linux 文本操作命令 awk 和 sed 的简单实用
目录
一、awk命令
1.1 awk的逻辑运算符
1.2 awk实现计算功能
1.3 awk中使用if
1.4 awk打印引号
二、sed 命令
2.1 处理特殊字符
2.2 替换全部
2.3 配指定行
一、awk命令
awk是对文本,按行进行处理。它可以将文本,按行以某一字符进行分割,分成不同的段,其中$0代表整个文本行,$n代表第n段,而默认的分隔符是”空格键”或”Tab键”。
Awk运作的模式如下:
![]()
简易例子如下:

如果要取出账号与登陆者的ip,且账号与ip之间用tab键隔开,则命令如下:
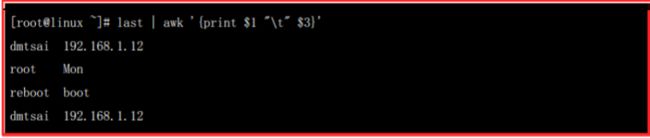
注意:
1、”\t”必须得用双引号引住,否则是识别不了的。
2、发现第2行和第4行有点乱,那是因为在原始的last中,第一段和第三段就是那样的,所以,用awk时,一定要确认好数据的格式。
3、发现上面命令中,并没有”条件类型”的限制,那是因为我们要处理文本的每一行。
awk的处理流程:

从上述流程知,awk是以行为一次处理的单位,而以字段为最小的处理单位,那么awk如何知道所处理的数据有几行、几栏呢,这就需要awk的内建变量帮忙啦
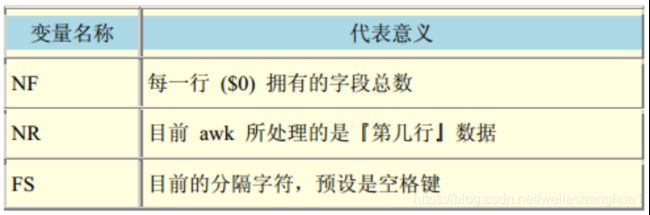
简易例子:
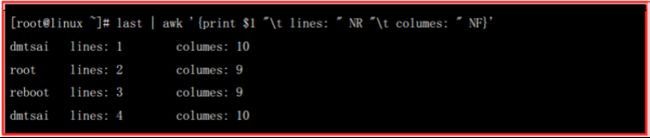
显然,输出是账户名、awk当前处理的哪一行、awk当前处理行的字段数。
注意:awk所有的动作都是用单引号引住的,所以用print打印时,非变量的文字部分,一定要用双引号引住,包括用printf。
1.1 awk的逻辑运算符
既然命令中可以写”条件类型”,那自然需要一些逻辑运算啦,如下:
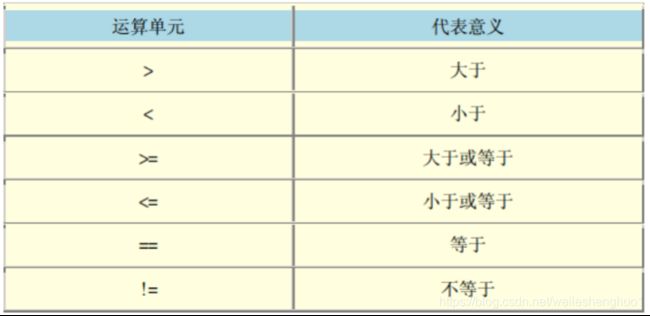
值得注意的是表格中没有=运算符,它和程序语言中一样,如果是直接给变量赋值,就是直接用的=,而不是’==’。
简易例子:
这个只是让你知道,passwd中的内容格式是什么,和下面的cat /etc/passwd 是不对应的。

显然,将文本行的分隔符改为了”:”,而且对于每一行,只有第三段的值<10,才输出第一个字段和第三个字段。但是奇怪的是,为什么第一行没有按指定的要求输出呢?
那是因为,在我们读入第一行时,那些变量$1,$2…… 还是以预设的空格为分隔,所以我们虽然定义了 FS=”:”,则仅能在第二行处理时才能生效,那么如何解决这个问题呢?
可以预先设定awk的变量,利用BEGIN这个关键词

注意:这个BEGIN 并不等价于”NR==1”,它表示在”NR==1”之前就进行处理了,相应的还有一个END呢。
1.2 awk实现计算功能
简易例子:
薪资数据表pay.txt如下:
Name 1st 2nd 3th
songbw 100 200 300
xiaosh 2 3 45
majf 7 8 9用awk 命令实现薪资统计
(base) localhost:~ songbw$ cat pay.txt |\
> awk 'NR==1 {printf "%10s %10s %10s %10s %10s\n", $1, $2, $3, $4, "Total"}
> NR >= 2 {total = $2 + $3 + $4; printf "%10s %10d %10d %10d %10.2f\n", $1, $2, $3, $4, total }'
Name 1st 2nd 3th Total
songbw 100 200 300 600.00
xiaosh 2 3 45 50.00
majf 7 8 9 24.00
显然,上述是算每个人三个月工资的总和。
注意:
1、

如上例子中,我是用的分号隔开的
2、格式化输出时,在printf的格式设定当中,务必加上’\n’,才能进行分行,而print 是不需要的!
3、与bash shell的变量不同,在awk当中,变量可以直接使用,不需要加$!
1.3 awk中使用if
awk的动作{}也支持if(条件)哦,上述子,可以更改如下:
(base) desktop-6rkqqec:fsdownload songbw$ cat pay.txt |\
> awk '{if(NR==1){printf "%10s %10s %10s %10s %10s\n", $1, $2, $3, $4, "Total"}}
> {if(NR >= 2){total = $2 + $3 + $4
> printf "%10s %10d %10d %10d %10.2f\n", $1, $2, $3, $4, total}}'
Name 1st 2nd 3th Total
songbw 100 200 300 600.00
xiaosh 2 3 45 50.00
majf 7 8 9 24.00简单小例子,帮助怎么写带if的awk:
awk -F: '{if($1>10) {print $1}}' /etc/passwd以后稍微参考下,就可以写简单的if语句
5、awk 写 if 的嵌套
grep "get msg 0000066666 4" 2020-04-11.txt|grep CProcessEventThread|awk 'BEGIN{FS="|" ; total=0; unknow=0; Tel=0; interPhone=0; IM=0; printf "%10s %10s %10s %10s %10s\n", "unknow", "Tel", "interPhone", "IM", "total"} {if($6==800002 && $12==4){total=total+1; {if($21==0){unknow=unknow+1}}; {if($21==1){Tel=Tel+1}}; {if($21==2){interPhone=interPhone+1}}; {if($21==3){IM=IM+1}}}} END{printf "%10d %10d %10d %10d %10d\n", unknow, Tel, interPhone, IM, total}'另外awk可以帮我们进行循环计算,这是属于高级课程,以后有需要再学吧。
1.4 awk打印引号
1、打印双引号
首先,awk 打印的字符串是要加引号的,如
awk '{print "songbw"}' generatorRecordings.sh
打印songbw这个字符串是要加引号的,那么正常逻辑打印双引号应该为 awk '{print """}' generatorRecordings.sh
但是出现错误:

提示没有终止的字符串,提示很正确,因为三个双引号,两个双引号之间是一个string,但是现在只有三个,也就是说有一个字符串没有写完,解决办法,打印出来的引号需要用\转义,如下:
awk '{print "\""}' generatorRecordings.sh
2、打印单引号
awk '{print "'\''"}' # 放大: awk '{print " ' \ ' ' " }'
使用一个双引号“”,然后在双引号里面加入两个单引号'',接着在两个单引号里面加入一个转义的单引号\',然后就可以输出单引号了。
例子:
awk '{print "'\''"}' generatorRecordings.sh
1.4 awk 传入外部参数
通过 awk -v 参数,例子如下:
脚本 testStatistics.sh 如下
#!/bin/sh
enterpriseID=$1
grep "get msg $enterpriseID 4" 2020-04-11.txt|grep CProcessEventThread|awk -v agentID=$2 'BEGIN{FS="|"; total=0; unknow=0; Tel=0; interPhone=0; IM=0; printf "%10s %10s %10s %10s %10s\n", "unknow", "Tel", "interPhone", "IM", "total"} {if($6==agentID && $12==4){total=total+1; {if($14==0){unknow=unknow+1}}; {if($14==1){Tel=Tel+1}}; {if($14==2){interPhone=interPhone+1}}; {if($14==3){IM=IM+1}}}} END{printf "%10d %10d %10d %10d %10d\n", unknow, Tel, interPhone, IM, total}'
例子中 agentID变量要在 awk 中使用,所以必须在 awk -v 后面对 agentID 进行赋值,否则awk语句内部是识别不了变量 agentID的
参考书籍及文章:
鸟哥的linux私房菜
http://phi.sinica.edu.tw/aspac/reports/94/94011/
http://linux.vbird.org/linux_basic/0330regularex/awk.pdf
二、sed 命令
文本test.txt中内容:
# flume.conf: A single-node Flume configuration
# Name the components on this agent
a3.sources = r1 a3.channels = c1
a3.sinks = k1
a3.channels = c1脚本try.sh中内容:
#!/bin/bash
i=4
sed 's/a3/a'$i'/' test.txt
执行脚本try.sh后的结果:



发现,每一行的第一个匹配的都进行了改变,并且打开test.txt后的内容和原来相比,并没有发生任何变化,因为
如果想让test.txt文本中发生改变,需要加上-i 命令参数,如下,将
sed 's/a3/a'$i'/' test.txt
改为
sed -i 's/a3/a'$i'/' test.txt
如果想让test.txt文本中所有匹配的都进行改变,需要加上/g,具体如下:
sed -i 's/a3/a'$i'/g' test.txt
sed具体用法如下:
sed 's/原字符串/替换字符串/'
2.1 处理特殊字符
单引号里面,s表示替换,三根斜线中间是替换的样式,特殊字符需要使用反斜线”\”进行转义,但是单引号”‘”是没有办法用反斜线”\”转义的,这时候只要把命令中的单引号改为双引号就行了,例如:
代码如下:
sed "s/原字符串包含'/替换字符串包含'/" //要处理的字符包含单引号
命令中的三根斜线分隔符可以换成别的符号,这在要替换的内容有较多斜线是较为方便,例如换成问号”?”:
代码如下:
sed 's?原字符串?替换字符串?' //自定义分隔符为问号2.2 替换全部
可以在末尾加g替换每一个匹配的关键字,否则只替换每行的第一个,例如:
代码如下:
sed 's/原字符串/替换字符串/g' //替换所有匹配关键字2.3 配指定行
例子:
sed '2s/原字符串/替换字符串/g' //替换第2行
sed '$s/原字符串/替换字符串/g' //替换最后一行
sed '2,5s/原字符串/替换字符串/g' //替换2到5行
sed '2,$s/原字符串/替换字符串/g' //替换2到最后一行2.4 去除空格
(base) ➜ mysql_case cat a.txt
project_id = 36
(base) ➜ mysql_case sed s/' '//g a.txt
project_id=36
(base) ➜ mysql_case所以说shell中需要去除空格时,可以考虑用sed
2.5 mac 中使用 sed 修改
我们知道,使用 sed 命令,如果想在原文修改,使用 -i 参数,但是 mac 系统还有一点,不一样,需要加入一个空格,否则会报错,如下:
(base) ➜ mysql_case cat a.txt
project_id = 36
(base) ➜ mysql_case
(base) ➜ mysql_case sed -i "s/36/41/g" a.txt
sed: 1: "a.txt": command a expects \ followed by text
(base) ➜ mysql_case sed -i '' "s/36/41/g" a.txt
(base) ➜ mysql_case cat a.txt
project_id = 41
(base) ➜ mysql_case需要加入一个空格,sed 的文件修改才能实现,我的系统是 mac pro 系统
2.6 sed使用shell中的变量
这个也是难了我一阵儿,当时就觉着,我写的 sed 命令没问题,为啥就替换不了呢,后来通过调试才发现,如果在shell 脚本中使用 sed,单引号中的shell 变量是无法识别的,需要把单引号换成双引号才行,如下例子,更换目录中 project_id 变量
#!/bin/sh
#filename=`ls ./insert_craftemplate`
#for file in $filename
#do
# echo $file
# mysql -h127.0.0.1 -uroot -psongbowei <参考文章:
[1] sed 中使用shell 变量