Hbase 操作命令
文章目录
- Hbase Shell 操作
-
- 一,基本操作
-
- 1,启动hbase
- 2,命名空间操作命令
- 3,表操作命令
- 二,DML
- 1,写入数据
- 2,读取数据
- 三、删除与版本介绍
- 四、Hbase Java API操作
Hbase Shell 操作
一,基本操作
1,启动hbase
首先启动hbase: start-hbase.sh
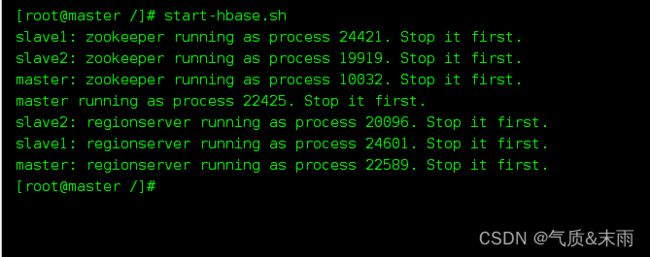
进入hbase 命令行命令: hbase shell
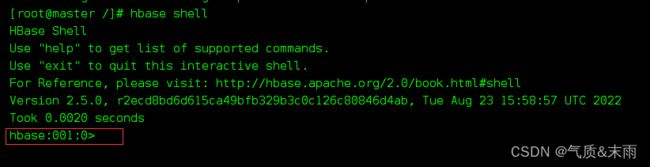
2,命名空间操作命令
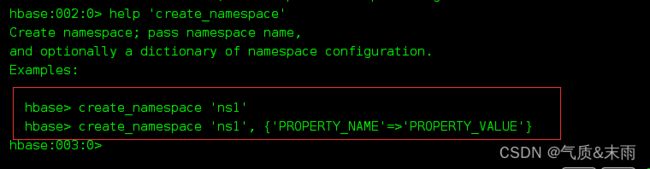
1,查看帮助命令: help 想要查看具体命令的话,需要加上引号 例如 help ‘create_namespace’
能够展示Hbase中所用能使用的命令,主要是使用的命令有 namespace 命令空间有关,DDL创建修改表格,DML写入读取数据.
输入help ‘create_namespace’ 下面例出了两种创建命名空间的语法格式
2, namespace 命名空间
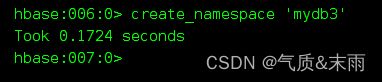
创建命名空间: create_namespace 要先创建命名空间。然后在命名空间里面创建表格
3,查看命名空间: list_namespace 可以查看创建好了的所有的命名空间,系统自带的有两个,其中这个default 没写命名空间的时候就存储在default里面,NAMESPACE 是系统的命名空间,我们是不会人为的去用到的,有系统需要用到的表格
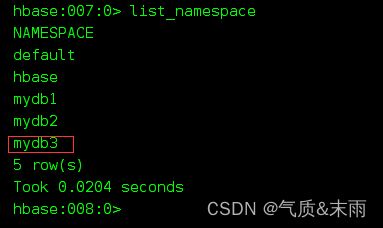
4,修改命名空间: alter_namespace
5,删除命名空间:drop_namespace
3,表操作命令
通过help帮助命令,可以看到有很多的创建方式
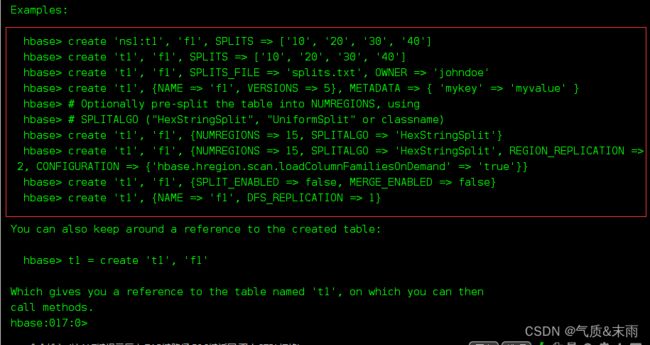
1,创建一个表
输入命令: create ‘bigdata:test1’,{NAME=>‘h1’,VERSIONS=>5}
创建表之前需要先创建一个命名空间,要是是在default默认空间里的话就可以省略命令空间

如果是在默认的命名空间default 里的话,是可以省略的,直接表名,如果没有其他的参数需要更改的话,直接加上两个列族就行
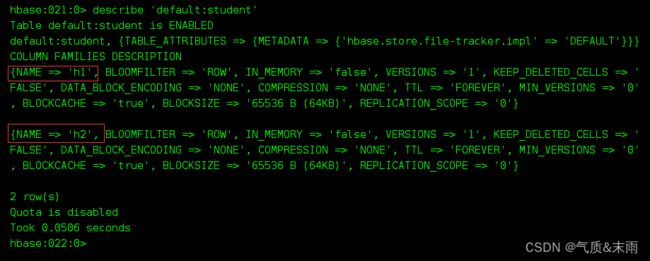
输入命令: describe ‘default:student’ 查看刚刚创建的表
可以看得到,我们直接加入了两个列族,h1和h2
想要创建多个列族和里面的参数的话,直接用逗号隔开

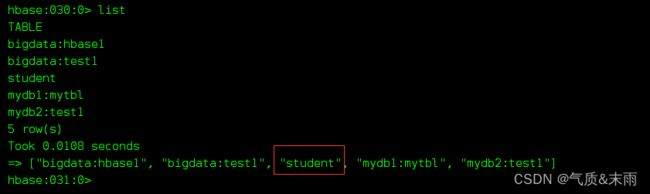
输入命令: list 可以查看所有的命名空间和表名 下面那种没有命名空间的就是在默认的命名空间default 下
2,修改表
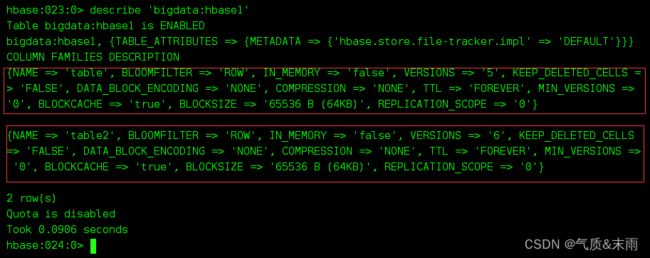
表名创建时写的所有和列族相关的信息,都可以后续通过alter修改,包括增加删除列族,也是在修改操作里的
增加列族和修改信息都使用覆盖的方法,
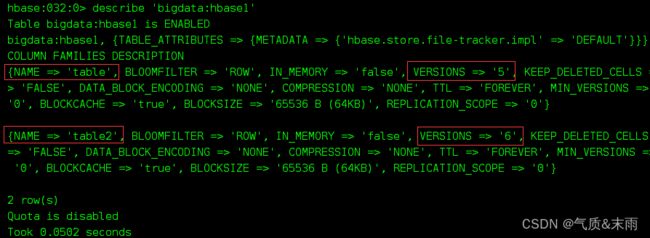
没增加前前的 ‘bigdata:hbase1’ 的列族名和维护的版本
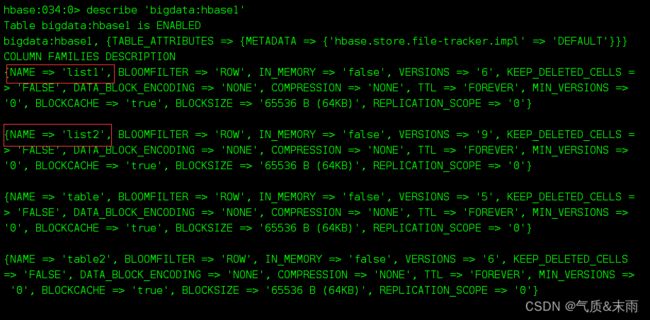
1)输增加列族命令:alter ‘bigdata:hbase1’,{NAME=>‘list1’,VERSIONS=>9},{NAME=>‘list2’,VERSIONS=>9}

查看修改之后的 ‘bigdata:hbase1’ 表里面的信息 发现增加了两个列族
2)修改’bigdata:hbase1’ 的 列族list1 的版本信息 从版本6改为3,修改列族信息的时候不要加大括号,直接列族名,后面跟要修改的参数
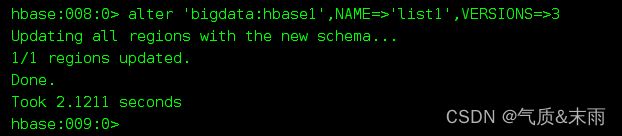
可以看到list1的版本号已经从6改为3了
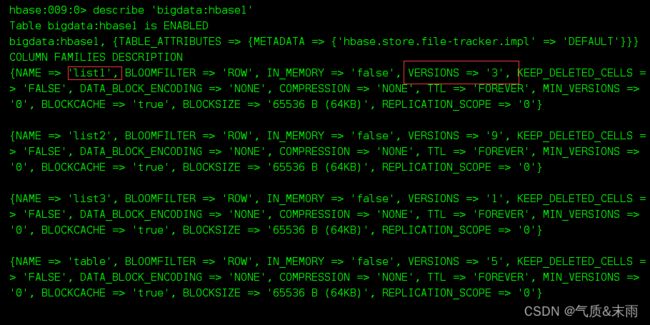
3)删除列族的话有两种语法:
alter ‘bigdata:hbase1’, NAME=>‘list1’, METHOD=>‘delete’ 第一种 method的参数改为delete
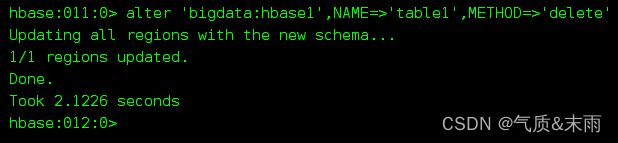
alter ‘bigdata:hbase1’ ,‘delete’=> ‘list2’ 第二种delete 直接跟 列族名
我比较喜欢第二种

可以看到下面在table1和table2的列族已经不存在了
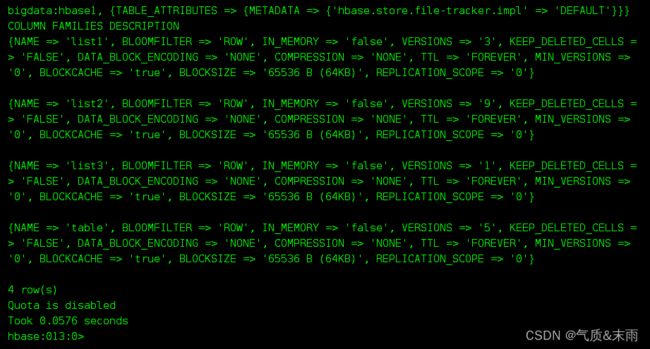
3,删除表
删除表需要drop命令,使用help查看,可以看到drop 命令的语法非常简单
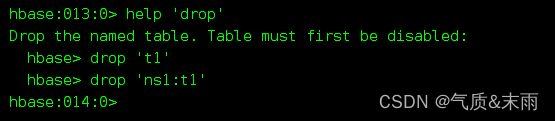
先查看有哪些表
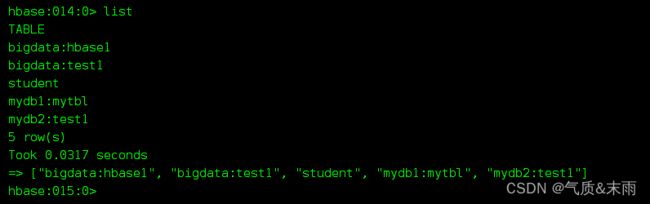
删除 ‘mydb1:mytbl’ 表 ,发现下面报错了
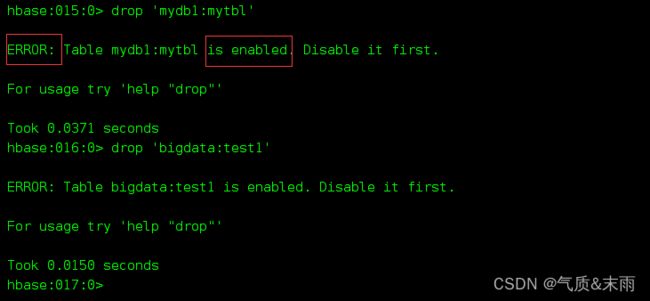
需要先把表标记为 disable 不可用,才能删除, 直接disable 加表名就可以了
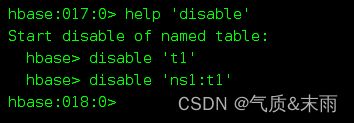
输入命令: disable ‘mydb1:mytbl’ 修改后查看,可以看到已经成disable了
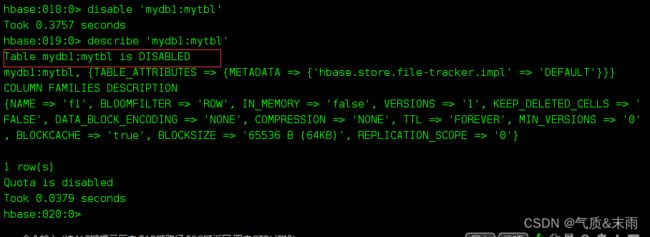
再进行删除表
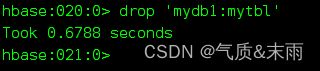
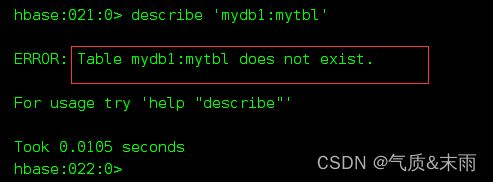
删除成功,‘mydb1:mytbl’ 表不存在
二,DML
1,写入数据
在Hbase 中如果想要写入数据,只能添加结果中最底层的 cell ,可以手动加入时间戳指定的cell版本,推荐不写默认使用当前的系统时间
在hbase里面想要写入数据都使用put,想要修改的话也可以用他,是直接覆盖的,查看put的语法
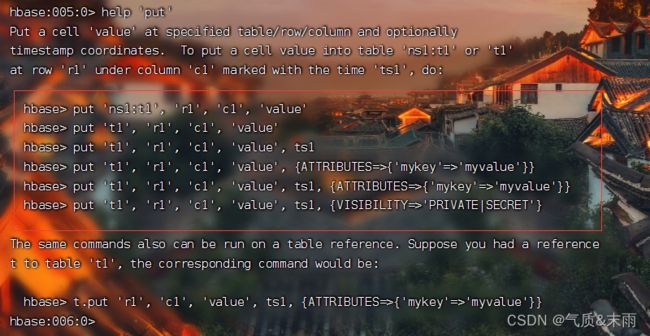
输入命令: put ‘bigdata:hbase1’,‘1001’,‘list1:name’,‘zhangsan’
语法是 put 然后表名,然后是列族,列名是name,最后这个张三就是1001行,name列下的数据

要是是在同一行号,同一列下增加数据的话,就会覆盖

要是想在同一列下增加数据的话,直接把行号改了就行了

要是想增加多列的话,直接行号不变,修改列名增加数据就行了
2,读取数据
读取数据使用get 和 scan
get最大的数据是一行数据,也可以进行列的过滤,读取数据的结果为多行cell
查看get和scan的使用方法
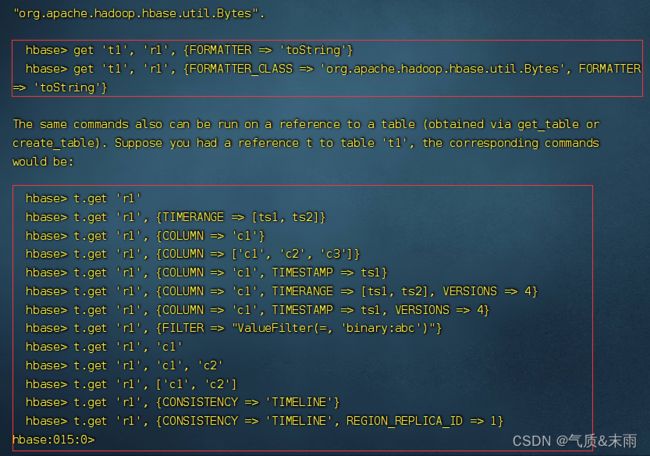
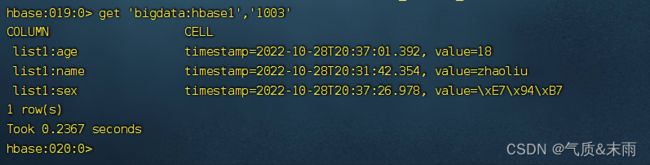
输入命令: get ‘bigdata:hbase1’ ,‘1003’ 直接get 表明加行号,所有的数据都读出来了,get只能读一行1的数据
要是想要指定查看哪些列的话,行号后面加上{COLUMN=>},里面是具体的列名,要是有多个的话,就用列表装起来
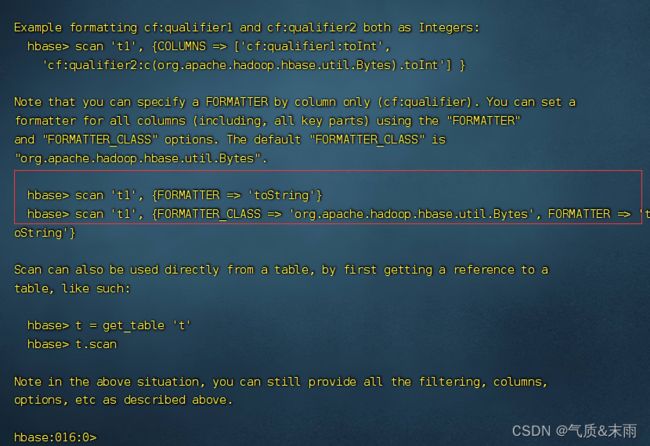
如果想要读取多行数据的话,get就不行了,得使用scan扫描
scan可以扫描整张表,所有的行和所有的列
输入命令: scan ‘bigdata:hbase1’
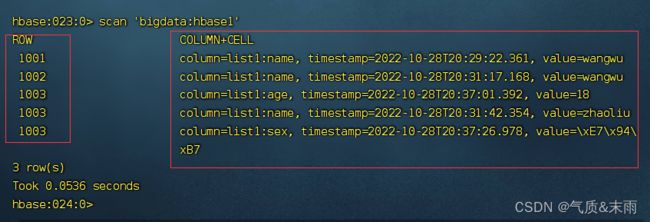
输入命令: scan ‘bigdata:hbase1’,{STARTROW=>‘1001’,STARTROW=>‘1002’} ,可以指定扫描从哪里到哪里

三、删除与版本介绍
删除数据的方法有两个: delete 和 deleteall
这里就要涉及当初创建表的时候,设置的维护版本的问题
- delete 表示删除一个版本的数据,即为1个cell ,不填写版本,默认删除最新的那一个版本,他的意思是,VERSIONS=>3 ,要是设置的时候维护的版本号是3的话,然后第一次name设置的zahngsan,第二次name设置的是lisi,要是删除的话就是lisi,然后就会变成张三,只会删除最近的那个时间戳.
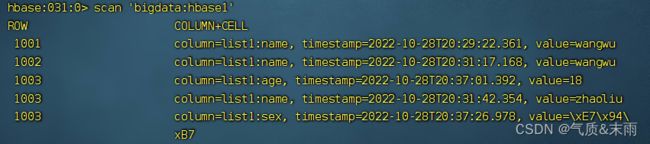
delete ‘bigdata:hbase1’,‘1001’,‘list1:sex’ delete 加 表名加行名加 列名 删除sex列
![]()
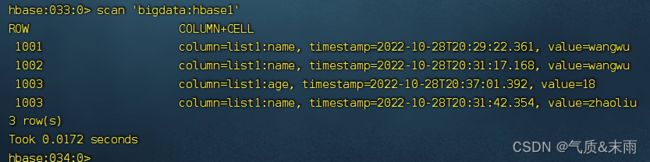
删除之后,再次查看 1003 行的,sex列已经没有了,因为这里的VERSIONS设置的是1
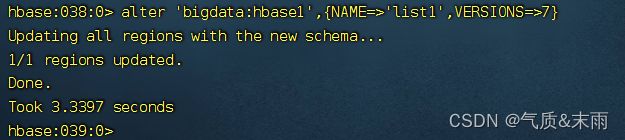
把列族list1的版本号改为7,然后下面读取多个版本的数据
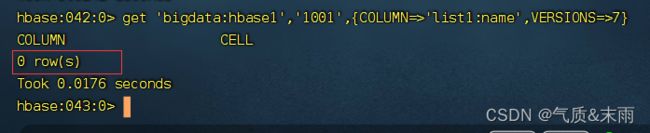
查看一行的多个版本的数据,COLUNM是列,VERSIONS=>7,读取的是7个版本的数据,但是具体是多少,还是要看当时创建列族的时候,版本号是多少

2) deleteall 表示删除所有版本的数据,即为当前行,当前列的多个cell。(执行命令会标记数据为要删除,不会直接将数据彻底删除,删除数据只在特定的时期清理磁盘时进行)
输入命令: deleteall ‘bigdata:hbase1’,‘1001’,‘list1:name’ 删除这个列所有的版本数据

再次查看这个1001 行 name的数据就为空了
四、Hbase Java API操作
package org.example;
import com.jcraft.jsch.IO;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import static org.example.HBaseDemoo.existsTable;
public class test_hbase {
private static Connection connection;
private static String nameSpaceName;
//连接Hbase
static{
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","master,slave1,slave2");
try {
System.out.println("hello world!");
connection = ConnectionFactory.createConnection(conf);
System.out.println("Hello word2!");
}catch (IOException e){
e.printStackTrace();
}
}
//创建表空间
public static void createNameSpace(String nameSpaceName) throws Exception{
if (nameSpaceName == null || nameSpaceName.equals("")){
System.out.println("nameSpace 名字不能为空");
return;
}
Admin admin = connection.getAdmin();
NamespaceDescriptor.Builder builder = NamespaceDescriptor.create(nameSpaceName);
NamespaceDescriptor namespaceDescriptor = builder.build();
try{
admin.createNamespace(namespaceDescriptor);
System.out.println("namespace 创建成功!");
}catch (NamespaceExistException e){
System.err.println(nameSpaceName + "名字已经存在!");
}finally {
admin.close();
}
}
//创建表
public static void createTable(String nameSpaceName,String tableName,String ... cfs) throws Exception{
if(existsTable(nameSpaceName, tableName)){
System.err.println((nameSpaceName == null || nameSpaceName.equals("")? "default" : nameSpaceName) + ":" + tableName + "表已存在?");
return ;
}
Admin admin = connection.getAdmin();
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf(nameSpaceName,tableName));
if (cfs==null || cfs.length <= 1){ //cfs 列族
System.err.println("至少指定一个列族");
}
assert cfs != null;
for (String cf:cfs){
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(cf));
ColumnFamilyDescriptor columnFamilyDescriptor = columnFamilyDescriptorBuilder.build();
tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptor);
}
TableDescriptor tableDescriptor = tableDescriptorBuilder.build();
admin.createTable(tableDescriptor);
byte [][] splitKeys= new byte[4][];
splitKeys[0] = Bytes.toBytes("1000");
splitKeys[1] = Bytes.toBytes("2000");
splitKeys[2] = Bytes.toBytes("3000");
splitKeys[3] = Bytes.toBytes("4000");
// ['1000','2000','3000','4000']
admin.createTable(tableDescriptor,splitKeys);
}
//判断表是否存在
public static boolean exisTable(String nameSpaceName,String tableName) throws Exception{
Admin admin = connection.getAdmin();
return admin.tableExists(TableName.valueOf(nameSpaceName, tableName));
}
//put
//里面的次数,按顺序依次为:表空间,表,行号,列族,列名,value
public static void putData(String nameSpaceName,String tableName,String rowkey,String cf,String cl,String value) throws Exception{
Table table = connection.getTable(TableName.valueOf(nameSpaceName,tableName));
Put put = new Put(Bytes.toBytes(rowkey));
put.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cl),Bytes.toBytes(value));
table.put(put);
table.close();
}
//delete
//里面的参数,按顺序依次是:表空间,表,行号,列族,列名
public static void deleteData(String nameSpaceName,String tableName,String rowkey,String cf,String cl) throws Exception{
Table table = connection.getTable(TableName.valueOf(nameSpaceName,tableName));
Delete delete = new Delete(Bytes.toBytes(rowkey));
delete.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cl));
table.delete(delete);
table.close();
}
//get
//里面的参数,按顺序依次是:表空间,表,行号,列族,列名
public static void getData(String nameSpaceName,String tableName,String rowkey,String cf, String cl) throws Exception {
Table table = connection.getTable(TableName.valueOf(nameSpaceName,tableName));
Get get = new Get(Bytes.toBytes(rowkey));
get.addFamily(Bytes.toBytes(cf));
get.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cl));
Result result = table.get(get);
Cell[] cells = result.rawCells(); //
for (Cell cell : cells) { //通过CellUtil 这个工具得到1001行下的数据,rowkey加上列族加上列 得到的就是那个值,所以才要用CellUtil取出来
String cellString = Bytes.toString(CellUtil.cloneRow(cell)) + " : " +
Bytes.toString(CellUtil.cloneFamily(cell)) + " : " +
Bytes.toString(CellUtil.cloneQualifier(cell))+ " : " +
Bytes.toString(CellUtil.cloneValue(cell));
System.out.println(cellString);
}
table.close();
}
//scan
//里面的参数依次是,表空间,表,开始行,终止行
public static void scanData(String nameSpaceName,String tableName,String startRow, String stopRow) throws Exception {
Table table = connection.getTable(TableName.valueOf(nameSpaceName,tableName));
Scan scan = new Scan();
//scan.withStartRow(Bytes.toBytes(startRow));
//scan.withStopRow(Bytes.toBytes(stopRow));
scan.withStartRow(Bytes.toBytes(startRow)).withStopRow(Bytes.toBytes(stopRow));
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
String cellString = Bytes.toString(CellUtil.cloneRow(cell)) + " : " +
Bytes.toString(CellUtil.cloneFamily(cell)) + " : " +
Bytes.toString(CellUtil.cloneQualifier(cell))+ " : " +
Bytes.toString(CellUtil.cloneValue(cell));
System.out.println(cellString);
}
System.out.println("-----------------------------------------------");
}
table.close();
}
public static void main(String[] args) throws Exception{
//createNameSpace("HIVE");
createTable("HIVE","hive2","h1","h2");
//putData("HIVE","hive","1001","h1","name","wangwu");
//deleteData("HIVE","hive","1001","h1","name"
//getData("HIVE","hive","1001","h1","name");
//scanData("HIVE","hive","1001","1001");
}
}