Flink第六章:多流操作
系列文章目录
Flink第一章:环境搭建
Flink第二章:基本操作.
Flink第三章:基本操作(二)
Flink第四章:水位线和窗口
Flink第五章:处理函数
Flink第六章:多流操作
文章目录
- 系列文章目录
- 前言
- 一、分流
-
- 1.侧输出流(process function)
- 二、合流
-
- 1. 联合(Union)
- 2. 连接(Connect)
- 3.实时对账案例
- 4.窗口联结(Window Join)
- 5.间隔联结(Interval Join)
- 6.窗口同组联结(Window CoGroup)
- 总结
前言
之前我们进行的都是Flink的单流操作,接下来我们我们进行Flink的多流操作.
创建scala

一、分流
1.侧输出流(process function)
我们根据不同的点击用户进行输出
SplitStreamTest.scala
package com.atguigu.chapter05
import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object SplitStreamTest {
// 定义输出标签
val maryTag = OutputTag[(String, String, Long)]("mary-tag")
val bobTag = OutputTag[(String, String, Long)]("bob-tag")
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.addSource(new ClickSource)
val elseStream: DataStream[Event] = stream.process(new ProcessFunction[Event, Event] {
override def processElement(value: Event, ctx: ProcessFunction[Event, Event]#Context, out: Collector[Event]): Unit = {
if (value.user == "Mary") {
ctx.output(maryTag, (value.user, value.url, value.timestamp))
} else if (value.user == "Bob") {
ctx.output(bobTag, (value.user, value.url, value.timestamp))
} else {
out.collect(value)
}
}
})
elseStream.print("else")
elseStream.getSideOutput(maryTag).print("mary")
elseStream.getSideOutput(bobTag).print("bob")
env.execute()
}
}

二、合流
1. 联合(Union)
UnionTest.scala
package com.atguigu.chapter05
import com.atguigu.chapter02.Source.Event
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object UnionTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 读取两条流进行合并
val stream1: DataStream[Event] = env.socketTextStream("127.0.0.1", 7777).map(
data => {
val fields: Array[String] = data.split(",")
Event(fields(0).trim, fields(1).trim, fields(2).trim.toLong)
}
).assignAscendingTimestamps(_.timestamp)
val stream2: DataStream[Event] = env.socketTextStream("127.0.0.1", 8888).map(
data => {
val fields: Array[String] = data.split(",")
Event(fields(0).trim, fields(1).trim, fields(2).trim.toLong)
}
).assignAscendingTimestamps(_.timestamp)
stream1.union(stream2)
.process(new ProcessFunction[Event,String] {
override def processElement(value: Event, ctx: ProcessFunction[Event, String]#Context, out: Collector[String]): Unit = {
out.collect(s"当前水位线: ${ctx.timerService().currentWatermark()}+${value}")
}
}).print()
env.execute()
}
}

我们发出数据的顺序是
7777
Mary,./home,1000
Mary,./home,2000
8888
Mary,./home,500
Mary,./home,1000
可以看到,当只有一条流有数据是,水位线不会推进,因为合流后的水位线默认用最晚的,当第二条流的第二条数据到达,水位线推到500-1,因为程序是先打印后推进水位线.
2. 连接(Connect)
ConnectTest.scala
package com.atguigu.chapter05
import org.apache.flink.streaming.api.functions.co.CoMapFunction
import org.apache.flink.streaming.api.scala._
object ConnectTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//定义两条整数流
val stream1: DataStream[Int] = env.fromElements(1, 2, 3)
val stream2: DataStream[Long] = env.fromElements(1L, 2L, 3L)
// 连接两条流
stream1.connect(stream2)
.map(new CoMapFunction[Int,Long,String] {
override def map1(value: Int): String = s"Int:$value"
override def map2(value: Long): String = s"Long:$value"
})
.print()
env.execute()
}
}

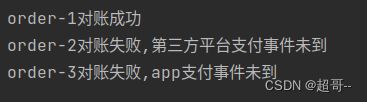
3.实时对账案例
现在有两条流,我们用Key分组,两条流中都含有同样的Key,对账成功,否则对账失败.
BillCheckExample.scala
package com.atguigu.chapter05
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.co.CoProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object BillCheckExample {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 1.来自app的支付日志流,(order-id,status,timestamp)
val appStream: DataStream[(String, String, Long)] = env.fromElements(
("order-1", "success", 1000L),
("order-2", "success", 2000L)
)
.assignAscendingTimestamps(_._3)
// 2.来自第三方支付平台的日志流,(order-id,status,timestamp)
val thirdpartStream: DataStream[(String, String, String, Long)] = env.fromElements(
("order-1", "success", "wechat", 3000L),
("order-3", "success", "alipy", 4000L)
)
.assignAscendingTimestamps(_._4)
appStream.connect(thirdpartStream)
.keyBy(_._1,_._1)
.process(new CoProcessFunction[(String,String,Long),(String, String, String, Long),String] {
// 定义状态变量,用来保存一节到达的事件
var appEvent : ValueState[(String,String,Long)]= _
var thirdpartyEvent :ValueState[(String,String,String,Long)]= _
override def open(parameters: Configuration): Unit = {
appEvent = getRuntimeContext.getState(new ValueStateDescriptor[(String, String, Long)]("app-event",classOf[(String,String,Long)]))
thirdpartyEvent=getRuntimeContext.getState(new ValueStateDescriptor[(String, String, String, Long)]("thirdparty-event",classOf[(String,String,String,Long)]))
}
override def processElement1(value: (String, String, Long), ctx: CoProcessFunction[(String, String, Long), (String, String, String, Long), String]#Context, out: Collector[String]): Unit = {
if (thirdpartyEvent.value()!=null){
out.collect(s"${value._1}对账成功")
// 清空状态
thirdpartyEvent.clear()
}else{
// 如果另一条流中事件没有到达就注册定时器,开始等待
ctx.timerService().registerEventTimeTimer(value._3+5000)
//保存当前时间到对应的状态
appEvent.update(value)
}
}
override def processElement2(value: (String, String, String, Long), ctx: CoProcessFunction[(String, String, Long), (String, String, String, Long), String]#Context, out: Collector[String]): Unit = {
if (appEvent.value()!=null){
out.collect(s"${value._1}对账成功")
// 清空状态
appEvent.clear()
}else{
// 如果另一条流中事件没有到达就注册定时器,开始等待
ctx.timerService().registerEventTimeTimer(value._4+5000)
//保存当前时间到对应的状态
thirdpartyEvent.update(value)
}
}
override def onTimer(timestamp: Long, ctx: CoProcessFunction[(String, String, Long), (String, String, String, Long), String]#OnTimerContext, out: Collector[String]): Unit = {
// 判断状态是否为空,如果不为空,说明另一条流对应的事件没来
if (appEvent.value()!=null){
out.collect(s"${appEvent.value()._1}对账失败,第三方平台支付事件未到")
}
if (thirdpartyEvent.value()!=null){
out.collect(s"${thirdpartyEvent.value()._1}对账失败,app支付事件未到")
}
appEvent.clear()
thirdpartyEvent.clear()
}
}).print()
env.execute()
}
}
4.窗口联结(Window Join)
将两条流中,同一个窗口内的数据连接
WindowJoinTest.scala
package com.atguigu.chapter05
import org.apache.flink.api.common.functions.JoinFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object WindowJoinTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream1: DataStream[(String, Long)] = env.fromElements(
("a", 1000L),
("b", 1000L),
("a", 2000L),
("a", 2000L)
).assignAscendingTimestamps(_._2)
val stream2: DataStream[(String, Long)] = env.fromElements(
("a", 3000L),
("b", 3000L),
("a", 4000L),
("b", 4000L)
).assignAscendingTimestamps(_._2)
// 窗口连接操作
stream1.join(stream2)
.where(_._1)
.equalTo(_._1)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply( new JoinFunction[(String,Long),(String,Long),String] {
override def join(in1: (String, Long), in2: (String, Long)): String = {
in1+"->"+in2
}
})
.print()
env.execute()
}
}

5.间隔联结(Interval Join)
以一条流里的某一个事件的时间戳为原点,匹配另一条流中,同一时间戳的前后一段时内是否有对应的数据.
IntervalJoinTest.scala
package com.atguigu.chapter05
import com.atguigu.chapter02.Source.Event
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.util.Collector
object IntervalJoinTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 订单事件流
val orderStream: DataStream[(String, String, Long)] = env
.fromElements(
("Mary", "order-1", 5000L),
("Alice", "order-2", 5000L),
("Bob", "order-3", 20000L),
("Alice", "order-4", 20000L),
("Cary", "order-5", 51000L)
).assignAscendingTimestamps(_._3)
// 点击事件流
val pvStream: DataStream[Event] = env
.fromElements(
Event("Bob", "./cart", 2000L),
Event("Alice", "./prod?id=100", 3000L),
Event("Alice", "./prod?id=200", 3500L),
Event("Bob", "./prod?id=2", 2500L),
Event("Alice", "./prod?id=300", 36000L),
Event("Bob", "./home", 30000L),
Event("Bob", "./prod?id=1", 23000L),
Event("Bob", "./prod?id=3", 33000L)
).assignAscendingTimestamps(_.timestamp)
// 两条流进行间隔连接,匹配一个订单事件前后一段时间内发生的点击事件
orderStream.keyBy(_._1)
.intervalJoin(pvStream.keyBy(_.user))
.between(Time.seconds(-5),Time.seconds(10))
.process(new ProcessJoinFunction[(String, String, Long),Event,String] {
override def processElement(left: (String, String, Long), right: Event, ctx: ProcessJoinFunction[(String, String, Long), Event, String]#Context, out: Collector[String]): Unit = {
out.collect(left+"=>"+right)
}
})
.print()
env.execute()
}
}

6.窗口同组联结(Window CoGroup)
和窗口连接很象,区别是,CoGroup以整个窗口为一组进行连接
CoGroupTest.scala
package com.atguigu.chapter05
import org.apache.flink.api.common.functions.{CoGroupFunction, JoinFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.util.Collector
import java.lang
object CoGroupTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream1: DataStream[(String, Long)] = env.fromElements(
("a", 1000L),
("b", 1000L),
("a", 2000L),
("a", 2000L)
).assignAscendingTimestamps(_._2)
val stream2: DataStream[(String, Long)] = env.fromElements(
("a", 3000L),
("b", 3000L),
("a", 4000L),
("b", 4000L)
).assignAscendingTimestamps(_._2)
// 窗口同组连接操作
stream1.coGroup(stream2)
.where(_._1)
.equalTo(_._1)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new CoGroupFunction[(String, Long),(String, Long),String] {
override def coGroup(iterable: lang.Iterable[(String, Long)], iterable1: lang.Iterable[(String, Long)], collector: Collector[String]): Unit = {
collector.collect(iterable+"=>"+iterable1)
}
})
.print()
env.execute()
}
}

总结
多流操作基本就这些了.