Hadoop大数据分析技术(伪分布式搭建)
一.安装JDK和配置SSH免密登录
(1)准备软件
(2)解压压缩包
tar -zxvf jdk-8u221-linux-x64.tar.gz
(3)在此处我们配置系统环境变量,使用命令:
vim /etc/profile
(4)在最后加入以下两行内容:
export JAVA_HOME=/root/software/jdk1.8.0_221 # 配置Java的安装目录
export PATH=$PATH:$JAVA_HOME/bin # 在原PATH的基础上加入JDK的bin目录
(5)让配置文件立即生效,使用如下命令:
source /etc/profile
2. 配置SSH免密登录
(1)下载SSH服务并启动
SSH服务(openssh-server和openssh-clients)已经为大家下载好,所以此处直接启动即可:
SSH服务启动成功后,默认开启22(SSH的默认端口)端口号,可以使用以下命令进行查看:
netstat -tnulp

(2)首先生成密钥对,使用命令:
ssh-keygen
## 或者
ssh-keygen -t rsa上面一种是简写形式,提示要输入信息时不需要输入任何东西,直接回车三次即可。
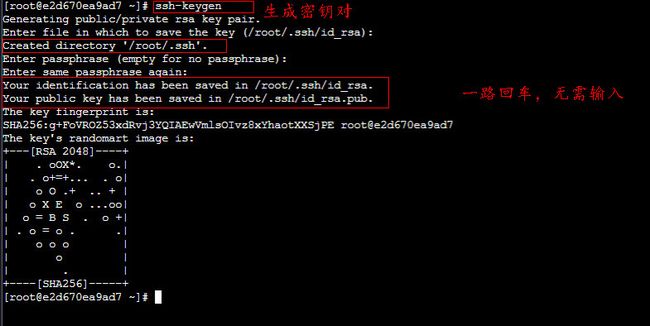
从打印信息中可以看出,私钥 id_rsa 和公钥 id_rsa.pub 都已创建成功,并放在 /root/.ssh 目录中:

(3)将公钥放置到授权列表文件 authorized_keys中,使用命令:
cp id_rsa.pub authorized_keys(4)修改授权列表文件 authorized_keys 的权限,使用命令:
chmod 600 authorized_keys(5)验证免密登录是否配置成功,使用如下命令:
sshlocalhost
## 或者
ssh e2d670ea9ad7
## 或者
ssh10.141.0.42(6)远程登录成功后,若想退出,可以使用exit命令。
二.搭建HDFS伪分布式集群
成功搭建HDFS伪分布式集群,具体步骤如下:
- 解压hadoop2.7.7安装包
- 配置环境变量hadoop-env.sh
- 配置核心组件core-site.xml
- 配置文件系统hdfs-site.xml(伪分布式的核心步骤)
- 配置Hadoop系统环境变量
- 格式化文件系统
- 脚本一键启动HDFS集群
- 查看进程启动情况
- 通过UI查看HDFS运行状态
hadoop伪分布式搭建教程_哈都婆的博客-CSDN博客
通过UI查看HDFS运行状态
通过本机的浏览器访问http://localhost:50070或http://本机IP地址:50070查看HDFS集群状态。
三.搭建YARN伪分布式集群
成功搭建YARN伪分布式集群,具体步骤如下:
- 配置环境变量yarn-env.sh
- 配置计算框架 mapred-site.xml
- 配置 YARN 系统 yarn-site.xml
- 脚本一键启动YARN集群
- 查看进程启动情况
- 通过UI查看YARN运行状态
1. 配置环境变量yarn-env.sh
使用如下命令打开“yarn-env.sh”文件:
vim /root/software/hadoop-2.7.7/etc/hadoop/yarn-env.sh找到JAVA_HOME参数位置,将前面的#去掉,将其值修改为本机安装的JDK的实际位置。
2. 配置计算框架mapred-site.xml
在$HADOOP_HOME/etc/hadoop/目录中默认没有该文件,需要先通过如下命令将文件复制并重命名为“mapred-site.xml”:
cp mapred-site.xml.template mapred-site.xml接着,打开“mapred-site.xml”文件进行修改:
vim /root/software/hadoop-2.7.7/etc/hadoop/mapred-site.xml将下面的配置内容添加到
mapreduce.framework.name yarn 3. 配置YARN系统yarn-site.xml
使用如下命令打开该配置文件:
vim /root/software/hadoop-2.7.7/etc/hadoop/yarn-site.xml将下面的配置内容加入
yarn.nodemanager.aux-services mapreduce_shuffle 4. 脚本一键启动YARN集群
start-yarn.sh5. 查看进程启动情况
在本机上执行 jps 命令查看进程启动情况。
6. 通过UI查看YARN运行状态
通过本机的浏览器访问http://localhost:8088或http://本机IP地址:8088查看YARN集群状态。
四.HDFS的shell操作(ls\mkdir\cp\mv\rm)
HDFS的常用Shell操作
(1)ls命令
ls命令用于查看指定路径的当前目录结构,类似于Linux系统中的ls命令,其语法格式如下:
hadoop fs -ls [-d] [-h] [-R] 其中,各项参数说明如下:
- -d:将目录显示为普通文件。
- -h:使用便于操作人员读取的单位信息格式。
- -R:递归显示所有子目录的信息。
(2)mkdir命令
mkdir命令用于在指定路径下创建子目录,其中创建的路径可以采用URI格式进行指定,与Linux命令mkdir相同,可以创建多级目录,其语法格式如下:
hadoop fs -mkdir [-p] 其中,-p参数表示创建子目录来先检查路径是否存在,如果不存在,则创建相应的各级目录(即创建多级目录,级联创建)。
(3)put命令
put命令用于将本地系统的文件或文件夹复制到HDFS上,其语法格式如下:
hadoop fs -put [-f] [-p] 其中各项说明如下:
- -f:覆盖目标文件。
- -p:保留访问和修改时间、权限。
(4)get命令
get命令用于将HDFS的文件或文件夹复制到本地文件系统上,其语法格式如下:
hadoop fs -get [-p] [-ignoreCrc] [-crc] ... 其中各项说明如下:
- -p:保留访问和修改时间、权限。
- -ignoreCrc:跳过对下载文件的CRC检查。
- -crc:为下载的文件写的CRC校验和,在本地文件系统生成一个.xxx.crc的校验文件。
(5)cp命令
cp命令用于将指定文件从 HDFS 的一个路径(源路径)复制到 HDFS 的另外一个路径(目标路径)。这个命令允许有多个源路径,此时目标路径必须是一个目录。其语法格式如下:
hadoop fs -cp [-f] [-p] ... 其中各项说明如下:
- -f:覆盖目标文件。
- -p:保留访问和修改时间、权限。
(6)mv命令
mv命令用于在HDFS目录中移动文件,不允许跨文件系统移动文件(也就是只能在HDFS分布式文件系统中,cp命令也一样(区别于put和get命令))。其语法格式如下:
hadoop fs -mv ... (7)rm命令
rm命令用于在HDFS中删除指定文件或文件夹。其语法格式如下:
hadoop fs -rm [-f] [-r|-R] [-skipTrash] 其中各项说明如下:
- -f:覆盖目标文件。
- -r|-R:递归删除目录。
- -skipTrash:绕过回收站(如果已启用),立即删除指定的文件或文件夹。
(8)rmdir命令
rmdir命令用于删除HDFS上的空目录。其语法格式如下:
hadoop fs -rmdir
文件操作
(1)cat命令
cat命令用于将路径指定文件的内容输出到stdout。其语法格式如下:
cat命令可以将一个或多个文件的内容输出到标准输出(stdout)。例如,要将文件example.txt的内容输出到stdout,可以使用以下命令:
cat example.txt
如果要将多个文件的内容合并并输出到stdout,可以将它们的文件名作为参数传递给cat命令,如下所示:
cat file1.txt file2.txt file3.txt
这将输出file1.txt、file2.txt和file3.txt的内容,按顺序合并在一起,并输出到stdout。
hadoop fs -cat [-ignoreCrc] (2)tail命令
tail命令用于将指定文件最后1K字节的内容输出到(一个文件)stdout,一般用于查看日志。其语法格式如下:
hadoop fs -tail [-f] 其中,-f 参数用于显示文件增长时附加的数据。
(3)appendToFile命令
appendToFile 命令用于追加一个或多个文件内容到已经存在的文件末尾,其语法格式如下:
hadoop fs -appendToFile ... 注意:HDFS文件不能进行修改,但是可以进行追加。
(4)getmerge命令
getmerge命令用于合并下载多个文件,指定一个源目录和一个目标文件,将源目录中所有的文件合并并排序地连接成本地的一个目标文件。其语法格式如下:
hadoop fs -getmerge [-nl] 其中,-nl参数用于在每个文件的末尾添加一个换行符。
(5)chmod命令
chmod命令用于改变文件的权限,命令的使用者必须是文件的所有者或者超级用户。其语法格式如下:
hadoop fs -chmod [-R] PATH其中,-R参数将使改变在目录结构下递归进行。
(6)chown命令
chown命令用于改变文件的拥有者或所属组,命令的使用者必须是文件的所有者或者超级用户。其语法格式如下:
hadoop fs -chown [-R] [OWNER][:[GROUP]] PATH其中,-R参数将使改变在目录结构下递归进行。
(7)count命令
count命令用于统计指定目录下的目录数、文件数和字节数。其语法格式如下:
hadoop fs -count [-h] 其中,-h参数使用便于操作人员读取的单位信息格式。
(8)df命令
df命令用于统计文件系统(也就是HDFS文件系统)的容量、可用空间和已用空间信息。其语法格式如下:
hadoop fs -df [-h] [ ...] 其中,-h参数使用便于操作人员读取的单位信息格式。
(9)du命令
du命令用于显示指定目录下所有文件和文件夹的大小,或者当只指定一个文件时,显示此文件的大小。其语法格式如下:
hadoop fs -du [-s] [-h] 其中各项说明如下:
- -s:不显示指定目录下每个单独文件的大小,只统计目录所占用空间的总大小。
- -h:使用便于操作人员读取的单位信息格式。
-c:在显示每个目录的大小之后,显示它们的总和。
例如,要显示当前目录下所有文件和子目录的大小,并以人类可读的方式显示它们,可以使用以下命令:
du -h
如果要显示指定目录的总大小,而不显示子目录和文件的详细信息,可以使用以下命令:
du -s /path/to/directory
如果要显示指定目录及其子目录中所有文件和文件夹的总大小,并以人类可读的方式显示它们,可以使用以下命令:
du -h -c /path/to/directory
(10)setrep命令
setrep命令用于改变HDFS中文件的副本系数。其语法格式如下:
hadoop fs -setrep [-R] 其中,-R参数用于递归改变指定目录下所有文件的副本系数。
五.Eclipse连接Hadoop
在 Linux 下通过 eclipse 直接连接我们搭建的 Hadoop 集群,在 eclipse 中可以直接查看 Hadoop 集群的文件信息。
Linux下Eclipse连接Hadoop(1-7步)
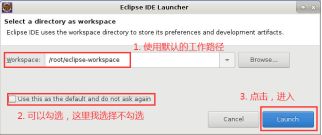
4.双击桌面的“Eclipse”图标启动Eclipse,首次启动Eclipse时,会弹出“Eclipse IDE Launcher”的对话框,提示设置Workspace的路径,设定好路径后,倘若勾选了“Use this as the default and do not ask again”,那么以后再启动时就不会有提示,直接进入默认工作空间:
5.进入Eclipse后,因为是首次打开,所以会看到一个“Welcome”欢迎页,将其关掉即可:
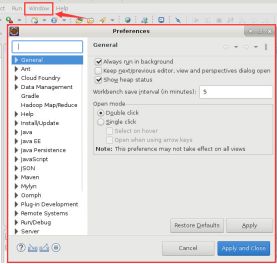
6.之后点击 “Window”->“Preferences”,此时会弹出如下对话框:
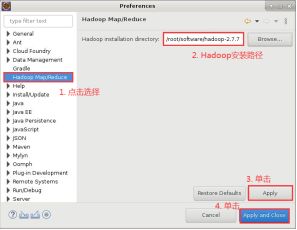
7.在对话框的左侧找到 “Hadoop Map/Reduce”选项,hadoop-2.7.7 的安装路径‘/root/software/hadoop-2.7.7‘配置在此选项中,然后依次单击 “Apply”->“Apply and Close”,如下图所示:
8.之后点击 “Window”->“Show View”->“Other”,弹出“Show View”对话框,选中“MapReduce Tools”下的“Map/Reduce Locations”,然后点击“Open”,关闭对话框:

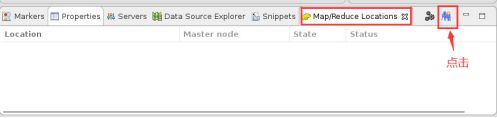
9.此时在Eclipse底部出现“Map/Reduce Locations”窗口,选择其右边的蓝色小象图标,如下所示:
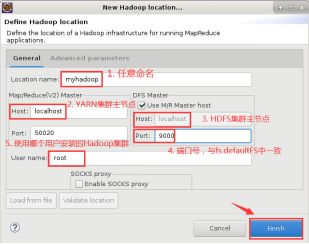
10.点击蓝色小象图标后,弹出“New Hadoop locaiton...”对话框,其中,“Location name”可以随意命名,这里我写成“myhadoop”;
之后是 “Map/Reduce(V2)Master”,将“Host”修改为YARN集群主节点的IP地址或主机名,这里我填写“localhost”;
之后再看 “DFS Master”,将“Host”修改为HDFS集群主节点的IP地址或主机名,将 “Port”修改为9000,与我们在core-site.xml中设置fs.defaultFS选项的一致;
最后是 “User name”,此处的用户名为搭建Hadoop集群的用户,即root。
设置完成,点击“Finish”即可。
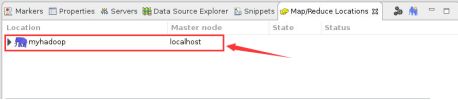
- 此时在Eclipse底部“Map/Reduce Locations”窗口中会出现如下信息:
- 之后选择 “File”->“New”->“Project”->“Map/Reduce Project”->“Next”,弹出“New MapReduce Project Wizard”对话框,为“Project name”起个名字,可以任意取名:
- 之后弹出“Open Associated Perspective”对话框,直接点击“No”即可:
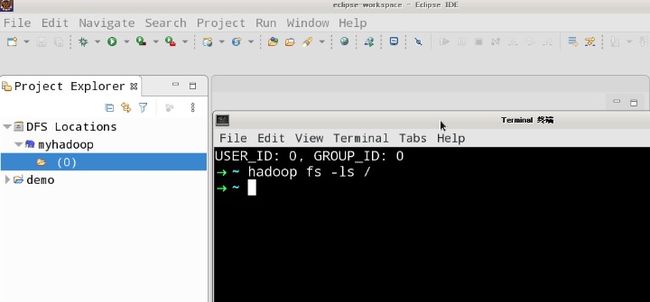
- 此时在Eclipse 的左侧“Project Explorer”下看到我们新创建的项目和 “DFS Locations”列表栏,打开此列表栏,验证Eclipse是否连接成功Hadoop,如果能正确显示HDFS上的文件和目录说明配置成功:
目录为空:
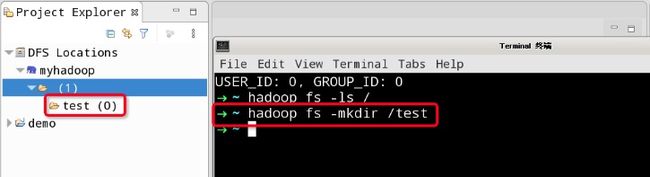
创建文件夹,刷新目录:hadoop fs -mkdir /test
- 其中,myhadoop为我们在第10步是为“Location name”随意取的名字;
- myhadoop下无名文件夹为HDFS集群的根目录(/,完整路径为
hdfs://localhost:9000/); - 再往下一层的tmp和user为HDFS集群根目录下的文件夹,若是新搭建的集群,还未来得及运行任何HDFS Shell操作或MapReduce程序,根目录下是空的,即没有任何的文件或文件夹。
后续请关注跟新
9.Java API操作HDFS(查看目录下文件信息)
10.WordCount 程序编写