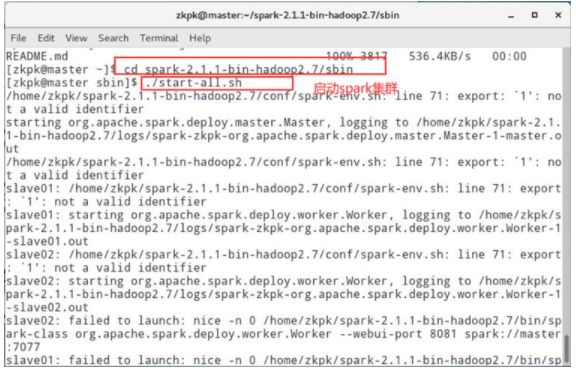
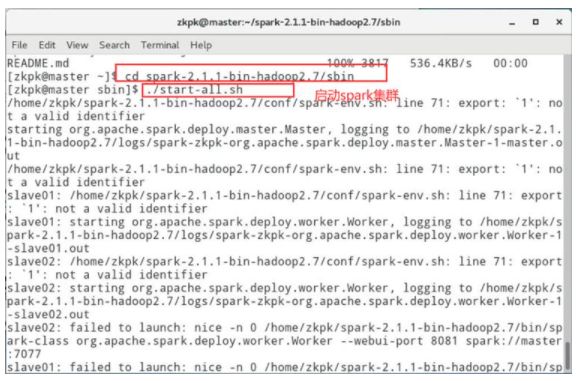
6.7启动spark集群
6.7.1进入master节点 的spark的sbin目录
[zkpk@master ~]$ cd spark-2.1.1-bin-hadoop2.7/sbin/
6.7.2运行start-all.sh启动spark集群
[zkpk@master sbin]$ ./start-all.sh
6.7.3验证spark standalone模式部署正确
6.7.3.1打开浏览器访问spark webui界面地址:http://master:8080,出现类似下图界面

6.7.3.2命令行提交job到spark集群
[zkpk@master sbin]$ cd spark-2.1.1-bin-hadoop2.7/bin/[zkpk@master bin]$./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --num-executors 3 --driver-memory 1g --executor-memory 1g --executor-cores 1 examples/jars/spark-examples_2.11-2.1.1.jar 10

计算出pi的结果,如下图:Pi is roughly 3.1418271418271417
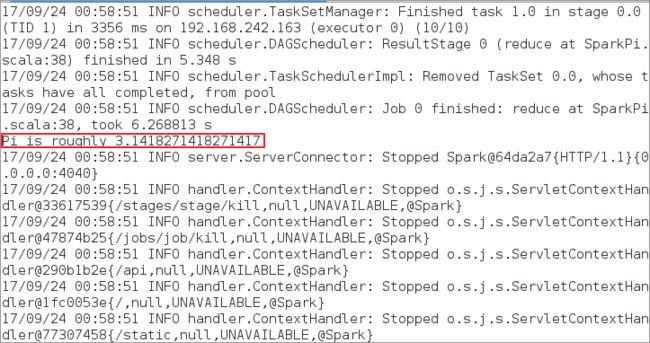
6.7.3.3至此说明,spark standalone模式安装部署成功
7、总结
spark
standalone的安装部署涉及到集群中的各节点,基本步骤就是在master节点解压压缩包,配置spark的slaves、spark-env.sh文件、配置.bash_profile文件,并将spark目录及.bash_profile远程拷贝到其它从节点,在master节点启动spark集群,以spark
standalone模式运行一个spark的计算pi的例子