MySQL性能优化1-MySQL底层索引结构
❤️ 个人主页:程序员句号
支持水滴:点赞 + 收藏⭐ + 留言+关注
订阅专栏:MySQL性能调优
MySQL性能优化专栏
1.MySQL性能优化1-MySQL底层索引结构
2.MySQL2-Explain详解
3.MySQL3-索引最佳实战
4.MySQL4-MySQL内部组件结构
5.MySQL5-事务隔离级别和锁机制
6.MySQL6-深入理解MVCC和BufferPool缓存机制
文章目录
-
- 深入理解MySQL底层索引结构与算法
-
- 什么是索引?
- 索引数据结构的选择
- 为什么MySQL选择B+Tree,不选择B-Tree?
- 什么是聚集(聚簇)索引,什么是非聚集索引?
-
- InnoDB存储结构
- MyISAM存储结构
- 什么是主键索引和非主键索引?
- 什么是覆盖索引?
- 为什么建议InnoDB表必须建主键?并且推荐使用整型的自增主键?
- 为什么非主键索引结构叶子存储的是主键值?(InnoDB)
- 联合索引的底层数据结构是怎么样的?
-
- 最左前缀原理是什么?为什么有这个最左前缀?
深入理解MySQL底层索引结构与算法
什么是索引?
一句话解释:索引是帮助MySQL高效获取数据的排好序的数据结构。
我们都知道MySQL底层使用的是B+Tree树,那为什么要使用B+Tree树勒?有哪些数据结构可以使用?
索引数据结构的选择
不了解数据结构也没关系,记住就行,后面去理解下各种数据结构就好。
这四种我们都没有使用,为什么不使用?
-
二叉树
这是因为如果我们的主键是自增的,那么所形成的二叉树就跟链表一样了,链表的缺点大家都知道,插入快,查询慢。
-
红黑树
红黑树是对二叉树的一个升级,可以解决上面那个问题,但如果数据量巨大,那么它的高度是非常高的,那么也会导致查询慢。 -
Hash表
Hash表单纯来说,查找的时候都比B+Tree树快,因为只需要计算一次hash就可以找到数据。但它不支持范围查询之类的复杂查询,如果需要范围查找,那么就得全表扫描了。 -
B-Tree
这个结构解决红黑树的问题,但不完全解决,因为它是相当于开了一个多叉树,也就是一个节点可以存储多个节点,因为它设置了根节点的大小为16KB。但B-Tree结构是非叶子节点不会存储数据,所以高度对于B+Tree树还是比较高。
为什么MySQL选择B+Tree,不选择B-Tree?
主要因为两个原因:
- 同样的数据量B+Tree树的高度小于B-Tree的高度,因为B-Tree非叶子节点也会存储数据,而MySQL设置的一个高度数据大小是16KB。所以每个节点的数据大小越大,每个高度能存储的节点就越少,那么能存储的节点数量也就越少
- 加载到内存中,费内存
什么是聚集(聚簇)索引,什么是非聚集索引?
我们常用的InnoDB存储结构就是使用的聚集索引,而非聚集索引就是MyISAM。
聚集索引:叶子节点包含了完整的数据记录(也就是数据和索引没有分开)。
非聚集索引:MyISAM索引文件和数据就是分离的。
在window下安装mysql,然后建一个test表,找到mysql安装目录下的data目录,再找到对应的数据库目录,打开后可以看到下方的文件。
InnoDB存储结构
- frm:表结构
- .ibd:索引加数据

MyISAM存储结构
- 【frm后缀】:表结构
- .【MYD后缀】:数据
- 【MYI后缀】:索引文件

什么是主键索引和非主键索引?
主键索引:每张表都有主键,你设置的主键会默认生成一个索引,该索引就叫主键索引。
非主键索引:除主键索引外,设置的其他索引如单一索引,联合索引都是非主键索引。
两者区别:主键索引的叶子节点是存储的完整数据,而非主键索引叶子节点是存储的主键id,所以就有个回表操作。SQL命中了非主键索引,非主键索引还需要进行一次回表操作
什么是覆盖索引?
覆盖索引算不上真正的索引,它意思是查询的结构集在我们的索引中,就不需要进行回表操作。MySQL执行计划explain结果里的key有使用索引,如果select后面查询的字段都可以从这个索引的树中获取,这种情况一般可以说用到了覆盖索引,extra里一般都有using index;覆盖索引一般针对的是辅助索引,整个查询结构只通过辅助索引就能拿到结构,不需要通过辅助所以树找到主键,再通过主键去主键索引树里获取其他字段值。
为什么建议InnoDB表必须建主键?并且推荐使用整型的自增主键?
因为和Innodb的存储结构相关的,Innodb的索引和数据是在一起的,所以它肯定会由一列组成B+Tree,如果你没有建索引,首先MySQL会先从表里找一列全是数字不重复的列作为索引,如果没找到,会创建一个虚拟的索引rowId,所以这就是有啥建议有主键的原因。
第二个问题:为什么推荐使用整型的?
我们观察索引查找的过程,会发现每次都在做比较把,那什么样的数据比较最快勒,那肯定是整型咯,如果是uuid,还得转成Aisll码去一个一个的比较。
第三个问题:为什么推荐使用自增主键?
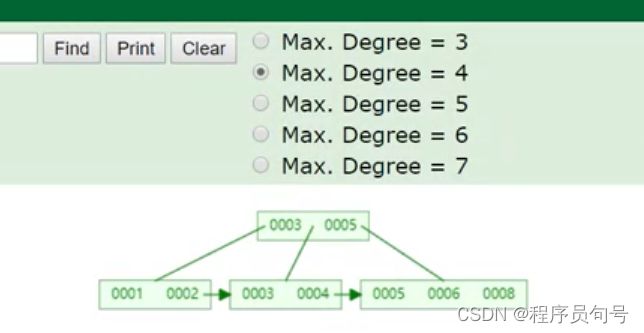
因为如果是有序的,那么就会减少B+Tree树的分裂和平衡。
如下图这时候插入7,可能会造成节点的分裂和平衡。因为我们知道叶子叶子的排列是排好序的,7在6和8之间,而刚好节点数量又达到了阈值,所以会分裂和平衡。
(这里是使用了数据结构可视化网址)
为什么非主键索引结构叶子存储的是主键值?(InnoDB)
因为一致性和节省存储空间,如果每开一个索引就要维护一份数据,那它浪费空间了。并且你做更新删除等操作时也需要同时删除几个索引下的数据。会产生回表操作(也就是查聚集索引的那个数据结构)
联合索引的底层数据结构是怎么样的?
分为联合主键和联合索引。
也是一颗B+Tree,但是它会排序,先比较name,再比较age,再比较position来决定先后顺序。
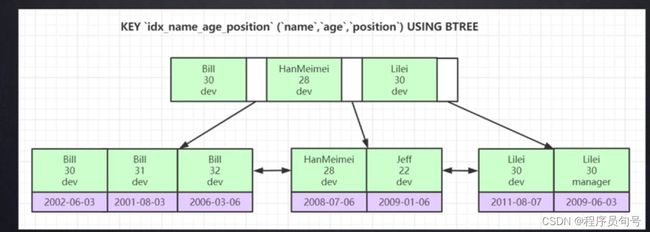
最左前缀原理是什么?为什么有这个最左前缀?
前提你创建了联合索引,你想要使用到索引,必须先使用最左边的那个字段,否则你是使用不了索引的。
EXPLAIN SELECT * FROM test_innodb WHERE name = 'Bill' and age = 31; 走索引
EXPLAIN SELECT * FROM test_innodb WHERE age = 30 AND position = 'dev'; 不走
EXPLAIN SELECT* FROM test_innodb WHERE position = 'manager'; 不走
EXPLAIN SELECT* FROM test_innodb WHERE name = 'Bill' and position = 'manager'; 走索引
EXPLAIN SELECT* FROM test_innodb WHERE name = 'Bill' and position < 'manager' and position > 'dev'; 走
EXPLAIN SELECT * FROM test_innodb WHERE age = 30 AND name = 'dev'; 走索引(因为Mysql的自动优化)
第二个问题:因为它的底层数据结构就是先根据字段前后去排序组成的二叉树,如果第一个没得,那么后面的字段你去查找会发现不是顺序的,那么你就只能去全表扫描了。
例如上图:如果不用name字段,那么age单独是没得顺序的,你根据age去查找肯定是得全表扫描的。想要age字段有序,之前的索引字段name必须是相等的