Fast-BEV代码复现实践
Fast-BEV代码复现实践,专业踩坑
最近在研究一些BEV视觉感知算法,这里记录一下Fast-BEV代码复现实践,专业踩坑^_^
理论这里就不详细介绍,详情见原作者论文Fast-BEV: A Fast and Strong Bird’s-Eye View Perception Baseline
其他csdn,知乎上理论讲解也比较详细。主要还是本人太菜,讲不了理论,这里只讲工程复现^_^
1 运行环境搭建
1.1 conda与cuda
- 采用conda管理python环境,毕竟方便,miniconda下载地址 安装步骤略
- 显卡驱动cuda,cudnn安装网上帖子多,为了省略篇幅,默认安装好了
- 大家具体不知道各种库版本号对应关系,就直接跟着抄作业,cuda-11.3.0, cudnn-8.6.0,python-3.8, torch-1.10.0 , mmopenlab相关库版本也一样,直接抄作业
- conda和pip换国内源, 百度搜一下,防止国内安装失败
1.2 构建python虚拟环境
- 大家不知道某个库的具体版本,就直接抄作业,跟我一致就行,后面就不再强调
- 构建python环境
python用3.8以上,3.7版本后续mmcv相关安装出了问题
conda create -n fastbev python=3.8
- 激活新环境
conda activate fastbev
- torch安装
cuda与torch版本查询 我用的torch-1.10.0
pip install torch==1.10.0+cu113 torchvision==0.11.0+cu113 torchaudio==0.10.0 -f https://download.pytorch.org/whl/torch_stable.html
- 安装mmcv相关库
由于fastbev出来很久了,而mmcv-full已经更新到2.x.x版本,改名为mvcc, fastbev还是用的 mmcv-full
- 安装fastbev所需的mmopenlab的相关包
# 安装mmcv-full安装时终端会卡住,不是卡住,是下载时间比较长,耐心等待
pip install mmcv-full==1.4.0
# 安装mmdet
pip install mmdet==2.14.0
# 安装mmdet
pip install mmsegmentation==0.14.1
1.3 下载FASTBEV源码
- 安装fastbev相关依赖
# 下载fastbev工程
git clone https://github.com/Sense-GVT/Fast-BEV.git
# 激活虚拟环境
conda activate fastbev
# 进入Fast-BEV
cd Fast-BEV
# 配置所需依赖包
pip install -v -e .
# or "python setup.py develop"
- 查看mmopenlab相关包版本号
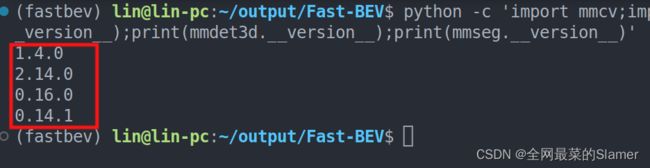
python -c 'import mmcv;import mmdet;import mmdet3d;import mmseg;print(mmcv.__version__);print(mmdet.__version__);print(mmdet3d.__version__);print(mmseg.__version__)'
显示版本号如下:依次为mmcv,mmdet,mmdet3d,mmseg对应的版本号
其他依赖包:
pip install ipdb
pip install timm
自此基本环境已经装好。
2 准备数据集
2.1 下载数据集
这里只介绍nuscenes数据集,nuscenes下载地址
由于nuscenes数据太大,这里只测试nuscense提供mini版本, 下载map跟mini,如下图点击红色框中US即可
- 下载
点击US,Aias都行

下载后得到2个压缩的文件

- 解压到当前目录
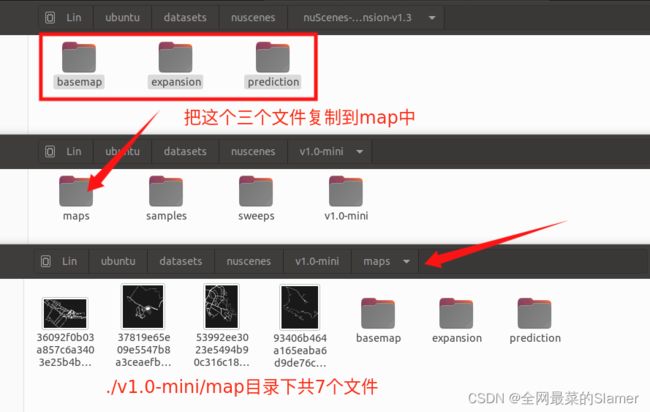
解压得到nuScenes-map-expansion-v1.3与v1.0-mini两个目录, 把nuScenes-map-expansion-v1.3中的三个文件复制到v1.0-mini/map目录下。最终得到新v1.0-mini目录,就行训练所需的数据集。
2.2 数据集转换为FastBEV支持格式
进入Fast-BEV工程目标, 创建data目录,然后将上面的v1.0-mini文件夹复制到./Fast-BEV/data下, 并将v1.0-mini重命名为nuscenes, 目录结构如下图所示:

因为使用的mini数据集, 转换时候加上参数--version 该数据未提供v1.0-test文件
如果使用全部的nuscenes数据可以不跟--version
- 运行create_data.py
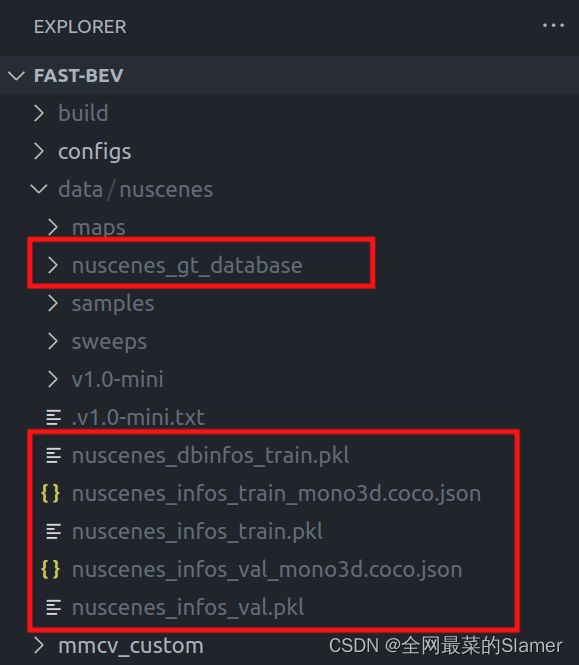
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --workers 10 --version v1.0-mini
执行后,产生下面红框中的文件
- 运行nuscenes_seq_converter.py
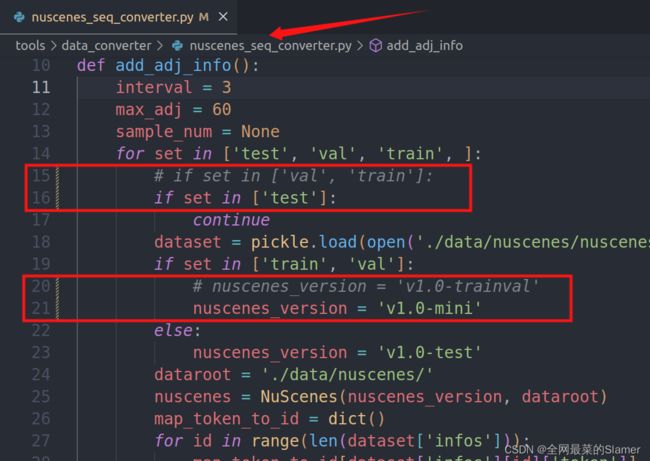
由于使用的mini数据集无test文件,需要修改nuscenes_seq_converter.py文件,找到代码15行和20行,修改如下:
修改后,运行
python tools/data_converter/nuscenes_seq_converter.py
生成 nuscenes_infos_train_4d_interval3_max60.pkl 与 nuscenes_infos_val_4d_interval3_max60.pkl 两个文件,
这两个文件就是训练需要的数据集,如下图所示:

3 训练
3.1 训练配置
- 下载预训练模型pretrained_models
下载地址 需要魔法上网
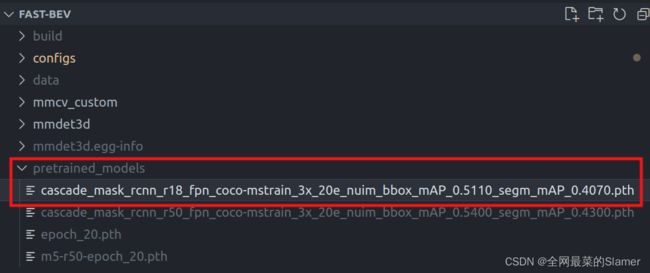
总体提供了r18,r34,r50三种残差网络模型。这里下载cascade_mask_rcnn_r18_fpn_coco-mstrain_3x_20e_nuim_bbox_mAP_0.5110_segm_mAP_0.4070.pth
这个需要跟配置文件一致。配置文件也是 r18, 下载后,新建一个pretrained_models目录放入其中。如下图所示:
- 修改配置文件
不修改配置文件可能出现3.2节的报错问题, 修改后,可直接跳过3.2小节
以 configs/fastbev/exp/paper/fastbev_m0_r18_s256x704_v200x200x4_c192_d2_f4.py,文件为例:(当然其他几个配置文件也行)

-
将该配置文件中的将SyncBN改成BN,将AdamW2换成Adam;
-
该配置文件中146行代码去掉注释; 147-150代码加上注释, 如下所示
file_client_args = dict(backend='disk')
# file_client_args = dict(
# backend='petrel',
# path_mapping=dict({
# data_root: 'public-1424:s3://openmmlab/datasets/detection3d/nuscenes/'}))
- 安装setuptools-58.0.4版本
conda install setuptools==58.0.4
- 配置文件中预训练模型地址修改, 代码331行,
load_from参数指向第1步下载的预训练模型地址,如果不知道相对路径,可以直接给绝对路径,我这里是相对路径
load_from = 'pretrained_models/cascade_mask_rcnn_r18_fpn_coco-mstrain_3x_20e_nuim_bbox_mAP_0.5110_segm_mAP_0.4070.pth'
- 训练
python tools/train.py configs/fastbev/exp/paper/fastbev_m0_r18_s256x704_v200x200x4_c192_d2_f4.py --work-dir work_dir --gpu-ids 0
参数说明
--gpu-ids 0代表gpu使用第1块。本机只有一块gpu
--work-dir 输出文件目录,包含日志等文件
其他参数详情建train.py中parse_args()函数
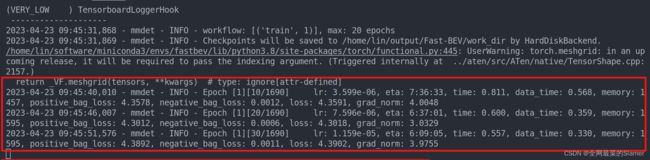
终端出现以下图中红色框中内容,代表训练已经成功运行, 具体训练周期epoch,batch_size等参数可以在fastbev_m0_r18_s256x704_v200x200x4_c192_d2_f4.py配置文件中修改
3.2 训练时报错
- 错误1

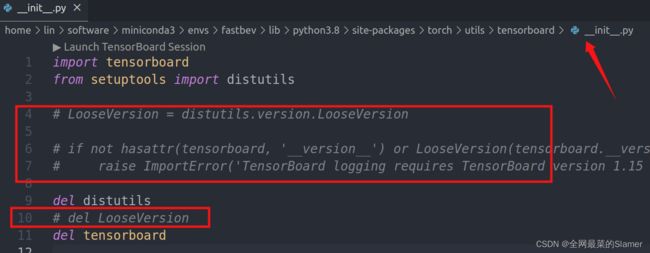
方案1: 点击红框上面一行,跳转到报错的文件中,注释掉使用distutils的代码
方案2:
AttributeError: module 'distutils' has no attribute 'version'
conda install setuptools==58.0.4
- 错误2

146行去掉注释,147-150加上注释
- 错误3

将SyncBN改成BN
- 错误4
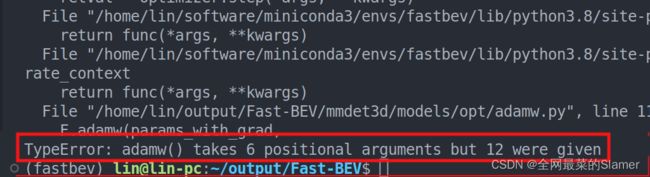
将AdamW2换成Adam
4 测试
4.1 测试推理
由于自己的显卡显存受限,训练的模型,测试结果不太理想,直接采用原作者提供的训练好的模型进行测试,下载地址
本人采用的fastbev_m0_r18_s256x704_v200x200x4_c192_d2_f4中epoch_20.pth, 下载地址
python tools/test.py configs/fastbev/exp/paper/fastbev_m0_r18_s256x704_v200x200x4_c192_d2_f4.py pretrained_models/epoch_20.pth --out output/result.pkl
- out 必须跟.pkl后缀。用来保存检测结果
--out 必须跟.pkl后缀。用来保存检测结果
--show 不要加,加上会报错,可能原作者未优化好
4.2 可视化
由于测试运行代码时,加入–show会报错,可以tools/misc/visualize_results.py把上一步的result.pkl生成视频流展示。
python tools/misc/visualize_results.py configs/fastbev/exp/paper/fastbev_m0_r18_s256x704_v200x200x4_c192_d2_f4.py --result output/result.pkl --show-dir show_dir
- 报错1:
assert len(_list) == len(sort)
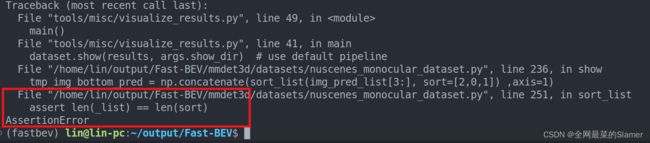
解决办法:Fast -BEV/mmdet3d/datasets/nuscenes monocular_dataset.py, 找到192行修改成193行样子:

- 报错2:
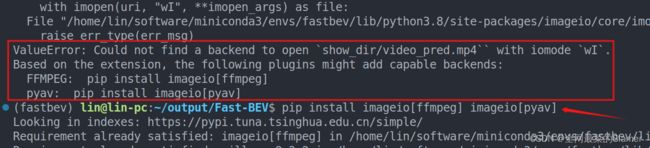
解决方法,安装这2个包:
pip install imageio[ffmpeg] imageio[pyav]
最后运行visualize_results.py ,生成video_pred.mp4与video_gt.mp4两个视频:
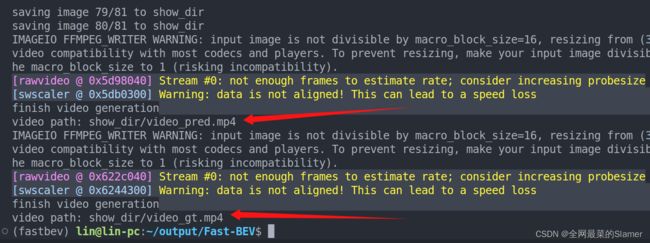
其中某一帧可视化:
发现m5-r18模型效果不是很好,很多只检测了个寂寞,大家可以尝试用m5-r50的epoch_20pth, 下载地址
参考文章
感谢各位大佬的辛勤付出, 瑞思拜^-^!!!
作者源码github地址
参考文章一
参考文章二
小伙伴们部署时遇到问题,欢迎各位小伙伴留言,欢迎进入bev交流釦裙472648720,大家一起学bev!
如果觉得文章可以,一键三连支持一波,瑞思拜^-^