数据库的基本操作
文章目录
- 补充知识:
- 一:对数据库的操作:
-
-
-
- **显示当前的所有数据库**
- 创建数据库,并指定字符集
- 选中数据库与删除数据库操作
-
-
- 二:数值类型
- 三:字符串类型
- 四:日期类型
- 五:表的操作
-
-
-
- 查看表结构
- 创建表
- 删除表
-
-
- 六:记录的操作
-
- 6.1:记录的新增
-
-
- 单行数据 + 全列插入
- 多行数据 + 指定列插入
-
- 6.2:记录的查询
-
-
- 全列查询
- 指定列查询
- 查询字段为表达式
- 别名
- 去重:DISTINCT
- 排序:ORDER BY
- 条件查询:WHERE
-
-
- 比较运算符
- 逻辑运算符
-
- 分页查询:LIMIT
-
- 6.3:记录的修改 Update
-
- matched 与 changed 的区别
- 6.4:记录的删除
-
- delete 与 drop 的区别:
补充知识:
- 客户端是与用户进行交互的部分,服务器是存储数据的本体(存储在硬盘上的),客户端(client)给服务器(server)发送的信号叫请求(request),服务器给客户端响应(response),客户端与服务器之间通过网络来通信
- 内存读写速度是外存的三到四个数量级(几千倍)
- 数据库以表的形式表示,表中的每一条称为记录,记录中的每一列称为字段
- 数据库中的关键字不区分大小写
- ctrl + c 在sql中不是复制,而是终止当前的执行或输入的内容
- 在控制台里复制是:回车,粘贴是:鼠标右键
组织方式 数据集合:
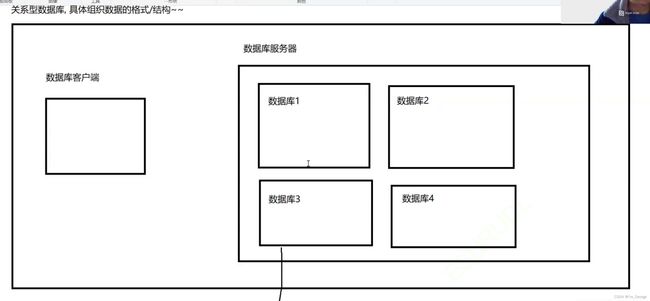
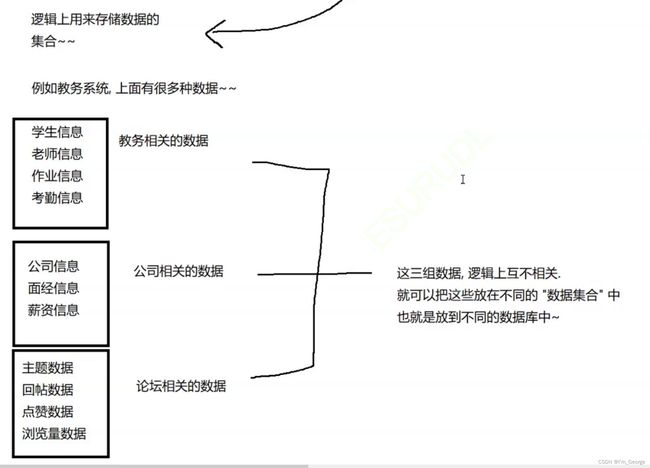
一:对数据库的操作:
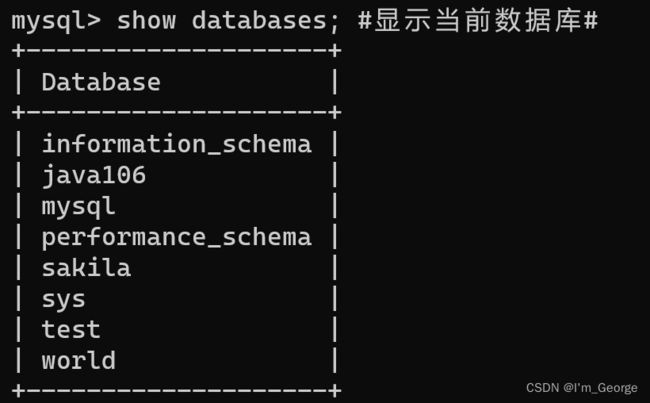
显示当前的所有数据库
创建数据库,并指定字符集
![]()
说明:MySQL的utf8编码不是真正的utf8,没有包含某些复杂的中文字符。MySQL真正的utf8是使用utf8mb4,建议大家都使用utf8mb4
之所以用if not exists 是因为SQL很多时候写到一个文件中,批量执行,如果执行过程中某个操作报错后。后续语句就不执行了
注意1:
utf8字符集中一个汉字占3个字节,不同的字符集编码方式不同,
所占的空间也就不同,Unicode一个汉字是2个字节

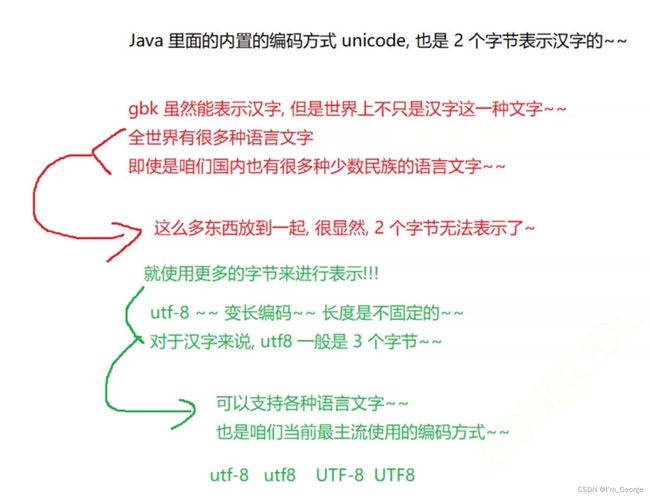

注意二:
mysql提供了配置文件,可以根据配置文件(my.ini)来搭配实现自己想要的功能,但是要注意的是,修改配置文件的时候先拷贝一份,以防万一。而且不是修改完就可以直接生效,你要重启服务器,重新加载配置文件之后,只是针对新的数据库有影响,已有数据库不会变化,仍然要重新建库
数据库创建好了,已经有很多数据了,再修改字符集那是灾难性的。
选中数据库与删除数据库操作

二:数值类型
| 数据类型 | 大小 | 对应Java的类型 |
|---|---|---|
| bit | 1 | 常用Boolean对应bit,只能存0 1 |
| tinyint | 1字节 | byte |
| smallint | 2字节 | short |
| int | 4字节 | int |
| bigint | 8字节 | long |
| float | 4 | float |
| double | 8 | double |
| decimal(M,D) | max(M,D) + 2 | 其中M:有效字数,D:小数点后几位bigdecimal |
| numeric(M,D) | max(M,D) + 2 | BigDecimal |
注意:
数值类型可以指定为无符号(unsigned),表示不取负数。
1字节(bytes)= 8bit。对于整型类型的范围:
有符号范围:-2(类型字节数*8-1)到2(类型字节数*8-1)-1,如int是4字节,就是-231到231-1,因为最前面的是符号位,后面的31位是数值位,正数:231-1个,零:1个,负数:231个
无符号范围:0到2(类型字节数*8)-1,如int就是232-1
尽量不使用unsigned,对于int类型可能存放不下的数据,int unsigned同样可能存放不下,与其
如此,还不如设计时,将int类型提升为bigint类型。注意:double, float存储精度不高(IEE754标准),但是decimal 牺牲了空间与速度来换更精确的表示方式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IxYGCIZB-1670499358199)(D:/%E4%BD%A0%E5%A5%BDJava/644.png)]
decimal(3,1):三位有效数字,保留小数点后以一位。相如100.0这样是不在他范围的。
sql对于类型的检查不是很严格,是弱类型的,涉及很多类型的转化
三:字符串类型
常用的是varchar(size) 可变长字符串
| 数据类型 | 大小 | 说明 | 对应java类型 |
|---|---|---|---|
| varchar | 0-65,535字节 | 可变长度字符串 | String |
| TEXT | 0-65,535字节 | 长文本数据 | String |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 | String |
| BLOB | 0-65,535字节 | 二进制形式的长文本数据 | byte[] |
varchar(128) :指的是这列最多存128个字符,而不是128个字节,一个字符占多大的字节取决于你采用那个字符集,而且这里不是你写了128就固定分配128个字符,也会动态分配的,但是不会超过128
四:日期类型
datatime 占8个字节,【1000年,9999年】
timestamp 占4个字节 【1970年,2038年】
补充:伪随机

五:表的操作
查看表结构
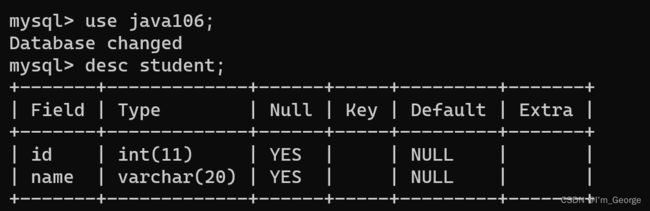
注意:
select * from 表名 //查看表中的所有数据 desc 表名 //查看表的列是啥,类型是啥
创建表

可以使用comment增加字段说明。
comment 只能在创建表的时候使用,更推荐用–来写注释
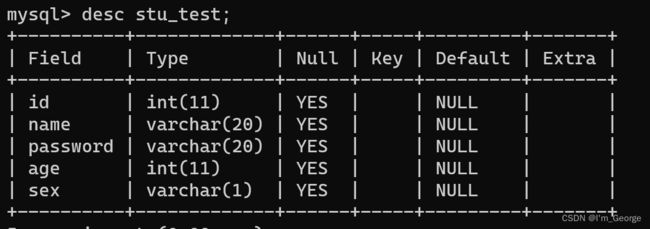
删除表

六:记录的操作
6.1:记录的新增
SQL中可以使用“–空格+描述”来表示注释说明
单行数据 + 全列插入
-- 插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
INSERT INTO student VALUES (100, 10000, '唐三藏', NULL);
INSERT INTO student VALUES (101, 10001, '孙悟空', '11111');
多行数据 + 指定列插入
-- 插入两条记录,value_list 数量必须和指定列数量及顺序一致
INSERT INTO student (id, sn, name) VALUES
(102, 20001, '曹孟德'),
(103, 20002, '孙仲谋');

一次写十条比一次写一条快的,但是起始也快不上多少
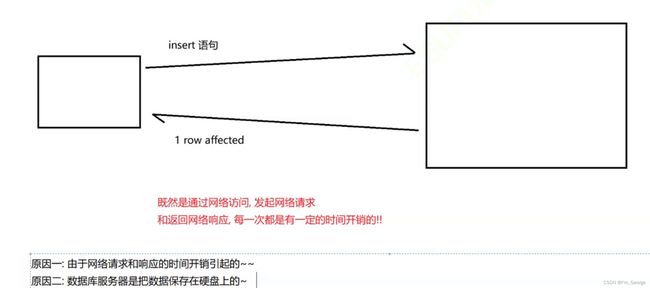
原因1:由于网络请求和响应的时间开销引起的,
原因2:数据库服务器是把数据保存在硬盘上的,
原因三:mysql关系型数据库每进行一次sql操作,内部就要开启一个事务,每次事务的开启都有开销,
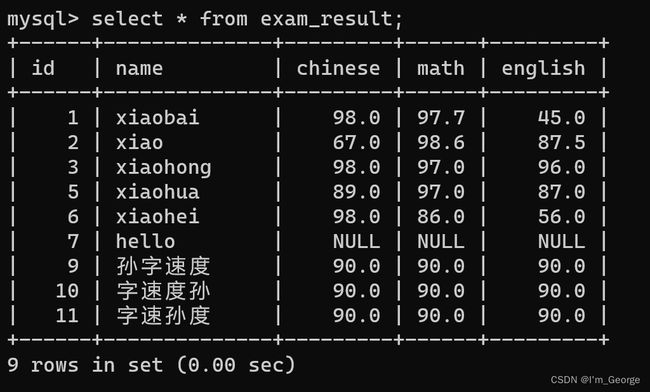
6.2:记录的查询
select只是查询无论如何都不会修改硬盘上的数据
![]()
注意格式:
insert into 表名 (指定列)values()()()();
全列查询
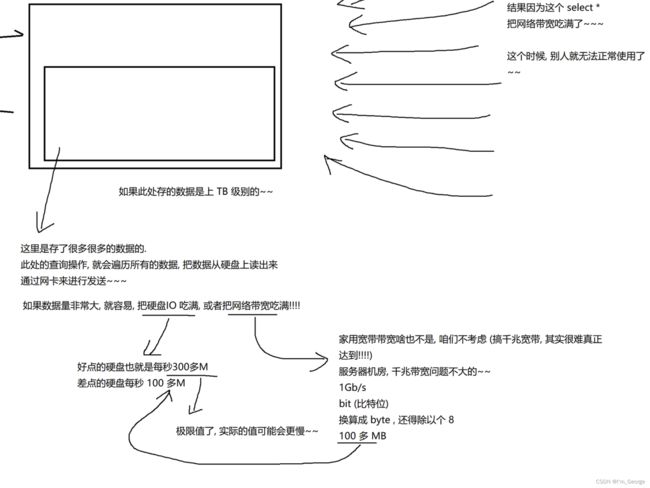
- 通常情况下不建议使用 * 进行全列查询
-- 1. 查询的列越多,意味着需要传输的数据量越大;
-- 2. 可能会影响到索引的使用。(索引待后面课程讲解)
SELECT * FROM exam_result;
注意:
select * from student 工作时一般不要使用,因为会把硬盘的IO资源以及网络的带宽给吃满。
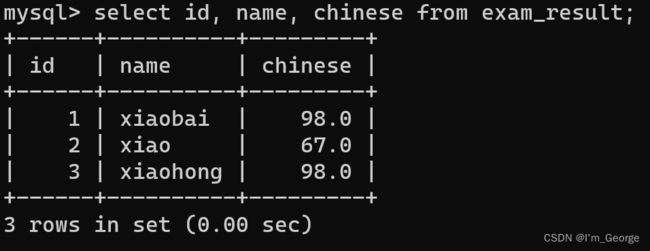
指定列查询
-- 指定列的顺序不需要按定义表的顺序来
SELECT id, name, english FROM exam_result;
//别忘了逗号
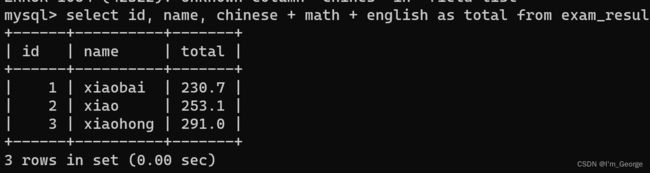
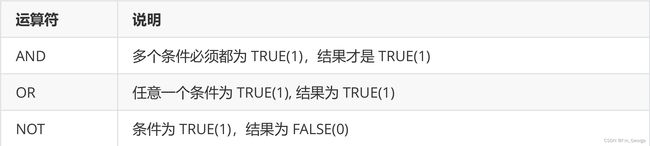
查询字段为表达式
-- 表达式包含多个字段
SELECT id, name, chinese + math + english FROM exam_result;
表达式只能进行一行上的计算,不能进行行与行之间的计算
别名
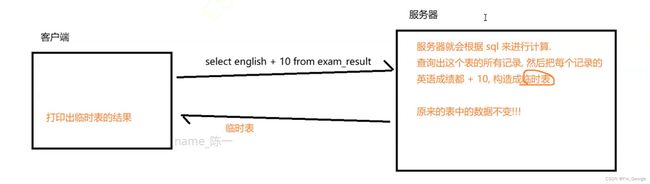
进行表达式查询的时候,表达式结果是一个临时表,这个临时表并不是写入到硬盘中的,临时表的类型也不是和原始表一样,会尽可能把数据给表示进去。
去重:DISTINCT
使用DISTINCT关键字对某列数据进行去重

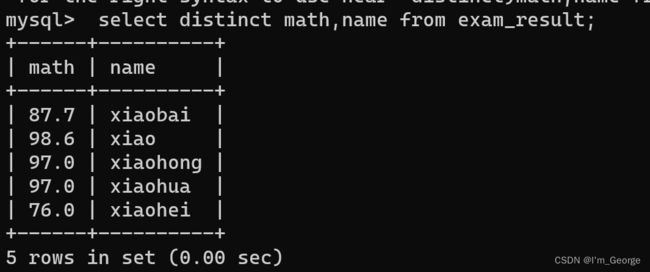
注意他会根据你要的顺序然后打印
排序:ORDER BY
底层大概率是归并排序
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
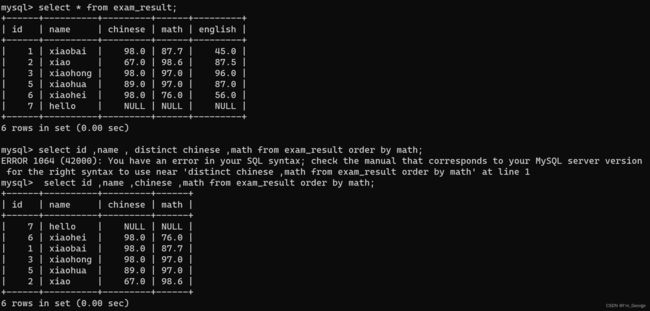
select id,name,chinese,math from exam_result order by math;
- 没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
- NULL 数据排序,视为比任何值都小,升序出现在最上面,降序出现在最下面,而且sql中的null于任何数进行计算都是null
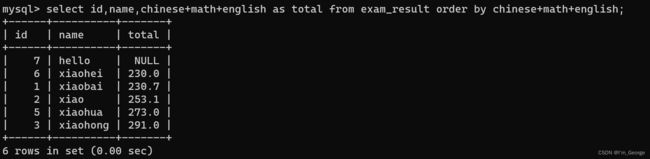
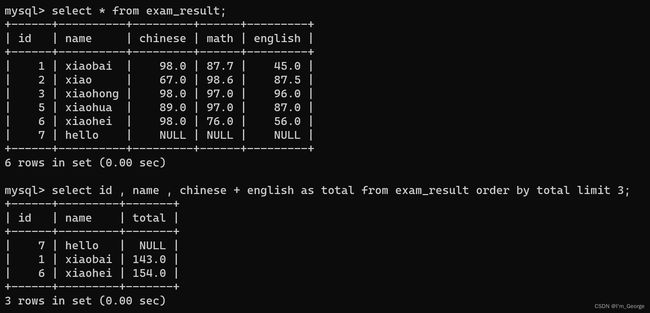
- 使用表达式及别名排序,可以使用表达式别名进行排序但是where中不可以使用表达式别名进行条件判断。
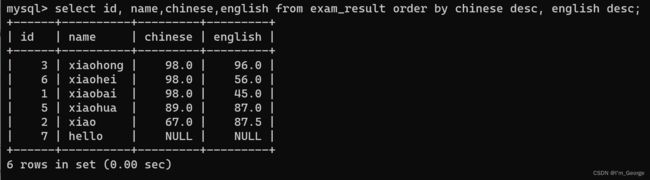
。- 可以对多个字段进行排序,排序优先级随书写顺序
条件查询:WHERE
根据查询的条件,按行进行筛选。通过where指定一个条件,把查询到的每一行都带入到条件中,看条件是真还是假,把条件为真的行,保留(作为临时表结果),条件为假的舍弃。
比较运算符
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
|---|---|
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| != <> | 不等于 |
| between a0 and a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, …) | 如果是 option 中的任意一个,返回 TRUE(1) |
| is null | 是 NULL |
| is not null | 不是 NULL |
| like | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字 符 |
- 注意:
- = 与 <=> 的区别,= 是不可以比较null的,而<=>是可以比较null的
- between a0 and a1 的前闭后闭的,而大多数语言都是前闭后开的。
- null与任何值进行计算都是null
- null是最小的,比负数都小,不是同一个比较范畴。
逻辑运算符
-
注意:
-
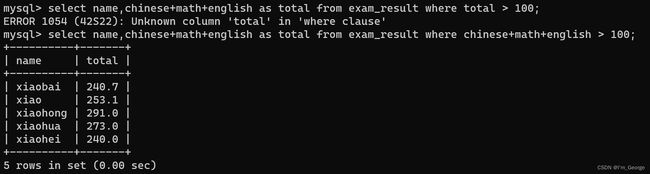
**WHERE条件可以使用表达式,但不能使用别名,但可以使用表达式别名排序。原因是执行顺序的问题,sql的执行顺序是 from -> where -> group by ->聚集函数 -> having -> select -> order by
-
AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
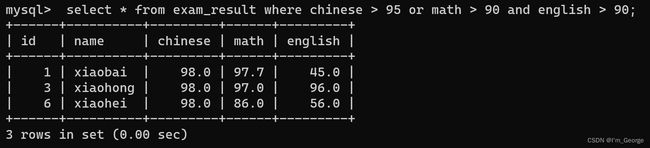
这部分的意思是(语文成绩大于95)或者(数学成绩大于90并且英语成绩大于90)的人
-
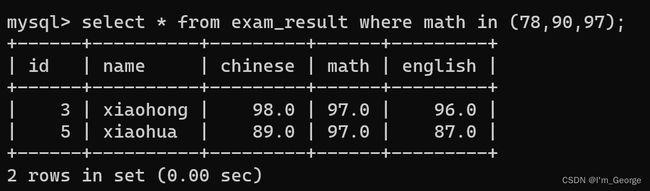
这部分的意思是数学成绩是78或90或97的人
-
模糊查询:LIKE
% 匹配任意多个(包括 0 个)字符,
孙%:匹配的是以孙开头的字符串
%孙:匹配的是以孙结尾的字符串
%孙%:匹配的是只要有孙这个字的字符串
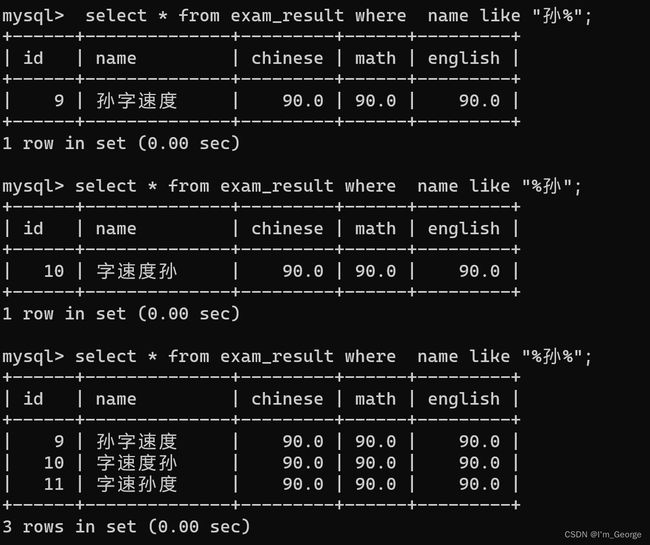
_ 匹配严格的一个任意字符
SELECT name FROM exam_result WHERE name LIKE '孙_';-- 匹配到孙权
mysql中支持的模糊匹配的功能是非常有限的,实际的开发中可能会遇到一些更为复杂的模糊匹配,例如可能会描述一些更为复杂的规则,某某字符,出现在什么位置范围,重复出现的次数范围,包含一些特殊的符号之类。
这时候发明了一个东西叫正则表达式,来描述这样的字符串的规则,来描述一个字符串长啥样,查询或进行其他操作的时候按照这套规则进行匹配。
NULL 的查询:IS [NOT] NULL
-- is null要求只能比较一个列是否为空
列名 is null;
-- <=>可以直接比较两个列,万一某行两列都是null也能查出来,这个场景使用 is null就不好搞
列名1 <=> 列名2
分页查询:LIMIT
查询操作中,引入一个limit,通过limit来限制查询结果的数量,直接在查询语句的结尾加上limit,来指定查询结果的最大数量。
-- 格式
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
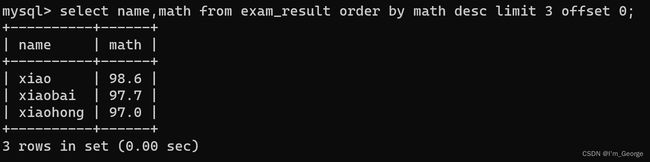
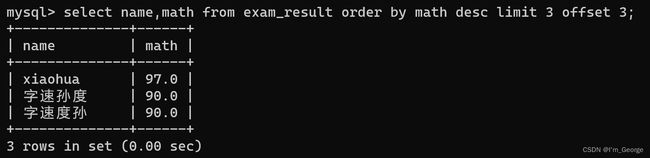
limit n offset m:意思是从第m条开始包括m,拿出n个来,如果最后的结果不足n个也不会受到影响,offset的的值是从0开始计算的。
6.3:记录的修改 Update
(切实的在改变硬盘上的数据)
-- 格式
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
update exam_result(表名) set math = 80 where name like "孙%";
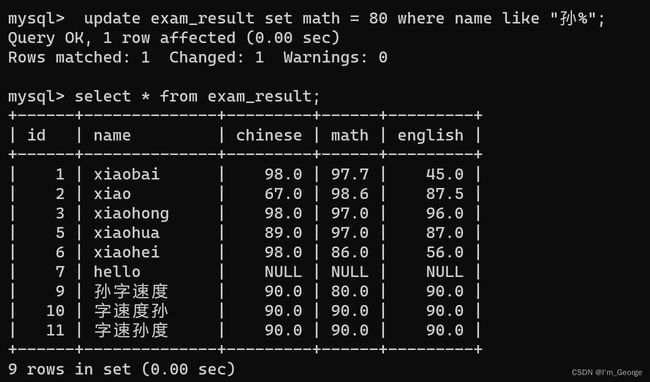
update可以同时修改多个列:
-- 将数学排名前三的学生的所有成绩减10分
update exam_result set chinese = chinese - 10,math = math - 10,english = english - 10 where chinese is not null and math is not null and english is not null order by math desc limit 3;
-- update可以同时修改多个列
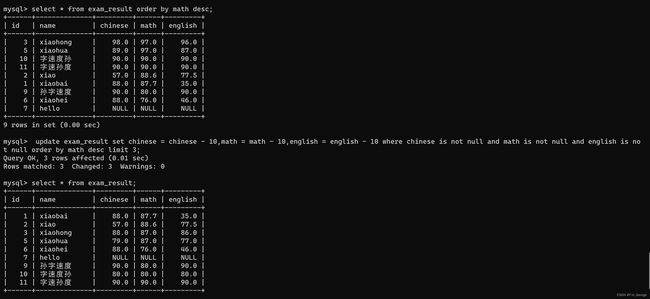
(不加条件就把这个表全给改了)
update 也可以搭配一些子句进行操作
-- update 也可以搭配一些子句进行操作
update exam_result set chinese = 150 where name like "孙%" order by chinese + math + english;
matched 与 changed 的区别
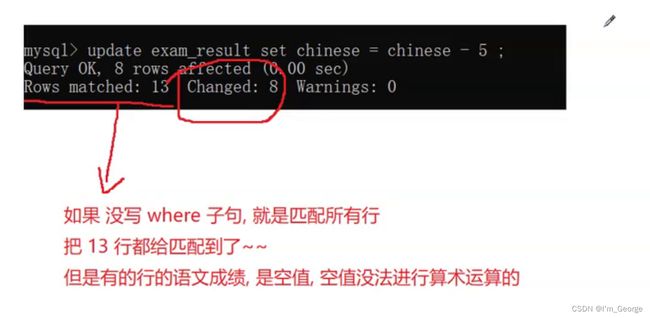
matched 是匹配
changed是改变
6.4:记录的删除
-- 格式
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
把数学成绩倒数后3名给删了

不加条件就把这个表给删了
delete 与 drop 的区别:
delete from exam_result; -- 将表里的记录都删了,但是表还在那里没被删除。
drop table exam_result; -- 将表以及里面的数据一锅端了