Pilota:为什么一个代码生成工具如此复杂丨GOTC Rust系列分享
对于一个 Rust RPC 框架来说,根据 IDL 做代码生成是为了让用户更方便地使用框架。而生成代码的质量以及周边能力都会对用户的开发体验有着非常非常直接的影响。
所以,字节跳动 CloudWeGo 开发了 Pilota 这样的一个框架,来为用户生成良好的代码。
在 2023 年 5 月 28 日 举行的「GOTC 全球开源技术峰会 - Rust 论坛」上,字节跳动服务框架研发工程师刘翼飞介绍了 Pilota 这款代码生成工具,今天我们就为大家介绍这次分享的内容。

为什么需要代码生成工具
首先,我们为什么需要代码生成工具?
因为在 RPC 的世界里,用户通过 IDL 这种形式来描述一个服务的接口。
比如说这里有个 service,service 还提供了一些方法,需要描述这个方法的入参的类型和返回结构的类型,用户是通过这个 IDL 去描述的。

在实际代码中,我们不能直接去使用这样的 IDL,所以就需要把 IDL 转换成 Rust 代码,交给用户框架使用。

这样的翻译过程,就是我们的代码生成工具需要做的事情,即把一份 IDL 翻译为 Rust 代码。
同时,还需要做一些编解码逻辑的生成。
比如说我们对定义的一个 Message 的 trait,需要提供 encode decode 方法,这个 encode 就是把自身结构化的数据编码到一段二进制数据,而 decode 就是从一段二进制数据中得到一份结构化的数据,这些编解码逻辑也需要代码工具去进行具体生成。

有了我们的代码生成工具之后,就可以非常方便去调用一次 RPC,只需要在 built.rs 文件的那边去写上依赖了哪个 IDL 文件,我们代码生成工具会给它生成一段代码,之后只需要在你的业务逻辑里通过 include! 宏把生成好的代码引入,就可以非常方便的构造出一个 client,就像完成一次普通的函数调用一样来完成一次 RPC 调用。


这种方式让 RPC 调用就变得非常简单。
生成 Rust 代码的挑战
那么,生成代码的时候会遇到什么挑战?
其实很多时候可能等会想这有什么复杂的,只需要把一个 IDL 给转换成 AST,然后逐行翻译而已,我们只需要简单实现一个 Parser 就行了。其实我们最开始也是这么想,我们的第一版的代码生成工具就是用这个思路去做的,非常简单。
但是后来我们遇到非常多的问题。
比如说我们在 IDL 里存在一个循环依赖问题,我们存在 struct a 依赖了 struct b。然后 struct b 又依赖了 struct a。


如果直接翻译到 Rust 代码编译,编译器就会报错,告诉你这两个 struct 的大小无法计算。
Rust 的世界里是不允许去这样去描述循环依赖的,所以必须要通过一些手段来解除这个大小的问题。
比如说在这里给这些 Field 上加上 Box, 因为 Box 其实就是一个指针,这个结构的大小就是一个指针的大小,那么 size 计算的这个循环依赖就被解开了。

那么我们是如何解决这个问题的呢?
其实非常简单,就是我们会生成一个图,IDL 的每一个类型都会变成图里的一个节点,节点之间的边就是引用的feild。比如说结构 a 的话,它是通过这个 a.b 这个去使用了结构 b,然后类型 b 的话通过 b.a 来使用结构 a。
然后现在我们可以新上一个图,然后我发现这个图里面它是存在环的,我们需要检测出这个图的环,然后把这个环的东西上全部再加上一个 Box,我们就可以解决这个问题。

这时候用户提出了一个新的需求,这说你能不能帮我生成的那些 Rust 常用的 derive macro,比如 Hash 和 Eq。
但是我们是否可以对所有的类型全部都加上 Hash 这个 derive macro 呢?
不行,因为在 Rust 的世界里,像 float,它其实是没有实现 Hash 这个 Trait 的。
如果我们对于这样一个结构去实现给它加上一个 derive Hash,就会得到编译器的报错,因为 float64 这个类型并没有实现 Hash ,所以就需要定一个规则,如果一个结构体里面的所有字段都可以都实现的 Hash 的话,就需要那么这个结构是可以 derive Hash。

举个例子,有 3 个结构 a,b,c,结构 a 依赖结构 b、结构 c,结构 b 有依赖的结构 a ,然后结构 c 里面是有一个 double 类型的 feild,对应的 Rust 的类型是 float64。


那么这个时候我们开始要计算哪些结构可以被 Hash。我们首先来看一下结构 a 类型,我们会发现 Hash(A) 的成立取决于 Hash(B) 和 Hash(C) 这两个命题同时成立,然后再来看一下 field b,那么 Hash(B) 的成立就取决 Hash(A) 的成立。而 Hash(C) 的成立则取决于 Hash(double) 的成立。
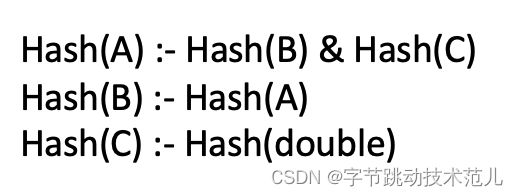
拿到这三个逻辑命题之后,就需要判断这些逻辑命题是否成立了。
首先来看一下这个第一个问题 Hash(A),因为 Hash(A) 的成立取决于 Hash(B) 和 Hash(C) 的成立,然后 Hash(B) 的成立取决 Hash(A) 的成立。
如果就这样非常简单直白地通过递归去处理的话,会发现 a 依赖 b,然后 b 反过来依赖 a,递归是永远不可能逃过去的。
此时就需要用一些手段了。处理 Hash(A) 要计算 Hash(B) 和 Hash(C),在计算 Hash(B) 时,因为要它依赖 Hash(A),而 Hash(A) 处于计算中,所以需要在计算 Hash(B) 的时候创建一个 lazy dependency,稍后计算,先不管它。
此时把 Hash(B) 替换成 Hash(A),再回到 Hash(A)的计算,我们会发现 Hash(A) 依赖于 Hash(C) 和 Hash(A) 的成立。再去处理一下 Hash(C),Hash(A) 成立其实依赖于 Hash(double) 的成立。但是其实 double 这个类型对应的 float32 并没有实现 Hash,所以最后我们得到一个问题,就是 Hash(A) 的成立,这个命题等价于 false & hash(A), 因为有 false 存在,所以这个命题已经不成立了,所以 Hash(A) 这个命题是不成立的。
此时还有一个问题:现在 Hash(A) 已经计算完,那么 Hash(B) 呢?因为刚才 Hash(B) 是计算到了一半,处于 lazy dependency 的中间态,需要把 Hash(B) 重新计算一遍。因为已经得出 Hash(A) 不成立,所以可以顺利计算出 Hash(B) 不成立。
因此,Hash(A)、Hash(B)、Hash(C) 这三个命题都是不成立的。

但如果换一个场景,假设 c 结构里面的字段不是一个 double,它是一个 int32,再按刚才的方式计算一遍,发现 Hash(C) 是成立的,那么可以得到 Hash(A) 的成立依赖于 Hash(A) 自身的成立。这个情况下我们怎么处理?
在 Rust 的世界里,如果一个 struct 有且仅有一个 field,而且这个 field 的类型还是自己本身的话,我们是可以对这个 struct derive hash的。因此,在这种情况下我们可以制定一个规则:如果一个命题只依赖自己本身的成立,那这个命题是成立的。那么 Hash(A) 也是成立的。
接下来我们就再回过来计算 Hash(B),因为 Hash(B),之前 lazy dependency Hash(A),那么因为 Hash(A) 是成立的。然后我在计算 Hash(B) 时候也会得到一个成立的结果,那么此时 Hash(A), Hash(B), Hash(C) 均成立。

处理 IDL 的过程中可能还会遇到常量,因为在所有的 thrift 中你是可以通过 const 来去定义一个常量的。

这个常量又该如何生成呢?
比如 thrift string 这个常量类型,会生成 &'static str 这个类型的常量,Rust 编译器会对常量进行一些优化,所以我们的代码生成工具是能够去为用户生成 &'static str 类型无疑是更好的。
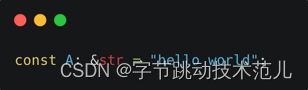
但是 thrift 可以允许用户写出非常自由的类型。比如通过 const 去指定一个 map 类型,然后 map 里面有 list 这样的一个类型。

但是在 Rust 里我们是没办法通过 const 去表达的,因为在 Rust 里面 Hashmap、vector 这些类型都涉及到内存分配。所以需要通过 lazy static 来处理,先创建一个 static reference,里面是生成了这样一个构造,这个 Hashmap 和构造这个 vector 的一些构造逻辑。
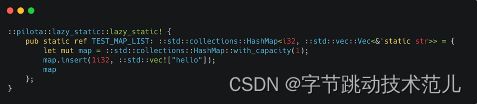
那么会引入什么问题呢?因为现在的设计里面存在两种类型表示,一种是 const,一种是 struct 里面的。

现在我们已经针对 const 里面的 string 类型生成 &'static str。
但是如果我们在 struct 里的string是怎么处理的?在 struct 里的 string 类型 field,它其实很有可能是需要被用户用来构在一个 request 里面,或者被服务端作为 response 出来,但是所以用户需要非常轻松地去构造出这样的一个field。
但是如果这里的 string 处理成一个 &'static str 的情况,那么用户基本上没法构造,因为 &'static str 构造的条件要求太高了。
所以此时需要定义一个规则,在 struct 这个 scope 里面的话, string 里面定义的 string 这个类型对应的 Rust 类型 string,那么就会存在两种类型表示的一个问题。
比如说现在这个“hello world” 这个 literal 但是如果在 const 个 scope 里面,对应类型是 &'static str,这个表达式可以直接被使用。但是如果是在非 const 这种形式里面,它需要被转化成一个 string,所以需要通过 to_owned() 方法转化成一个 string。但如果情况变得更加复杂,这里不是一个 literal 而是一个符号,那么就需要我们的代码生成工具有一个自己的类型系统,来去处理不同类型之间的转换的方式。
在一些实践中,我们还遇到了代码生成量过大的问题。
在我们的业务代码里面,对业务用的 IDL 文件,可能有几十个 thrift idl 文件,然后我们的生成工具生成了 150 万行 Rust 代码,一次 cargo check 需要执行 10 分钟。因为当时我们的代码生成工具逻辑是会把所有的 IDL 生成的 Rust 代码全部给放到一个文件里面去,所以导致用户的操作 check 过程非常慢。
但是在这过程中会发现一个问题,比如说这里有一个入口文件 a,它里面有个 service,这是用户真的要用到的一个 service,但是这个文件应该是统计,现在我们发现这两个文件里有 5 个结构,分别是 service、a,aa,b,bb。
但是其实用户只关心入口处的 service,没有被这个 service 所依赖的结构,用户都是不关心的。
所以此时我们就可以做出一个优化手段,以这个 service 作为入口节点,扫描哪些结构是被依赖的、哪些结构需要被生成,以减少需要生成的结构。这样优化之后,之前 150 万行代码只剩下 10 万行,编译效率得到大幅度提升。
在 CloudWeGo 下有一个 RPC 框架 Volo,提供给用户调用 RPC 的能力,那么 IDL 是怎么被 Volo 使用的呢?
我们需要一个代码生成工具来作为 IDL 和我们的 RPC 框架的一个桥梁,这个工具就是 Pilota,这是我们开源的一个代码生成工具。
Pilota 的设计架构
Pilota 的结构看起来很简单,它的入口就是一个 Parser,Parser 的输入是一个 IDL,输出是一个 AST。经过 Naming Resolve 符号解析之后产生一个中间表示 IR,我们会基于这个中间表示去处理循环依赖、类型转换、依赖收集等问题。最后继续执行一下用户自定义的 Plugin,把这个最终的结果交给 Backend 生产代码。
首先,我们来看一下 Parser 部分,现在我们 Parser 支持Thrift 和 Protobuf 两种,它的输出就是一个 AST。
只要 IDL 格式能够被转换到 Pilota 的 AST 表示,那么就可以接入 Pilota 这套体系,上面提到的那些复杂问题都可以很轻松被解决。
当我们拿到 AST 之后,就需要进入 Naming Resolve 阶段。
其实 Pilota 的 AST 已经非常接近 Rust 的表示形式了,只不过这里可能会有一些特殊之处,因为存在一些同名符号,比如 Mod Test 和 Struct Test
在 Pilota 的 AST 里是允许同名符号存在的,但是这样会给符号解析带来一些挑战。为什么要去允许这样一个设计呢?
因为在 Protobuf 会有一个非常特殊的设计,就是 Nested Item,你可以在 message 里面再去定义 message,但是在 Rust 里面不能在 Struct 里面再去定义 Struct,所以为了支持 Protobuf 这种特性就需要 Pilota 的 AST 可以表达这种形式。对于这种形式,在 Pilota 生成 Struct 同时 还会再生成一个同名的 Mod 用于相关的 nested item。
所以当同名符号出现,就会像 Rust 一样,在 Naming resolve 这个过程使用不同的 namespace,因为 Rust 现在 Naming Resolve 过程中,它其实是会存在两种 namespace,一个是 Type,还有一种是 Value Pilota 里也有类似的设计,会划分为三种不同的 namespace,分别是 type、value、Mod。
先看一下这个 AST 结构图,这些文件里面所有的 item 全部遍历一次,给符号分配好 ID。
分配完成这个 ID 之后的话,就需要计算出每个结构体,每个 field 里面的 path 到底指向哪个 id。
但是同名的符号可能会引入歧义问题,那么就需要需要根据 namespace 对不同的解析结果进行筛选。
在 Rust 中会有一些常用的第三方库的 derive macro,比如 serde。那么就需要 Pilota 提供一种灵活的能力来让用户自定义生成代码里的 attributes。
在 Pilota 每个 item field varaint 都会有一个对应的 adjust 字段,用户可以通过写一个plugin,访问到 adjust 的这个结构,然后通过修改里面 attributes 来自定义生成代码中的 attributes 和使用 nested_item 字段来控制额外生成的 Rust 代码比如 Impl Block。
Pilota 的未来
解决这些问题之后,Pilota 已经能满足绝大部分场景的使用了。但 Pilota 也在探索一些不同的代码生成方式。
有一些开发者表示生成的代码量还是挺大的,即使经过这些优化之后,代码量仍然有 5W-10W 左右,而且有的业务方也希望他们不想感知到 IDL 的存在,但是在现在的体系里用户必须要通过 IDL 来生成代码。但是能不能让用户换一种使用方式呢?
比如用户希望根据三个 IDL 生成对应的服务代码,那么可以生成 3 个 crate 来方便用户使用。
但是在这 3 个 crate 中可能会存在一些被同时使用的结构,就需要一个 coomon crate 来存放这样的结构。这种生成方式会给我们带来什么好处呢?
首先可以充分利用编译器的缓存,因为现在的 Rust 编译的缓存其实是一个 crate 级别的,比如说原本可能生成了十几万行代码,十几万行代码在业务里面被放到一个 crare。现在生成多个 crate,可能十几万行代码已经被完全放到 6 个 crate 里面,每个 crate 只分担了几万行代码量,缓存粒度更细了,当一个 crate 的代码发生更新,只需要重新编译这几万行代码就行了。
在生成了这些 crate 之后,开发者可以使用 cargo workspace 的方式来管理,然后将这些 crate 发布到 git上或者其他地方。那么其他开发者可以直接使用已经生成好的代码完成 RPC 调用,也不需要去关心 IDL 的存在了。
好的,这就是今天的分享了,谢谢大家。
GitHub 地址:
https://github.com/cloudwego/pilota