【论文翻译】(arxiv 2023)Neural Radiance Fields (NeRFs): A Review and Some Recent Developments
(arxiv 2023) Neural Radiance Fields (NeRFs): A Review and Some Recent Developments
2023/05/06:好短的一篇arxiv文章,刚好下午剩点时间翻了,五一假期不上班太舒服了,一点都不想上班。这篇写的有点抽象,只能说是抽象。
Abstract
神经辐射场(NeRF)是一个利用全连接神经网络(又称多层感知机)的权重表示3D场景的框架。 该方法用于新视图合成任务,能够从给定的连续视点获得最先进的逼真图像渲染。NeRF已经成为一个受欢迎的研究领域,因为最近的发展扩大了基本框架的性能和能力。最近的发展包括需要更少的图像来训练模型进行视图合成的方法,以及能够从无约束和动态场景表示中生成视图的方法。
1. Introduction
视图合成是计算机视觉研究的主要问题之一,它在计算机图形学和3D渲染领域具有许多意义和共同的方法。该问题的解决方案旨在开发一种方法,该方法可以从稀疏的视点集输入2D RGB图像,从而生成特定场景的新视图。这种模型的输出应该在一组连续的视点上采样,从而产生相同场景的逼真的新颖视图。一些流行的方法包括光场插值,通过基于网格的近似进行表面估计,以及最近的神经体绘制(基于神经网络的方法)。神经辐射场(NeRF)是由Mildenhall等人引入的,适合后一类方法,这些方法使用神经网络架构来表示场景,并使用神经体渲染来合成新视图,以获得最先进的结果。原始论文[1]将NeRF推广为视图合成的主要方法,并做出了3个总体贡献,使框架能够产生逼真的输出,可以模拟场景的复杂形状和表示。(1)第一个是通过一个简单的全连接神经网络来表示连续场景,该网络将5D输入(3个欧几里德坐标维度和2个观看方向维度)映射到4D输出(RGB颜色通道和体积密度)。(2)第二个贡献是利用可微分相机光线的神经体渲染技术,这使得RGB表示的优化成为可能。(3)最后,利用位置编码技术对输入进行变换到高维空间,这使得神经网络能够在训练过程中捕获场景表示中更高频率的细节。NeRF模型此后得到了改进和扩展,以得到各种表示模式。本文对NeRF原文进行了回顾,又称为vanilla NeRF,并进一步探讨了为扩展基线模型所做的许多贡献中的一部分工作。本次回顾将包括以下基于NeRF的发展:PixelNeRF, RegNeRF,Mip-NeRF, Raw NeRF, NeRF in-the-Wild。为了在高层次上回顾这些概念,我们将不包括为实验设计的特定方程或模型体系结构,我们建议您探索原始论文以了解具体实现的细节。
2. Neural Radiance Fields
A. Neural Volume Rendering
NeRF表示是建立在神经体积的基础上的,神经体积是一种隐式的三维场景的体积表示,学习并存储为深度神经网络的权重。在Lombardi等人的研究中,二维图像被输入到变分自编码器(VAE)中,并被编码为潜在代码。解码器的输出将潜在代码重建为空间中每个点的具有RGB和alpha通道复合表示的体素表示。虽然他们的研究目标是从2D图像构建3D表示,但VAE是通过从体素表示重建2D图像来训练的,使用光线步进技术进行体绘制。光线步进法是一个可微的过程,这使得使用梯度下降方法进行优化成为可能。场景的2D重建可以通过估计从3D场景在给定观看方向投影的图像平面中的每个像素的亮度值来执行。
每个像素点的光线以垂直于图像/相机平面的给定观看方向投射到3D空间中,并用于表示沿着光线的空间的体积或占用。像素的体积密度是通过对沿射线的体积积分来确定的;这个过程被称为体绘制。由于计算上不可能确定沿连续射线的体积,因此对沿射线离散点的体积进行采样以估计积分;这种用于体绘制的技术被称为光线步进。像素的亮度和体积通常表示为重建二维图像中的颜色(r,g,b)和不透明度。这个过程可以通过神经网络进行映射,整个表示方法被称为神经体绘制。
在Lombardi等人的案例中,使用神经体绘制从VAE的输出中获得的3D体素输出中重建图像。然而,由于VAE的性质,当来自低维空间的潜在代码被上采样到高维三维体素空间时,会发生伪影和重建扭曲。需要应用各种附加技术来减轻这些影响。因此,最终的3D几何形状往往不够完美。相比之下,视图合成的目标是从新的视点生成逼真的图像。利用vae重构一个3D体素表示是不必要的,因为它会导致文献[2]中描述的缺陷。
B. NeRF 3D Scene Representation=
原始NeRF论文提出,场景的表示是一个神经体积,该神经体积由一个简单的全连接神经网络架构(称为多层感知器(MLP))的权重来描述。其5D输入 ( x , y , z , θ , Φ ) (x, y, z, θ, Φ) (x,y,z,θ,Φ)对应于三维空间中的位置, x = ( x , y , z ) x = (x, y, z) x=(x,y,z)和二维观看方向 d = ( θ , Φ ) d = (θ, Φ) d=(θ,Φ)对应于沿相机光线的一个点。MLP的输出对应于颜色通道 c = ( r , g , b ) c = (r, g, b) c=(r,g,b)和该视点二维图像平面中像素的体密度 σ σ σ的映射。与之前的研究不同,场景的3D表示完全通过简单前馈MLP的权重隐式表示,而不是通过体素表示。MLP前馈网络可以表示为 F Θ : ( x , d ) → ( c , σ ) F_Θ: (x, d)→(c, σ) FΘ:(x,d)→(c,σ)。MLP的参数 Θ Θ Θ使用可微体积渲染函数进行优化,并在一组地面真实图像及其已知的观看方向上进行训练。损失函数可以通过评估体绘制过程中真实像素颜色和期望像素颜色之间的差异来选择。在论文中,作者使用了一个简单的均方误差。对于原始论文中NeRF场景表示的视觉概述,请参见图1。

C. Positional Encoding
当像前一节中描述的那样直接训练MLP F Θ : ( x , d ) → ( c , σ ) F_Θ: (x, d)→(c, σ) FΘ:(x,d)→(c,σ)时,模型往往难以输出细致逼真的结果。在许多编码任务中,这是一个常见的问题,当人们想要通过一个完全连接的神经网络的权重来编码一个表示(如图像)时。这个任务很困难,因为MLP偏向于更快地学习低频。这意味着,这些网络往往在需要概括结果的任务上工作得更快,并避免过度拟合数据。然而,由于神经体绘制的目标是将精确的几何形状拟合到3D场景中,因此网络最好对数据进行过拟合。 Tancik等人[3]介绍了一种Transformer常用的方法,称为位置编码,将低频输入映射到高频域。将输入映射到高频域使得MLP捕获场景中的高频和高分辨率细节。当应用于MLP时,NeRF模型变为 F Φ : ( γ ( x ) , γ ( d ) ) → ( c , σ ) F_Φ:(γ(x), γ(d))→(c, σ) FΦ:(γ(x),γ(d))→(c,σ)。其中γ(.)是将输入映射到高频域的函数。在NeRF中采用傅里叶特征映射作为高频特征映射函数。请注意,这是实现从NeRF模型获得的逼真结果所必需的。
D. Properties
到目前为止,NeRF模型及其视图合成的优化方法被描述为一种神经体表示,可以捕获3D场景的高频几何细节。这给NeRF提供了一些有趣的内在属性,超出了视图合成的任务。需要注意的第一个属性是,由于3D几何表示作为权重存储在完全连接的神经网络中,因此NeRF可以被视为3D模型的压缩格式。 通过在预定义视点上查询预训练的NeRF,然后应用移动立方体法等三维几何构造方法来重建三维模型。这一点很重要,因为NeRF文件的大小将小于模型所训练的单个图像。 第二个属性是NeRF捕获有关场景的相关几何信息,这使我们能够使用详细的几何信息用于生成深度图和形状可视化等任务。这也可以用来捕捉混合现实场景中的遮挡效果。第三个属性是在不同的观看方向上视觉化色彩感知效果的能力,此属性允许在给定固定位置的各种照明条件下以逼真的方式捕捉场景。
E. Implementation and Challenges
从NeRF方法获得的结果视点非常细致,并且在综合建模场景和真实场景中都优于先前的最先进方法。然而,到目前为止所描述的普通NeRF模型对于现实世界的实现有几个限制。我们将重点关注的第一个方面是训练和优化过程。实现NeRF模型的挑战在于,每个场景都需要对具有已知视点方向的图像进行训练。虽然这个问题对于移动应用程序来说似乎相当有限,但有一些方法可以估计这些参数,包括COLMAP structurefrom-motion包[5]。这可能会在生成新场景的过程中引入一些变化,但所获得的结果仍然令人印象深刻。与其他方法相比,训练和渲染过程非常缓慢,并且需要来自独特视点的不同图像集来捕获无缝连续视图合成。大多数实现需要至少80张图像进行训练。用非常稀疏的图像训练的模型将产生不可解释的场景,并且不能泛化。 其他挑战包括对所捕获场景的限制。nerf被限制在静态场景中,因为动态因素的影响会对视图合成产生剧烈的影响。这包括反射、移动的物体和背景。vanilla模型观察到的这些挑战创造了一个新的研究领域,特别是优化和扩展基础NeRF概念。我们将在本文的下几个部分探讨解决这些挑战的最新发展。
3. View Synthesis From Fewer Images
NeRF研究的最新进展所解决的一个挑战领域是场景的校准过程。由于训练和渲染新场景的时间和计算量大,NeRF的实现经常受到限制。一种方法是减少在校准过程中花费的资源。有两篇论文解决了减少所需校准图像数量的问题。
A. Pixel NeRF
vanilla NeRF模型需要来自不同视点的许多图像,因为MLP模型不能很好地泛化。MLP也不包含空间信息,因为图像在输入到训练过程之前是扁平的。如果使用多个视点来校准场景,则普通方法不会考虑从多个视点学习到的信息。当图像采样不一致且稀疏(少于80张图像)时,这将导致场景合成的退化。Yu等人[4]引入了对基础NeRF模型的扩展,该模型在校准过程中包含了场景先验。这个模型被命名为PixelNeRF,对NeRF框架的主要贡献是通过卷积神经网络(CNN)传递输入图像来训练场景先验,从而对模型进行调节。为了更好地说明这一点,给出了论文中的体绘制管道的可视化概述[4],如图2所示。这允许使用低至一个校准图像来训练模型,尽管这只推荐用于简单的几何形状。在多视图校准(2或更多图像)中,每个输入图像在不同视图下的CNN输出在通过体绘制过程馈送之前进行组合。PixelNerf能够使用简单的合成模型在ShapeNet数据集中的一张校准图像上实现连续的场景表示。该模型还在真实图像上进行了测试,并且能够使用单个校准图像生成场景的连贯几何表示,这在普通NeRF中是不可能的。然而,结果并不完美,并产生了伪影和扭曲。通过增加多个视图(2-3个)进行校准,这个问题得到了显著缓解。

B. RegNeRF
Niemeyer等人介绍了一种方法,该方法减少了当vanilla NeRF仅在少数图像上训练时发生的浮动伪像和图像不一致。本文通过对未见视图中的斑块进行正则化以实现几何平滑和颜色[7]。本文引入的模型被命名为RegNeRF,它是对传统NeRF模型优化过程的改进。而普通NeRF模型在输入图像的重建损失上进行优化,它没有优化学习各点的几何一致性,因此该方法随着样本图像变得稀疏而恶化。RegNeRF在不可见的视点从补丁中采样光线,然后定义一个优化,目标是正则化补丁的几何平滑度和颜色可能性。这是在训练过程中通过定义颜色和几何块的正则化项的损失函数来完成的。本文的结果表明,与以前的模型相比,在减少浮动伪影方面有了显著的改进。由于RegNeRF保留了原始NeRF模型的MLP架构,因此在预训练期间,它的计算成本要低于基于CNN的pixelNeRF。RegNeRF可以使用低至3个校准图像进行训练。
4. Dynamic and Unconstrained Conditions
特定场景的动态条件是影响其表现的主要因素。通常是普通NeRF模型不能利用这些动态条件,事实上,它需要约束场景来实现没有诸如浮动伪像和混叠等伪像的体积渲染。NeRF模型的最新发展探索了利用、控制和操纵场景条件的各个方面的方法。在本节中,我们将探讨一些论文,这些论文解决了多尺度表示的抗混叠、图像处理管道和无约束样本图像表示等领域的问题。
A. Mip-NeRF
多尺度表示对许多图像处理和三维绘制任务提出了挑战。从不同的尺度重建3D场景或2D图像通常伴随着被称为锯齿的伪影,这通常是由混叠引起的。当对低分辨率输入图像进行采样时,在NeRF模型中特别观察到混叠。具有相同分辨率的视图重建通常包含这些锯齿。用多尺度分辨率训练NeRF模型来缓解这个问题,通常不会导致显著的改进,特别是当试图重现更高分辨率的视图时。Barron等人介绍了Mip-NeRF,这是NeRF方法的扩展,它使用射线锥来捕获空间体积,而不是无穷小的点来控制场景的多尺度表示[8]。随着图像比例的变化,单个像素从场景中捕获的信息量也在变化。因此,每个像素上沿单点射线的采样点在与邻近像素的插值过程中会引起失真,从而导致混叠效果。沿圆锥射线区域的采样点允许以非线性方式捕获体积信息。本文通过拟合多元高斯分布来近似这些沿射线锥的圆锥交点。由于采样不再沿直线进行,因此在分布中选择样本相当于位置编码的期望值,这反过来又使网络基于缩放调整的空间体积进行推理。锥形射线的视觉表示形式为原论文[8]中的图象,见图3。本研究的结果表明,Mip-NeRF在多尺度分辨率重建方面优于先前的vanilla NeRF方法。与具有类似结果的超采样方法相比,它的计算效率也显著提高。

B. Raw NeRF
在本节中,我们来看一种NeRF模型方法,该方法考虑了图像处理和后处理管道,而不是模型架构,以从场景中获得更多信息,从而产生令人印象深刻的结果。NeRF模型通常使用低动态范围图像(LDR)进行训练,以执行新视图合成。这种处理过程通常用于去除图像中的噪声,特别是在黑暗中。然而,这是以牺牲场景中较暗区域的细节为代价的。这种细节的缺失反映在NeRF模型生成的新视图上。例如,场景在非常低的照明条件下,产生非常黑暗的视点图像,几乎没有细节。相比之下,HDR高动态范围图像通过将不同曝光或视图的多张图像组合在一起来捕捉细节,甚至应用后处理技术来重新对焦。Mildenhall等人在他们的论文[9]中提出,NeRF模型的输入是原始的、经过最小处理的、有噪声的拼接线性图像,以捕捉场景的更多细节,尤其是在黑暗中。然后,NeRF可以合成场景的新视点,并应用后处理技术在最终合成视图中捕捉类似HDR的效果。
Raw NeRF管道的可视化流程如图4所示。这种方法对新视图合成有许多启示。首先,Raw NeRF能够生成场景的去噪视图,优于LDR处理中使用的深度去噪方法以及多视图去噪。Raw NeRF能够在非常低的照明条件下渲染具有逼真细节的场景。此外,还可以利用HDR色彩空间中的后处理方法实现场景曝光重构、色调映射、重对焦等进一步的效果。这是在捕捉场景的3D几何细节的同时进行的。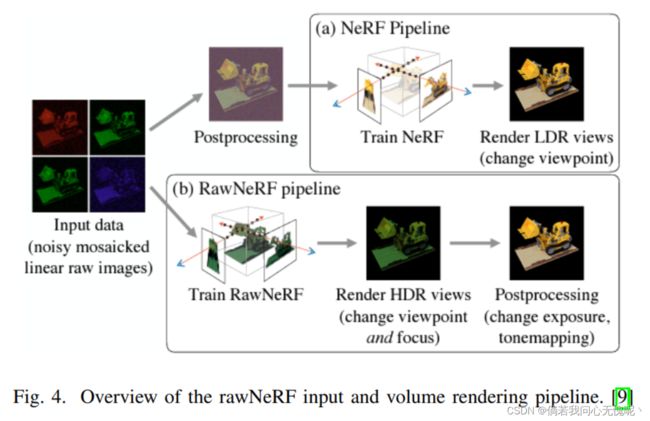
C. NeRF in the Wild
普通 NeRF模型和它的许多变体的一个限制是约束采样条件的要求。这限制了NeRF在现实世界和自然图像上的许多可能应用。这也限制了NeRF模型需要一个或几个物体的固定场景,并且需要相当一致的图像视点进行校准。当在不受约束的图像和动态场景上进行训练时NeRF生成带有浮动伪影的视图,因为它不知道如何解释这些变化的实体。Martin-Brualla等人提出了NeRF模型的扩展,称为NeRF-W,该模型嵌入场景的静态和瞬态组件,以在动态条件下生成新的视图[10]。NeRF-W能够通过对模型的输入进行外观嵌入和瞬态嵌入的调节,将学习到的静态成分和动态因素分离开来。在训练过程中,NeRF-W通过优化NeRF在重构损失上的权重来学习这些解释,重构损失是由不确定性因素调制的。这样做NeRFW能够成功地将场景的结构与动态方面隔离开来。由于学习了瞬态嵌入,因此可以根据训练数据的变化在各种条件下重建场景。本质上,NeRF-W是基于动态因素的原始NeRF模型的解耦版本。
5. Conclusion
自2020年NeRF框架开发以来,已经进行了许多变体和扩展,大大提高了其性能和能力。该模型能够实现最先进的结果和逼真的渲染,为这种框架在视图合成和其他领域提供了许多机会。自那以后,NeRF已成为一个独立的研究领域,并不断取得重大进展。NeRF的应用包括电影摄影中的3D场景渲染、3D图形生成、虚拟渲染和网站演练等等。本文回顾了基本的NeRF框架,并探讨了迄今为止(在撰写本文时)取得的一些最新进展。强烈建议在各自的项目网站通过视频演示直观地观察每个NeRF模型变体,更能直观地了解其功能。