每日学术速递5.29
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
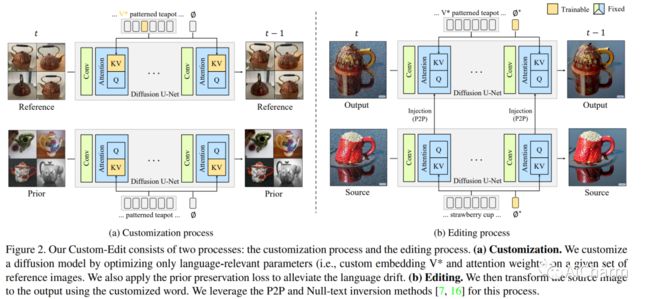
1.Custom-Edit: Text-Guided Image Editing with Customized Diffusion Models(CVPR 2023)

标题:自定义编辑:使用自定义扩散模型进行文本引导图像编辑
作者:Jooyoung Choi, Yunjey Choi, Yunji Kim, Junho Kim, Sungroh Yoon
文章链接:https://arxiv.org/abs/2305.15779
项目代码:https://rl-at-scale.github.io/


摘要:
文本到图像扩散模型可以根据用户提供的文本提示生成多样化的高保真图像。最近的研究扩展了这些模型以支持文本引导的图像编辑。虽然文本引导是用户直观的编辑界面,但它往往无法确保用户准确传达概念。为了解决这个问题,我们提出了自定义编辑,其中我们 (i) 使用一些参考图像自定义扩散模型,然后 (ii) 执行文本引导编辑。我们的主要发现是,仅使用增强提示自定义与语言相关的参数可以显着提高参考相似性,同时保持源相似性。此外,我们为每个定制和编辑过程提供我们的配方。我们比较了流行的定制方法,并使用各种数据集验证了我们在两种编辑方法上的发现。
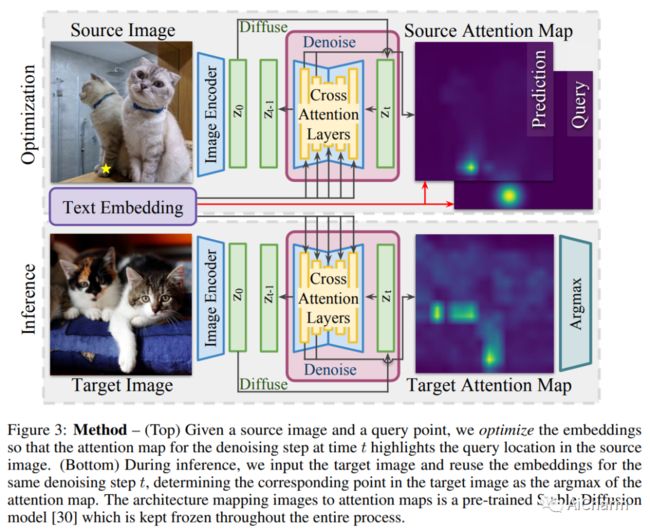
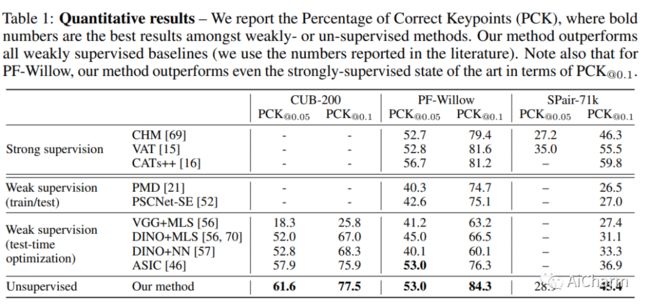
2.Unsupervised Semantic Correspondence Using Stable Diffusion

标题:使用稳定扩散的无监督语义对应
作者:Eric Hedlin, Gopal Sharma, Shweta Mahajan, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, Kwang Moo Yi
文章链接:https://arxiv.org/abs/2305.15581


摘要:
文本到图像扩散模型现在能够生成通常与真实图像无法区分的图像。为了生成这样的图像,这些模型必须理解它们被要求生成的对象的语义。在这项工作中,我们表明,无需任何训练,就可以在扩散模型中利用这种语义知识来找到语义对应——多个图像中具有相同语义的位置。具体来说,给定一张图像,我们优化这些模型的提示嵌入,以最大程度地关注感兴趣的区域。这些优化的嵌入捕获有关位置的语义信息,然后可以将其传输到另一个图像。通过这样做,我们在 PF-Willow 数据集上获得了与最先进的强监督技术相当的结果,并且显着优于(相对于 SPair-71k 数据集的 20.9%)PF-Willow、CUB-200 上任何现有的弱监督或无监督方法和 SPair-71k 数据集。
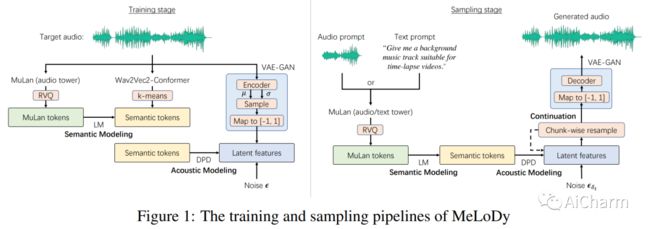
3.Efficient Neural Music Generation

标题:高效的神经音乐生成
作者:Max W. Y. Lam, Qiao Tian, Tang Li, Zongyu Yin, Siyuan Feng, Ming Tu, Yuliang Ji, Rui Xia, Mingbo Ma, Xuchen Song, Jitong Chen, Yuping Wang, Yuxuan Wang
文章链接:https://arxiv.org/abs/2305.15719
项目代码:https://efficient-melody.github.io/


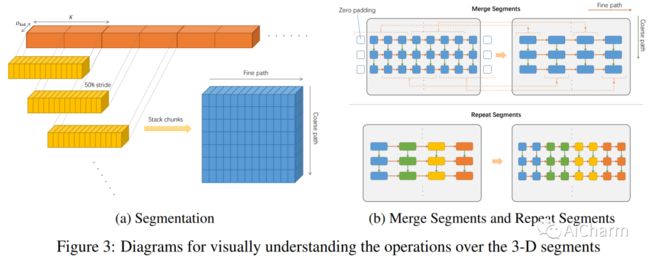
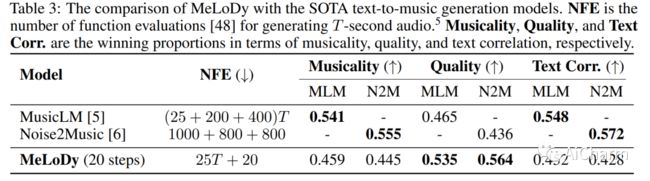
摘要:
最先进的 MusicLM 显着推动了音乐生成的最新进展,它包括三个 LM 的层次结构,分别用于语义、粗声学和精细声学建模。然而,使用 MusicLM 进行采样需要通过这些 LM 一个一个地进行处理以获得细粒度的声学标记,这使得计算成本高昂且无法实时生成。具有与 MusicLM 同等质量的高效音乐生成仍然是一项重大挑战。在本文中,我们提出了 MeLoDy(M 代表音乐;L 代表 LM;D 代表扩散),这是一种 LM 引导的扩散模型,它可以生成最先进质量的音乐音频,同时减少 95.7% 或 99.6% 的前向传递MusicLM,分别用于采样 10 秒或 30 秒的音乐。MeLoDy 继承了 MusicLM 的最高级别 LM 进行语义建模,并应用新颖的双路径扩散 (DPD) 模型和音频 VAE-GAN 将条件语义标记有效地解码为波形。DPD 被提议通过在每个去噪步骤中通过交叉注意将语义信息有效地合并到潜在片段中来同时对粗略和精细声学进行建模。我们的实验结果表明 MeLoDy 的优越性,不仅在于其在采样速度和无限连续生成方面的实际优势,还在于其最先进的音乐性、音频质量和文本相关性。
更多Ai资讯:公主号AiCharm