ZooKeeper 相关概念总结
文章目录
- 前言
- 1、ZooKeeper 介绍
-
- 1.1、ZooKeeper 概览
- 1.2、ZooKeeper 特点
- 1.3、ZooKeeper 应用场景
-
- 1.3.1、分布式锁
- 1.3.2、命名服务
- 1.3.3、集群管理和注册中心
- 2、ZooKeeper 重要概念
-
- 2.1、Data model(数据模型)
- 2.2、znode(数据节点)
- 2.3、版本(version)
- 2.4、ACL(权限控制)
- 2.5、Watcher(事件监听器)
- 2.6、会话(Session)
- 3、ZooKeeper 集群
-
- 3.1、ZooKeeper 集群角色
- 3.2、ZooKeeper 集群 Leader 选举过程
- 3.3、ZooKeeper 集群为啥最好奇数台
- 3.4、ZooKeeper 选举的过半机制防止脑裂
- 4、ZAB 协议和 Paxos 算法
-
- 4.1、ZAB 协议介绍
- 4.2、ZAB 中的三个角色
- 4.2、ZAB 协议两种基本的模式:崩溃恢复和消息广播
- 5、下载安装
- 6、zookeeper 客户端API操作
-
- 6.1、Zookeeper官方客户端API
- 6.2、Zookeeper Curator客户端API操作
- 7、zookeeper 写数据原理
- 8、基于 Zookeeper 的分布式锁
-
- 8.1、如何基于 ZooKeeper 实现分布式锁
- 8.2、为什么要用临时顺序节点
- 8.3、为什么要设置对前一个节点的监听
- 8.4、如何实现可重入锁
- 9、ZooKeeper 可视化工具
前言
ZooKeeper 最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。
关于 ZooKeeper 这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的 Pig 项目),雅虎的工程师希望给这个项目也取一个动物的名字。研究院的首席科学家 RaghuRamakrishnan 开玩笑地说:“ 在这样下去,我们这儿就变成动物园了!” 此话一出,大家纷纷表示就叫动物园管理员吧一因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一一个大型的动物园了,而 ZooKeeper 正好要用来进行分布式环境的协调一一于是,ZooKeeper 的名字也就由此诞生了。
1、ZooKeeper 介绍
1.1、ZooKeeper 概览
ZooKeeper 是一个开源的分布式协调服务,它的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
ZooKeeper 为我们提供了高可用、高性能、稳定的分布式数据一致性解决方案,通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。这些功能的实现主要依赖于 ZooKeeper 提供的 数据存储+事件监听 功能。
ZooKeeper 将数据保存在内存中,性能是不错的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景)。
另外,很多顶级的开源项目都用到了 ZooKeeper,比如:
- Kafka : ZooKeeper 主要为 Kafka 提供 Broker 和 Topic 的注册以及多个 Partition 的负载均衡等功能。不过,在 Kafka 2.8 之后,引入了基于 Raft 协议的 KRaft 模式,不再依赖 Zookeeper,大大简化了 Kafka 的架构。
- Hbase : ZooKeeper 为 Hbase 提供确保整个集群只有一个 Master 以及保存和提供 regionserver 状态信息(是否在线)等功能。
- Hadoop : ZooKeeper 为 Namenode 提供高可用支持。
1.2、ZooKeeper 特点
- 全局数据一致:集群中每个服务器保存一份相同的数据副本,client无论连接到哪个服务器,展示的数据都是一致的,这是最重要的特征。
- 可靠性:如果消息被其中一台服务器接受,那么将被所有的服务器接受。
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
- 数据更新原子性:一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态。
- 实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。
1.3、ZooKeeper 应用场景
1.3.1、分布式锁
分布式锁的实现方式有很多种,比如 Redis 、数据库 、zookeeper 等。个人认为 zookeeper 在实现分布式锁这方面是非常非常简单的。
zk在高并发的情况下保证节点创建的全局唯一性,这玩意一看就知道能干啥了。实现互斥锁呗,又因为能在分布式的情况下,所以能实现分布式锁呗。
如何实现呢?这玩意其实跟选主基本一样,我们也可以利用临时节点的创建来实现。
首先肯定是如何获取锁,因为创建节点的唯一性,我们可以让多个客户端同时创建一个临时节点,创建成功的就说明获取到了锁 。然后没有获取到锁的客户端也像上面选主的非主节点创建一个 watcher 进行节点状态的监听,如果这个互斥锁被释放了(可能获取锁的客户端宕机了,或者那个客户端主动释放了锁)可以调用回调函数重新获得锁。
zk 中不需要向 redis 那样考虑锁得不到释放的问题了,因为当客户端挂了,节点也挂了,锁也释放了。是不是很简单?
那能不能使用 zookeeper 同时实现 共享锁和独占锁 呢?答案是可以的,不过稍微有点复杂而已。还记得 有序的节点 吗?
这个时候我规定所有创建节点必须有序,当你是读请求(要获取共享锁)的话,如果 没有比自己更小的节点,或比自己小的节点都是读请求 ,则可以获取到读锁,然后就可以开始读了。若比自己小的节点中有写请求 ,则当前客户端无法获取到读锁,只能等待前面的写请求完成。
如果你是写请求(获取独占锁),若 没有比自己更小的节点 ,则表示当前客户端可以直接获取到写锁,对数据进行修改。若发现 有比自己更小的节点,无论是读操作还是写操作,当前客户端都无法获取到写锁 ,等待所有前面的操作完成。
这就很好地同时实现了共享锁和独占锁,当然还有优化的地方,比如当一个锁得到释放它会通知所有等待的客户端从而造成 羊群效应 。此时你可以通过让等待的节点只监听他们前面的节点。
具体怎么做呢?其实也很简单,你可以让 读请求监听比自己小的最后一个写请求节点,写请求只监听比自己小的最后一个节点 ,感兴趣的小伙伴可以自己去研究一下。
1.3.2、命名服务
如何给一个对象设置ID,大家可能都会想到 UUID,但是 UUID 最大的问题就在于它太长了。。。(太长不一定是好事,嘿嘿嘿)。那么在条件允许的情况下,我们能不能使用 zookeeper 来实现呢?
我们之前提到过 zookeeper 是通过 树形结构 来存储数据节点的,那也就是说,对于每个节点的 全路径,它必定是唯一的,我们可以使用节点的全路径作为命名方式了。而且更重要的是,路径是我们可以自己定义的,这对于我们对有些有语意的对象的ID设置可以更加便于理解。
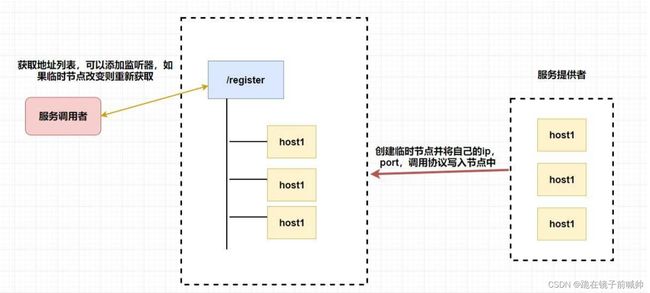
1.3.3、集群管理和注册中心
看到这里是不是觉得 zookeeper 实在是太强大了,它怎么能这么能干!
别急,它能干的事情还很多呢。可能我们会有这样的需求,我们需要了解整个集群中有多少机器在工作,我们想对集群中的每台机器的运行时状态进行数据采集,对集群中机器进行上下线操作等等。
而 zookeeper 天然支持的 watcher 和 临时节点能很好的实现这些需求。我们可以为每条机器创建临时节点,并监控其父节点,如果子节点列表有变动(我们可能创建删除了临时节点),那么我们可以使用在其父节点绑定的 watcher 进行状态监控和回调。

至于注册中心也很简单,我们同样也是让 服务提供者 在 zookeeper 中创建一个临时节点并且将自己的 ip、port、调用方式 写入节点,当 服务消费者 需要进行调用的时候会 通过注册中心找到相应的服务的地址列表(IP端口什么的) ,并缓存到本地(方便以后调用),当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从地址列表中取一个服务提供者的服务器调用服务。
当服务提供者的某台服务器宕机或下线时,相应的地址会从服务提供者地址列表中移除。同时,注册中心会将新的服务地址列表发送给服务消费者的机器并缓存在消费者本机(当然你可以让消费者进行节点监听,我记得 Eureka 会先试错,然后再更新)。
2、ZooKeeper 重要概念
2.1、Data model(数据模型)
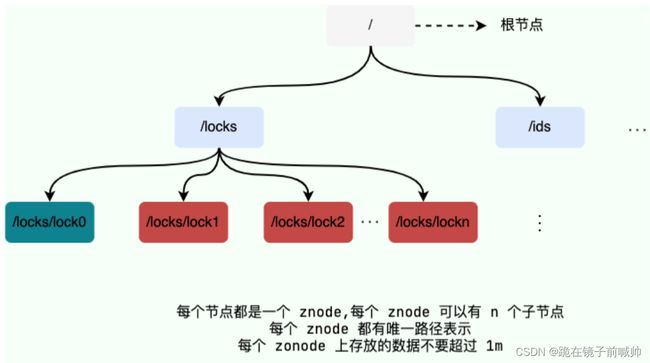
ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二级制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在 ZooKeeper 中被称为 znode,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都一个唯一的路径标识。
强调一句:ZooKeeper 主要是用来协调服务的,而不是用来存储业务数据的,所以不要放比较大的数据在 znode 上,ZooKeeper 给出的上限是每个结点的数据大小最大是 1M。
从下图可以更直观地看出:ZooKeeper 节点路径标识方式和 Unix 文件系统路径非常相似,都是由一系列使用斜杠"/"进行分割的路径表示,开发人员可以向这个节点中写入数据,也可以在节点下面创建子节点。这些操作我们后面都会介绍到。
2.2、znode(数据节点)
介绍了 ZooKeeper 树形数据模型之后,我们知道每个数据节点在 ZooKeeper 中被称为 znode,它是 ZooKeeper 中数据的最小单元。你要存放的数据就放在上面,是你使用 ZooKeeper 过程中经常需要接触到的一个概念。
我们通常是将 znode 分为 4 大类:
- 持久(PERSISTENT)节点 :一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
- 临时(EPHEMERAL)节点 :临时节点的生命周期是与 客户端会话(session) 绑定的,会话消失则节点消失 。并且,临时节点只能做叶子节点 ,不能创建子节点。
- 持久顺序(PERSISTENT_SEQUENTIAL)节点 :除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 /node1/app0000000001 、/node1/app0000000002 。
- 临时顺序(EPHEMERAL_SEQUENTIAL)节点 :除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性
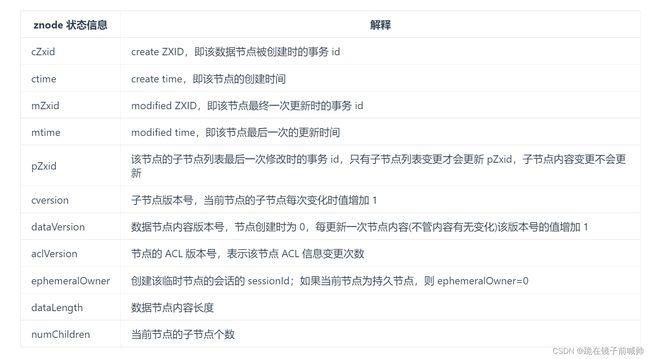
每个 znode 由 2 部分组成:
- stat :状态信息
- data : 节点存放的数据的具体内容
Stat 类中包含了一个数据节点的所有状态信息的字段,包括事务 ID(cZxid)、节点创建时间(ctime) 和子节点个数(numChildren) 等等。下面我们来看一下每个 znode 状态信息究竟代表的是什么吧!
2.3、版本(version)
在前面我们已经提到,对应于每个 znode,ZooKeeper 都会为其维护一个叫作 Stat 的数据结构,Stat 中记录了这个 znode 的三个相关的版本:
- dataVersion :当前 znode 节点的版本号。
- cversion : 当前 znode 子节点的版本。
- aclVersion : 当前 znode 的 ACL 的版本。
2.4、ACL(权限控制)
ZooKeeper 采用 ACL(AccessControlLists)策略来进行权限控制,类似于 UNIX 文件系统的权限控制。对于 znode 操作的权限,ZooKeeper 提供了以下 5 种:
- CREATE : 能创建子节点
- READ :能获取节点数据和列出其子节点
- WRITE : 能设置/更新节点数据
- DELETE : 能删除子节点
- ADMIN : 能设置节点 ACL 的权限
其中尤其需要注意的是,CREATE 和 DELETE 这两种权限都是针对 子节点 的权限控制。对于身份认证,提供了以下几种方式:
- world : 默认方式,所有用户都可无条件访问。
- auth :不使用任何 id,代表任何已认证的用户。
- digest :用户名:密码认证方式: username:password 。
- ip : 对指定 ip 进行限制
2.5、Watcher(事件监听器)
Watcher 为事件监听器,是 zk 非常重要的一个特性,很多功能都依赖于它,它有点类似于订阅的方式,即客户端向服务端注册指定的 watcher ,当服务端符合了 watcher 的某些事件或要求则会向客户端发送事件通知 ,客户端收到通知后找到自己定义的 Watcher 然后 执行相应的回调方法 。
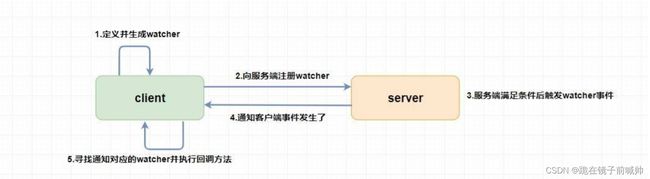
zookeeper 监听原理
zookeeper的监听事件有四种
- nodedatachanged 节点数据改变
- nodecreate 节点创建事件
- nodedelete 节点删除事件
- nodechildrenchanged 子节点改变事件

- 首先要有⼀个 main()线程。
- 在 main 线程中创建 Zookeeper 客户端, 这时就会创建两个线程, ⼀个负责网络连接通信(connet),⼀个负责监听 (listener) 。
- 通过 connect 线程将注册的监听事件发送给 Zookeeper 。
- 在 Zookeeper 的注册监听器列表中将注册的监听事件添加到列表中。
- Zookeeper 监听到有数据或路径变化, 就会将这个消息发送给 listener 线程。
- listener 线程内部调用了 process() 方法。
2.6、会话(Session)
Session 可以看作是 ZooKeeper 服务器与客户端的之间的一个 TCP 长连接,通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能够向 ZooKeeper 服务器发送请求并接受响应,同时还能够通过该连接接收来自服务器的 Watcher 事件通知。
Session 有一个属性叫做:sessionTimeout ,sessionTimeout 代表会话的超时时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,只要在sessionTimeout规定的时间内能够重新连接上集群中任意一台服务器,那么之前创建的会话仍然有效。
另外,在为客户端创建会话之前,服务端首先会为每个客户端都分配一个 sessionID。由于 sessionID是 ZooKeeper 会话的一个重要标识,许多与会话相关的运行机制都是基于这个 sessionID 的,因此,无论是哪台服务器为客户端分配的 sessionID,都务必保证全局唯一。
3、ZooKeeper 集群
为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。通常 3 台服务器就可以构成一个 ZooKeeper 集群了。ZooKeeper 官方提供的架构图就是一个 ZooKeeper 集群整体对外提供服务。
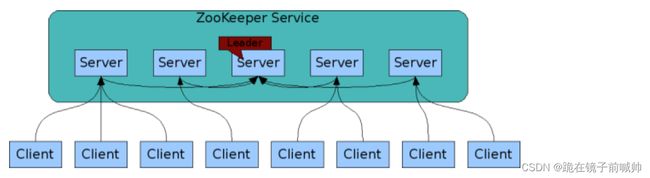
上图中每一个 Server 代表一个安装 ZooKeeper 服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 ZAB 协议(ZooKeeper Atomic Broadcast)来保持数据的一致性。
最典型集群模式: Master/Slave 模式(主备模式)。在这种模式中,通常 Master 服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
3.1、ZooKeeper 集群角色
但是,在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了 Leader、Follower 和 Observer 三种角色。如下图所示
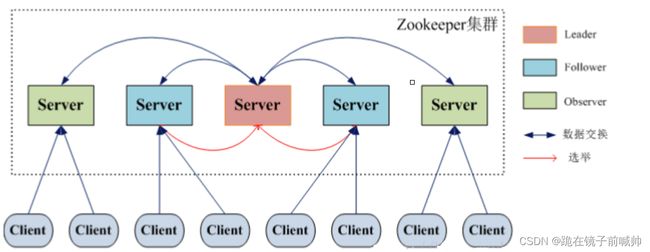
ZooKeeper 集群中的所有机器通过一个 Leader 选举过程 来选定一台称为 “Leader” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,Follower 和 Observer 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。

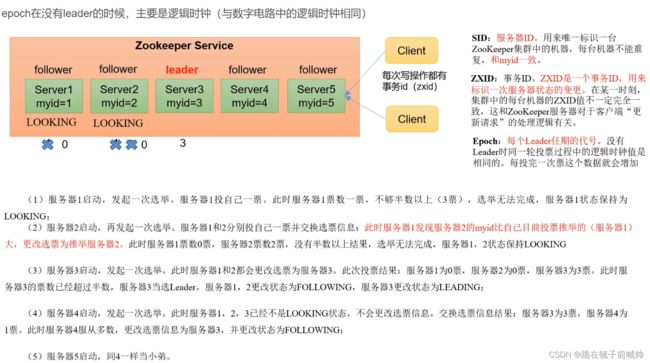
3.2、ZooKeeper 集群 Leader 选举过程
Zookeeper第一次启动的选举机制
Zookeeper非第一次启动的选举机制
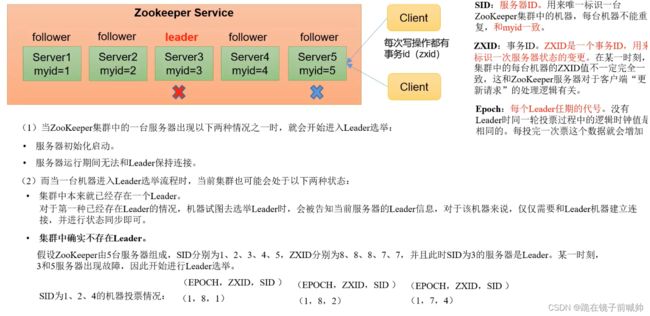
选举Leader规则:①EPOCH大的直接胜出 ②EPOCH相同,事务id大的胜出 ③事务id相同,服务器id大的胜出
3.3、ZooKeeper 集群为啥最好奇数台
ZooKeeper 集群在宕掉几个 ZooKeeper 服务器之后,如果剩下的 ZooKeeper 服务器个数大于宕掉的个数的话整个 ZooKeeper 才依然可用。假如我们的集群中有 n 台 ZooKeeper 服务器,那么也就是剩下的服务数必须大于 n/2。先说一下结论,2n 和 2n-1 的容忍度是一样的,都是 n-1,大家可以先自己仔细想一想,这应该是一个很简单的数学问题了。
比如假如我们有 3 台,那么最大允许宕掉 1 台 ZooKeeper 服务器,如果我们有 4 台的的时候也同样只允许宕掉 1 台。 假如我们有 5 台,那么最大允许宕掉 2 台 ZooKeeper 服务器,如果我们有 6 台的的时候也同样只允许宕掉 2 台。
综上,何必增加那一个不必要的 ZooKeeper 呢?
3.4、ZooKeeper 选举的过半机制防止脑裂
何为集群脑裂
对于一个集群,通常多台机器会部署在不同机房,来提高这个集群的可用性。保证可用性的同时,会发生一种机房间网络线路故障,导致机房间网络不通,而集群被割裂成几个小集群。这时候子集群各自选主导致“脑裂”的情况。
举例说明:比如现在有一个由 6 台服务器所组成的一个集群,部署在了 2 个机房,每个机房 3 台。正常情况下只有 1 个 leader,但是当两个机房中间网络断开的时候,每个机房的 3 台服务器都会认为另一个机房的 3 台服务器下线,而选出自己的 leader 并对外提供服务。若没有过半机制,当网络恢复的时候会发现有 2 个 leader。仿佛是 1 个大脑(leader)分散成了 2 个大脑,这就发生了脑裂现象。脑裂期间 2 个大脑都可能对外提供了服务,这将会带来数据一致性等问题。
过半机制是如何防止脑裂现象产生的
ZooKeeper 的过半机制导致不可能产生 2 个 leader,因为少于等于一半是不可能产生 leader 的,这就使得不论机房的机器如何分配都不可能发生脑裂。
4、ZAB 协议和 Paxos 算法
Paxos 算法应该可以说是 ZooKeeper 的灵魂了。但是,ZooKeeper 并没有完全采用 Paxos 算法 ,而是使用 ZAB 协议作为其保证数据一致性的核心算法。另外,在 ZooKeeper 的官方文档中也指出,ZAB 协议并不像 Paxos 算法那样,是一种通用的分布式一致性算法,它是一种特别为 Zookeeper 设计的崩溃可恢复的原子消息广播算法。
4.1、ZAB 协议介绍
ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
4.2、ZAB 中的三个角色
和介绍 Paxos 一样,在介绍 ZAB 协议之前,我们首先来了解一下在 ZAB 中三个主要的角色,Leader 领导者、Follower跟随者、Observer观察者 。
4.2、ZAB 协议两种基本的模式:崩溃恢复和消息广播
ZAB 协议包括两种基本的模式,分别是
- 崩溃恢复 :当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。其中,所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致。
- 消息广播 :当集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进入消息广播模式了。 当一台同样遵守 ZAB 协议的服务器启动后加入到集群中时,如果此时集群中已经存在一个 Leader 服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式:找到 Leader 所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
消息广播模式
第一步肯定需要 Leader 将写请求 广播 出去呀,让 Leader 问问 Followers 是否同意更新,如果超过半数以上的同意那么就进行 Follower 和 Observer 的更新(和 Paxos 一样)。当然这么说有点虚,画张图理解一下。
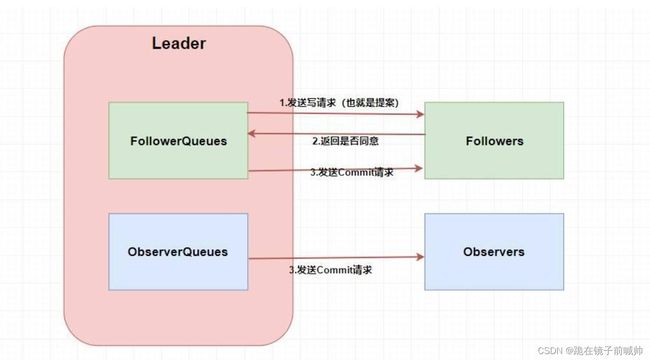
这两个 Queue 哪冒出来的?答案是 ZAB 需要让 Follower 和 Observer 保证顺序性 。何为顺序性,比如我现在有一个写请求A,此时 Leader 将请求A广播出去,因为只需要半数同意就行,所以可能这个时候有一个 Follower F1因为网络原因没有收到,而 Leader 又广播了一个请求B,因为网络原因,F1竟然先收到了请求B然后才收到了请求A,这个时候请求处理的顺序不同就会导致数据的不同,从而 产生数据不一致问题 。
所以在 Leader 这端,它为每个其他的 zkServer 准备了一个 队列 ,采用先进先出的方式发送消息。由于协议是 通过 TCP 来进行网络通信的,保证了消息的发送顺序性,接受顺序性也得到了保证。
除此之外,在 ZAB 中还定义了一个 全局单调递增的事务ID ZXID ,它是一个64位long型,其中高32位表示 epoch 年代,低32位表示事务id。epoch 是会根据 Leader 的变化而变化的,当一个 Leader 挂了,新的 Leader 上位的时候,年代(epoch)就变了。而低32位可以简单理解为递增的事务id。
定义这个的原因也是为了顺序性,每个 proposal 在 Leader 中生成后需要 通过其 ZXID 来进行排序 ,才能得到处理。
崩溃恢复模式
说到崩溃恢复我们首先要提到 ZAB 中的 Leader 选举算法,当系统出现崩溃影响最大应该是 Leader 的崩溃,因为我们只有一个 Leader ,所以当 Leader 出现问题的时候我们势必需要重新选举 Leader 。
Leader 选举可以分为两个不同的阶段,第一个是我们提到的 Leader 宕机需要重新选举,第二则是当 Zookeeper 启动时需要进行系统的 Leader 初始化选举。下面我先来介绍一下 ZAB 是如何进行初始化选举的。
假设我们集群中有3台机器,那也就意味着我们需要两台以上同意(超过半数)。比如这个时候我们启动了 server1 ,它会首先 投票给自己 ,投票内容为服务器的 myid 和 ZXID ,因为初始化所以 ZXID 都为0,此时 server1 发出的投票为 (1,0)。但此时 server1 的投票仅为1,所以不能作为 Leader ,此时还在选举阶段所以整个集群处于 Looking 状态。
接着 server2 启动了,它首先也会将投票选给自己(2,0),并将投票信息广播出去(server1也会,只是它那时没有其他的服务器了),server1 在收到 server2 的投票信息后会将投票信息与自己的作比较。首先它会比较 ZXID ,ZXID 大的优先为 Leader,如果相同则比较 myid,myid 大的优先作为 Leader。所以此时server1 发现 server2 更适合做 Leader,它就会将自己的投票信息更改为(2,0)然后再广播出去,之后server2 收到之后发现和自己的一样无需做更改,并且自己的 投票已经超过半数 ,则 确定 server2 为 Leader,server1 也会将自己服务器设置为 Following 变为 Follower。整个服务器就从 Looking 变为了正常状态。
当 server3 启动发现集群没有处于 Looking 状态时,它会直接以 Follower 的身份加入集群。
还是前面三个 server 的例子,如果在整个集群运行的过程中 server2 挂了,那么整个集群会如何重新选举 Leader 呢?其实和初始化选举差不多。
首先毫无疑问的是剩下的两个 Follower 会将自己的状态 从 Following 变为 Looking 状态 ,然后每个 server 会向初始化投票一样首先给自己投票(这不过这里的 zxid 可能不是0了,这里为了方便随便取个数字)。
假设 server1 给自己投票为(1,99),然后广播给其他 server,server3 首先也会给自己投票(3,95),然后也广播给其他 server。server1 和 server3 此时会收到彼此的投票信息,和一开始选举一样,他们也会比较自己的投票和收到的投票(zxid 大的优先,如果相同那么就 myid 大的优先)。这个时候 server1 收到了 server3 的投票发现没自己的合适故不变,server3 收到 server1 的投票结果后发现比自己的合适于是更改投票为(1,99)然后广播出去,最后 server1 收到了发现自己的投票已经超过半数就把自己设为 Leader,server3 也随之变为 Follower。
请注意 ZooKeeper 为什么要设置奇数个结点?比如这里我们是三个,挂了一个我们还能正常工作,挂了两个我们就不能正常工作了(已经没有超过半数的节点数了,所以无法进行投票等操作了)。而假设我们现在有四个,挂了一个也能工作,但是挂了两个也不能正常工作了,这是和三个一样的,而三个比四个还少一个,带来的效益是一样的,所以 Zookeeper 推荐奇数个 server 。
那么说完了 ZAB 中的 Leader 选举方式之后我们再来了解一下 崩溃恢复 是什么玩意?
其实主要就是 当集群中有机器挂了,我们整个集群如何保证数据一致性?
如果只是 Follower 挂了,而且挂的没超过半数的时候,因为我们一开始讲了在 Leader 中会维护队列,所以不用担心后面的数据没接收到导致数据不一致性。
如果 Leader 挂了那就麻烦了,我们肯定需要先暂停服务变为 Looking 状态然后进行 Leader 的重新选举(上面我讲过了),但这个就要分为两种情况了,分别是 确保已经被Leader提交的提案最终能够被所有的Follower提交 和 跳过那些已经被丢弃的提案 。
确保已经被Leader提交的提案最终能够被所有的Follower提交是什么意思呢?
假设 Leader (server2) 发送 commit 请求(忘了请看上面的消息广播模式),他发送给了 server3,然后要发给 server1 的时候突然挂了。这个时候重新选举的时候我们如果把 server1 作为 Leader 的话,那么肯定会产生数据不一致性,因为 server3 肯定会提交刚刚 server2 发送的 commit 请求的提案,而 server1 根本没收到所以会丢弃。
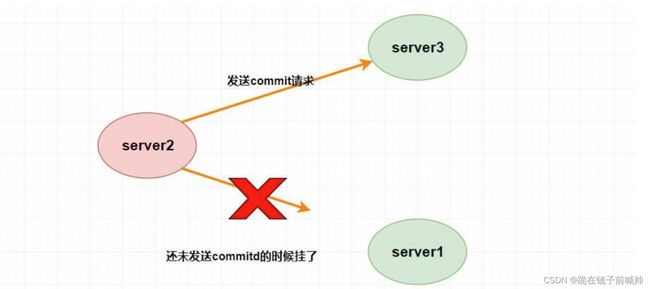
那怎么解决呢?
聪明的同学肯定会质疑,这个时候 server1 已经不可能成为 Leader 了,因为 server1 和 server3 进行投票选举的时候会比较 ZXID ,而此时 server3 的 ZXID 肯定比 server1 的大了。(不理解可以看前面的选举算法)
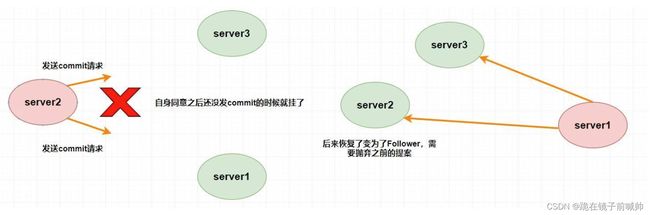
那么跳过那些已经被丢弃的提案又是什么意思呢?
假设 Leader (server2) 此时同意了提案N1,自身提交了这个事务并且要发送给所有 Follower 要 commit 的请求,却在这个时候挂了,此时肯定要重新进行 Leader 的选举,比如说此时选 server1 为 Leader (这无所谓)。但是过了一会,这个 挂掉的 Leader 又重新恢复了 ,此时它肯定会作为 Follower 的身份进入集群中,需要注意的是刚刚 server2 已经同意提交了提案N1,但其他 server 并没有收到它的 commit 信息,所以其他 server 不可能再提交这个提案N1了,这样就会出现数据不一致性问题了,所以 该提案N1最终需要被抛弃掉 。
5、下载安装
ZooKeeper 本身可以以单机模式安装运行,不过它的长处在于通过分布式 ZooKeeper 集群(一个Leader,多个Follower),基于一定的策略来保证 ZooKeeper 集群的稳定性和可用性,从而实现分布式应用的可靠性。
1、下载 zookeeper
ZooKeeper 下载地址: https://zookeeper.apache.org/releases.html
2、安装 JDK
由于 zookeeper 集群的运行需要 Java 运行环境,所以需要首先安装 JDK。
3、解压 zookeeper
在指定目录下解压下载的 zookeeper(我的解压文件夹放在桌面下)。
4、修改配置文件 zoo.cfg
单机配置时:只配置dataDir和dataLogDir即可,不用配置下面的server.*
将 conf 下 zoo_sample.cfg 文件复制并重命名为 zoo.cfg 文件。然后通过 vim zoo.cfg 命令对该文件进行修改:
server1
#客户端与服务器或者服务器与服务器之间维持心跳,也就是每个 tickTime 时间就会发送一次心跳
tickTime=2000
#Leader允许Follower启动时在initLimit时间内完成数据同步,单位:tickTime
initLimit=10
#Leader发送心跳包给集群中所有Follower,若Follower在syncLimit时间内没有响应,那么Leader就认为该follower已经挂掉了,单位:tickTime
syncLimit=5
#配置ZK的数据目录
dataDir=C:\\Users\\13992\\Desktop\\zookeeper\\server1\\data
#用于接收客户端请求的端口号
clientPort=2181
#配置ZK的日志目录
dataLogDir=C:\\Users\\13992\\Desktop\\zookeeper\\server1\\logs
#ZK集群节点配置,端口号2888用于集群节点之间数据通信,端口号3888用于集群中Leader选举
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
server2
#客户端与服务器或者服务器与服务器之间维持心跳,也就是每个 tickTime 时间就会发送一次心跳
tickTime=2000
#Leader允许Follower启动时在initLimit时间内完成数据同步,单位:tickTime
initLimit=10
#Leader发送心跳包给集群中所有Follower,若Follower在syncLimit时间内没有响应,那么Leader就认为该follower已经挂掉了,单位:tickTime
syncLimit=5
#配置ZK的数据目录
dataDir=C:\\Users\\13992\\Desktop\\zookeeper\\server2\\data
#用于接收客户端请求的端口号
clientPort=2182
#配置ZK的日志目录
dataLogDir=C:\\Users\\13992\\Desktop\\zookeeper\\server2\\logs
#ZK集群节点配置,端口号2888用于集群节点之间数据通信,端口号3888用于集群中Leader选举
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
server3
#客户端与服务器或者服务器与服务器之间维持心跳,也就是每个 tickTime 时间就会发送一次心跳
tickTime=2000
#Leader允许Follower启动时在initLimit时间内完成数据同步,单位:tickTime
initLimit=10
#Leader发送心跳包给集群中所有Follower,若Follower在syncLimit时间内没有响应,那么Leader就认为该follower已经挂掉了,单位:tickTime
syncLimit=5
#配置ZK的数据目录
dataDir=C:\\Users\\13992\\Desktop\\zookeeper\\server3\\data
#用于接收客户端请求的端口号
clientPort=2183
#配置ZK的日志目录
dataLogDir=C:\\Users\\13992\\Desktop\\zookeeper\\server3\\logs
#ZK集群节点配置,端口号2888用于集群节点之间数据通信,端口号3888用于集群中Leader选举
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
①、tickTime:基本事件单元,这个时间是作为Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,每隔tickTime时间就会发送一个心跳;最小 的session过期时间为2倍tickTime
②、dataDir:存储内存中数据库快照的位置,除非另有说明,否则指向数据库更新的事务日志。注意:应该谨慎的选择日志存放的位置,使用专用的日志存储设备能够大大提高系统的性能,如果将日志存储在比较繁忙的存储设备上,那么将会很大程度上影像系统性能。
③、client:监听客户端连接的端口。
④、initLimit:允许follower连接并同步到Leader的初始化连接时间,以tickTime为单位。当初始化连接时间超过该值,则表示连接失败。
⑤、syncLimit:表示Leader与Follower之间发送消息时,请求和应答时间长度。如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
⑥、server.A=B:C:D
- A:其中 A 是一个数字,表示这个是服务器的编号。
- B:是这个服务器的 ip 地址。
- C:Zookeeper服务器之间的通信端口。
- D:Leader选举的端口。
我们需要修改的第一个是 dataDir,在指定的位置处创建好目录。第二个需要新增的是 server.A=B:C:D 配置,其中 A 对应下面我们即将介绍的 myid 文件。B是集群的各个IP地址,C:D 是端口配置。
5、创建 myid 文件
在 上一步 dataDir 指定的目录下,创建 myid 文件。然后在该文件添加上一步 server 配置的对应 A 数字。比如我们上面的配置:dataDir=C:\Users\13992\Desktop\zookeeper\server1\data,然后下面配置是:
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
那么就必须在 localhost 本机的 C:\Users\13992\Desktop\zookeeper\server1\data 目录下创建 myid 文件,然后在该文件中写上 1 即可。后面的机器依次在相应目录创建 myid 文件,写上相应配置数字即可。server1的就是1,server2的就是2,server3的就是3。
6、配置环境变量
为了能够在任意目录启动 zookeeper集群,我们需要配置环境变量。这不是搭建集群的必要操作,只不过如果你不配置环境变量,那么每次启动zookeeper需要到安装文件的 bin 目录下去启动。
7、启动zookeeper服务
zkServer.cmd
6、zookeeper 客户端API操作
ZooKeeper应用的开发主要通过 Java客户端API去连接和操作ZooKeeper集群。
ZooKeeper的 Java客户端API有:
- ZooKeeper官方的Java客户端API。
- 第三方的Java客户端API:比如:ZKClient,Curator(重点)。
6.1、Zookeeper官方客户端API
ZooKeeper官方的 Java客户端API提供了基本的操作。
例如:创建会话、创建节点、读取节点、 更新数据、删除节点和检查节点是否存在等。不过,对于实际开发来说,ZooKeeper官方API有一些不足之处,例如:
- ZooKeeper的Watcher监测是一次性的,每次触发之后都需要重新进行注册。∙
- 会话超时之后没有实现重连机制。
- 异常处理烦琐,ZooKeeper提供了很多异常,对于开发人员来说可能根本不知道应该如何处理这些抛出的异常。
- 仅提供了简单的 byte[]数组类型的接口,没有提供Java POJO级别的序列化数据处理接口。
- 创建节点时如果抛出异常,需要自行检查节点是否存在。
- 无法实现级联删除。
总之,ZooKeeper官方API功能比较简单,在实际开发过程中比较笨重,一般不推荐使用。但是,第三方客户端框架的底层封装使用的都是原生API。所以有必要了解一下原生API。
Zookeeper 提供了 Java客户端,创建项目并引入其依赖:
<!-- Zookeeper 原生API客户端 -->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.3</version>
</dependency>
注意:保持与服务端版本一致,不然会有很多兼容性的问题。
1、 ZooKeeper类
1.1 常用构造器
简单介绍一下参数比较多的构造器:
ZooKeeper(String connectString, int sessionTimeout, Watcher watcher, boolean canBeReadOnly, HostProvider aHostProvider)
- connectString:使用逗号分隔的列表,每个ZooKeeper节点是一个 host:port 对,集群模式下用逗号隔开,host:是机器名或者IP地址,port:是ZooKeeper节点对客户端提供服务的端口号。
- sessionTimeout:会话超时时间,该值不能超过服务端所设置的minSessionTimeout 和maxSessionTimeout;
- watcher:会话监听器,服务端事件将会触该监听;一般我们可以实现 Watcher接口。
- sessionId(long):自定义会话ID;
- sessionPasswd(byte[]):会话密码;
- canBeReadOnly(boolean):该连接是否为只读的;
- hostProvider(HostProvider):服务端地址提供者,指示客户端如何选择某个服务来调用,默认采用
StaticHostProvider实现。
下面实例我们使用这个构造器:
ZooKeeper (connectString, sessionTimeout, watcher)
1.2 主要方法
- create(path, data, acl,createMode):创建一个给定路径的 znode,并在znode 保存 data[]的
数据,createMode指定 znode 的类型。 - delete(path, version):如果给定 path 上的 znode 的版本和给定的 version 匹配, 删除
znode。 - exists(path, watch):判断给定 path 上的 znode 是否存在,并在 znode 设置一个 watch。
- getData(path, watch):返回给定 path 上的 znode 数据,并在 znode 设置一个watch。
- setData(path, data, version):如果给定 path 上的 znode 的版本和给定的version 匹配,设置
znode 数据。 - getChildren(path, watch):返回给定 path 上的 znode 的孩子 znode 名字,并在 znode
设置一个 watch。 - sync(path):把客户端 session 连接节点和 leader 节点进行同步。
2、原生Java客户端使用
依赖
org.apache.zookeeper
zookeeper
3.4.9
2.1 Zookeeper连接以及基本操作api接口
package com.example.canal.zk;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.ZooKeeper;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
/**
* @Description: Zookeeper连接以及基本操作api
* @Author: yangjj_tc
* @Date: 2023/1/11 10:19
*/
public interface IZookpConnection {
/**
* @Description: 建立会话
* @Author: yangjj_tc
* @Date: 2023/1/11 10:25
*/
ZooKeeper clientConnect() throws IOException;
/**
* @Description: 创建节点
* @Author: yangjj_tc
* @Date: 2023/1/11 10:24
*/
void createNote(String path, String data, CreateMode mode) throws KeeperException, InterruptedException;
/**
* @Description: 获取节点数据
* @Author: yangjj_tc
* @Date: 2023/1/11 10:23
*/
void getNoteData(String path) throws KeeperException, InterruptedException, UnsupportedEncodingException;
/**
* @Description: 更新节点
* @Author: yangjj_tc
* @Date: 2023/1/11 10:22
*/
void updateNote(String path, String data) throws KeeperException, InterruptedException;
/**
* @Description: 删除节点
* @Author: yangjj_tc
* @Date: 2023/1/11 10:23
*/
void deleteNote(String path) throws KeeperException, InterruptedException;
/**
* @Description: 获取直系子节点列表
* @Author: yangjj_tc
* @Date: 2023/1/11 10:25
*/
void getChildrenNode(String path) throws KeeperException, InterruptedException;
}
2.2 Zookeeper连接以及基本操作api实现类
package com.example.canal.zk;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.ACL;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* @Description: 实现类
* @Author: yangjj_tc
* @Date: 2023/1/11 10:26
*/
public class ZookpConnectionImpl implements IZookpConnection {
private ZooKeeper zooKeeper; // 实际操作zookeeper的对象
private String url; // 将要连接的服务器地址
private Watcher watcher; // 事件监听器
private int timeout; // 超时时间
public ZookpConnectionImpl(String url, Watcher watcher, int timeout) throws IOException {
this.url = url;
this.watcher = watcher;
this.timeout = timeout;
connect();
}
private void connect() throws IOException {
this.zooKeeper = new ZooKeeper(url, timeout, watcher);
}
@Override
public ZooKeeper clientConnect() {
return this.zooKeeper;
}
@Override
public void createNote(String path, String data, CreateMode mode) throws InterruptedException, KeeperException {
// 开启监听
zooKeeper.exists(path, true);
ArrayList<ACL> acl = ZooDefs.Ids.OPEN_ACL_UNSAFE;
/**
* path:节点创建的路径
* data:节点创建要保存的数据,是个byte类型的
* acl:节点创建的权限信息(4种类型)
* ANYONE_ID_UNSAFE表示任何⼈,AUTH_IDS此ID仅可⽤于设置ACL,它将被客户机验证的ID替换,OPEN_ACL_UNSAFE这是⼀个完全开放的ACL,CREATOR_ALL_ACL此ACL授予创建者身份验证ID的所有权限
* createMode:创建节点的类型(4种类型)
* PERSISTENT持久节点,PERSISTENT_SEQUENTIAL持久顺序节点,EPHEMERAL临时节点,EPHEMERAL_SEQUENTIAL临时顺序节点
*/
this.zooKeeper.create(path, data.getBytes(), acl, mode);
}
@Override
public void getNoteData(String path) throws InterruptedException, KeeperException, UnsupportedEncodingException {
/**
* path:节点路径
* watch:是否监听 true 表示开启监听 false 不开启监听
* stat:节点状态 null表示获取最新数据
*/
byte[] data = zooKeeper.getData(path, false, null);
System.out.println(new String(data, "utf-8"));
}
@Override
public void updateNote(String path, String data) throws KeeperException, InterruptedException {
// 开启监听
zooKeeper.exists(path, true);
/**
* path:节点路径
* data:节点要修改的数据
* version:节-1,表示对最新版本的数据进⾏修改
*/
this.zooKeeper.setData(path, data.getBytes(), -1);
}
@Override
public void deleteNote(String path) throws KeeperException, InterruptedException {
/**
* path:节点路径
* watch:是否监听 true 表示开启监听 false 不开启监听
*/
Stat exists = this.zooKeeper.exists(path, true);
this.zooKeeper.delete(path, -1);
}
@Override
public void getChildrenNode(String path) throws KeeperException, InterruptedException {
/**
* path:节点路径
* watch:是否监听 true 表示开启监听 false 不开启监听
*/
List<String> childNodes = zooKeeper.getChildren(path, true);
System.out.println(childNodes == null ? Collections.EMPTY_LIST : childNodes);
childNodes.forEach(node -> System.out.println(node));
}
}
2.3 自定义 Zookeeper 客户端
package com.example.canal.zk;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import java.io.IOException;
import java.io.InputStream;
import java.io.UnsupportedEncodingException;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
/**
* @Description: 自定义 Zookeeper 客户端
* @Author: yangjj_tc
* @Date: 2023/1/11 10:46
*/
public class ZookpClient implements Watcher {
private IZookpConnection connection; // 连接zookeeper服务
private static String serverAddr; // 服务端地址
private static int timeout; // 超时时间
private final static CountDownLatch countDownLatch = new CountDownLatch(1);
// 通过读取配置文件初始化参数
static {
InputStream rs = null;
try {
rs = ZookpClient.class.getClassLoader().getResourceAsStream("application.properties");
Properties properties = new Properties();
properties.load(rs);
serverAddr = properties.getProperty("serverAddr");
timeout = Integer.parseInt(properties.getProperty("timeout"));
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
rs.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
public ZookpClient() throws InterruptedException, IOException {
this.connection = new ZookpConnectionImpl(serverAddr, this, timeout);
countDownLatch.await();
}
public void createNode(String path, String data, CreateMode mode) throws InterruptedException, KeeperException {
this.connection.createNote(path, data, mode);
}
public void getNodeData(String path) throws KeeperException, InterruptedException, UnsupportedEncodingException {
connection.getNoteData(path);
}
public void updateNote(String path, String data) throws KeeperException, InterruptedException {
connection.updateNote(path, data);
}
public void deleteNode(String path) throws KeeperException, InterruptedException {
connection.deleteNote(path);
}
public void getChildrenNode(String path) throws KeeperException, InterruptedException {
connection.getChildrenNode(path);
}
@Override
public void process(WatchedEvent event) {
if(Event.KeeperState.SyncConnected == event.getState()){
if(Event.EventType.None == event.getType() && null == event.getPath()){
// 如果收到了服务端的响应事件,连接成功
System.out.println("Zookeeper Server is Connected!");
countDownLatch.countDown();
}else if(Event.EventType.NodeCreated == event.getType()){
System.out.println("success create znode");
}else if(Event.EventType.NodeDataChanged == event.getType()){
System.out.println("success change znode data" + event.getPath());
}else if(Event.EventType.NodeDeleted == event.getType()){
System.out.println("success delete znode");
}else if(Event.EventType.NodeChildrenChanged == event.getType()){
System.out.println("success change NodeChildrenznode" + event.getPath());
}
}
}
}
2.4 功能测试类
package com.example.canal.zk;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.List;
/**
* @Description: 测试类
* @Author: yangjj_tc
* @Date: 2023/1/11 10:53
*/
public class ZookpTest {
private ZookpClient zookpClient = new ZookpClient();
public ZookpTest() throws InterruptedException, IOException {
}
/**
* @Description: 测试创建节点
* @Author: yangjj_tc
* @Date: 2023/1/11 11:08
*/
@org.junit.Test
public void createNodeTest() throws InterruptedException, KeeperException {
zookpClient.createNode("/yang/jun/ccc", "helloWorld1", CreateMode.PERSISTENT);
}
/**
* @Description: 测试获取节点数据
* @Author: yangjj_tc
* @Date: 2023/1/11 11:08
*/
@org.junit.Test
public void getNoteDataTest() throws InterruptedException, KeeperException, UnsupportedEncodingException {
zookpClient.getNodeData("/yang/jun");
}
/**
* @Description: 测试修改节点
* @Author: yangjj_tc
* @Date: 2023/1/11 11:18
*/
@org.junit.Test
public void updateNoteTest() throws KeeperException, InterruptedException {
zookpClient.updateNote("/yang/jun","newData");
}
/**
* @Description: 测试删除节点
* @Author: yangjj_tc
* @Date: 2023/1/11 11:21
*/
@org.junit.Test
public void deleteNodeTest() throws InterruptedException, KeeperException {
zookpClient.deleteNode("/yang/jun/jie");
}
/**
* @Description: 测试获取子节点
* @Author: yangjj_tc
* @Date: 2023/1/11 11:23
*/
@org.junit.Test
public void getChildrenNode() throws KeeperException, InterruptedException {
zookpClient.getChildrenNode("/yang");
}
}
配置文件
# zk
# 地址
serverAddr=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
# 超时时间
timeout=300000
6.2、Zookeeper Curator客户端API操作
原生的 Java API 开发存在的问题
- 会话连接是异步的,需要自己去处理。比如使用CountDownLatch
- Watch 需要重复注册,不然就不能生效
- 开发的复杂性还是比较高的
- 不支持多节点删除和创建。需要自己去递归
Zookeepe r被广泛应用于分布式环境下各种应用程序的协调,Curator 解决了很多Zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher和NodeExistsException异常等等。
依赖
Maven依赖(使用curator的版本:2.12.0,对应Zookeeper的版本为:3.4.x,如果跨版本会有兼容性问题,很有可能导致节点操作失败)
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-client</artifactId>
<version>4.3.0</version>
</dependency>
1、创建连接
① 使用静态工厂方法创建会话
// 重试策略,重试间隔时间为1秒,重试次数为10次。curator管理了zookeeper的连接,在操作zookeeper的过程中出现连接问题会自动重试。
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 10);
// 通过工厂创建连接
CuratorFramework zkClient = CuratorFrameworkFactory.builder().connectString(ZOOKEEPER_ADDRESS) // zookeeper地址
.sessionTimeoutMs(5000) // 会话超时时间,单位毫秒,默认60秒
.connectionTimeoutMs(15000) // 连接创建超时时间,单位毫秒,默认15秒
.retryPolicy(retryPolicy) // 重试策略
.build();
// 打开连接
zkClient.start();
或者
CuratorFramework cf = CuratorFrameworkFactory.newClient(ZOOKEEPER_ADDRESS, 5000, 15000, retryPolicy);
② 创建包含隔离命名空间的会话
为了实现不同的 Zookeeper 业务之间的隔离,需要为每个业务分配一个独立的命名空间(NameSpace),即指定一个 Zookeeper 的根路径,例如当客户端指定了独立命名空间为“/config”,那么该客户端对Zookeeper 上的数据节点的操作都是基于该目录进行的。在多个应用共用一个Zookeeper集群的场景下,这对于实现不同应用之间的相互隔离十分有意义。
CuratorFramework zkClient = CuratorFrameworkFactory.builder().connectString(zkAddr)
.sessionTimeoutMs(5000)
.connectionTimeoutMs(3000)
.retryPolicy(new ExponentialBackoffRetry(1000, 5))
.namespace("config")
.build();
2、启动客户端
zkClient.start();
3、创建节点
Zookeeper 的节点模式总共有三种,持久节点,临时节点,顺序节点,通过组合我们可以实现以下4种节点类型:
- PERSISTENT:持久化
- PERSISTENT_SEQUENTIAL:持久化并且带序列号
- EPHEMERAL:临时
- EPHEMERAL_SEQUENTIAL:临时并且带序列号
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 10);
CuratorFramework zkClient =
CuratorFrameworkFactory.newClient("127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183", 5000, 15000, retryPolicy);
zkClient.start();
// 创建一个节点,初始内容为空
// 如果没有设置节点属性,节点创建模式默认为持久化节点,内容默认为空
zkClient.create().forPath("/yang");
// 创建一个节点,附带初始化内容
zkClient.create().forPath("/yang", "hello".getBytes());
// 创建一个节点,指定创建模式(临时节点),内容为空
zkClient.create().withMode(CreateMode.EPHEMERAL).forPath("/yang");
// 创建一个节点,指定创建模式(临时节点),附带初始化内容
zkClient.create().withMode(CreateMode.EPHEMERAL).forPath("/yang", "hello".getBytes());
// 创建一个节点,指定创建模式(临时节点),附带初始化内容,并且自动递归创建父节点
zkClient.create().creatingParentContainersIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/yang/jun/jie", "hello".getBytes());
4、读取数据节点
// 读取一个节点的数据内容
System.out.println(new String(zkClient.getData().forPath("/yang"), "utf-8"));
// 读取一个节点的数据内容,同时获取到该节点的stat
Stat stat = new Stat();
System.out.println(new String(zkClient.getData().storingStatIn(stat).forPath("/yang"), "utf-8"));
// 获取某个节点的所有子节点路径
System.out.println(zkClient.getChildren().forPath("/yang"));
5、更新数据节点
// 更新一个节点的数据内容
// 该接口会返回一个Stat实例
zkClient.setData().forPath("/yang", "yang".getBytes());
// 更新一个节点的数据内容,强制指定版本进行更新
zkClient.setData().withVersion(-1).forPath("/yang/jun", "jun".getBytes());
// 检查节点是否存在
zkClient.checkExists().forPath("/yang");
6、删除数据节点
// 删除一个节点
// 此方法只能删除叶子节点,否则会抛出异常。
zkClient.delete().forPath("/yang");
// 删除一个节点,并且递归删除其所有的子节点
zkClient.delete().deletingChildrenIfNeeded().forPath("/yang");
// 删除一个节点,强制指定版本进行删除
zkClient.delete().withVersion(-1).forPath("/yang");
// 删除一个节点,强制保证删除
// guaranteed()是一个保障措施,只要客户端会话有效,会在后台持续进行删除操作,直到成功。
zkClient.delete().guaranteed().forPath("/yang");
// 上面的多个流式接口是可以自由组合的,例如:
zkClient.delete().guaranteed().deletingChildrenIfNeeded().withVersion(-1).forPath("/yang");
7、事务
CuratorFramework 的实例包含 inTransaction 接口方法,调用此方法开启一个 ZooKeeper 事务。可以复合create,setData,check,delete 等操作然后调用 commit 作为一个原子操作提交。例如:
zkClient.inTransaction().check().forPath("/yang")
.and().create().withMode(CreateMode.PERSISTENT).forPath("/yang/c", "new".getBytes())
.and().setData().forPath("/yang/c", "newnew".getBytes())
.and().commit();
8、异步接口
上面提到的创建、删除、更新、读取等方法都是同步的,Curator提供异步接口,引入了 BackgroundCallback 接口用于处理异步接口调用之后服务端返回的结果信息。BackgroundCallback 接口中一个重要的回调值为CuratorEvent,里面包含事件类型、响应吗和节点的详细信息。
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 5, 300, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(10000), new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "zkSyncThreadPool");
}
});
zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL)
.inBackground((curatorFramework, curatorEvent) -> {
System.out.println(
String.format("eventType:%s,resultCode:%s", curatorEvent.getType(), curatorEvent.getResultCode()));
}, executor).forPath("/yang");
如果 inBackground() 方法不指定 executor,那么会默认使用Curator的EventThread去进行异步处理。
9、事件监听
- NodeCache
NodeCache用于监听指定ZooKeeper数据节点本身的变化,数据变化或者节点被删除都会触发回调方法。
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 10);
CuratorFramework zkClient =
CuratorFrameworkFactory.newClient("127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183", 5000, 15000, retryPolicy);
zkClient.start();
NodeCache cache = new NodeCache(zkClient, "/yang", false);
cache.start(true);
cache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
ChildData currentData = cache.getCurrentData();
if (currentData == null) {
System.out.println("节点被删除");
} else {
String data = new String(currentData.getData());
System.out.println("=====> Node data update, new Data: " + data);
}
}
});
zkClient.setData().forPath("/yang", "data2".getBytes());
// client.delete().forPath(path);
TimeUnit.SECONDS.sleep(5);
cache.close();
- PathChildrenCache
PathChildrenCache是用来监听指定节点 的子节点变化情况。
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 10);
CuratorFramework zkClient =
CuratorFrameworkFactory.newClient("127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183", 5000, 15000, retryPolicy);
zkClient.start();
PathChildrenCache cache = new PathChildrenCache(zkClient, "/yang", true);
// 如果目录存在子节点,则所有子节点都会触发通知,同时会触发INITIALIZED事件,建议使用
cache.start(PathChildrenCache.StartMode.POST_INITIALIZED_EVENT);
// 较POST_INITIALIZED_EVENT,少了INITIALIZED事件
// cache.start(PathChildrenCache.StartMode.NORMAL);
// 如果目录存在子节点,已存在的子节点不触发通知,仅捕获后续发生的变更事件
// cache.start(PathChildrenCache.StartMode.BUILD_INITIAL_CACHE);
cache.getListenable().addListener(new PathChildrenCacheListener() {
public void childEvent(CuratorFramework ient, PathChildrenCacheEvent event) throws Exception {
if (event.getType().equals(PathChildrenCacheEvent.Type.INITIALIZED)) {
System.out.println("子节点初始化成功");
} else if (event.getType().equals(PathChildrenCacheEvent.Type.CHILD_ADDED)) {
System.out.println("添加子节点路径:" + event.getData().getPath());
System.out.println("子节点数据:" + new String(event.getData().getData()));
} else if (event.getType().equals(PathChildrenCacheEvent.Type.CHILD_REMOVED)) {
System.out.println("删除子节点:" + event.getData().getPath());
} else if (event.getType().equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)) {
System.out.println("修改子节点路径:" + event.getData().getPath());
System.out.println("修改子节点数据:" + new String(event.getData().getData()));
}
}
});
zkClient.create().forPath("/yang/jun/jie","data1".getBytes());
TimeUnit.SECONDS.sleep(5);
cache.close();
- TreeCache
结合NodeCache和PathChildrenCahce的特性,是对整个目录进行监听
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 10);
CuratorFramework zkClient =
CuratorFrameworkFactory.newClient("127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183", 5000, 15000, retryPolicy);
zkClient.start();
String path = "/dir1";
TreeCache cache = new TreeCache(zkClient, path);
cache.start();
// 添加错误监听器
cache.getUnhandledErrorListenable().addListener(new UnhandledErrorListener() {
@Override
public void unhandledError(String s, Throwable throwable) {
System.out.println("======> 错误原因:" + throwable.getMessage());
}
});
cache.getListenable().addListener(new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework curatorFramework, TreeCacheEvent treeCacheEvent) throws Exception {
switch (treeCacheEvent.getType()) {
case INITIALIZED:
System.out.println("=====> INITIALIZED : 初始化");
break;
case NODE_ADDED:
System.out.println("=====> NODE_ADDED : " + treeCacheEvent.getData().getPath() + " 数据:"
+ (treeCacheEvent.getData().getData() == null ? ""
: new String(treeCacheEvent.getData().getData())));
break;
case NODE_REMOVED:
System.out.println("=====> NODE_REMOVED : " + treeCacheEvent.getData().getPath() + " 数据:"
+ (treeCacheEvent.getData().getData() == null ? ""
: new String(treeCacheEvent.getData().getData())));
if ("/dir1/dir2".equals(treeCacheEvent.getData().getPath())) {
throw new RuntimeException("=====> 测试异常监听UnhandledErrorListener");
}
break;
case NODE_UPDATED:
System.out.println("=====> NODE_UPDATED : " + treeCacheEvent.getData().getPath() + " 数据:"
+ (treeCacheEvent.getData().getData() == null ? ""
: new String(treeCacheEvent.getData().getData())));
break;
default:
System.out.println("=====> treeCache Type:" + treeCacheEvent.getType());
break;
}
}
});
zkClient.delete().forPath("/dir1/dir2");
zkClient.delete().forPath("/dir1/dir3");
zkClient.delete().forPath("/dir1/dir4");
TimeUnit.SECONDS.sleep(5);
cache.close();
10、ACL权限
RetryPolicy retry = new ExponentialBackoffRetry(1000, 3);
CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181", 5000, 5000, retry);
client.start();
//ACL有IP授权和用户名密码访问的模式
ACL aclRoot = new ACL(Perms.ALL,new Id("digest",DigestAuthenticationProvider.generateDigest("root:root")));
List<ACL> aclList = new ArrayList<ACL>();
aclList.add(aclRoot);
String path = client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL)
.withACL(aclList)
.forPath("/node_3/node_ACL","2".getBytes());
System.out.println(path);
CuratorFramework client1 = CuratorFrameworkFactory.builder().connectString("192.168.0.3:2181")
.sessionTimeoutMs(5000)//会话超时时间
.connectionTimeoutMs(5000)//连接超时时间
.authorization("digest","root:root".getBytes())//权限访问
.retryPolicy(retry)
.build();
client1.start();
String re = new String(client1.getData().forPath("/node_3/node_ACL"));
System.out.println(re);
7、zookeeper 写数据原理
不管是采用命令行还是api操作zookeeper集群,其实都是对于zookeeper进行写数据操作,那它的底层原理是什么呢?
① 直接向leader发写请求

如上图。假设 zookeeper 集群中有三台 zookeeper 服务器,首先 client 会给 leade r写数据,然后leader给其中一个 follower 写数据,之后 follower 会回复leader。此时,集群已经有半数服务器更新了数据,会由 leader 向 client 回复。之后 leader 继续与其它的 follow 进行数据同步与回复确认。
② 直接向leader发写请求

如上图。client 给 follower 发送写请求后,follower 会将请求转发给 leader,leader 进行写操作,并且选择一台follower 完成写操作,follower 响应请求并回复。当超过半数的服务器完成写操作后,会由 leader 回复给最开始响应 client 的 follower,并由它对 client 进行回复。之后继续完成其它 follower 的数据同步与应答。
8、基于 Zookeeper 的分布式锁
对于单机多线程来说,在 Java 中,我们通常使用 ReetrantLock 类、synchronized 关键字这类 JDK 自带的 本地锁 来控制一个 JVM 进程内的多个线程对本地共享资源的访问。
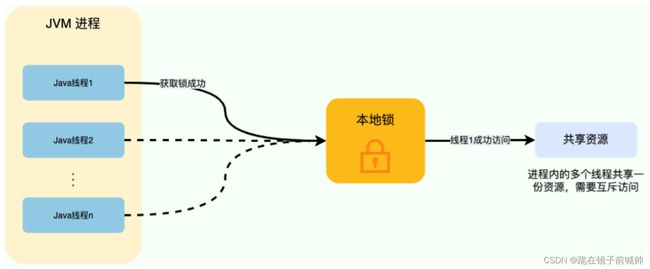
从图中可以看出,这些线程访问共享资源是互斥的,同一时刻只有一个线程可以获取到本地锁访问共享资源。
分布式系统下,不同的服务/客户端通常运行在独立的 JVM 进程上。如果多个 JVM 进程共享同一份资源的话,使用本地锁就没办法实现资源的互斥访问了。于是,分布式锁就诞生了。
举个例子:系统的订单服务一共部署了 3 份,都对外提供服务。用户下订单之前需要检查库存,为了防止超卖,这里需要加锁以实现对检查库存操作的同步访问。由于订单服务位于不同的 JVM 进程中,本地锁在这种情况下就没办法正常工作了。我们需要用到分布式锁,这样的话,即使多个线程不在同一个 JVM 进程中也能获取到同一把锁,进而实现共享资源的互斥访问。
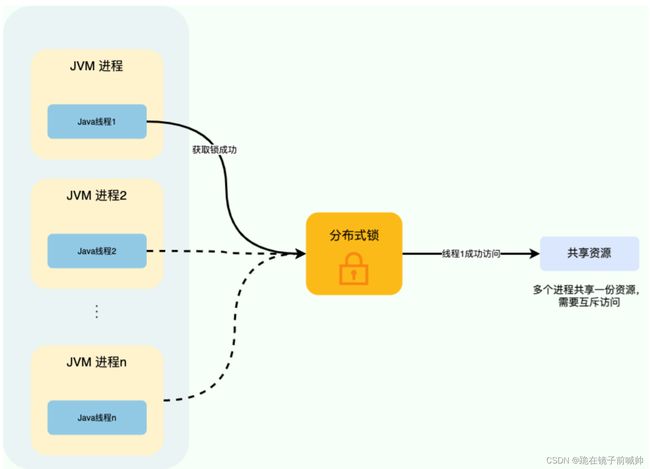
从图中可以看出,这些独立的进程中的线程访问共享资源是互斥的,同一时刻只有一个线程可以获取到分布式锁访问共享资源。
一个最基本的分布式锁需要满足:
- 互斥 :任意一个时刻,锁只能被一个线程持有。
- 高可用 :锁服务是高可用的。并且,即使客户端的释放锁的代码逻辑出现问题,锁最终一定还是会被释放,不会影响其他线程对共享资源的访问。
- 可重入:一个节点获取了锁之后,还可以再次获取锁。
通常情况下,我们一般会选择基于 Redis 或者 ZooKeeper 实现分布式锁,Redis 用的要更多一点。
8.1、如何基于 ZooKeeper 实现分布式锁
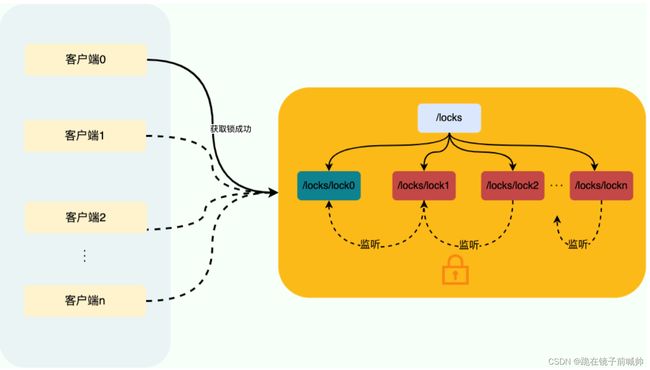
ZooKeeper 分布式锁是基于 临时顺序节点 和 Watcher(事件监听器) 实现的。
获取锁:
- 首先我们要有一个持久节点/locks,客户端获取锁就是在locks下创建临时顺序节点。
- 假设客户端 1 创建了/locks/lock1节点,创建成功之后,会判断 lock1是否是 /locks 下最小的子节点。
- 如果 lock1是最小的子节点,则获取锁成功。否则,获取锁失败。
- 如果获取锁失败,则说明有其他的客户端已经成功获取锁。客户端 1 并不会不停地循环去尝试加锁,而是在前一个节点比如/locks/lock0上注册一个事件监听器。这个监听器的作用是当前一个节点释放锁之后通知客户端 1(避免无效自旋),这样客户端 1 就加锁成功了。
释放锁:
- 成功获取锁的客户端在执行完业务流程之后,会将对应的子节点删除。
- 成功获取锁的客户端在出现故障之后,对应的子节点由于是临时顺序节点,也会被自动删除,避免了锁无法被释放。
- 我们前面说的事件监听器其实监听的就是这个子节点删除事件,子节点删除就意味着锁被释放。
实际项目中,推荐使用 Curator 来实现 ZooKeeper 分布式锁。Curator 是 Netflix 公司开源的一套 ZooKeeper Java 客户端框架,相比于 ZooKeeper 自带的客户端 zookeeper 来说,Curator 的封装更加完善,各种 API 都可以比较方便地使用。
Curator主要实现了下面四种锁:
- InterProcessMutex:分布式可重入排它锁
- InterProcessSemaphoreMutex:分布式不可重入排它锁
- InterProcessReadWriteLock:分布式读写锁
- InterProcessMultiLock:将多个锁作为单个实体管理的容器,获取锁的时候获取所有锁,释放锁也会释放所有锁资源(忽略释放失败的锁)。
CuratorFramework client = ZKUtils.getClient();
client.start();
// 分布式可重入排它锁
InterProcessLock lock1 = new InterProcessMutex(client, lockPath1);
// 分布式不可重入排它锁
InterProcessLock lock2 = new InterProcessSemaphoreMutex(client, lockPath2);
// 将多个锁作为一个整体
InterProcessMultiLock lock = new InterProcessMultiLock(Arrays.asList(lock1, lock2));
if (!lock.acquire(10, TimeUnit.SECONDS)) {
throw new IllegalStateException("不能获取多锁");
}
System.out.println("已获取多锁");
System.out.println("是否有第一个锁: " + lock1.isAcquiredInThisProcess());
System.out.println("是否有第二个锁: " + lock2.isAcquiredInThisProcess());
try {
// 资源操作
resource.use();
} finally {
System.out.println("释放多个锁");
lock.release();
}
System.out.println("是否有第一个锁: " + lock1.isAcquiredInThisProcess());
System.out.println("是否有第二个锁: " + lock2.isAcquiredInThisProcess());
client.close();
分布式锁
package com.example.canal.zk;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public class DistributedLock {
private final String connectionString = "127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183";
private final int sessionTimeout = 2000;
private final ZooKeeper zk;
private CountDownLatch countDownLatch = new CountDownLatch(1);
private CountDownLatch waitLatch = new CountDownLatch(1);
private String waitPath;
private String currentMode;
public DistributedLock() throws IOException, InterruptedException, KeeperException {
// 获取连接
zk = new ZooKeeper(connectionString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
// connectLatch 如果连接上zk 可以释放
if (watchedEvent.getState() == Event.KeeperState.SyncConnected) {
countDownLatch.countDown();
}
// waitLatch 需要释放
if (watchedEvent.getType() == Event.EventType.NodeDeleted && watchedEvent.getPath().equals(waitPath)) {
waitLatch.countDown();
}
}
});
// 等待zk正常连接后,往下走程序
countDownLatch.await();
// 判断根节点/locks是否存在
Stat stat = zk.exists("/locks", false);
if (stat == null) {
// 创建根节点,这是⼀个完全开放的ACL,持久节点
zk.create("/locks", "locks".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
// 对zk加锁
public void zkLock() {
try {
// 创建对应的临时顺序节点
currentMode =
zk.create("/locks/" + "seq-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 判断创建的节点是否是序号最小的节点,如果是获取到锁,如果不是,监听他序号前一个节点
List<String> children = zk.getChildren("/locks", false);
if (children.size() == 1) {
return;
} else {
//[seq-0000000016, seq-0000000017]
Collections.sort(children);
// 获取节点名称 /locks/seq-0000000017 -> seq-0000000017
String thisNode = currentMode.substring("/locks/".length());
// 通过seq-0000000017获取该节点在children集合的位置
int index = children.indexOf(thisNode);
// 判断
if (index == -1) {
System.out.println("数据异常");
} else if (index == 0) {
// 就一个节点,可以获取锁了
return;
} else {
// 需要监听 他前一个结点的变化
waitPath = "/locks/" + children.get(index - 1);
zk.getData(waitPath, true, null);
// 等待监听
waitLatch.await();
}
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 解锁
public void unZkLock() {
// 删除节点
try {
zk.delete(currentMode, -1);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
}
测试类
package com.example.canal.zk;
import org.apache.zookeeper.KeeperException;
import java.io.IOException;
public class DistributedLockTest {
public static void main(String[] args) throws InterruptedException, IOException, KeeperException {
final DistributedLock lock1 = new DistributedLock();
final DistributedLock lock2 = new DistributedLock();
new Thread(new Runnable() {
@Override
public void run() {
try {
lock1.zkLock();
System.out.println("线程1 启动,获取到锁");
Thread.sleep(5 * 1000);
lock1.unZkLock();
System.out.println("线程1 释放锁");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
try {
lock2.zkLock();
System.out.println("线程2 启动,获取到锁");
Thread.sleep(5 * 1000);
lock2.unZkLock();
System.out.println("线程2 释放锁");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
curator 分布式锁
分布式执行一些不需要同时执行的复杂任务,curator利用zk的特质,实现了这个选举过程。其实就是利用了多个zk客户端在同一个位置建节点,只会有一个客户端建立成功这个特性。来实现同一时间,只会选择一个客户端执行任务。
核心代码
InterProcessMutex lock = new InterProcessMutex(client, lockPath);
if ( lock.acquire(maxWait, waitUnit) ) // 尝试在规定的时间内获取锁
{
try
{
// do some work inside of the critical section here
}
finally
{
lock.release(); // 释放锁
}
}
代码样例
package com.example.canal.zk;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class CuratorTest {
private final static String ZOOKEEPER_ADDRESS = "127.0.0.1:2181";
public static void main(String[] args) throws Exception {
// 重试策略,重试间隔时间为1秒,重试次数为10次。curator管理了zookeeper的连接,在操作zookeeper的过程中出现连接问题会自动重试。
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 10);
// 通过工厂创建连接
CuratorFramework cf = CuratorFrameworkFactory.builder().connectString(ZOOKEEPER_ADDRESS)
.connectionTimeoutMs(15000).retryPolicy(retryPolicy).sessionTimeoutMs(5000).build();
// 或者这样创建连接
// CuratorFramework cf = CuratorFrameworkFactory.newClient(ZOOKEEPER_ADDRESS,5000,15000,retryPolicy);
// 打开连接
cf.start();
System.out.println("=======================state:" + cf.getState());
String orderNo = "10001";
// 模拟数据库操作
DB db = new DB();
ExecutorService executorService = Executors.newFixedThreadPool(5);
// 这里有3个线程同时执行同一个订单号的操作
executorService.submit(new DistributedWorkerThread(cf, db, orderNo));
executorService.submit(new DistributedWorkerThread(cf, db, orderNo));
executorService.submit(new DistributedWorkerThread(cf, db, orderNo));
executorService.shutdown();
Thread.sleep(15000);
cf.close();
}
static class DB {
private List<String> orders = new ArrayList<>();
public void add(String order) {
if (!exist(order)) {
this.orders.add(order);
}
}
public boolean exist(String order) {
return this.orders.contains(order);
}
}
static class DistributedWorkerThread implements Runnable {
private CuratorFramework cf;
private String orderNo;
private DB db;
public DistributedWorkerThread(CuratorFramework cf, DB db, String orderNo) {
this.cf = cf;
this.db = db;
this.orderNo = orderNo;
}
public void run() {
String lockNode = "/lock/ms" + orderNo;
InterProcessMutex lock = new InterProcessMutex(cf, lockNode);
try {
if (lock.acquire(10, TimeUnit.SECONDS)) { // 这里也可以不指定时间,就是一直等直到获取到锁。
try {
if (db.exist(orderNo)) {
System.out.println(Thread.currentThread().getName() + "订单已存在!");
return;
}
System.out.println(Thread.currentThread().getName() + "在这里执行你的业务代码..orderNo:" + orderNo);
this.db.add(orderNo);
Thread.sleep(1500L);
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.release();
System.out.println(Thread.currentThread().getName() + "执行完毕!");
}
} else {
System.out.println(Thread.currentThread().getName() + "未获取到锁..");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
8.2、为什么要用临时顺序节点
每个数据节点在 ZooKeeper 中被称为 znode,它是 ZooKeeper 中数据的最小单元。
我们通常是将 znode 分为 4 大类:
- 持久(PERSISTENT)节点 :一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
- 临时(EPHEMERAL)节点 :临时节点的生命周期是与 客户端会话(session) 绑定的,会话消失则节点消失 。并且,临时节点只能做叶子节点 ,不能创建子节点。
- 持久顺序(PERSISTENT_SEQUENTIAL)节点 :除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 /node1/app0000000001 、/node1/app0000000002 。
- 临时顺序(EPHEMERAL_SEQUENTIAL)节点 :除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
可以看出,临时节点相比持久节点,最主要的是对会话失效的情况处理不一样,临时节点会话消失则对应的节点消失。这样的话,如果客户端发生异常导致没来得及释放锁也没关系,会话失效节点自动被删除,不会发生死锁的问题。
使用 Redis 实现分布式锁的时候,我们是通过过期时间来避免锁无法被释放导致死锁问题的,而 ZooKeeper 直接利用临时节点的特性即可。
假设不适用顺序节点的话,所有尝试获取锁的客户端都会对持有锁的子节点加监听器。当该锁被释放之后,势必会造成所有尝试获取锁的客户端来争夺锁,这样对性能不友好。使用顺序节点之后,只需要监听前一个节点就好了,对性能更友好。
8.3、为什么要设置对前一个节点的监听
Watcher(事件监听器),是 ZooKeeper 中的一个很重要的特性。ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper
实现分布式协调服务的重要特性。
同一时间段内,可能会有很多客户端同时获取锁,但只有一个可以获取成功。如果获取锁失败,则说明有其他的客户端已经成功获取锁。获取锁失败的客户端并不会不停地循环去尝试加锁,而是在前一个节点注册一个事件监听器。
这个事件监听器的作用是: 当前一个节点对应的客户端释放锁之后(也就是前一个节点被删除之后,监听的是删除事件),通知获取锁失败的客户端(唤醒等待的线程,Java 中的 wait/notifyAll ),让它尝试去获取锁,然后就成功获取锁了。
8.4、如何实现可重入锁
这里以 Curator 的 InterProcessMutex 对可重入锁的实现来介绍(源码地址:InterProcessMutex.java)。
当我们调用 InterProcessMutex#acquire方法获取锁的时候,会调用InterProcessMutex#internalLock方法。
// 获取可重入互斥锁,直到获取成功为止
@Override
public void acquire() throws Exception {
if (!internalLock(-1, null)) {
throw new IOException("Lost connection while trying to acquire lock: " + basePath);
}
}
internalLock 方法会先获取当前请求锁的线程,然后从 threadData( ConcurrentMap
第一次获取锁的时候,lockData为 null。获取锁成功之后,会将当前线程和对应的 lockData 放到 threadData 中
private boolean internalLock(long time, TimeUnit unit) throws Exception {
// 获取当前请求锁的线程
Thread currentThread = Thread.currentThread();
// 拿对应的 lockData
LockData lockData = threadData.get(currentThread);
// 第一次获取锁的话,lockData 为 null
if (lockData != null) {
// 当前线程获取过一次锁之后
// 因为当前线程的锁存在, lockCount 自增后返回,实现锁重入.
lockData.lockCount.incrementAndGet();
return true;
}
// 尝试获取锁
String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
if (lockPath != null) {
LockData newLockData = new LockData(currentThread, lockPath);
// 获取锁成功之后,将当前线程和对应的 lockData 放到 threadData 中
threadData.put(currentThread, newLockData);
return true;
}
return false;
}
LockData是 InterProcessMutex中的一个静态内部类。
private final ConcurrentMap<Thread, LockData> threadData = Maps.newConcurrentMap();
private static class LockData
{
// 当前持有锁的线程
final Thread owningThread;
// 锁对应的子节点
final String lockPath;
// 加锁的次数
final AtomicInteger lockCount = new AtomicInteger(1);
private LockData(Thread owningThread, String lockPath)
{
this.owningThread = owningThread;
this.lockPath = lockPath;
}
}
如果已经获取过一次锁,后面再来获取锁的话,直接就会在 if (lockData != null) 这里被拦下了,然后就会执行lockData.lockCount.incrementAndGet(); 将加锁次数加 1。整个可重入锁的实现逻辑非常简单,直接在客户端判断当前线程有没有获取锁,有的话直接将加锁次数加 1 就可以了。
9、ZooKeeper 可视化工具
http://www.redisant.cn/za