Java实现LL1语法分析器【编译原理】
java通过预测分析法实现语法分析程序【编译原理】
- 前言
- 推荐
-
- 实验要求
- 需知LL1工作原理
- Java实现LL1语法分析器0
-
- 实验步骤
- LL1.java
- Grammar.java
- LeftRecursion.java
- FirstAndFollow.java
- AnalyzeTable.java
- LL1Stack.java
- 实验结果
- Java实现LL1语法分析器1
-
- Grammar.java
- Production.java
- FirstAndFollow.java
- TestMain.java
- 最后
前言
2023-5-10 09:44:27
以下内容源自《【编译原理】》
仅供学习交流使用
推荐
Java实现LL1语法分析器
实验要求
一、预测分析法基本要求:
1) 任意输入一个文法G;
2) 处理文法中可能存在的左递归和公共左因子问题;
3) 对文法中的每个非终结符自动生成并打印输出:
① FIRST集; ② FOLLOW集;
4)判断处理后的文法是否为LL(1)文法,
如果是,自动生成并打印输出其预测分析表;
5) 模拟分析过程。
如输入一个句子,如果该句子合法则输出与句子对应的语法树;
能够输出分析过程中每一步符号栈的变化情况。
如果该句子非法则进行相应的报错处理。
测试文法:
① S →ABBA
A → a | ε
B → b | ε
② S → aSe | B
B → bBe | C
C → cCe | d
③ E →E+T | T
T →T*F | F
F →(E) | i
④ S →Qc | c
Q →Rb | b
R →Sa | a
E->E+T|T
T->T*F|F
F->(E)|i
i*i+i
S->ABBA
A ->a | ε
B ->b | ε
abba
需知LL1工作原理
4.3LL(1)分析法
首先,LL1文法的3个条件
- 没有左递归
- FIRST集不相交
- 含ε的FIRST集与其FOLLOW集不相交
需要的算法有:
- 算法:消除左递归
- 算法:预测分析程序工作过程
- 算法:构造FIRST与FOLLOW
- 算法:构造分析表M的算法
2023-5-20 15:16:06
Java实现LL1语法分析器0
2023-6-5 08:15:13
参考:Java实现LL1语法分析器
实验步骤
设计一个主类用来进行文件的输入,和结果的输出;然后按照四步走的策略来创建相对于的类操作。
第一步:创建LeftRecursion类来消除左递归,获取原始的产生式、终结符、非终结符;消除左递归之后的产生式、终结符和非终结符。然后简化产生式,每一个产生式只包含一个候选式。
第二步:创建FirstAndFollow类来求FIRST集和FOLLOW集。
第三步:创建AnalyzeTable类来获取分析表。
第四步:创建LL1Stack类来对测试用例进行入栈操作求解结果。
为了完成以上的任务,还需要创建一个Grammar类保存数据。以上就是设计的主要方案。
LL1.java
import java.io.File;
import java.io.FileNotFoundException;
import java.util.*;
/*
* 实验的主要方法:
* 1、消除左递归
* 1.1构造出终结符集、非终结符集
* 1.2把消除左递归得到的产生式进行简化,即一条产生式里面只有一个候选式
* 2、构造FIRST集和FOLLOW集
* 3、构造预测分析表
* 4、构造符号栈和输入串栈进行测试实例分析
* */
public class LL1 {
//原始的产生式
static ArrayList<String> expression;
//语法器
static Grammar grammar;
public static void main(String []args) throws FileNotFoundException {
grammar=new Grammar();
expression=new ArrayList<>();
//采用文件读入的方式
File file=new File("E:\\code\\bytest\\test11\\test4.txt");
try(Scanner input=new Scanner(file)) {
while (input.hasNextLine()){
String line=input.nextLine();
if (line.equals("")){//采用空一行这种方式,下一行就是测试用例
grammar.setTestEx(input.nextLine());
break;
}else {
expression.add(line);
}
}
}
//消除左递归
LeftRecursion leftRecursion=new LeftRecursion();
leftRecursion.setExpression(expression);
leftRecursion.work();
//分别给语法器开始设置非终结符集、终结符集、文法开始符号、简化之后的产生式
grammar.setNa(leftRecursion.getNa());
grammar.setNt(leftRecursion.getNt());
grammar.setStart(leftRecursion.getStart());
grammar.setSimpleExpression(leftRecursion.getSimpleExpression());
System.out.println();
System.out.println("--------------------------------------------------");
System.out.println("消除左递归");
System.out.println();
System.out.println("产生式");
for(Map.Entry<Character, ArrayList<String>> entry : grammar.getSimpleExpression().entrySet()){
for (String s:entry.getValue()){
System.out.println(entry.getKey()+"->"+s);
}
}
System.out.println("--------------------------------------------------");
System.out.println("非终结符");
for (Character na:grammar.getNa().keySet()){
System.out.printf("%-10c",na);
}
System.out.println();
System.out.println("--------------------------------------------------");
System.out.println("终结符");
for (Character nt:grammar.getNt().keySet()){
System.out.printf("%-10c",nt);
}
System.out.println();
System.out.println("--------------------------------------------------");
System.out.println("读取测试用例");
System.out.println(grammar.getTestEx());
//开始构造FIRST集和FOLLOW集
FirstAndFollow firstAndFollow=new FirstAndFollow(grammar);
firstAndFollow.work();
grammar.setFirst(firstAndFollow.getFirst());
grammar.setFollow(firstAndFollow.getFollow());
System.out.println("--------------------------------------------------");
System.out.println("FIRST集");
for (Character na:grammar.getNa().keySet()){
String FirstSet=grammar.getFirst().get(na).toString().replace("[","");
FirstSet=FirstSet.replace("]","");
System.out.println("FIRST("+na+")={"+FirstSet+"}");
}
System.out.println("--------------------------------------------------");
System.out.println("FOLLOW集");
for (Character na:grammar.getNa().keySet()){
String FollowSet=grammar.getFollow().get(na).toString().replace("[","");
FollowSet=FollowSet.replace("]","");
System.out.println("FOLLOW("+na+")={"+FollowSet+"}");
}
//构造预测分析表
AnalyzeTable analyzeTable=new AnalyzeTable(grammar);
analyzeTable.work();
grammar.setAnalyzeTable(analyzeTable.getAnalyzeTable());
System.out.println("--------------------------------------------------");
System.out.println("预测分析表");
System.out.printf("%-11s","");
for (Character nt:grammar.getNt().keySet()){
if (nt!='ε') {
System.out.printf("%-10s", nt);
}
}
System.out.println();
for (Character na:grammar.getNa().keySet()){
System.out.printf("%-10s",na);
for (int i=1;i<=grammar.getNt().size();i++){
if(grammar.getAnalyzeTable()[grammar.getNa().get(na)][i]!=null){
System.out.printf("%-10s",na+"->"+ grammar.getAnalyzeTable()[grammar.getNa().get(na)][i]);
}else{
System.out.printf("%-10s","");
}
}
System.out.println("");
}
System.out.println("--------------------------------------------------");
System.out.println("预测分析步骤");
System.out.println();
//利用LL1开始测试测试用例
LL1Stack stack=new LL1Stack(grammar);
stack.work();
}
}
Grammar.java
import java.util.*;
public class Grammar {
//非终结符
/*
* 这里解释一下为什么要采用Map,而不是采用Set,因为我觉得采用map方便生成预测分析表,可以利用键对应的值,找到产生式在
* 分析表中的位置。如 E->FA.要找到它在分析表中的位置,先要确定E在哪一行,直接判断FIRST(E)对应的符号所在哪一列,才可
* 以确定表达式的位置,这样也有利于最后的测试用例测试。
* */
private Map<Character,Integer> Na;
//终结符
private Map<Character,Integer> Nt;
//原始的产生式
private ArrayList<String> expression;
//简化之后的产生式
private Map<Character,ArrayList<String>> simpleExpression;
//开始符
private Character start;
//测试实例
private String testEx;
//分析表
private String[][] analyzeTable;
//first集
private Map<Character, HashSet<Character>> First;
//Follow集
private Map<Character, HashSet<Character>> Follow;
public Grammar() {
Na=new LinkedHashMap<>();
Nt=new LinkedHashMap<>();
simpleExpression=new LinkedHashMap<>();
Follow=new HashMap<>();
First=new HashMap<>();
}
public Map<Character, Integer> getNa() {
return Na;
}
public void setNa(Map<Character, Integer> na) {
Na = na;
}
public Map<Character, Integer> getNt() {
return Nt;
}
public void setNt(Map<Character, Integer> nt) {
Nt = nt;
}
public ArrayList<String> getExpression() {
return expression;
}
public void setExpression(ArrayList<String> expression) {
this.expression = expression;
}
public Map<Character, ArrayList<String>> getSimpleExpression() {
return simpleExpression;
}
public void setSimpleExpression(Map<Character, ArrayList<String>> simpleExpression) {
this.simpleExpression = simpleExpression;
}
public Character getStart() {
return start;
}
public void setStart(Character start) {
this.start = start;
}
public Map<Character, HashSet<Character>> getFirst() {
return First;
}
public void setFirst(Map<Character, HashSet<Character>> first) {
First = first;
}
public Map<Character, HashSet<Character>> getFollow() {
return Follow;
}
public void setFollow(Map<Character, HashSet<Character>> follow) {
Follow = follow;
}
public String getTestEx() {
return testEx;
}
public void setTestEx(String testEx) {
this.testEx = testEx;
}
public String[][] getAnalyzeTable() {
return analyzeTable;
}
public void setAnalyzeTable(String[][] analyzeTable) {
this.analyzeTable = analyzeTable;
}
}
LeftRecursion.java
import java.util.*;
public class LeftRecursion {
//非终结符
private Map<Character,Integer> Na;
//终结符
private Map<Character,Integer> Nt;
//原始的产生式
private ArrayList<String> expression;
//简化之后的产生式
private Map<Character,ArrayList<String>> simpleExpression;
//开始符
private Character start;
private int countNa;//非终结符的数量
private int countNt;//终结符的数量
public Map<Character, Integer> getNa() {
return Na;
}
public void setNa(Map<Character, Integer> na) {
Na = na;
}
public Map<Character, Integer> getNt() {
return Nt;
}
public void setNt(Map<Character, Integer> nt) {
Nt = nt;
}
public ArrayList<String> getExpression() {
return expression;
}
public void setExpression(ArrayList<String> expression) {
this.expression = expression;
}
public Map<Character, ArrayList<String>> getSimpleExpression() {
return simpleExpression;
}
public void setSimpleExpression(Map<Character, ArrayList<String>> simpleExpression) {
this.simpleExpression = simpleExpression;
}
public Character getStart() {
return start;
}
public void setStart(Character start) {
this.start = start;
}
public LeftRecursion(){
Na=new LinkedHashMap<>();
Nt=new LinkedHashMap<>();
simpleExpression=new LinkedHashMap<>();
};
public LeftRecursion(Map<Character, Integer> na, Map<Character, Integer> nt, ArrayList<String> expression, Character start) {
Na = na;
Nt = nt;
this.expression = expression;
this.start = start;
}
//初始化得到初始的终结符和非终结符
public void init(){
boolean hasKong=false;
countNa=1;
countNt=1;
start=expression.get(0).charAt(0);
for (String str:expression){
String []term=str.split("->");
if (!Na.containsKey(term[0].charAt(0))) {
Na.put(term[0].charAt(0), countNa);
countNa++;
}
}
//输出初始的非终结符
System.out.println("--------------------------------------------------");
System.out.println("非终结符");
for (Character na:Na.keySet()){
System.out.printf("%-10c",na);
}
System.out.println();
for (String str:expression){
String []term=str.split("->");
String []candidate=term[1].split("\\|");
for (String s:candidate){
for (int i=0;i<s.length();i++){
if (!Na.containsKey(s.charAt(i))&&!Nt.containsKey(s.charAt(i))){
if (s.charAt(i)!='ε') {
Nt.put(s.charAt(i), countNt);
countNt++;
}else{
hasKong=true;
}
}
}
}
}
if (!Nt.containsKey('#')) {
Nt.put('#', countNt++);
}
if (hasKong){
Nt.put('ε', countNt++);
}
//输出初始的终结符
System.out.println("--------------------------------------------------");
System.out.println("终结符");
for (Character nt:Nt.keySet()){
System.out.printf("%-10c",nt);
}
}
//输出原始的产生式
private void printOrigin(){
System.out.println("原始产生式");
for (String ex:expression){
Character na=ex.charAt(0);
String []parts=ex.split("->");
String []candidates=parts[1].split("\\|");
for (String s:candidates){
System.out.println(na+"->"+s);
}
}
}
/*
*完全消除左递归
*
* 如果文法G不含回路,也不含ε产生式,则下列算法可消除左递归(完全)
* 1、把G的非终结符按任意顺序排列成P1,…,Pn
* 2、for i:=1 to n do
* for j:=1 to i-1 do
* 把形如 Pi → P j γ 的规则改写成 P i → δ1 | ... | δk γ, 其中 P i → δ1 γ | ... | δk γ ;
* 消除关于Pi的直接左递归
* 3、化简由2得到的文法(取消无用非终结符产生式)
*
* */
private void allLeftTest(){
for (int i=0;i<expression.size();i++){
String []str=expression.get(i).split("->");
String []candidate=str[1].split("\\|");
String newExpression=str[1];
Character c=str[0].charAt(0);
ArrayList<String>notNeedChange=new ArrayList<>();
notNeedChange.addAll(Arrays.asList(candidate));
boolean hasLeft=false;
for (int j=0;j<=i-1;j++){
candidate=newExpression.split("\\|");
newExpression="";
for (int k=0;k<candidate.length;k++){
if (candidate[k].charAt(0)==expression.get(j).charAt(0)){
String []toReplace=expression.get(j).split("->");
if (expression.get(j).contains("|")){
candidate[k]=toReplace[1].replaceAll("\\|",candidate[k].substring(1)+"|")+candidate[k].substring(1);
}else {
candidate[k] = toReplace[1] + candidate[k].substring(1);
}
}
if (candidate[k].charAt(0)==c)
hasLeft = true;
newExpression+=candidate[k];
if (k!=candidate.length-1)
newExpression+="|";
}
candidate=newExpression.split("\\|");
}
if (i==0) {
for (int j = 0; j < candidate.length; j++) {
if (candidate[j].charAt(0) == c) {
hasLeft = true;
break;
}
}
}
if (hasLeft){
disLeft(i,c,candidate);
if (!Nt.containsKey('ε')) {
Nt.put('ε', countNt);
}
}else{
ArrayList<String> right=new ArrayList<>();
if (simpleExpression.get(c)!=null) {
right.addAll(simpleExpression.get(c));
}
right.addAll(notNeedChange);
simpleExpression.put(c,right);
}
}
}
private void disLeft(int index,Character c,String []test){
//出现左递归的话需要做出改变的候选式子,即带左递归的式子
ArrayList<String>needChange=new ArrayList<>();
//不带左递归的候选式
ArrayList<String>notNeedChange=new ArrayList<>();
//先找到一个合适的非终结符,来替代
char reCh = 'A';
for (int i='A'-'A';i<26;i++){
reCh= (char) ('A'+i);
if (!Na.containsKey(reCh)&&!Nt.containsKey(reCh)){
break;
}
}
//找到造成左递归的候选式
for (String s:test){
if (s.charAt(0)==c){
needChange.add(s);
}else{
notNeedChange.add(s);
}
}
//增加到非终结符集
Na.put(reCh,countNa++);
ArrayList<String> right=new ArrayList<>();
//获取原来已经简化的产生式
if (simpleExpression.get(c)!=null) {
right.addAll(simpleExpression.get(c));
}
//消除左递归
for (int i=0;i<notNeedChange.size();i++){
right.add(notNeedChange.get(i)+reCh);
}
simpleExpression.put(c,right);
//新的产生式
ArrayList<String> right2=new ArrayList<>();
for (String string:needChange){
string=string.substring(1)+reCh;
right2.add(string);
}
right2.add("ε");
simpleExpression.put(reCh,right2);
}
//直接消除左递归。这个方法不能完全消除左递归
public void testLeftRecur(){
for (String str:expression){
//判断有没有左递归
boolean hasLeft=false;
String []term=str.split("->");
String []candidate=term[1].split("\\|");
//出现左递归的话需要做出改变的候选式子,即带左递归的式子
ArrayList<String>needChange=new ArrayList<>();
//不带左递归的候选式
ArrayList<String>notNeedChange=new ArrayList<>();
//逐个查看候选式,以确定那些需要修改
for (String s:candidate){
//出现左递归吗
if (s.charAt(0)==term[0].charAt(0)) {
needChange.add(s);
hasLeft=true;
}
else
notNeedChange.add(s);
}
//出现左递归了
if (hasLeft){
//先找到一个合适的非终结符,来替代
char reCh = 'A';
for (int i=0;i<26;i++){
reCh= (char) ('A'+i);
if (!Na.containsKey(reCh)&&!Nt.containsKey(reCh)){
break;
}
}
//增加到非终结符集
Na.put(reCh,countNa++);
ArrayList<String> right=new ArrayList<>();
//获取原来已经简化的产生式
if (simpleExpression.get(term[0].charAt(0))!=null) {
right.addAll(simpleExpression.get(term[0].charAt(0)));
}
//消除左递归
for (String string:notNeedChange){
right.add(string+reCh);
}
simpleExpression.put(term[0].charAt(0),right);
ArrayList<String> right2=new ArrayList<>();
for (String string:needChange){
string=string.substring(1)+reCh;
right2.add(string);
}
right2.add("ε");
simpleExpression.put(reCh,right2);
Nt.put('ε',countNt);
}else {
ArrayList<String> right=new ArrayList<>();
if (simpleExpression.get(term[0].charAt(0))!=null) {
right.addAll(simpleExpression.get(term[0].charAt(0)));
}
right.addAll(notNeedChange);
simpleExpression.put(term[0].charAt(0),right);
}
}
}
public void work(){
printOrigin();
init();
allLeftTest();
// testLeftRecur();
}
}
FirstAndFollow.java
import java.util.*;
public class FirstAndFollow {
private Map<Character, HashSet<Character>> First;
private Map<Character, HashSet<Character>> Follow;
private Grammar grammar;
public FirstAndFollow(Grammar grammar) {
this.grammar = grammar;
First=new HashMap<>();
Follow=new HashMap<>();
}
public Map<Character, HashSet<Character>> getFirst() {
return First;
}
public void setFirst(Map<Character, HashSet<Character>> first) {
First = first;
}
public Map<Character, HashSet<Character>> getFollow() {
return Follow;
}
public void setFollow(Map<Character, HashSet<Character>> follow) {
Follow = follow;
}
public Grammar getGrammar() {
return grammar;
}
public void setGrammar(Grammar grammar) {
this.grammar = grammar;
}
//求FIRST集
private void getFirstSet(){
for (Character character:grammar.getNa().keySet()){
First.put(character, getNaFirstSet(character));
}
}
/*
* 具体方法:
* 1.若X ∈VT,则FIRST(X)={X}
* 2.若X∈VN,且有产生式X→a…,则把a加入到FIRST(X)中;若X→ɛ也是一条 产生式,则把 ɛ 也加到FIRST(X)中。
* 3.若X→Y…是一个产生式且Y∈VN,则把FIRST(Y)中的所有非ɛ元素都加到 FIRST(X)中;
* 若X → Y1Y2…YK 是一个产生式,Y1,Y2,…,Y(i-1)都是非终结符, 而且,对于任何j,1≤j ≤i-1, FIRST(Yj)都
* 含有ɛ (即Y1..Y(i-1)=>ɛ),则把 FIRST(Yj)中的所有非ɛ元素都加到FIRST(X)中;
* 特别是,若所有的FIRST(Yj , j=1,2,…,K)均含有ɛ,则把 ɛ 加到FRIST(X)中。
* */
private HashSet<Character> getNaFirstSet(Character character){
HashSet<Character> term=new HashSet<>();
for (String ex:grammar.getSimpleExpression().get(character)){
//第一个字符是终结符
if (grammar.getNt().containsKey(ex.charAt(0))){
term.add(ex.charAt(0));
}
//第一个字符是非终结符
else{
if (First.get(ex.charAt(0))!=null){
term.addAll(First.get(ex.charAt(0)));
}else {
term.addAll(getNaFirstSet(ex.charAt(0)));
}
}
}
return term;
}
//求FOLLOW集
private void getFollowSet(){
for (Character character:grammar.getNa().keySet()){
Follow.put(character, getNaFollowSet(character));
}
}
/*
* 1、对于文法的开始符号S,置#于FOLLOW(S) 中;
* 2、若A→α B β是一个产生式,则把FIRST(β)\{ɛ}加至FOLLOW(B)中;
* 3、若A→α B是一个产生式,或A→ αBβ是 一个产生式而β可以推导出ɛ (即 ɛ FIRST(β)), 则把FOLLOW(A)加至FOLLOW(B)中。
* */
private HashSet<Character> getNaFollowSet(Character c){
HashSet<Character> term=new HashSet<>();
if (c==grammar.getStart()){
term.add('#');
}
for (Map.Entry<Character, ArrayList<String>> entry : grammar.getSimpleExpression().entrySet()){
for (String s:entry.getValue()){
// System.out.println(entry.getKey()+"->"+s);
if (s.indexOf(c)!=-1){
if (s.indexOf(c)==s.length()-1){
if (entry.getKey()!=c) {
if (Follow.get(entry.getKey()) != null) {
term.addAll(Follow.get(entry.getKey()));
} else {
term.addAll(getNaFollowSet(entry.getKey()));
}
}
}else{
//所求非终结符后的第一个字符
Character last=s.charAt(s.indexOf(c)+1);
//如果是终结符
if (grammar.getNt().containsKey(last)){
term.add(last);
}
//如果是非终结符
else{
HashSet<Character> firstToAdd=new HashSet<>(First.get(last));
firstToAdd.remove('ε');
term.addAll(firstToAdd);
if (grammar.getSimpleExpression().get(entry.getKey()).contains("ε")&&entry.getKey()!=c){
if (Follow.get(entry.getKey())!=null){
term.addAll(Follow.get(entry.getKey()));
}
else {
term.addAll(getNaFollowSet(entry.getKey()));
}
}
}
}
}
}
}
return term;
}
public void work(){
getFirstSet();
getFollowSet();
}
}
AnalyzeTable.java
public class AnalyzeTable {
//分析表
private String[][] analyzeTable;
private Grammar grammar;
public AnalyzeTable(Grammar grammar) {
this.grammar=grammar;
analyzeTable=new String[grammar.getNa().size()+1][grammar.getNt().size()+1];
}
public String[][] getAnalyzeTable() {
return analyzeTable;
}
public void setAnalyzeTable(String[][] analyzeTable) {
this.analyzeTable = analyzeTable;
}
public Grammar getGrammar() {
return grammar;
}
public void setGrammar(Grammar grammar) {
this.grammar = grammar;
}
/*
*预测分析表的构造方法
* 1、对文法G的每个产生式A→α执行第2步 和第3步;
* 2、对每个终结符a∈FIRST(α),把A→α加至M[A,a]中,
* 3、若ɛ∈FIRST(α),则对任何b∈FOLLOW(A) , 把A→α加至M[A,b]中,
* 4、把所有无定义的M[A,a]标上“出错标志”。
* */
private void genTable(){
for (Character Na:grammar.getNa().keySet()){
int row=grammar.getNa().get(Na);
for (Character Nt:grammar.getFirst().get(Na)){
//第3步的情况
if (Nt=='ε'){
for (Character follow:grammar.getFollow().get(Na)){
analyzeTable[row][grammar.getNt().get(follow)]="ε";
}
}else {
//执行第1步
for (String s:grammar.getSimpleExpression().get(Na)) {
//这里还需要进一步判断是因为一个非终结符有可能对应多个产生式,我们需要寻找出遇到这个终结符时对应的产生式
//如果这个产生式的第一个符号是终结符且等于当前遇到的终结符
if (grammar.getNt().containsKey(s.charAt(0))){
if (Nt==s.charAt(0)){
analyzeTable[row][grammar.getNt().get(Nt)]=s;
break;
}
}else{
if (grammar.getFirst().get(s.charAt(0)).contains(Nt)){
analyzeTable[row][grammar.getNt().get(Nt)]=s;
break;
}
}
}
}
}
}
}
public void work(){
genTable();
}
}
LL1Stack.java
import java.util.Stack;
public class LL1Stack {
private Grammar grammar;
//这个是符号栈
private Stack<Character> analyzeStack;
//这个是输入串栈
private Stack<Character> remain;
public LL1Stack(Grammar grammar) {
this.grammar = grammar;
analyzeStack=new Stack<>();
remain=new Stack<>();
remain.push('#');
//将输入串反向压栈
for (int i=grammar.getTestEx().length()-1;i>=0;i--){
remain.push(grammar.getTestEx().charAt(i));
}
analyzeStack.push('#');
analyzeStack.push(grammar.getStart());
}
public Grammar getGrammar() {
return grammar;
}
public void setGrammar(Grammar grammar) {
this.grammar = grammar;
}
public Stack<Character> getAnalyzeStack() {
return analyzeStack;
}
public void setAnalyzeStack(Stack<Character> analyzeStack) {
this.analyzeStack = analyzeStack;
}
public Stack<Character> getRemain() {
return remain;
}
public void setRemain(Stack<Character> remain) {
this.remain = remain;
}
/*
* LL1分析器工作步骤:
* 1、如果X=a='#,分析成功退出
* 2、如果X=a!='#,X推出,a指向写一个输入符号
* 3、X为非终结符,查找分析表。M[x,a]是候选式反序压栈;M[x,a]=空串,弹栈什么都不压;M[x,a]为空白,出错
* 4、然后x!=a,出错
* */
private void analyze(){
System.out.printf("%-21s%-24s%-20s%-20s\n","步骤","符号栈","输入串","所用产生式");
System.out.printf("%-25d%-25s%-25s%-25s\n",0,printStack(analyzeStack.toString()),new StringBuilder(printStack(remain.toString())).reverse().toString(),"");
int step=1;
while (!remain.empty()){
if (analyzeStack.peek()==remain.peek()&&remain.peek()=='#'){
System.out.printf("%-25d%-25s%-25s%-25s\n",step,printStack(analyzeStack.toString()),new StringBuilder(printStack(remain.toString())).reverse().toString(),"分析成功,输入合法");
break;
}
else if (analyzeStack.peek()==remain.peek()&&remain.peek()!='#'){
analyzeStack.pop();
remain.pop();
System.out.printf("%-25d%-25s%-25s%-25s\n",step,printStack(analyzeStack.toString()),new StringBuilder(printStack(remain.toString())).reverse().toString(),"");
step++;
}
else if (grammar.getNa().containsKey(analyzeStack.peek())){
if (grammar.getAnalyzeTable()[grammar.getNa().get(analyzeStack.peek())][grammar.getNt().get(remain.peek())]==null){
System.out.printf("%-25d%-25s%-25s%-25s\n",step,printStack(analyzeStack.toString()),new StringBuilder(printStack(remain.toString())).reverse().toString(),"这里出错了,不存在M["+analyzeStack.peek()+","+remain.peek()+"]");
break;
}
else if (grammar.getAnalyzeTable()[grammar.getNa().get(analyzeStack.peek())][grammar.getNt().get(remain.peek())].equals("ε")){
Character na=analyzeStack.pop();
System.out.printf("%-25d%-25s%-25s%-25s\n",step,printStack(analyzeStack.toString()),new StringBuilder(printStack(remain.toString())).reverse().toString(),na+"->"+"ε");
step++;
}else {
String ex=grammar.getAnalyzeTable()[grammar.getNa().get(analyzeStack.peek())][grammar.getNt().get(remain.peek())];
Character na=analyzeStack.pop();
for (int i=ex.length()-1;i>=0;i--){
analyzeStack.push(ex.charAt(i));
}
System.out.printf("%-25d%-25s%-25s%-25s\n",step,printStack(analyzeStack.toString()),new StringBuilder(printStack(remain.toString())).reverse().toString(),na+"->"+ex);
step++;
}
}else{
System.out.printf("%-25d%-25s%-25s%-25s\n",step,printStack(analyzeStack.toString()),new StringBuilder(printStack(remain.toString())).reverse().toString(),"这里出错了,"+analyzeStack.peek()+"!="+remain.peek());
break;
}
}
}
//不会正则表达式的蒟蒻只能这样子写了
private String printStack(String s){
s=s.replace(", ","");
s=s.replace("[","");
s=s.replace("]","");
return s;
}
public void work(){
analyze();
}
}
实验结果
1、输入数据:
E->E+T|T
T->T*F|F
F->(E)|i
i*i+i
输出结果:i*i+i是合法的



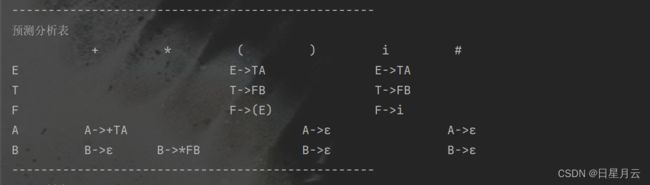
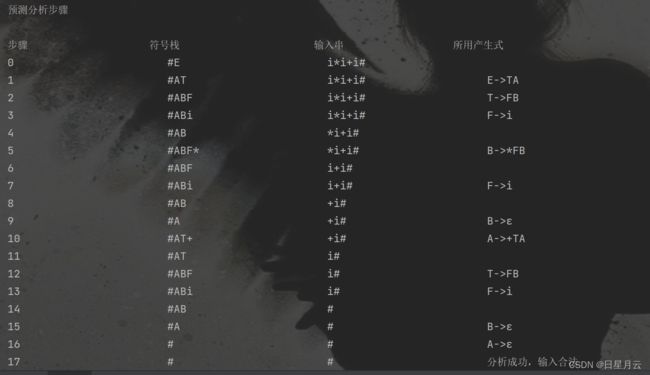
Java实现LL1语法分析器1
以下是自己写的代码
Grammar.java
package s2;
import java.util.ArrayList;
import java.util.HashSet;
/**
*
* 文法为四元组
* S:开始符号
* Vt:终结符号集
* Vn:非终结符号集
* Ps:产生式集合
* 扩充的巴科斯范式->转为巴科斯范式
*/
public class Grammar {
String S;//开始符号
HashSet<String> Vt;//终结符号集
HashSet<String> Vn;//非终结符号集
ArrayList<Production> PS=new ArrayList<>();//产生式集合
public Grammar() {
// this.PS.add(new Production("S0","#S#"));
}
public Grammar(ArrayList<Production> PS) {
this();
this.PS.addAll(PS);
}
public Grammar(String s, HashSet<String> vt, HashSet<String> vn, ArrayList<Production> PS) {
this(PS);
S = s;
Vt = vt;
Vn = vn;
}
/**
* 通过输入构造文法
* 默认第一个条件式的左部为开始符号
* 右部必须是一个符号一个结点
* @param text 输入
* @return 文法
*/
public static Grammar createGrammar(String text){
ArrayList<Production> ps = getPs(text);
Production production = ps.get(0);
String S= production.left;
HashSet<String> Vt=new HashSet<>();
HashSet<String> Vn=new HashSet<>();
for (Production p:ps){
String left=p.left;
Vn.add(left);
}
for (Production p:ps){
String right=p.right;
for (String s : right.split("")) {
if (!Vn.contains(s)&&!s.equals("|")){
Vt.add(s);
}
}
}
return new Grammar(S,Vt,Vn,ps);
}
/**
* 通过输入得到产生式集合
* @param text 输入
* @return 产生式集合
*/
public static ArrayList<Production> getPs(String text){
ArrayList<Production> PS=new ArrayList<>();
String textStr[] = text.split("\\r\\n|\\n|\\r");
for (String pStr:textStr){
String[] split = pStr.split(Production.DEFINE);
Production p=new Production(split[0],split[1]);
PS.add(p);
}
return PS;
}
/**
* 扩充的巴科斯范式->转为巴科斯范式
*/
public static Grammar transfer(Grammar g){
ArrayList<Production> ps=new ArrayList<>();
for (Production p:g.PS){
String left=p.left;
String right=p.right;
String[] split = right.split("\\"+Production.OR);
for (String r:split){
Production pNew=new Production(left,r);
ps.add(pNew);
}
}
return new Grammar(g.S,g.Vt,g.Vn,ps);
}
/**
* 打印文法
* @param g 文法
*/
public static void printGrammar(Grammar g){
System.out.println("Grammar{");
System.out.println("\t"+"S='"+g.S+"'");
System.out.println("\t"+"Vt="+g.Vt);
System.out.println("\t"+"Vn="+g.Vn);
System.out.println("\t"+"PS=[");
for (Production p:g.PS){
System.out.println("\t\t"+p);
}
System.out.println("\t]");
System.out.println("}");
}
}
Production.java
package s2;
/**
* 产生式
*
* left:左部
* right:右部
*/
public class Production {
//左部
String left;
//右部
String right;
//元语言符号
static final String DEFINE ="→";//定义为
static final String OR ="|";//或
static final String NULL="ε";//空
public Production() {
}
public Production(String left, String right) {
this.left = left;
this.right = right;
}
@Override
public String toString() {
return left + DEFINE + right;
}
public static void main(String[] args) {
Production p=new Production("S","a");
System.out.println(p);
}
}
FirstAndFollow.java
package s2;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import static s2.Production.NULL;
public class FirstAndFollow {
Map<String, HashSet<String>> First;
Map<String, HashSet<String>> Follow;
Grammar grammar;
public FirstAndFollow() {
First = new HashMap<>();
Follow = new HashMap<>();
}
public FirstAndFollow(Grammar grammar) {
this();
this.grammar = grammar;
}
//求first集
public void getFirstSet() {
for (String vn : grammar.Vn) {
First.put(vn, getVnFirstSet(vn));
}
}
/*
* 具体方法:
* 1.若X ∈VT,则FIRST(X)={X}
* 2.若X∈VN,且有产生式X→a…,则把a加入到FIRST(X)中;若X→ɛ也是一条 产生式,则把 ɛ 也加到FIRST(X)中。
* 3.若X→Y…是一个产生式且Y∈VN,则把FIRST(Y)中的所有非ɛ元素都加到 FIRST(X)中;
* 若X → Y1Y2…YK 是一个产生式,Y1,Y2,…,Y(i-1)都是非终结符, 而且,对于任何j,1≤j ≤i-1, FIRST(Yj)都
* 含有ɛ (即Y1..Y(i-1)=>ɛ),则把 FIRST(Yj)中的所有非ɛ元素都加到FIRST(X)中;
* 特别是,若所有的FIRST(Yj , j=1,2,…,K)均含有ɛ,则把 ɛ 加到FRIST(X)中。
*/
public HashSet<String> getVnFirstSet(String vn) {
HashSet<String> term = new HashSet<>();
for (Production p : grammar.PS) {
if (p.left.equals(vn)) {
//得到右部第一个符号
String[] split = p.right.split("");
String f = split[0];
//第一个字符是终结符
if (grammar.Vt.contains(f)) {
term.add(f);
}
//第一个字符是非终结符
else if (grammar.Vn.contains(f)) {
HashSet<String> set = First.get(f);
if (set == null) {
set = getVnFirstSet(f);
}
HashSet<String> copy = new HashSet<>(set);
if (!copy.contains(NULL)) {
term.addAll(copy);
} else {
copy.remove(NULL);
term.addAll(copy);
int all = 0;
for (int i = 1; i < split.length; i++) {
String h = split[i];
HashSet<String> s = First.get(h);
if (s == null) {
s = getVnFirstSet(h);
}
HashSet<String> c = new HashSet<>(s);
if (!c.contains(NULL)) {
term.addAll(c);
all++;
} else {
c.remove(NULL);
term.addAll(c);
}
}
if (all == 0) {
term.add(NULL);
}
}
}
}
}
return term;
}
//求Follow集
public void getFollowSet() {
for (String vn : grammar.Vn) {
Follow.put(vn, getVnFollowSet(vn));
}
}
/*
* 1、对于文法的开始符号S,置#于FOLLOW(S) 中;
* 2、若A→α B β是一个产生式,则把FIRST(β)\{ɛ}加至FOLLOW(B)中;
* 3、若A→α B是一个产生式,或A→ αBβ是 一个产生式而β可以推导出ɛ (即 ɛ FIRST(β)), 则把FOLLOW(A)加至FOLLOW(B)中。
*/
private HashSet<String> getVnFollowSet(String vn) {
HashSet<String> term = new HashSet<>();
if (vn.equals(grammar.S)) {
term.add("#");
}
for (Production p : grammar.PS) {
String[] split = p.right.split("");
for (int i = 0; i < split.length; i++) {
if (split[i].equals(vn)) {
if (i + 1 < split.length) {
String b = split[i + 1];
HashSet<String> set = new HashSet<>(First.get(b));
if (set.contains(NULL)) {
HashSet<String> lf = Follow.get(p.left);
if (lf == null) {
lf = getVnFollowSet(p.left);
}
term.addAll(lf);
}
HashSet<String> copy = new HashSet<>(set);
copy.remove(NULL);
term.addAll(copy);
} else {
HashSet<String> lf = Follow.get(p.left);
if (lf == null) {
lf = getVnFollowSet(p.left);
}
term.addAll(lf);
}
}
}
}
return term;
}
}
TestMain.java
package s2;
import org.junit.Test;
import java.util.ArrayList;
import java.util.HashSet;
import static s2.Grammar.*;
public class TestMain {
@Test
public void testPrint() {
HashSet<String> Vt=new HashSet<>();
Vt.add("a");
Vt.add("b");
Vt.add("ε");
HashSet<String> Vn=new HashSet<>();
Vn.add("S");
Vn.add("A");
Vn.add("B");
ArrayList<Production> Ps=new ArrayList<>();
Ps.add(new Production("S","ABBA"));
Ps.add(new Production("A","a|ε"));
Ps.add(new Production("B","b|ε"));
Grammar grammar=new Grammar("S",Vt,Vn,Ps);
printGrammar(grammar);
/*
Grammar{
S='S'
Vt=[a, b, ε]
Vn=[A, B, S]
PS=[
S→ABBA
A→a|ε
B→b|ε
]
}
*/
}
@Test
public void testGetPs(){
String text="S→ABBA\n"
+"A→a|ε\n"
+"B→b|ε";
ArrayList<Production> ps = getPs(text);
System.out.println(ps);
//[S→ABBA, A→a|ε, B→b|ε]
}
@Test
public void testCreate(){
String text="S→ABBA\n"
+"A→a|ε\n"
+"B→b|ε";
Grammar grammar = createGrammar(text);
printGrammar(grammar);
/*
Grammar{
S='S'
Vt=[a, b, ε]
Vn=[A, B, S]
PS=[
S→ABBA
A→a|ε
B→b|ε
]
}
*/
}
@Test
public void testTransfer(){
String text="S→ABBA\n"
+"A→a|ε\n"
+"B→b|ε";
Grammar grammar = createGrammar(text);
printGrammar(grammar);
Grammar transfer = transfer(grammar);
printGrammar(transfer);
/*
Grammar{
S='S'
Vt=[a, b, ε]
Vn=[A, B, S]
PS=[
S→ABBA
A→a
A→ε
B→b
B→ε
]
}
*/
}
@Test
public void testGetFirst(){
String text="S→ABBA\n"
+"A→a|ε\n"
+"B→b|ε";
Grammar grammar = createGrammar(text);
Grammar transfer = transfer(grammar);
printGrammar(transfer);
FirstAndFollow faf=new FirstAndFollow(transfer);
faf.getFirstSet();
System.out.println(faf.First);
}
@Test
public void testGetFollow(){
String text="S→ABBA\n"
+"A→a|ε\n"
+"B→b|ε";
Grammar grammar = createGrammar(text);
Grammar transfer = transfer(grammar);
printGrammar(transfer);
FirstAndFollow faf=new FirstAndFollow(transfer);
faf.getFirstSet();
faf.getFollowSet();
System.out.println(faf.Follow);
}
}
最后
2023-6-5 08:03:04
你对我百般注视,
并不能构成万分之一的我,
却是一览无余的你。
祝大家逢考必过
点赞收藏关注哦