智能运维 | 你真的知道如何执行一条命令吗?

今天我们不聊上层建筑,不聊故障自愈,也不聊智能化运维的暗夜与黎明,今天我们聊一个很基础的话题:如何执行一条命令。许多人看到这个话题,可能觉得这是一个简单至极的问题。但是,事实果真如此吗?别急,下面我们来抽丝剥茧,一探究竟。
什么是命令
首先回顾一下“命令”的具体含义,发令以使之,谓发令而使其做某事,这是“命令”一词的基础释义。从这里我们可以看命令的三个最基本的要素:命令内容(令)、命令传递(发)、命令执行(使)。如果将这三要素限定在服务器上,它们又是如何运作的呢?

图1 Windows与Linux下的命令
1
何为命令内容(令)
无论是Windows还是Linux操作系统,都会提供相应的CLI(不要吐槽Windows的CLI难用),供使用者交互执行命令或运行批处理脚本。仔细观察,所有命令行都有一个相同的特点:固定词+选项+参数,无出其右。CLI伴随着操作系统的诞生,且命令行处理又是一个复杂但相似的过程,因此各种语言也都提供了相应的库支持,如C语言提供了getopt/getopt_long等函数,C++的Boost提供了Options库,Shell中处理此事的是getopts和getopt。
2
何为命令传递(发)
命令传递有两种方式,一种是文件形式,将Bat/Shell脚本上传到服务器然后执行。另外一种就是交互式,通过Telnet/SSH等方式远程连接服务器后,直接在命令行界面执行。虽然从形式上我们将命令传递分为了两种方式,但从本质上来说,服务器上的命令传递,都没有逃脱网络传输这个过程。
3
何为命令执行(使)
对于操作系统来说,命令的执行,其实就是启动一个进程并传递相应的参数,运行完成后得到相应的结果。这里我们并不关心进程如何创建,PBC的结构如何等细节,我们只关心命令进程的启动方式以及结果的获取方式。
为什么要执行命令
在产品的研发和维护过程中,有三个主题是无法绕过的,分别是配置管理、部署升级和监控采集。
1
配置管理
配置管理的目标是为了标识变更、控制变更、确保变更正确实现并向其他有关人员报告变更。从某种角度讲,配置管理是一种标识、组织和控制修改的技术。通常情况下,配置管理都会统一部署配置服务器来同步所有节点的配置。但是在开发测试过程中,总会出现临时修改某个或某一批节点的配置的情况,这时通过人工逐个登录来完成修改显然是不太可能的。
2
部署升级
DevOps的概念如今日趋流行,部署升级越发成为开发运维过程中重要的一环,频繁的交互意味着频繁的部署。部署过程可以拆解为两个小的步骤,一是新软件包的上传,二是服务进程的重新启动。服务进程的重新启动不必多说,软件包的上传可能有多种方式,如SFTP的集中式,P2P的点对点式等。
3
监控采集
在产品的运维过程需要时刻监控系统及业务软件的运行状态,各种运维决策都是以这些数据为依据进行的。随着自动化运维的发展,很多运维动作都从人工执行变为了自动执行,自动执行的决策过程更是需要采集大量的实时信息。监控数据的来源主要分两种,一种是通过业务软件提供的接口直接读取状态数据,另一种是通过日志/进程状态/系统状态等(如使用Grep提取日志,通过PS查询进程状态,通过DF查询磁盘使用等)方式间接查询。
无论是配置管理、部署变更还是监控采集,都有一个共同的目的:控制服务器。在现阶段,要想对服务器进行控制,离不开“在大量服务器上执行命令并收集结果”这一基础能力,这也是今天我们的主题“如何执行一条命令”的意义所在。
面临的困难
命令行的三要素,也是如何执行一条命令行面对的三个问题,如前文所述,对于单机环境来说,这三个问题在前人的努力下已经被很好的解决。可是如果要在几十万台服务器上每天执行几十亿条命令,同时保证时效性,保证执行成功率,保证结果正确收集,保证7*24小时稳定运行,就不是一件简单的事情了。所谓远行无轻担,量大易也难,在构建这样的执行系统的过程中要面临诸多困难,此处举几个突出的例子如下:
信息存储问题:为了支持水平扩展,需要高效的内存数据库作为缓存。为了做到执行命令的可追溯、可统计,需要对执行过的命令信息持久化。日均几十亿的热数据,年均上万亿的冷数据,需要仔细选择存储方案。
任务调度问题:为了达到在任意多台服务器上执行命令的要求,需要确定何时分发命令、何时回收结果以及怎么样的并发度批量下发。
消息传输问题:为了保证命令高效正确送达目标服务器,需要构建一个可靠的命令传输网络,使命令信息在准确送达的前提下保障传输的可靠与高效,毕竟百度的几十万台服务器分布在世界各地。
代理执行问题:为了更好的处理权限、单机并发等单机执行问题,需要在目标机构建执行代理,以应对单机的复杂执行环境。

图2 简单问题放大后也变得困难
百度目前拥有分布在世界各地的几十万台服务器,并且随着业务,尤其是云业务的不断扩张,这个数字还在持续增长,构建一个高效稳定通用可扩展的命令描述、传递、执行系统在这样的环境中有着重要的现实意义。对百度各产品线的用户来说,这样的一个系统,最基础的要求是:执行高效、控制灵活、扩展方便。
1. 执行高效:
单机执行,要求能够达到秒级命令下发/执行/结果收集。
集群执行,要求支持同时在数十万台服务器上并行执行,同时保证集群中每个服务器达到单机执行的性能。
2. 控制灵活:
单机控制,要求支持暂停、取消、重做功能。
集群控制,要求支持暂停点功能,也即可以在执行到某台服务器时暂停,等待人工检查确认无问题后可继续执行。
3. 扩展方便:
支持插件,要求支持自定义执行插件,用户可编写自己的插件执行相应操作。
支持回调,要求支持自定义用户回调,如任务执行失败调用相应回调接口。
除了以上的业务需求外,一个分布式系统的搭建,还要考虑可用性、可扩展性、性能、一致性等方面的硬性要求。
如何解决
为了解决这个简单的难题,我们设计了如图3所示的百度集群控制系统(Cluster Control System,简称CCS系统,由百度云智能运维团队打造的大规模远程命令执行系统),通过分离控制信息与执行信息建立了两级数据模型,结合命令执行及机房部署特点建立了四级传输模型,通过三级守护方式建立了稳定的执行代理,在大规模服务器集群上解决了“命令三要素”问题。
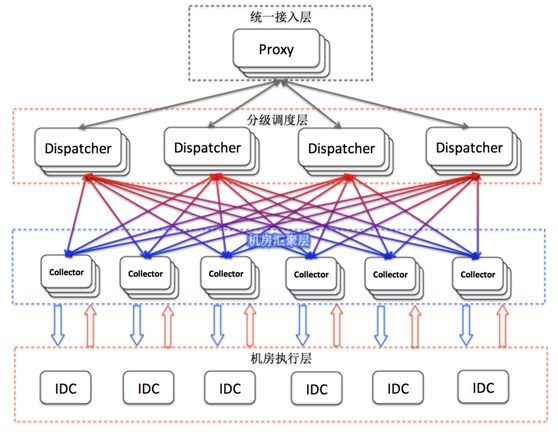
图3 百度集群控制系统架构
截至目前,CCS系统已经部署在全百度的所有机房中,用户可以方便的在任意一台服务器上进行秒级命令下发和结果收集,日均承载数亿次来自各产品的接口调用。关于数据模型、传输模型、执行代理这“分布式命令三要素”的设计及应用,我们将在下一篇文章中详细介绍。
关于作者
运小宇 百度云高级研发工程师
负责百度智能云运维基础组件相关开发工作,致力于运维基础设施的建设,夙兴夜寐,只为提高服务器操作的便利性,一桥飞架南北,天堑变通途。
![]()
更多相关文章
智能运维 | 百度自动化运维是怎么做的(上)——概念以及标准从何而来?
智能运维 | 百度自动化运维是怎么做的(下)——运维编年史
智能运维 | 为何说自动化运维三大要素是标准化、工程化和智能化?
智能运维 | 百度网络监控实战:NetRadar横空出世(上)
智能运维 | 百度网络监控实战:NetRadar横空出世(下)
智能运维 | 框架在手,AI我有
智能运维 | 干货分享,百度如何实现大规模分布式监控系统的高可用
智能运维 | 百亿级外网访问质量保障:百度猎鹰外网监控(上)
智能运维 | 百亿级外网访问质量保障:百度猎鹰外网监控(下)
智能运维 | 百度海量日志处理——任务调度实践与优化
智能运维 | 有了故障自愈机器人,运维小哥终于可以安心睡了
智能运维 | 使用故障自愈机器人?运维小哥先解决这些问题
智能运维 | 单机房故障自愈,收藏这一篇就够了
智能运维 | 六度亮剑SREcon,百度引领智能运维新风向