4. Response对象的7个属性
4. Response对象的7个属性
文章目录
- 4. Response对象的7个属性
-
- 1. Response对象的属性(属性=变量)
- 2. 网页源代码
- 3. 人工查看网页源代码
- 4. Response对象的7个属性
- 5. 总结
1. Response对象的属性(属性=变量)
【代码示例】
# 1.导入库
import requests
# 2.定义url
url = 'https://music.163.com/'
# 3.发送请求,并把响应结果赋值给变量r
r = requests.get(url)
# 4.2 查看r的类型
print(type(r))
【终端输出】
通过requests库的get方法访问网页后返回了一个Response对象。
response[rɪˈspɒns]:响应。
Response对象即响应对象。
Response对象里面存的是服务器返回的所有信息,包括响应头,响应状态码等等。
其中,服务器返回的网页代码会存在Response对象的content和text两个属性里。
直接写在类里的变量称为类属性。
content和text就是类的2个属性。
我把content和text当做2个变量。
这2个变量存储的是网页的源代码。
【备注】
上述理解是我本人的认知,不一定准确,仅供大家参考。
2. 网页源代码
在互联网上浏览网页时,我们通常可以在浏览器中查看网页源代码。
网页源代码它是一种以纯文本形式展示网页内容的方式。
网页源代码包含了网页中使用的HTML、CSS、JavaScript等代码,以及各种标记、元素、属性等。
它代表了网页的本质内容,是网页在浏览器中渲染展示的基础。
网站源码也分为两种:静态网页和动态网页。
【静态网页】
静态源码如htmL。
片面的理解:静态网页就是所见即所得,网页的源代码和我们肉眼看到的内容是一致的。
【动态网页】
动态源码如:asP,PhP,JsP,.net,cgi。
片面的理解:动态网页中我们看到的内容很多在网页源代码中是没有的。
3. 人工查看网页源代码
【方法1】
-
在360浏览器中输入网址:
https://www.baidu.com/。 -
点击鼠标右键。
-
点击【查看网页源代码】。
【方法2】
-
在360浏览器中输入网址:
https://www.baidu.com/。 -
按【F12】快捷键。
-
点击【元素】。
得到的页面如下图所示:
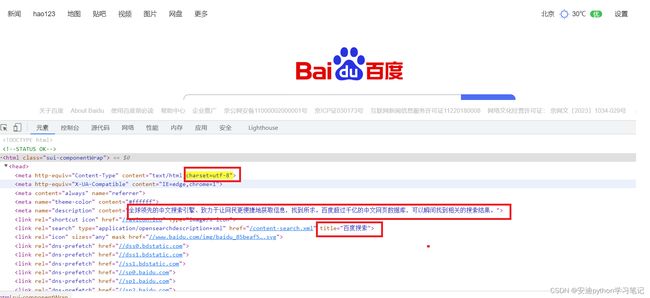
大家注意留意红色框里的内容。
charset=utf-8
charset [t’ʃɑ:set]:字符集,编码,字符编码。
utf-8是一种编码方式。
charset=utf-8表示该网页的编码方式为utf-8。
4. Response对象的7个属性
【代码示例】
# 1.导入库
import requests
# 2.定义url
url = 'https://www.baidu.com/'
# 3.发送请求,并把响应结果赋值给变量r
r = requests.get(url)
# Response对象的7个属性
print(r.status_code)
print(r.encoding)
print(r.apparent_encoding)
print(r.request)
print(r.url)
print(r.text)
print(r.content)
重点关注代码的后7行。
这里的r就表示一个Response对象。
r = Response对象
【属性1】
- r.status_code :响应状态码,返回值为200表示网络请求正常。
print(r.status_code)
【终端输出】
200
【属性2】
- r.encoding:编码方式,这里的encoding表示从HTTP header中
猜测的响应内容编码方式,特别注意有时候猜测的编码方式和网页本身的编码方式不一致。
print(r.encoding)
【终端输出】
ISO-8859-1
encoding [ɪnˈkəʊdɪŋ]:编码。
这里输出的ISO-8859-1也是一种编码方式。
是程序根据访问的网页猜测该网页的的编码方式为ISO-8859-1。
我们刚才手动查看过该网页的编码方式如下:
charset=utf-8表示该网页的编码方式为utf-8。
程序猜测的编码方式ISO-8859-1与原本的编码方式utf-8不一致。
这显然是程序猜错了。
不是所有的网页都会猜错。好像中文网页都会猜错。
猜错了编码方式我们看到的源代码和程序输出的源代码就不一致,下节会有讲解。
【属性3】
- r.apparent_encoding:从内容中分析出的响应内容编码方式(备选编码方式)。
apparent [əˈpærənt]:明显的,表面的。
encoding [ɪnˈkəʊdɪŋ]:编码。
print(r.apparent_encoding)
【终端输出】
utf-8
【属性4】
- request:请求对象,主要包括:r.request.url, r.request.method, r.request.headers。
requests [rɪˈkwests]:请求;要求。
method[ˈmeθəd]:方法。
headers:请求头。
【代码示例1】
print(r.request)
【终端输出】
【代码示例2】
print(r.request.url)
【终端输出】
https://www.baidu.com/
输出我们访问的网址连接。
【代码示例3】
print(r.request.method)
【终端输出】
GET
输出我们访问网页的方法get方法。
【代码示例4】
print(r.request.headers)
【终端输出】
{
'User-Agent': 'python-requests/2.26.0',
'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*',
'Connection': 'keep-alive'
}
输出网页的请求头信息(后面会讲解)。
【属性5】
- r.url:输出请求的网址链接。
print(r.url)
【终端输出】
https://www.baidu.com/
【属性6】
- r.text输出网页源代码,返回的数据类型为字符串类型。
print(r.text)
输出如下图所示:
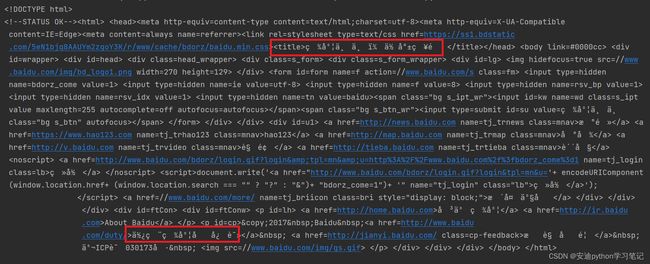
这里的输出理论上要跟我们手动查询的网页源代码一致才对。
但观察输出结果红色框中的代码,我们发现有很多乱码。
为什么会出现乱码呢?
这就是解码方式和编码方式不一致导致的。
【查看r.text数据类型】
print(type(r.text))
【终端输出】
重点关注r.text的数据类型为字符串类型。
【属性7】
- r.content输出网页源代码,返回的数据类型为bytes类型。
content [ˈkɑːntent]:内容。
print(r.content)
输出如下图所示:
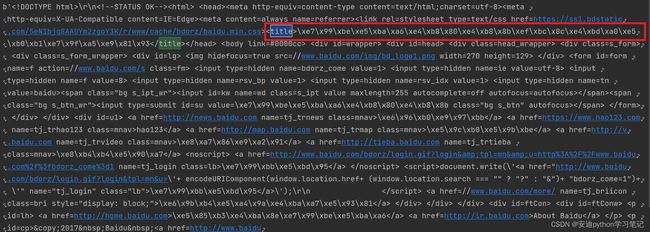
这里的输出跟我们手动查询的网页源代码也不一致。
这里的输出不是乱码,是二进制数据。
【查看r.content数据类型】
print(type(r.content))
【终端输出】
bytes:字节。
这里bytes可以理解成二进制数据。
重点关注r.content的数据类型为bytes类型。
为了方便后面的课程讲解,大家先对属性有个基础的认识。
怎样才能输出手动查看到的网页源代码呢,下节课讲解。
5. 总结
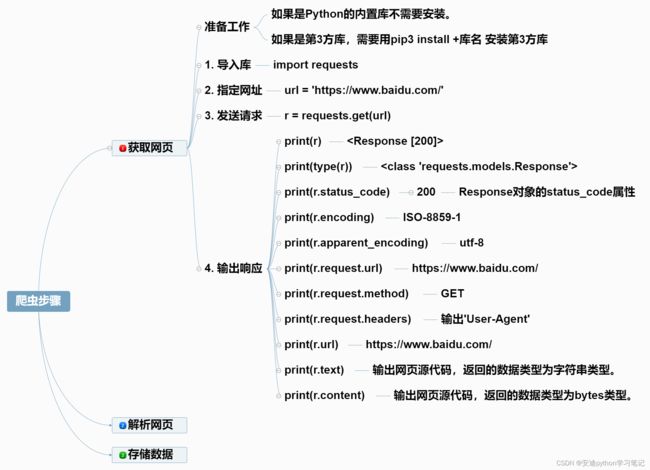
【代码总结】
# 1.导入库
import requests
# 2.定义url
url = 'https://www.baidu.com/'
# 3.发送请求,并把响应结果赋值给变量r
r = requests.get(url)
# Response对象的7个属性
print(r.status_code)
print(r.encoding)
print(r.apparent_encoding)
print(r.request.url)
print(r.request.method)
print(r.request.headers)
print(r.url)
print(r.text)
print(r.content)
【终端输出】
200
ISO-8859-1
utf-8
https://www.baidu.com/
GET
{
'User-Agent': 'python-requests/2.26.0',
'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*',
'Connection': 'keep-alive'}
https://www.baidu.com/
因太占篇幅,print(r.text)和print(r.content)的输出结果未我没有打印。