决策树理论
这个文本讨论了决策树模型中的基尼系数。当数据集的所有数据属于同一类时,基尼系数为0,因为此时无需进行分类,已经属于同一类别。因此,选项B是正确的。
决策树是一种用于分类和预测的机器学习模型。基尼系数是衡量数据集纯度的指标,用于衡量数据集中不同类别之间的差异程度。在决策树中,基尼系数用于选择最佳的分割点,以将数据集分成不同的类别。当基尼系数为0时,表示数据集已经是纯的,不需要进行进一步的分类。
因此,当数据集的所有数据属于同一类时,基尼系数为0。
http://172.30.211.4/assignment/index.jsp
2.Kmeans 是一种无监督学习的聚类算法,它不能直接应用于文本分类任务。相比之下,决策树、支持向量机、KNN 等方法都可以被用来解决文本分类问题。
使用
C.分析客户性别与购物偏好的关系 更适合使用决策树进行预测。决策树算法常用于分类和回归问题,特别是在特征较多、数据量较大时表现较为优秀。在客户性别与购物偏好之间的问题中,可以通过决策树模型来查找和了解不同性别的购物习惯差异,并基于这些差异来为目标客户推荐更合适的产品或服务。而针对微博用户情感与电影票房的关系和股票未来价格的预测问题,可能需要考虑更复杂的机器学习算法和更全面的数据特征来进行预测。针对银行客户流失预测问题,则可以利用分类算法和回归算法,如逻辑回归、随机森林等进行建模预测。
指标
. 决策树规则的数目不是决策树的性能评价指标之一。准确率和召回率为分类算法中常用的性能评价指标,ROC曲线下的面积AUC为二分类问题中比较重要的指标。而决策树规则的数目仅仅反映了生成决策树时选择的特征数量和分裂节点的数量,无法直接反映预测结果的准确性或可解释性。
基尼系数
当数据集的所有数据均匀分布时,基尼系数最大为0.5。因此,选项C是正确的答案。在二分类问题中,基尼系数衡量了当随机选择两个样本时它们被错分到不同类别的概率,值越小表示数据集纯度越高,模型分类效果越好。而当分类问题中各类别样本数完全相等时,基尼系数最大。

选项C不正确。决策树模型是一种基于树形结构进行分类的机器学习模型,具有可解释性和易理解等优点。但是,当决策树趋向于过度匹配训练数据时,就会发生过拟合现象,导致较差的泛化性能。因此,需要采用剪枝等技术来防止决策树过拟合。
其他选项都是正确的:
A、决策树的划分依据可用熵、信息增益、信息增益比等指标,以衡量在划分后样本的纯度变化情况,选项A正确,而信息熵度量了一个事件的不确定度,可以用于评估划分前后数据集的无序程度。
B、决策树的划分依据也可用基尼系数或Gini指数,表示随机抽取样本被错误地分类到不同的类别的概率,值越小表示分类效果越好。
D、决策树的深度表示从根节点到叶节点的最长路径所经过的节点数,决策树的叶节点数表示所有的决策路径数,在训练决策树模型时需要关注这些参数选择最优的模型

选项C不是决策树建立过程的停止准则。通常来说,在构建决策树的过程中,需要不断地选择最优的划分特征、计算信息增益或其他评价指标、生成子节点等操作,直到满足某个停止准则才会停止并输出决策树模型。
常用的停止准则包括:
A、达到了预先设定的最大树深度:停止扩展新的节点,防止过度拟合。
B、达到了预先设定的叶节点数量:停止扩展新的节点,防止过度拟合。
C、所有特征都遍历完不是停止准则,而是一个正常的构建流程,该步骤是为了找到最佳的特征进行分类。
D、若分支下全部数据都属于统一类别,则停止分裂,输出叶节点,并将该类别作为该叶节点的预测结果。

第一个说法正确,决策树是利用样本的属性作为节点,用属性取值作为分支的树结构,可以将样本进行分类预测。
第二个说法错误,决策树方法通常用于分类、回归等任务,而关联规则挖掘则是一种基于频繁项集的数据挖掘方法,两者是不同的技术路线。关联规则挖掘通过发现物品之间的关联性,来寻找频繁出现的组合规则,例如购买了A商品的人更可能购买B商品,帮助企业制定推荐策略;而决策树方法则是在已有的训练样本上构建分类模型,以便对新的未知样本进行分类预测,例如预测客户是否会流失等。

计算基尼系数
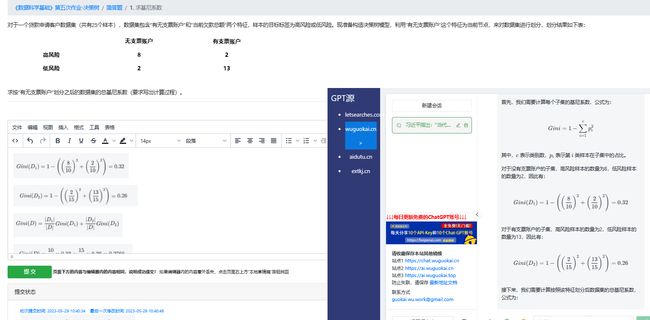
【问题描述】
本题所用数据来自中国知网论文《基于基尼系数的决策树在涉恐情报分析中的应用》,其中特征变量有四个,分别为Thought-tendency(思想趋势)、gender(性别)、Special-behavior-trajectory(特殊行为轨迹)、Tobacco-alcohol(烟酒),目标变量为Terrorism(是否重点涉恐),请用决策树算法构建一个重点涉恐人员识别模型。
要求:
(1)读入kbfz.csv文件;数据集下载:kbfz.csv
(2)初步了解数据集,显示数据集的形状和前5行的内容;
(3)以Thought-tendency、gender、Special-behavior-trajectory、Tobacco-alcohol为特征,Terrorism为目标变量;
(4)划分训练集和测试集,测试集数据占30%,random_state=0;
(5)用决策树算法建立分类模型,模型参数不需设置;
(6)显示分类准确率的值
【输入形式】
【输出形式】
(18, 5)
Thought-tendency gender Special-behavior-trajectory Tobacco-alcohol Terrorism
0 1 1 0 0 0
1 0 1 0 0 0
2 0 1 0 0 0
3 2 1 0 0 0
4 2 1 0 1 0
模型准确率为: 0.8333333333333334
【提示1】书写代码时,在程序起始处加入如下代码处理打印输出的警告信息:
import os
import sys
fd = os.open('/dev/null',os.O_WRONLY)
os.dup2(fd,2)
【提示2】读入kbfz.csv文件之后,加上如下代码保证打印输出格式正确:
pd.set_option('display.max_columns', None)