深入理解Linux虚拟内存管理(四)

系列文章目录
Linux 内核设计与实现
深入理解 Linux 内核(一)
深入理解 Linux 内核(二)
Linux 设备驱动程序(一)
Linux 设备驱动程序(二)
Linux 设备驱动程序(三)
Linux设备驱动开发详解
深入理解Linux虚拟内存管理(一)
深入理解Linux虚拟内存管理(二)
深入理解Linux虚拟内存管理(三)
深入理解Linux虚拟内存管理(四)
深入理解Linux虚拟内存管理(五)
文章目录
- 系列文章目录
- 一、启动分析
-
- 1、初始化内存
-
- (1)start_kernel
- (2)setup_arch
-
- 2.1 setup_memory
- 2.2 paging_init
- (3)mem_init
- 二、启动内存分配
-
- 1、初始化引导内存分配器
-
- (1)init_bootmem
- (2)init_bootmem_node
- (3)init_bootmem_core
- (4)总结
- 2、分配内存
-
- (1)保留大块区域的内存
-
- (a)reserve_bootmem
- (b)reserve_bootmem_core
- (c)总结
- (2)在启动时分配内存
-
- (a)alloc_bootmem
- (b)__alloc_bootmem
- (c)alloc_bootmem_node
- (d)__alloc_bootmem_node
- (e)__alloc_bootmem_core
- (f)总结
- 3、释放内存
-
- (1)free_bootmem
- (2)free_bootmem_core
- (3)总结
- 4、释放引导内存分配器
-
- (1)mem_init
-
- (a)⇐ set_max_mapnr_init
- (2)free_pages_init
- (3)one_highpage_init
- (4)free_all_bootmem
- (5)free_all_bootmem_core
-
- (a)⇐ mm.h
- (b)⇒ __free_page
- 二、页表管理
-
- 1、初始化页表
-
- (1)paging_init
- (2)pagetable_init
-
- (a)⇐ pgtable-2level.h
- (b)⇐ pgtable.h
- (c)⇐ page.h
- (d)pagetable_init
- (3)⇒ alloc_bootmem_low_pages
- (4)fixrange_init
- (5)kmap_init
-
- (a)⇐ fixmap.h
- (b)⇐ init_task.c
- (c)⇐ pgtable.h
- (d)kmap_init
- (6)⇒ zone_sizes_init
- 2、遍历页表
-
- (1)follow_page
- 3、⇔ 页表
-
- (1)pmd_alloc
-
- (a) ⇐ pgtable-2level.h
- (2)__pmd_alloc
-
- (a) ⇐ pgalloc.h
- 三、描述物理内存
-
- 1、初始化管理区
-
- (1)setup_memory
-
- (a)⇒ init_bootmem
- (b)⇒ register_bootmem_low_pages
- (c)⇒ reserve_bootmem
- (2)zone_sizes_init
- (3)free_area_init
- (4)free_area_init_core
-
- (a)⇒ alloc_bootmem_node
- (b)⇒ 初始化 mem_map
- (c)⇐ zone_t
- (d)⇒ wait_table_size
- (e)⇒ wait_table_bits
- (e)⇒ wait.h
- (f)⇒ mm.h
- (g)⇐ 概览
- (h)⇐ 伙伴算法
- (5)build_zonelists
-
- (a)⇐ mmzone.h
一、启动分析
1、初始化内存
(1)start_kernel
// init/main.c
asmlinkage void __init start_kernel(void)
{
// ...
setup_arch(&command_line);
// ...
mem_init();
kmem_cache_sizes_init();
pgtable_cache_init();
// ...
}
(2)setup_arch
// arch/i386/kernel/setup.c
void __init setup_arch(char **cmdline_p) {
// ...
max_low_pfn = setup_memory();
paging_init();
// ...
}
2.1 setup_memory
传送门
这个函数的调用图如图 2.3 所示。它为引导内存分配器初始化自身进行所需信息的获取。它可以分成几个不同的任务。
- 找到低端内存的 PFN 的起点和终点(min_low_pfn,max_low_pfn),找到高端内存的 PFN 的起点和终点(highstart_pfn,highend_pfn),以及找到系统中最后一页的 PFN。
- 初始化 bootmem_date 结构以及声明可能被引导内存分配器用到的页面。
- 标记所有系统可用的页面为空闲,然后为那些表示页面的位图保留页面。
- 在 SMP 配置或 initrd 镜像存在时,为它们保留页面。

2.2 paging_init
传送门
3.6 内核页表
用于完成页表收尾工作的对应函数是 paging_init()。x86 上该函数的调用图如图 3.4 所示。
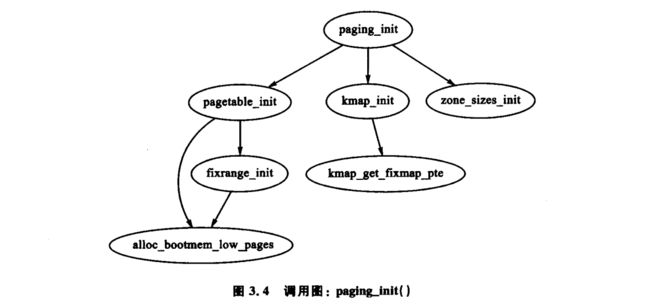
系统首先调用 pagetable_init() 初始化对应于 ZONE_DMA 和 ZONE_NORMAL 的所有物理内存所必要的页表。注意在 ZONE_HIGHMEM 中的高端内存不能被直接引用,对其的映射都是临时建立起来的。对于内核所使用的每一个 pgd_t,系统会调用引导内存分配器来分配一个页面给 PGD。
接下来,pagetable_init() 函数调用 fixrange_init() 建立固定大小地址空间,以映射从虚拟地址空间的尾部即起始于 FIXADDR_START 的空间。映射用于局部高级编程中断控制器(APIC),以及在 FIX_KMAP_BEGIN 和 FIX_KMAP_END 之间 kmap_atomic() 的原子映射。最后,函数调用 fixrange_init() 初始化高端内存映射中 kmap() 函数所需要的页表项。
在 pagetable_init() 函数返回后,内核空间的页表则完成了初始化,此时静态 PGD(swapper_pg_dir)被载入 CR3 寄存器中,换页单元可以使用静态表。
paging_init() 接下来的工作是调用 kmap_init() 初始化带有 PAGE_KERNEL 标志位的每个 PTE。最终的工作是调用 zone_sizes_init(),用于初始化所有被使用的管理区结构。
(3)mem_init
该函数负责消除启动内存分配器和与之相关的结构。

这个函数的功能相当简单。它负责计算高、低端内存的维度并向用户显示出信息消息。若有需要,还将运行硬盘的最终初始化。在 x86 平台,有关 VM 的主要函数是 free_pages_init()。
这个函数首先使引导内存分配器调用函数回收自身,UMA 结构中是调用 free_all_bootmem() 函数,NUMA 中是调用 free_all_bootmem_node() 函数。这两个函数都调用内核函数 free_all_bootmem_core() ,但是使用的参数不同。free_all_bootmem_core() 函数原理很简单,它执行如下任务。
- 对于这个节点上分配器可以识别的所有未被分配的页面:
- 将它们结构页面上的 PG_reserved 标志位清 0;
- 将计数器设置为 1;
- 调用 __free_pages() 以使伙伴分配器(下章将讨论)能建立释放列表。
- 释放位图使用的所有页面,并将这些页面交给伙伴分配器。
在这个阶段,伙伴分配器控制了所有在低端内存下的页面。free_all_bootmem() 返回后首先清算保留页面的数量。高端内存页面由 free_pages_init() 负责处理。但此时需要理解的是如何分配和初始化整个 mem_map 序列,以及主分配器如何获取页面。图 5.3 显示了单节点系统中初始化低端内存页面的基本流程。free_all_bootmem() 返回后,ZONE-NORMAL 中的所有页面都为伙伴分配器所有。为了初始化高端内存页面,free_pages_init() 对 highstart_pfn 和 highend_pfn 之间的每一个页面都调用了函数 one_highpage_init() 。此函数简单将 PG_reserved 标志位清 0 ,设置 PG_highmem 标志位,设置计数器为 1 并调用 __free_pages() 将自已释放到伙伴分配器中。这与 free_all_bootmem_core() 操作一样。
此时不再需要引导内存分配器,伙伴分配器成为系统的主要物理页面分配器。值得注意的是,不仅启动分配器的数据被移除,它所有用于启动系统的代码也被移除了。所有用于启动系统的初始函数声明都被标明为 __init,如下所示:
unsigned long __init free_all_bootmem(void)
连接器将这些函数都放在 init 区。x86 平台上 free_initmem() 函数可以释放 __init_begin 到 __init_end 的所有页面给伙伴分配器。通过这种方法,Linux 能释放数量很大的启动代码所使用的内存,已不再需要启动代码。

传送门 mem_init
二、启动内存分配
1、初始化引导内存分配器
(1)init_bootmem
// mm/bootmem.c
// 这是容易混淆的地方。参数 pages 实际上是该节点可寻址内存的 PFN 末端,而不是
// 按名字的意思:页面数。
unsigned long __init init_bootmem (unsigned long start, unsigned long pages) {
// 如果没有依赖于体系结构的代码,则设置该节点的可寻址最大 PFN。
max_low_pfn = pages;
// 如果没有依赖于体系结构的代码,则设置该节点的可寻址最小 PFN。
min_low_pfn = start;
// 调用 init_bootmem_core()(见 E.1.3 小节),在那里完成初始化 bootmem_data 的实
// 际工作。
return(init_bootmem_core(&contig_page_data, start, 0, pages));
}
(2)init_bootmem_node
// mm/bootmem.c
// 这个函数由 NUMA 体系结构调用,用于初始化特定节点的引导内存分配器数据。
unsigned long __init init_bootmem_node (pg_data_t *pgdat, unsigned long freepfn,
unsigned long startpfn, unsigned long endpfn)
{
// 仅直接调用 init_bootmem_core()
return(init_bootmem_core(pgdat, freepfn, startpfn, endpfn));
}
(3)init_bootmem_core
// mm/bootmem.c
static unsigned long __init init_bootmem_core (pg_data_t *pgdat,
unsigned long mapstart, unsigned long start, unsigned long end)
{
bootmem_data_t *bdata = pgdat->bdata;
unsigned long mapsize = ((end - start)+7)/8;
pgdat->node_next = pgdat_list;
pgdat_list = pgdat;
mapsize = (mapsize + (sizeof(long) - 1UL)) & ~(sizeof(long) - 1UL);
// 内存最低内存分配给 node_bootmem_map , 大小为 mapsize 个页面(struct page)
bdata->node_bootmem_map = phys_to_virt(mapstart << PAGE_SHIFT);
bdata->node_boot_start = (start << PAGE_SHIFT);
bdata->node_low_pfn = end;
/*
* Initially all pages are reserved - setup_arch() has to
* register free RAM areas explicitly.
*/
// 把所有位图初始化为 1, 即所有内存设置为保留(被占用)
memset(bdata->node_bootmem_map, 0xff, mapsize);
return mapsize;
}
(4)总结
一旦 setup_memory() 确定了可用物理页面的界限,系统将从两个引导内存的初始化函数中选择一个,并以待初始化的节点的起始和终止 PFN 作为调用参数。在 UMA 结构中,init_bootmem() 用于初始化 contig_page_data,而在 NUMA,init_bootmem_node() 则初始化一个具体的节点。这两个函数主要通过调用 init_bootmem_core() 来完成实际工作。
内核函数首先要把 pgdat_data_t 插入到 pgdat_list 链表中,因为这个节点在函数末尾很快就会用到。然后它记录下该节点的起始和结束地址(该节点与 bootmem_data_t 有关)并且分配一个位图来表示页面的分配情况。位图所需的大小以字节计算,计算公式如下:
m a p s i z e = ( e n d _ p f n − s t a r t _ p f n ) + 7 8 mapsize =\frac{(end\_pfn-start\_pfn)+7}{8} mapsize=8(end_pfn−start_pfn)+7
该位图存放于由 bootmem_data_t→node_boot_start 指向的物理地址处,而其虚拟地址的映射由 bootmem_data_t→node_bootmem_map 指定。由于不存在与结构无关的方式来检测内存中的空洞,整个位图就被初始化为 1 来标志所有页已被分配。将可用页面的位设置为 0 的工作则由与结构相关的代码完成。在 x86 结构中,register_bootmem_low_pages() 通过检测 e820 映射图,并在每一个可用页面上调用 free_bootmem() 函数,将其位设为 1,然后再调用 reserve_bootmem() 为保存实际位图所需的页面预留空间。
2、分配内存
(1)保留大块区域的内存
(a)reserve_bootmem
// mm/bootmem.c
void __init reserve_bootmem (unsigned long addr, unsigned long size)
{
reserve_bootmem_core(contig_page_data.bdata, addr, size);
}
(b)reserve_bootmem_core
// mm/bootmem.c
/*
* Marks a particular physical memory range as unallocatable. Usable RAM
* might be used for boot-time allocations - or it might get added
* to the free page pool later on.
*/
static void __init reserve_bootmem_core(bootmem_data_t *bdata, unsigned long addr, unsigned long size)
{
unsigned long i;
/*
* round up, partially reserved pages are considered
* fully reserved.
*/
// sidx 是服务页的起始索引。它的值是从请求地址中减去起始地址并除以页大小得到的。
unsigned long sidx = (addr - bdata->node_boot_start)/PAGE_SIZE;
// 末尾索引 eidx 的计算与 sidx 类似,但它的分配是向上取整到最近的页面。这意味着
// 对保留一页中部分请求将导致整个页都被保留。
unsigned long eidx = (addr + size - bdata->node_boot_start +
PAGE_SIZE-1)/PAGE_SIZE;
// end 是受本次保留影响的最后 PFN。
unsigned long end = (addr + size + PAGE_SIZE-1)/PAGE_SIZE;
// 检查是否给定了一个非零值。
if (!size) BUG();
// 检查起始索引不在节点起点之前。
if (sidx < 0)
BUG();
// 检查末尾索引不在节点末端之后。
if (eidx < 0)
BUG();
// 检查起始索引不在末尾索引之后。
if (sidx >= eidx)
BUG();
// 检查起始地址没有超出该启动内存节点所表示的内存范围。
if ((addr >> PAGE_SHIFT) >= bdata->node_low_pfn)
BUG();
// 检查末尾地址没有超出该启动内存节点所表示的内存范围。
if (end > bdata->node_low_pfn)
BUG();
// 从 sidx 开始,到 eidx 结束,这里测试和设置启动内存分配图中表示页面已经分
// 配的位。如果该位已经设置为 1,则打印一条消息:该位被设置了两次。
for (i = sidx; i < eidx; i++)
if (test_and_set_bit(i, bdata->node_bootmem_map))
printk("hm, page %08lx reserved twice.\n", i*PAGE_SIZE);
}
(c)总结
由上分析可知:保留内存主要通过函数 reserve_bootmem_core 来实现的,其主要就是把对应页帧号的位图(bootmem_data_t ->node_bootmem_map)设置为 1, 来表示对应的页被占用了。
(2)在启动时分配内存
(a)alloc_bootmem
// include/linux/bootmem.h
// 将 L1 硬件高速缓存页对齐,并在 DMA 中可用的最大地址后开始查找一页。 SMP_CACHE_BYTES 为 64?
#define alloc_bootmem(x) \
__alloc_bootmem((x), SMP_CACHE_BYTES, __pa(MAX_DMA_ADDRESS))
// 将 L1 硬件高速缓存页对齐,并从 0 开始查找。
#define alloc_bootmem_low(x) \
__alloc_bootmem((x), SMP_CACHE_BYTES, 0)
// 将已分配位对齐到一页大小,这样满页将从 DMA 可用的最大地址开始分配。
#define alloc_bootmem_pages(x) \
__alloc_bootmem((x), PAGE_SIZE, __pa(MAX_DMA_ADDRESS))
// 将已分配位对齐到一页大小,这样满页将从物理地址 0 开始分配。
#define alloc_bootmem_low_pages(x) \
__alloc_bootmem((x), PAGE_SIZE, 0)
(b)__alloc_bootmem
// mm/page_alloc.c
pg_data_t *pgdat_list;
// include/linux/mmzone.h
#define for_each_pgdat(pgdat) \
for (pgdat = pgdat_list; pgdat; pgdat = pgdat->node_next)
// mm/bootmem.c
//
// size 是请求分配的大小。
// align 是指定的对齐方式,它必须是 2 的幂。目前,一般设置为 SMP_CACHE_BYTES 或 PAGE_SIZE。
// goal 是开始查询的起始地址。
void * __init __alloc_bootmem (unsigned long size, unsigned long align, unsigned long goal)
{
pg_data_t *pgdat;
void *ptr;
// 遍历所有的可用节点,并试着轮流从各个节点开始分配。在 UMA 中,就从
// contig_page_data 节点开始分配。
for_each_pgdat(pgdat)
if ((ptr = __alloc_bootmem_core(pgdat->bdata, size,
align, goal)))
return(ptr);
/*
* Whoops, we cannot satisfy the allocation request.
*/
// 如果分配失败,系统将不能启动,故系统瘫痪。
printk(KERN_ALERT "bootmem alloc of %lu bytes failed!\n", size);
panic("Out of memory");
return NULL;
}
传送门 __alloc_bootmem_core
(c)alloc_bootmem_node
// include/linux/bootmem.h
// 将从请求节点处开始分配,对齐 L1 硬件高速缓存,并从
// ZONE_NORMAL 处开始找到一页 (如,在 ZONE_DMA 末端,其为 MAX_DMA_ADDRESS)。
#define alloc_bootmem_node(pgdat, x) \
__alloc_bootmem_node((pgdat), (x), SMP_CACHE_BYTES, __pa(MAX_DMA_ADDRESS))
// 将从请求节点处开始分配,分配页对齐到一页大小,所以全部页面将从 ZONE_NORMAL 中开始分配。
#define alloc_bootmem_pages_node(pgdat, x) \
__alloc_bootmem_node((pgdat), (x), PAGE_SIZE, __pa(MAX_DMA_ADDRESS))
// 将从请求节点处开始分配,分配页对齐到一页大小,所以全部页面将从物理地址 0 处开始分配,
// 这里将使用 ZONE_DMA。
#define alloc_bootmem_low_pages_node(pgdat, x) \
__alloc_bootmem_node((pgdat), (x), PAGE_SIZE, 0)
(d)__alloc_bootmem_node
// mm/bootmem.c
// 它所要分配的节点是特定的。
void * __init __alloc_bootmem_node (pg_data_t *pgdat, unsigned long size, unsigned long align, unsigned long goal)
{
void *ptr;
// 调用核心函数 __alloc_bootmem_core 来完成分配。
ptr = __alloc_bootmem_core(pgdat->bdata, size, align, goal);
// 如果成功则返回一个指针。
if (ptr)
return (ptr);
/*
* Whoops, we cannot satisfy the allocation request.
*/
// 否则,若在这里都没有分配内存,系统将不能启动,所以打印一条消息,表示系统瘫痪。
printk(KERN_ALERT "bootmem alloc of %lu bytes failed!\n", size);
panic("Out of memory");
return NULL;
}
(e)__alloc_bootmem_core
这是从一个带有引导内存分配器的特定节点中分配内存的核心函数。它非常大,所以将其分解成如下步骤:
- 函数开始处保证所有的参数都正确。
- 以 goal 参数为基础计算开始扫描的起始地址。
- 检查本次分配是否可以使用上次分配的页面以节省内存。
- 在位图中标记已分配页为 1,并将页中内容清 0。
/*
* We 'merge' subsequent allocations to save space. We might 'lose'
* some fraction of a page if allocations cannot be satisfied due to
* size constraints on boxes where there is physical RAM space
* fragmentation - in these cases * (mostly large memory boxes) this
* is not a problem.
*
* On low memory boxes we get it right in 100% of the cases.
*/
/*
* alignment has to be a power of 2 value.
*/
// 这是函数的前面部分,它保证参数有效。
//
// bdata 是要分配结构体的启动内存。
// size 是请求分配的大小。
// align 是分配的对齐方式,它必须是 2 的幂。
// goal 是上面要分配的最可能的合适大小? 以 goal 参数为基础计算开始扫描的起始地址。
static void * __init __alloc_bootmem_core (bootmem_data_t *bdata,
unsigned long size, unsigned long align, unsigned long goal)
{
unsigned long i, start = 0;
void *ret;
unsigned long offset, remaining_size;
unsigned long areasize, preferred, incr;
// 计算末尾位索引 eidx,它返回可能用于分配的最高页面索引。
unsigned long eidx = bdata->node_low_pfn - (bdata->node_boot_start >>
PAGE_SHIFT);
// 如果指定了 0 则调用 BUG()。
if (!size) BUG();
// 如果对齐不是 2 的幂,则调用 BUG()。
if (align & (align-1))
BUG();
// 对齐的缺省偏移是 0。
offset = 0;
// 如果指定了对齐方式则・・・・
// 请求的对齐方式与开始节点的对齐方式相同,这里计算偏移。
if (align &&
(bdata->node_boot_start & (align - 1UL)) != 0)
// 要使用的偏移与起始地址低位标记的请求对齐。实际上,这里的 offset 与 align 的一
// 般值 align 相似。
offset = (align - (bdata->node_boot_start & (align - 1UL)));
offset >>= PAGE_SHIFT;
/*
* We try to allocate bootmem pages above 'goal'
* first, then we try to allocate lower pages.
*/
// 这一块计算开始的 PFN 从 goal 参数为基础的地址处开始扫描。
//
// 如果指定了 goal,且 goal 在该节点的开始地址之后,goal 小于该节点可寻址 PFN,则 ...
// 开始的适当偏移是 goal 减去该节点可寻址的内存起点。
if (goal && (goal >= bdata->node_boot_start) &&
((goal >> PAGE_SHIFT) < bdata->node_low_pfn)) {
preferred = goal - bdata->node_boot_start;
} else
// 如果不是这样,则适当偏移为 0。
preferred = 0;
// 考虑偏移,调整适当偏移的大小,这样该地址将可以正确对齐。
preferred = ((preferred + align - 1) & ~(align - 1)) >> PAGE_SHIFT;
preferred += offset;
// 本次分配影响到的页面数存放在 areasize 中。
areasize = (size+PAGE_SIZE-1)/PAGE_SIZE;
// incr 是要跳过的页面数,如果多于一页,则它们满足对齐请求。
incr = align >> PAGE_SHIFT ? : 1;
// 这一块扫描内存,寻找一块足够大的块来满足请求。
//
// 如果本次分配不能满足从 goal 开始,则跳到这里的标志,这样将重新扫描该映射图。
restart_scan:
// 从 preferred 开始,这里线性扫描一块足够大的块来满足请求。这里以 incr 为
// 步长来遍历整个地址空间以满足大于一页的对齐。如果对齐小于一页,incr 为 1。
for (i = preferred; i < eidx; i += incr) {
unsigned long j;
if (test_bit(i, bdata->node_bootmem_map))
continue;
// 扫描下一个 areasize 大小的页面来确定它是否也可以被释放。如果到达可寻
// 址空间的末端 (eidx) 或者其中的一页已经在使用,则失败。
for (j = i + 1; j < i + areasize; ++j) {
if (j >= eidx)
goto fail_block;
if (test_bit (j, bdata->node_bootmem_map))
goto fail_block;
}
// 找到一个空闲块,所以这里记录 start,并跳转到找到的块。
start = i;
goto found;
fail_block:;
}
// 分配失败,所以从开始处重新开始。
if (preferred) {
preferred = offset;
goto restart_scan;
}
// 如果再次失败,则返回 NULL,这将导致系统瘫疾。
return NULL;
// 这一块测试以确定本次分配可以与前一次分配合并。
found:
// 检查分配的起点不会在可寻址内存之后。刚才已经检查过,所以这里是多余的。
if (start >= eidx)
BUG();
/*
* Is the next page of the previous allocation-end the start
* of this allocation's buffer? If yes then we can 'merge'
* the previous partial page with this allocation.
*/
// 如果对齐小于 PAGE_SIZE,前面的页面在其中有空间(last_offset != 0),而且
// 前面使用的页与本次分配的页相邻,则试着与前一次分配合并。
if (align <= PAGE_SIZE
&& bdata->last_offset && bdata->last_pos+1 == start) {
// 更新用于对 align 请求正确分页的偏移。
offset = (bdata->last_offset+align-1) & ~(align-1);
// 如果偏移现在超过了页面边界,则调用 BUG()。这个条件需要使用一次非常
// 槽糕的对齐选择。由于一般使用的对齐仅是一个 PAGE_SIZE 的因子,所以不可能在平常
// 使用。
if (offset > PAGE_SIZE)
BUG();
// remaining_size 是以前用过的页面中处于空闲的空间。
remaining_size = PAGE_SIZE-offset;
// 如果在旧的页面中有足够的空间剩余,这里使用旧的页面,然后更新 bootmem_data
//
// 结构来反映这一点。
if (size < remaining_size) {
// 这次分配中用到的页面数现在为 0。
areasize = 0;
// last_pos unchanged
// 更新 last_offset 为本次分配的末端。
bdata->last_offset = offset+size;
// 计算返回成功分配的虚拟地址。
ret = phys_to_virt(bdata->last_pos*PAGE_SIZE + offset +
bdata->node_boot_start);
} else {
// 如果不是这样,则这里计算除了这一页外还需要多少页面,并更新 bootmem_data。
//
// remaining_size 是上一次用来满足分配的页面空间。
remaining_size = size - remaining_size;
// 计算还需要多少页面来满足分配请求。
areasize = (remaining_size+PAGE_SIZE-1)/PAGE_SIZE;
// 计算分配开始的地址。
ret = phys_to_virt(bdata->last_pos*PAGE_SIZE + offset +
bdata->node_boot_start);
// 使用到的最后一页是 start 页面加上满足这次分配的额外页面数量 areasize。
bdata->last_pos = start+areasize-1;
// 已经计算过本次分配的末端。
bdata->last_offset = remaining_size;
}
// 如果偏移在页尾,则标记为 0。
bdata->last_offset &= ~PAGE_MASK;
} else {
// 如果没有,这里记录本次分配用到的页面和偏移,以便于下次分配时的合并。
//
// 不发生合并,所以这里记录用到的满足本次分配的最后一页。
bdata->last_pos = start + areasize - 1;
// 记录用到的最后一页。
bdata->last_offset = size & ~PAGE_MASK;
// 记录分配的起始虚拟地址。
ret = phys_to_virt(start * PAGE_SIZE + bdata->node_boot_start);
}
/*
* Reserve the area now:
*/
// 这一块在位图中标记分配页为 1,并将其内容清 0。
//
// 遍历本次分配用到的所有页面,在位图中设置 1。如果它们中已经有 1,则发生
// 了一次重复分配,所以调用 BUG()。
for (i = start; i < start+areasize; i++)
if (test_and_set_bit(i, bdata->node_bootmem_map))
BUG();
// 将页面用 0 填充。
memset(ret, 0, size);
// 返回分配的地址。
return ret;
}
(f)总结
由上分析可知:启动时分配函数 alloc_bootmem、alloc_bootmem_low、alloc_bootmem_pages、alloc_bootmem_low_pages 它们最终会调用 __alloc_bootmem_core 函数,其通过 bdata->node_bootmem_map 位图找到空闲可用的页面。
-
如果对齐(align)小于 PAGE_SIZE,前面的页面在其中有空间(last_offset != 0),而且前面使用的页与本次分配的页相邻,则试着与前一次分配合并,更新页面(bdata->last_pos)和偏移(bdata->last_offset);
-
否则不合并,并记录用到的页面(bdata->last_pos)和偏移(bdata->last_offset),以便于下次分配时的合并。
bdata 的字段意思可参考 ⇒ 5.1 描述引导内存映射
3、释放内存
(1)free_bootmem
// mm/bootmem.c
void __init free_bootmem (unsigned long addr, unsigned long size)
{
// 调用核心函数,以 contig_page_data 的启动内存数据为参数。
return(free_bootmem_core(contig_page_data.bdata, addr, size));
}
(2)free_bootmem_core
static void __init free_bootmem_core(bootmem_data_t *bdata, unsigned long addr, unsigned long size)
{
unsigned long i;
unsigned long start;
/*
* round down end of usable mem, partially free pages are
* considered reserved.
*/
unsigned long sidx;
// 计算受影响的末端索引 eidx。
unsigned long eidx = (addr + size - bdata->node_boot_start)/PAGE_SIZE;
// 如果末端地址不是页对齐,则它为受影响区域的末端向下取整到最近页面。
unsigned long end = (addr + size)/PAGE_SIZE;
// 如果释放了大小为 0 的页面,则调用 BUG()。
if (!size) BUG();
// 如果末端 PFN 在该节点可寻址内存之后,则这里调用 BUG()。
if (end > bdata->node_low_pfn)
BUG();
/*
* Round up the beginning of the address.
*/
// 如果起始地址不是页对齐的,则将其向上取整到最近页面。
start = (addr + PAGE_SIZE-1) / PAGE_SIZE;
// 计算要释放的起始索引。
sidx = start - (bdata->node_boot_start/PAGE_SIZE);
// 释放全部满页面,这里清理在启动位图中的位。如果已经为 0,则表示是一次重
// 复释放或内存从未使用,这里调用 BUG()。
for (i = sidx; i < eidx; i++) {
if (!test_and_clear_bit(i, bdata->node_bootmem_map))
BUG();
}
}
(3)总结
由上分析可知:函数 free_bootmem_core 主要就是把对应页帧号的位图(bootmem_data_t ->node_bootmem_map)设置为 0, 来表示对应的页是空闲的。
4、释放引导内存分配器
在系统启动后,引导内存分配器就不再需要了,这些函数负责销毁不需要的引导内存分配器结构,并将其余的页面传入到普通的物理页面分配器中。
(1)mem_init
这个函数的调用图如图 5.2 所示。引导内存分配器的这个函数的重要部分是它调用 free_pages_init() 。这个函数分成如下几部分:
- 函数前面部分为高端内存地址设置在全局 mem_map 中的 PFN,并将系统范围的 0 页面清零。
- 调用 free_pages_init() 。
- 打印系统中可用内存的提示信息。
- 如果配置项可用,则检查 CPU 是否支持 PAE,并测试 CPU 中的 WP 位。这很重要,如果没有 WP 位,就必须调用 verify_write() 对内核到用户空间的每一次写检查。这仅应用于像 386 一样的老处理器。
- 填充 swapper_pg_dir 的 PGD 用户空间部分的表项,其中有内核页表。0 页面映射到所有的表项。
// arch/i386/mm/init.c
void __init mem_init(void)
{
int codesize, reservedpages, datasize, initsize;
// ...
// 这个函数记录从 mem_map(highmem_start_page) 处高端内存开始的 PFN,系统中最
// 大的页面数 (max_mapnr 和 num_physpages),以及最后是可被内核映射的最大页面数
// (num_mappedpages)。
set_max_mapnr_init();
// high_memory 是高端内存开始处的虚拟地址。
high_memory = (void *) __va(max_low_pfn * PAGE_SIZE);
/* clear the zero-page */
// 将系统范围内的 0 页面清 0。
memset(empty_zero_page, 0, PAGE_SIZE);
// 调用 free_pages_init ,在那里告知引导内存分配器释放它自身以
// 及初始化高端内存的所有页面,以用于伙伴分配器。
reservedpages = free_pages_init();
// 计算用于初始化代码和数据的代码段、数据段和内存大小。(所有标识为 __init 的函
// 数都将在这一部分) 。
codesize = (unsigned long) &_etext - (unsigned long) &_text;
datasize = (unsigned long) &_edata - (unsigned long) &_etext;
initsize = (unsigned long) &__init_end - (unsigned long) &__init_begin;
// ...
if (boot_cpu_data.wp_works_ok < 0)
test_wp_bit();
#ifndef CONFIG_SMP
// 遍历 swapper_pg_dir 的用户空间部分用到的每个 PGD,并将 0 页面与之映射。
zap_low_mappings();
#endif
}
(a)⇐ set_max_mapnr_init
// mm/memory.c
unsigned long max_mapnr;
unsigned long num_physpages;
unsigned long num_mappedpages;
void * high_memory;
struct page *highmem_start_page;
// ==============================================================================
// arch/i386/mm/init.c
static void __init set_max_mapnr_init(void)
{
#ifdef CONFIG_HIGHMEM
highmem_start_page = mem_map + highstart_pfn;
max_mapnr = num_physpages = highend_pfn;
num_mappedpages = max_low_pfn;
#else
max_mapnr = num_mappedpages = num_physpages = max_low_pfn;
#endif
}
(2)free_pages_init
这个函数有 3 个重要的功能:调用 free_all_bootmem(),销毁引导内存分配器,以及释放伙伴分配器的所有高端内存。
// arch/i386/mm/init.c
static int __init free_pages_init(void)
{
extern int ppro_with_ram_bug(void);
int bad_ppro, reservedpages, pfn;
// 在奔腾 Pro 版本中有一个 bug,阻止高端内存中的某些页被使用。
// 函数 ppro_with_ram_bug() 检查是否存在这个 bug。
bad_ppro = ppro_with_ram_bug();
/* this will put all low memory onto the freelists */
// 调用 free_all_bootmem() 来销毁引导内存分配器。
totalram_pages += free_all_bootmem();
// 遍历所有的内存,计数保留给引导内存分配器的页面数。
reservedpages = 0;
for (pfn = 0; pfn < max_low_pfn; pfn++) {
/*
* Only count reserved RAM pages
*/
if (page_is_ram(pfn) && PageReserved(mem_map+pfn))
reservedpages++;
}
#ifdef CONFIG_HIGHMEM
// 对高端内存中的每一页,这里调用 one_highpage_init()。这个
// 函数清除 PG_reserved 位,设置 PG_high 位,设置计数为 1,调用 __free_pages() 来给
// 伙伴分配器分配页面,增加 totalhigh_pages 计数。杀死有 bug 的奔腾 Pro 的页面将被跳过。
for (pfn = highend_pfn-1; pfn >= highstart_pfn; pfn--)
one_highpage_init((struct page *) (mem_map + pfn), pfn, bad_ppro);
totalram_pages += totalhigh_pages;
#endif
return reservedpages;
}
传送门 free_all_bootmem
(3)one_highpage_init
这个函数初始化高端内存中的页面信息,并检查以保证页面不会在某些奔腾 Pro 上报 bug。它仅在编译时指定了 CONFIG_HIGHMEM 的情况下存在。
// arch/i386/mm/init.c
#ifdef CONFIG_HIGHMEM
void __init one_highpage_init(struct page *page, int pfn, int bad_ppro)
{
// 如果在 PFN 处不存在页面,则这里标记 struct page 为保留的,所以不会使用该页面。
if (!page_is_ram(pfn)) {
SetPageReserved(page);
return;
}
// 如果当前运行的 CPU 是有奔腾 Pro bug 的,而这个页面会导致崩责 (page_kill_ppro()
// 进行这项检查) ,这里就标记页面为保留的,它也不会被分配。
if (bad_ppro && page_kills_ppro(pfn)) {
SetPageReserved(page);
return;
}
// 从这里开始,就会使用高端内存的页面,所以这里首先清除保留位,然后将它们分配
// 给伙伴分配器。
ClearPageReserved(page);
// 设置 PG_highmem 位表示它是一个高端内存页面。
set_bit(PG_highmem, &page->flags);
// 初始化页面的使用计数为 1,它由伙伴分配器设为 0。
atomic_set(&page->count, 1);
// 利用 __free_page() 来释放页面,这样伙伴分配器会将高端内存页面
// 加到它的空闲链表中。
__free_page(page);
// 将可用的高内存页面总数 (totalhigh_pages) 加 1。
totalhigh_pages++;
}
#endif /* CONFIG_HIGHMEM */
(4)free_all_bootmem
// mm/bootmem.c
// 对 NUMA 而言,这里仅是简单地调用以特定 pgdat 为参数的核心函数。
unsigned long __init free_all_bootmem_node (pg_data_t *pgdat)
{
return(free_all_bootmem_core(pgdat));
}
// 对 UMA 而言,这里调用仅以节点 contig_page_data 为参数的核心函数。
unsigned long __init free_all_bootmem (void)
{
return(free_all_bootmem_core(&contig_page_data));
}
(5)free_all_bootmem_core
这是销毁引导内存分配器的核心函数。它分为如下两个主要部分:
- 对该节点已知的未分配页面,它完成如下步骤:
- 清除结构页面中的 PG_reserved 标志。
- 置计数为 1。
- 调用 __free_pages(),这样伙伴分配器可以构建它的空闲链表。
- 释放用于位图的页面,并将其释放给伙伴分配器。
// mm/bootmem.c
static unsigned long __init free_all_bootmem_core(pg_data_t *pgdat)
{
struct page *page = pgdat->node_mem_map;
bootmem_data_t *bdata = pgdat->bdata;
unsigned long i, count, total = 0;
unsigned long idx;
// 如果没有映射图,则意味着这个节点已经被释放了,且肯定在依赖于体系结构的代码
// 中出现了错误,所以这里调用 BUG()。
if (!bdata->node_bootmem_map) BUG();
// 将页面数的运行数传给伙伴分配器。
count = 0;
// idx 是该节点最后可寻址的索引。
idx = bdata->node_low_pfn - (bdata->node_boot_start >> PAGE_SHIFT);
// 遍历该节点可寻址的所有页面。
for (i = 0; i < idx; i++, page++) {
// 如果该页标记为空闲,则 .....
if (!test_bit(i, bdata->node_bootmem_map)) {
// 将传给伙伴分配器页面数的运行数加 1。
count++;
// 清除 PG_reserved 标志。
ClearPageReserved(page);
// 设置计数为 1,这样伙伴分配器将考虑这是页面的最后一个用户,并将其放入到空闲
// 链表中。
set_page_count(page, 1);
// 用伙伴分配器的释放函数,这样页面将被加入到空闲链表中。
__free_page(page);
}
}
// total 将设为由此函数传递的页面总数。
total += count;
/*
* Now free the allocator bitmap itself, it's not
* needed anymore:
*/
// 这一块释放分配器位图并返回。
//
// 获得在启动内存映射图顶端的 struct page。
page = virt_to_page(bdata->node_bootmem_map);
// 位图释放的页面数。
count = 0;
// 对该位图使用的所有页面,这里与前面的代码一样,将其释放给伙伴分配器。
for (i = 0; i < ((bdata->node_low_pfn-(bdata->node_boot_start >> PAGE_SHIFT))/8
+ PAGE_SIZE-1)/PAGE_SIZE; i++,page++) {
count++;
ClearPageReserved(page);
set_page_count(page, 1);
__free_page(page);
}
total += count;
// 设启动内存映射图为 NULL,以阻止其意外地被第 2 次释放。
bdata->node_bootmem_map = NULL;
// 返回该函数释放的页面总数,或者说,返回加人到伙伴分配器空闲链表的页面总数。
return total;
}
(a)⇐ mm.h
// include/linux/mm.h
#define get_page(p) atomic_inc(&(p)->count)
#define put_page(p) __free_page(p)
#define put_page_testzero(p) atomic_dec_and_test(&(p)->count)
#define page_count(p) atomic_read(&(p)->count)
#define set_page_count(p,v) atomic_set(&(p)->count, v)
#define SetPageReserved(page) set_bit(PG_reserved, &(page)->flags)
#define ClearPageReserved(page) clear_bit(PG_reserved, &(page)->flags)
(b)⇒ __free_page
传送门 __free_page
二、页表管理
1、初始化页表
(1)paging_init
当这个函数返回时,页面已经完全建立完成。注意这里都是与 x86 相关的。
// arch/i386/mm/init.c
/*
* paging_init() sets up the page tables - note that the first 8MB are
* already mapped by head.S.
*
* This routines also unmaps the page at virtual kernel address 0, so
* that we can trap those pesky NULL-reference errors in the kernel.
*/
void __init paging_init(void)
{
// pagetable_init() 负责利用 swapper_pg_dir 设立一个静态页表作为 PGD。
pagetable_init();
// 将初始化后的 swapper_pg_dir 载入 CR3 寄存器,这样 CPU 可以使用它。
load_cr3(swapper_pg_dir);
#if CONFIG_X86_PAE
/*
* We will bail out later - printk doesn't work right now so
* the user would just see a hanging kernel.
*/
// 如果 PAE 可用,则在 CR4 寄存器中设置相应的位。
if (cpu_has_pae)
set_in_cr4(X86_CR4_PAE);
#endif
// 清洗所有 (包括在全局内核中) 的 TLB。
__flush_tlb_all();
#ifdef CONFIG_HIGHMEM
// kmap_init() 调用 kmap() 初始化保留的页表区域。
kmap_init();
#endif
// zone_sizes_init() (见 B.1.2 小节) 记录每个管理区的大小,然后调用 free_area_init()
// (见 B.1.3 小节)来初始化各个管理区。
zone_sizes_init();
}
(2)pagetable_init
这个函数负责静态初始化一个从静态定义的称为 swapper_pg_dir 的 PDG 开始的页表。不管怎样,PTE 将可以指向在 ZONE_NORMAL 中的每个页面帧。
(a)⇐ pgtable-2level.h
// include/asm-i386/pgtable-2level.h
/*
* traditional i386 two-level paging structure:
*/
#define PGDIR_SHIFT 22
#define PTRS_PER_PGD 1024
/*
* the i386 is two-level, so we don't really have any
* PMD directory physically.
*/
#define PMD_SHIFT 22
#define PTRS_PER_PMD 1
#define PTRS_PER_PTE 1024
/*
* (pmds are folded into pgds so this doesnt get actually called,
* but the define is needed for a generic inline function.)
*/
#define set_pmd(pmdptr, pmdval) (*(pmdptr) = pmdval)
#define set_pgd(pgdptr, pgdval) (*(pgdptr) = pgdval)
static inline pmd_t * pmd_offset(pgd_t * dir, unsigned long address)
{
return (pmd_t *) dir;
}
#define __mk_pte(page_nr,pgprot) __pte(((page_nr) << PAGE_SHIFT) | pgprot_val(pgprot))
(b)⇐ pgtable.h
// ========================================================================
// include/asm-i386/pgtable.h
#define PMD_SIZE (1UL << PMD_SHIFT) // 4M
#define PMD_MASK (~(PMD_SIZE-1))
#define PGDIR_SIZE (1UL << PGDIR_SHIFT) // 4M
#define PGDIR_MASK (~(PGDIR_SIZE-1))
#define page_pte(page) page_pte_prot(page, __pgprot(0))
#define pmd_page(pmd) \
((unsigned long) __va(pmd_val(pmd) & PAGE_MASK))
/* to find an entry in a page-table-directory. */
#define pgd_index(address) ((address >> PGDIR_SHIFT) & (PTRS_PER_PGD-1))
#define __pgd_offset(address) pgd_index(address)
#define pgd_offset(mm, address) ((mm)->pgd+pgd_index(address))
/* to find an entry in a kernel page-table-directory */
#define pgd_offset_k(address) pgd_offset(&init_mm, address)
#define __pmd_offset(address) \
(((address) >> PMD_SHIFT) & (PTRS_PER_PMD-1))
#define mk_pte(page, pgprot) __mk_pte((page) - mem_map, (pgprot))
/* This takes a physical page address that is used by the remapping functions */
#define mk_pte_phys(physpage, pgprot) __mk_pte((physpage) >> PAGE_SHIFT, pgprot)
(c)⇐ page.h
// ========================================================================
// include/asm-i386/page.h
#define pmd_val(x) ((x).pmd)
#define pgd_val(x) ((x).pgd)
#define pgprot_val(x) ((x).pgprot)
#define __pte(x) ((pte_t) { (x) } )
#define __pmd(x) ((pmd_t) { (x) } )
#define __pgd(x) ((pgd_t) { (x) } )
#define __pgprot(x) ((pgprot_t) { (x) } )
(d)pagetable_init
页地址扩展(PAE,Page Address Extension),页面大小扩展(PSE,大概是 Page Size Extension 的简称),用于扩展 32 位寻址。因此 不研究 PAE 启用情况。
// arch/i386/mm/init.c
static void __init pagetable_init (void)
{
unsigned long vaddr, end;
pgd_t *pgd, *pgd_base;
int i, j, k;
pmd_t *pmd;
pte_t *pte, *pte_base;
// 这里初始化 PGD 的第一块。它把每个表项指向全局 0 页面。需要引用的在 ZONE_NORMAL
// 中可用内存的表项将在后面分配。
/*
* This can be zero as well - no problem, in that case we exit
* the loops anyway due to the PTRS_PER_* conditions.
*/
// 变量 end 标志在 ZONE_NORMAL 中物理内存的末端。
end = (unsigned long)__va(max_low_pfn*PAGE_SIZE);
// pgd_base 设立指向静态声明的 PGD 起始位置。
pgd_base = swapper_pg_dir;
#if CONFIG_X86_PAE
// 如果 PAE 可用,仅将每个表项设为 0 (实际上,将每个表项指向全局 0 页面) 就
// 不够了,因为每个 pgd_t 是一个结构。所以,set_pgd 必须在每个 pgd_t 上调用以使每个表项
// 都指向全局 0 页面。PTRS_PER_PGD(1024)
for (i = 0; i < PTRS_PER_PGD; i++)
set_pgd(pgd_base + i, __pgd(1 + __pa(empty_zero_page)));
#endif
// i 初始化为 PGD 中的偏移,与 PAGE_OFFSET 相对应。或者说,这个函数将仅初始
// 化线性地址空间的内核部分。可以不用关心这个用户空间部分。
i = __pgd_offset(PAGE_OFFSET);
// pgd 初始化为 pgd_t,对应于线性地址空间中内核部分的起点。
pgd = pgd_base + i;
// 这个循环开始指向有效 PMD 表项。在 PAE 的情形下,页面由 alloc_bootmem_low_pages()
// 分配,然后设立相应的 PGD。没有 PAG 时,就没有中间目录,所以就折返到 PGD 以保
// 留三层页表的假象。
//
// i 已经初始化为线性地址空间的内核部分起始位置,所以这里一直循环到最后
// PTRS_PER_PGD(1024) 处的 pgd_t。
for (; i < PTRS_PER_PGD; pgd++, i++) {
// 计算这个 PGD 的虚拟地址。PGDIR_SIZE(4M),即每个 PGD 代表 4M,PGD 共 1024 个
vaddr = i*PGDIR_SIZE;
// 如果到达 ZONE_NORMAL 的末端,则跳出循环,因为不再需要另外的页表项。
if (end && (vaddr >= end))
break;
#if CONFIG_X86_PAE
// 如果 PAE 可用,则为 PMD 分配一个页面,并利用 set_pgd() 将页面插入到页表中。
pmd = (pmd_t *) alloc_bootmem_low_pages(PAGE_SIZE);
set_pgd(pgd, __pgd(__pa(pmd) + 0x1));
#else
// 如果 PAE 不可用,仅设置 pmd 指向当前 pgd_t。这就是模拟三层页表的 "折返" 策略。
pmd = (pmd_t *)pgd;
#endif
// 这是一个有效性检查,以保证 PMD 有效。
if (pmd != pmd_offset(pgd, 0))
BUG();
// 这一块初始化 PMD 中的每个表项。这个循环仅在 PAE 可用时进行。请记住,没有 PAE
// 时 PTRS_PER_PMD 是 1。
for (j = 0; j < PTRS_PER_PMD; pmd++, j++) {
// 计算这个 PMD 的虚拟地址。PGDIR_SIZE(4M),PMD_SIZE(4M)
vaddr = i*PGDIR_SIZE + j*PMD_SIZE;
if (end && (vaddr >= end))
break;
// 如果 CPU 支持 PSE,使用大 TLB 表项。这意味着,对内核页面而言,一个 TLB
// 项将映射 4 MB 而不是平常的 4 KB,将不再需要三层 PTE。
if (cpu_has_pse) {
unsigned long __pe;
set_in_cr4(X86_CR4_PSE);
boot_cpu_data.wp_works_ok = 1;
// __pe 设置为内核页表的标志(_KERNPG_TABLE),以及表明这是一个映射 4 MB(_PAGE_PSE)
// 的标志,然后利用__pa()表明这块虚拟地址的物理地址。这意味着 4 MB 的物理
// 地址不由页表映射。
__pe = _KERNPG_TABLE + _PAGE_PSE + __pa(vaddr);
/* Make it "global" too if supported */
// 如果 CPU 支持 PGE,则为页表项设置它。它标记表项为全局的,并为所有进程可见。
if (cpu_has_pge) {
set_in_cr4(X86_CR4_PGE);
__pe += _PAGE_GLOBAL;
}
// 由于 PSE 的缘故,所以不需要三层页表。现在利用 set_pmd() 来设置 PMD,并
// 继续到下一个 PMD。
set_pmd(pmd, __pmd(__pe));
continue;
}
// 相反,如果 PSE 不被支持,需要 PTE 的时候,为它们分配一个页面。
pte_base = pte = (pte_t *) alloc_bootmem_low_pages(PAGE_SIZE);
// 这一块初始化 PTE。
// 对每个 pte_t, 计算当前被检查的虚拟地址, 创建一个 PTE 来指向相应的物理页面帧。
// PTRS_PER_PTE(1024),PGDIR_SIZE(4M),PMD_SIZE(4M),PAGE_SIZE(4K)
for (k = 0; k < PTRS_PER_PTE; pte++, k++) {
vaddr = i*PGDIR_SIZE + j*PMD_SIZE + k*PAGE_SIZE;
if (end && (vaddr >= end))
break;
*pte = mk_pte_phys(__pa(vaddr), PAGE_KERNEL);
}
// PTE 已经被初始化, 所以设置 PMD 来指向包含它们的页面。
set_pmd(pmd, __pmd(_KERNPG_TABLE + __pa(pte_base)));
// 保证表项已经正确建立。
if (pte_base != pte_offset(pmd, 0))
BUG();
}
}
// 在这点上,已经设立页面表项来引用 ZONE_NORMAL 的所有部分。需要的其他区域是
// 那些固定映射以及那些需要利用 kmap() 映射高端内存的区域。
/*
* Fixed mappings, only the page table structure has to be
* created - mappings will be set by set_fixmap():
*/
// 固定地址空间被认为从 FIXADDR_TOP 开始,并在地址空间前面结束。__fix_to_virt()
// 将一个下标作为参数,并返回在固定虚拟地址空间中的第 index 个下标后续页面帧 (从
// FIXADDR_TOP 开始)。 __end_of_fixed_addresses 是上一个由固定虚拟地址空间用到的下
// 标。或者说,这一行返回的应该是固定虚拟地址空间起始位置的 PMD 虚拟地址。
vaddr = __fix_to_virt(__end_of_fixed_addresses - 1) & PMD_MASK;
// 这个函数传递 0 作为 fixrange_init() 的结束, 它开始于 vaddr,并创建有效 PGD 和
// PMD 直到虚拟地址空间的末端,对这些地址而言不需要 PTE。
fixrange_init(vaddr, 0, pgd_base);
#if CONFIG_HIGHMEM
// 利用 kmap()来设立页表。
/*
* Permanent kmaps:
*/
vaddr = PKMAP_BASE;
fixrange_init(vaddr, vaddr + PAGE_SIZE*LAST_PKMAP, pgd_base);
// 利用 kmap() 获取对应于待用到的区域首址的 PTE。
pgd = swapper_pg_dir + __pgd_offset(vaddr);
pmd = pmd_offset(pgd, vaddr);
pte = pte_offset(pmd, vaddr);
pkmap_page_table = pte;
#endif
#if CONFIG_X86_PAE
/*
* Add low memory identity-mappings - SMP needs it when
* starting up on an AP from real-mode. In the non-PAE
* case we already have these mappings through head.S.
* All user-space mappings are explicitly cleared after
* SMP startup.
*/
// 这里设立一个临时标记来映射虚拟地址 0 和物理地址 0。
pgd_base[0] = pgd_base[USER_PTRS_PER_PGD];
#endif
}
(3)⇒ alloc_bootmem_low_pages
上文 pagetable_init 函数中有调用 alloc_bootmem_low_pages 函数。
static void __init pagetable_init (void) {
// ...
pte_base = pte = (pte_t *) alloc_bootmem_low_pages(PAGE_SIZE);
// ...
}
alloc_bootmem_low_pages 函数具体分析可参考 ⇒ alloc_bootmem 一节
(4)fixrange_init
上文 pagetable_init 函数中有调用 fixrange_init 函数。
static void __init pagetable_init (void) {
// ...
fixrange_init(vaddr, 0, pgd_base);
// ...
}
这个函数为固定虚拟地址映射创建有效的 PGD 和 PMD。
// arch/i386/mm/init.c
static void __init fixrange_init (unsigned long start, unsigned long end, pgd_t *pgd_base)
{
pgd_t *pgd;
pmd_t *pmd;
pte_t *pte;
int i, j;
unsigned long vaddr;
// 设置虚拟地址 (vaddr) 作为请求起始地址的一个参数。
vaddr = start;
// 获取对应于 vaddr 的 PGD 内部索引。
i = __pgd_offset(vaddr);
// 获取对应于 vaddr 的 PMD 内部索引。
j = __pmd_offset(vaddr);
// 获取 pgd_t 的起点。
pgd = pgd_base + i;
// 一直循环直到到达 end。当 pagetable_init() 传入 0 时,将继续循环直到 PGD 的末端。
// PTRS_PER_PGD(1024)
for ( ; (i < PTRS_PER_PGD) && (vaddr != end); pgd++, i++) {
#if CONFIG_X86_PAE
// 在有 PAE 时,若没有为 PMD 分配页面,这里就为 PMD 分配一个页面。
if (pgd_none(*pgd)) {
pmd = (pmd_t *) alloc_bootmem_low_pages(PAGE_SIZE);
set_pgd(pgd, __pgd(__pa(pmd) + 0x1));
if (pmd != pmd_offset(pgd, 0))
printk("PAE BUG #02!\n");
}
pmd = pmd_offset(pgd, vaddr);
#else
// 没有 PAE 时,也没有 PMD,所以这里把 pgd_t 看作 pmd_t。
pmd = (pmd_t *)pgd;
#endif
// 对 PMD 中的每个表项,这里将为 pte_t 表项分配一个页面,并在页表中设置。
// 注意 vaddr 是以 PMD 大小作为一步增加的。
// PTRS_PER_PMD(1)。
for (; (j < PTRS_PER_PMD) && (vaddr != end); pmd++, j++) {
if (pmd_none(*pmd)) {
pte = (pte_t *) alloc_bootmem_low_pages(PAGE_SIZE);
set_pmd(pmd, __pmd(_KERNPG_TABLE + __pa(pte)));
if (pte != pte_offset(pmd, 0))
BUG();
}
vaddr += PMD_SIZE;
}
j = 0;
}
}
(5)kmap_init
上文 paging_init 函数中有调用 kmap_init 函数。
// arch/i386/mm/init.c
void __init paging_init(void) {
// ...
#ifdef CONFIG_HIGHMEM
// kmap_init() 调用 kmap() 初始化保留的页表区域。
kmap_init();
#endif
// ...
}
(a)⇐ fixmap.h
// include/asm-i386/fixmap.h
/*
* used by vmalloc.c.
*
* Leave one empty page between vmalloc'ed areas and
* the start of the fixmap, and leave one page empty
* at the top of mem..
*/
#define FIXADDR_TOP (0xffffe000UL)
#define __FIXADDR_SIZE (__end_of_permanent_fixed_addresses << PAGE_SHIFT)
#define FIXADDR_START (FIXADDR_TOP - __FIXADDR_SIZE)
#define __fix_to_virt(x) (FIXADDR_TOP - ((x) << PAGE_SHIFT))
(b)⇐ init_task.c
结构体 mm_struct 可参考 ⇒ 4.3 进程地址空间描述符
// include/linux/sched.h
#define INIT_MM(name) \
{ \
mm_rb: RB_ROOT, \
pgd: swapper_pg_dir, \
mm_users: ATOMIC_INIT(2), \
mm_count: ATOMIC_INIT(1), \
mmap_sem: __RWSEM_INITIALIZER(name.mmap_sem), \
page_table_lock: SPIN_LOCK_UNLOCKED, \
mmlist: LIST_HEAD_INIT(name.mmlist), \
}
// arch/i386/kernel/init_task.c
struct mm_struct init_mm = INIT_MM(init_mm);
(c)⇐ pgtable.h
// include/asm-i386/page.h
#define pmd_val(x) ((x).pmd)
#define pgd_val(x) ((x).pgd)
#define pgprot_val(x) ((x).pgprot)
// =========================================================================
// include/asm-i386/pgtable-2level.h
/*
* traditional i386 two-level paging structure:
*/
#define PGDIR_SHIFT 22
#define PTRS_PER_PGD 1024
/*
* the i386 is two-level, so we don't really have any
* PMD directory physically.
*/
#define PMD_SHIFT 22
#define PTRS_PER_PMD 1
#define PTRS_PER_PTE 1024
static inline pmd_t * pmd_offset(pgd_t * dir, unsigned long address)
{
return (pmd_t *) dir;
}
// =========================================================================
// include/asm-i386/pgtable.h
#define pmd_page(pmd) \
((unsigned long) __va(pmd_val(pmd) & PAGE_MASK))
/* Find an entry in the third-level page table.. */
#define __pte_offset(address) \
((address >> PAGE_SHIFT) & (PTRS_PER_PTE - 1))
#define pte_offset(dir, address) ((pte_t *) pmd_page(*(dir)) + \
__pte_offset(address))
/* to find an entry in a page-table-directory. */
#define pgd_index(address) ((address >> PGDIR_SHIFT) & (PTRS_PER_PGD-1))
#define pgd_offset(mm, address) ((mm)->pgd+pgd_index(address))
/* to find an entry in a kernel page-table-directory */
#define pgd_offset_k(address) pgd_offset(&init_mm, address)
(d)kmap_init
这个函数仅存在于如果在编译时设置了 CONFIG_HIGHMEM 的情况下。它负责获取 kma 区域的首址,引用它的 PTE 以及保护页表。这意味着在使用 kmap() 时不一定都需要检查 PGD。
/*
* NOTE: pagetable_init alloc all the fixmap pagetables contiguous on the
* physical space so we can cache the place of the first one and move
* around without checking the pgd every time.
*/
#if CONFIG_HIGHMEM
pte_t *kmap_pte;
pgprot_t kmap_prot;
// 由于 fixrange_init() 已经设立了有效的 PGD 和 PMD,所以就不需要再一次检查
// 它们,这样 kmap_get_fixmap_pte() 可以快速遍历页表。
#define kmap_get_fixmap_pte(vaddr) \
pte_offset(pmd_offset(pgd_offset_k(vaddr), (vaddr)), (vaddr))
void __init kmap_init(void)
{
unsigned long kmap_vstart;
/* cache the first kmap pte */
// 缓存 kmap_vstart 中 kmap 区域的虚拟地址。
kmap_vstart = __fix_to_virt(FIX_KMAP_BEGIN);
// 缓存 PTE 作为 kmap_pte 中 kmap 区域的首址。
kmap_pte = kmap_get_fixmap_pte(kmap_vstart);
// 利用 kmap_prot 缓存页表表项的保护项。
kmap_prot = PAGE_KERNEL;
}
#endif /* CONFIG_HIGHMEM */
(6)⇒ zone_sizes_init
上文 paging_init 函数中有调用 zone_sizes_init 函数。
// arch/i386/mm/init.c
void __init paging_init(void) {
// ...
// zone_sizes_init() (见 B.1.2 小节) 记录每个管理区的大小,然后调用 free_area_init()
// (见 B.1.3 小节)来初始化各个管理区。
zone_sizes_init();
// ...
}
zone_sizes_init 函数具体分析可参考 ⇒ zone_sizes_init 一节
2、遍历页表
(1)follow_page
这个函数返回在 mm 页表中 address 处 PTE 用到的 struct page 。
// mm/memory.c
/*
* Do a quick page-table lookup for a single page.
*/
// 这个函数是 mm 中待遍历的页表。address 与 struct page 和 write 有关,它表明该页
// 是否将被写。
static struct page * follow_page(struct mm_struct *mm, unsigned long address, int write)
{
pgd_t *pgd;
pmd_t *pmd;
pte_t *ptep, pte;
// 获取 address 处的 PGD 并保证它存在且有效。
pgd = pgd_offset(mm, address);
if (pgd_none(*pgd) || pgd_bad(*pgd))
goto out;
// 获取address处的PMD并保证它存在且有效。
pmd = pmd_offset(pgd, address);
if (pmd_none(*pmd) || pmd_bad(*pmd))
goto out;
// 获取address处的PTE并保证它存在且有效。
ptep = pte_offset(pmd, address);
if (!ptep)
goto out;
pte = *ptep;
// 如果PTE当前存在,则可以返回一些东西。
if (pte_present(pte)) {
// 如果调用者指定了将发生写操作,则检查以保证PTE有写权限。如果是这样, 将PTE设为脏。
if (!write ||
(pte_write(pte) && pte_dirty(pte)))
// 如果PTE存在并有权限,则返回由PTE映射的struct page
return pte_page(pte);
}
out:
// 返回0表明该address没有相应的struct page
return 0;
}
3、⇔ 页表
(1)pmd_alloc
// include/linux/mm.h
/*
* On a two-level page table, this ends up being trivial. Thus the
* inlining and the symmetry break with pte_alloc() that does all
* of this out-of-line.
*/
// x86 两级页表,pmd 即为 pgd ?
static inline pmd_t *pmd_alloc(struct mm_struct *mm, pgd_t *pgd, unsigned long address)
{
if (pgd_none(*pgd))
return __pmd_alloc(mm, pgd, address);
return pmd_offset(pgd, address);
}
(a) ⇐ pgtable-2level.h
// include/asm-i386/pgtable-2level.h
static inline int pgd_none(pgd_t pgd) { return 0; }
static inline pmd_t * pmd_offset(pgd_t * dir, unsigned long address)
{
return (pmd_t *) dir;
}
(2)__pmd_alloc
// mm/memory.c
/*
* Allocate page middle directory.
*
* We've already handled the fast-path in-line, and we own the
* page table lock.
*
* On a two-level page table, this ends up actually being entirely
* optimized away.
*/
pmd_t *__pmd_alloc(struct mm_struct *mm, pgd_t *pgd, unsigned long address)
{
pmd_t *new;
/* "fast" allocation can happen without dropping the lock.. */
new = pmd_alloc_one_fast(mm, address);
if (!new) {
spin_unlock(&mm->page_table_lock);
new = pmd_alloc_one(mm, address);
spin_lock(&mm->page_table_lock);
if (!new)
return NULL;
/*
* Because we dropped the lock, we should re-check the
* entry, as somebody else could have populated it..
*/
if (!pgd_none(*pgd)) {
pmd_free(new);
goto out;
}
}
pgd_populate(mm, pgd, new);
out:
return pmd_offset(pgd, address);
}
(a) ⇐ pgalloc.h
// include/asm-i386/pgalloc.h
/*
* allocating and freeing a pmd is trivial: the 1-entry pmd is
* inside the pgd, so has no extra memory associated with it.
* (In the PAE case we free the pmds as part of the pgd.)
*/
#define pmd_alloc_one_fast(mm, addr) ({ BUG(); ((pmd_t *)1); })
#define pmd_alloc_one(mm, addr) ({ BUG(); ((pmd_t *)2); })
#define pmd_free_slow(x) do { } while (0)
#define pmd_free_fast(x) do { } while (0)
#define pmd_free(x) do { } while (0)
#define pgd_populate(mm, pmd, pte) BUG()
三、描述物理内存
1、初始化管理区
(1)setup_memory
这个函数的调用图如图 2.3 所示。它为引导内存分配器初始化自身进行所需信息的获取。它可以分成几个不同的任务。
- 找到低端内存的 PFN 的起点和终点(min_low_pfn,max_low_pfn),找到高端内存的 PFN 的起点和终点(highstart_pfn,highend_pfn),以及找到系统中最后一页的 PFN。
- 初始化 bootmem_date 结构以及声明可能被引导内存分配器用到的页面。
- 标记所有系统可用的页面为空闲,然后为那些表示页面的位图保留页面。
- 在 SMP 配置或 initrd 镜像存在时,为它们保留页面。
// arch/i386/kernel/setup.c
static unsigned long __init setup_memory(void) {
unsigned long bootmap_size, start_pfn, max_low_pfn;
// 将物理地址向上取整到下一页面,返回页帧号。由于_end 是已载入内核
// 镜像的底端地址,所以 start_pfn 现在是可能被用到的第一块物理页面帧的偏移。
start_pfn = PFN_UP(__pa(&_end));
// 遍历 e820 图,查找最高的可用 PFN。
find_max_pfn();
// 在 ZONE_NORMAL 中找到可寻址的最高页面帧。
max_low_pfn = find_max_low_pfn();
#ifdef CONFIG_HIGHMEM
// 如果高端内存可用,则从高端内存区域的 0 位置开始。如果内存在 max_low_pfn 后,
// 则把高端内存区的起始位置(highstart_pfn)定在那里,而其结束位置定在 max_pfn,
// 然后打印可用高端内存的提示消息。
highstart_pfn = highend_pfn = max_pfn;
if (max_pfn > max_low_pfn) {
highstart_pfn = max_low_pfn;
}
printk(KERN_NOTICE "%ldMB HIGHMEM available.\n",
pages_to_mb(highend_pfn - highstart_pfn));
#endif
// 为 config_page_data 节点初始化 bootmem_data 结构。
// 它设置节点的物理内存起始点(页帧号 start_pfn)和终点(页帧号 max_low_pfn ),
// 分配一张位图来表示这些页面,并将所有的页面设置为初始时保留。
bootmap_size = init_bootmem(start_pfn, max_low_pfn);
// 读入 e820 图,然后为运行时系统中的所有可用页面
// 调用 free_bootmem() 这将标记页面在初始化时为空闲(即可分配页面)。
register_bootmem_low_pages(max_low_pfn);
// 保留页面,即相应的位图的位设置为 1
reserve_bootmem(HIGH_MEMORY, (PFN_PHYS(start_pfn) +
bootmap_size + PAGE_SIZE-1) - (HIGH_MEMORY));
// 保留 0 号页面,因为 0 号页面是 BIOS 用到的一个特殊页面。
reserve_bootmem(0, PAGE_SIZE);
#ifdef CONFIG_SMP
// 保留额外的页面为跳板代码用。跳板代码处理用户空间如何进入内核空间。
reserve_bootmem(PAGE_SIZE, PAGE_SIZE);
#endif
#ifdef CONFIG_ACPI_SLEEP
// 如果加入了睡眠机制,就需要为它保留内存。这仅为那些有挂起功能的手提
// 电脑所用到。它已经超过本书的范围。
acpi_reserve_bootmem();
#endif
// ...
return max_low_pfn;
}
(a)⇒ init_bootmem
传送门 init_bootmem
(b)⇒ register_bootmem_low_pages
// arch/i386/kernel/setup.c
// 读入 e820 图,然后为运行时系统中的所有可用页面
// 调用 free_bootmem() 这将标记页面在初始化时为空闲(即可分配页面)。
static void __init register_bootmem_low_pages(unsigned long max_low_pfn)
{
int i;
for (i = 0; i < e820.nr_map; i++) {
unsigned long curr_pfn, last_pfn, size;
// ...
size = last_pfn - curr_pfn;
free_bootmem(PFN_PHYS(curr_pfn), PFN_PHYS(size));
}
}
传送门 free_bootmem
(c)⇒ reserve_bootmem
传送门 reserve_bootmem
(2)zone_sizes_init
这是一个用于初始化各管理区的高层函数。PFN 中管理区大小在 setup_memory() 过程中发现。这个函数填充一个管理区大小的数组,并把它传给 free_area_init()。
// arch/i386/mm/init.c
static void __init zone_sizes_init(void)
{
// 初始化大小为 0。
unsigned long zones_size[MAX_NR_ZONES] = {0, 0, 0};
unsigned int max_dma, high, low;
// 计算最大可能 DMA 寻址的 PFN。
// #define MAX_DMA_ADDRESS (PAGE_OFFSET+0x1000000) 16M
max_dma = virt_to_phys((char *)MAX_DMA_ADDRESS) >> PAGE_SHIFT;
// max_low_pfn 是 ZONE_NORMAL 可用的最高 PFN。
low = max_low_pfn;
// highest_pfn 是 ZONE_HIGHMEM 可用的最高 PFN。
high = highend_pfn;
// 如果在 ZONE_NORMAL 中的最高 PFN 低于 MAX_DMA_ADDRESS,则仅
// 把 ZONE_DMA 的大小赋值给它,其他管理区仍然为 0。
if (low < max_dma)
zones_size[ZONE_DMA] = low;
else {
// 设置 ZONE_DMA 中的页面数。
zones_size[ZONE_DMA] = max_dma;
// ZONE_NORMAL 的大小等于 max_low_pfn 减去 ZONE_DMA 中的页面数。
zones_size[ZONE_NORMAL] = low - max_dma;
#ifdef CONFIG_HIGHMEM
// ZONE_HIGHMEM 的大小是可能的最高 PFN 减去 ZONE_NORMAL 中可能的最
// 高 PFN(max_low_pfn)。
zones_size[ZONE_HIGHMEM] = high - low;
#endif
}
free_area_init(zones_size);
}
(3)free_area_init
这是一个与体系结构无关的函数,用于设置 UMA 体系结构。它仅是调用核心函数,传入静态 contig_page_data 作为节点。不同的是,NUMA 体系结构将使用 free_area_node()。
// mm/page_alloc.c
void __init free_area_init(unsigned long *zones_size)
{
free_area_init_core(0, &contig_page_data, &mem_map, zones_size, 0, 0, 0);
}
传递给 free_area_init_core() 的参数如下:
- 0 是该节点的节点标识(NID),这里为 0。
- contig_page_data 是静态全局 pg_data_t。
- mem_map 用于跟踪 struct page 的全局 mem_map。 函数 free_area_init_core() 将为这个数组分配内存。
- zones_sizes 是由 zone_sizes_init() 填充的管理区大小的数组。
- 0,这个 0 是物理地址的起始点。
- 0,第 2 个 0 是内存空洞大小的数组,但不用于 UMA 体系结构。
- 0,最后一个 0 是一个指向该节点局部 mem_map 的一个指针,用于 NUMA 体系结构。
(4)free_area_init_core
这个函数负责初始化所有的区域,并在节点中分配它们的局部 Imem_map。在 UMA 体系结构中,调用这个函数将初始化全局 mem_map 数组。在 NUMA 体系结构中,这个数组被看作是一个稀疏分布的虚拟数组。
// mm/page_alloc.c
/*
* Set up the zone data structures:
* - mark all pages reserved
* - mark all memory queues empty
* - clear the memory bitmaps
*/
void __init free_area_init_core(int nid, pg_data_t *pgdat, struct page **gmap,
unsigned long *zones_size, unsigned long zone_start_paddr,
unsigned long *zholes_size, struct page *lmem_map)
{
unsigned long i, j;
unsigned long map_size;
unsigned long totalpages, offset, realtotalpages;
// 该块主要负责计算每个区域的大小。
// 这个区域必须邻近由伙伴分配器分配的最大大小的块,从而进行位级操作。
// MAX_ORDER 为 10
const unsigned long zone_required_alignment = 1UL << (MAX_ORDER-1);
// 如果物理地址不是按页面排列的,就是一个 BUG()。
if (zone_start_paddr & ~PAGE_MASK)
BUG();
// 为这个节点初始化 totalpages 为 0。
totalpages = 0;
// 通过遍历 zone_sizes 来计算节点的总大小。
for (i = 0; i < MAX_NR_ZONES; i++) {
unsigned long size = zones_size[i];
totalpages += size;
}
// 通过减去 zholes_size 的空洞大小来计算实际的内存量。
realtotalpages = totalpages;
if (zholes_size)
for (i = 0; i < MAX_NR_ZONES; i++)
realtotalpages -= zholes_size[i];
// 打印提示信息告知用户这个节点可用的内存量。
printk("On node %d totalpages: %lu\n", nid, realtotalpages);
/*
* Some architectures (with lots of mem and discontinous memory
* maps) have to search for a good mem_map area:
* For discontigmem, the conceptual mem map array starts from
* PAGE_OFFSET, we need to align the actual array onto a mem map
* boundary, so that MAP_NR works.
*/
// 这一块在需要时分配局部 lmem_map,设置 gmap 位。在 UMA 体系结构中,gmap 实际
// 上就是 mem_map,所以这就是为它分配的内存。
//
// 计算数组所需的内存量。它等于页面总数量乘以 struct page 的大小。
map_size = (totalpages + 1)*sizeof(struct page);
// 如果映射图还没有分配,就在这里分配。
if (lmem_map == (struct page *)0) {
// 从引导内存分配器中分配一块内存。
lmem_map = (struct page *) alloc_bootmem_node(pgdat, map_size);
// MAP_ALIGN() 将在一个 struct page 大小范围内排列数组,从而计算在 mem_map
// 中基于物理地址 MAP_NR() 宏的内部偏移。
lmem_map = (struct page *)(PAGE_OFFSET +
MAP_ALIGN((unsigned long)lmem_map - PAGE_OFFSET));
}
// 设置 gmap 和 pgdat-node_mem_map 变量以分配 lmem_map。在 UMA 体系结构
// 中,仅设置 mem_map。
*gmap = pgdat->node_mem_map = lmem_map;
// 记录节点大小。
pgdat->node_size = totalpages;
// 记录起始物理地址。
pgdat->node_start_paddr = zone_start_paddr;
// 记录节点所占 mem_map 中的偏移。
pgdat->node_start_mapnr = (lmem_map - mem_map);
// 初始化管理区计数为 0,这将在函数的后面设置。
pgdat->nr_zones = 0;
// offset 现在是 lmem_map 开始的局部部分中 mem_map 的偏移。
offset = lmem_map - mem_map;
// 从这块管理区开始循环,初始化节点中的每个 zone_t。该初始化过程开始时设置已存在
// 基本字段的值。
//
// 追历节点中所有管理区。
for (j = 0; j < MAX_NR_ZONES; j++) {
zone_t *zone = pgdat->node_zones + j;
unsigned long mask;
unsigned long size, realsize;
// 记录在 zone_table 中指向该管理区的指针,见 2.6 节。
zone_table[nid * MAX_NR_ZONES + j] = zone;
// 计算管理区的实际大小。它基于 zones_sizes 的总大小减去 zholes_size 的空洞大小。
realsize = size = zones_size[j];
if (zholes_size)
realsize -= zholes_size[j];
// 打印提示信息告知在这个管理区中的页面数。
printk("zone(%lu): %lu pages.\n", j, size);
// 记录管理区的大小。
zone->size = size;
// zone_names 是管理区的大小,这里是为了打印的需要。
zone->name = zone_names[j];
// 初始化管理区的其他字段,如它的父 pgdat。
zone->lock = SPIN_LOCK_UNLOCKED;
zone->zone_pgdat = pgdat;
zone->free_pages = 0;
zone->need_balance = 0;
// 如果管理区没有内存,就转到下一个管理区,因为不需要其他操作了。
if (!size)
continue;
/*
* The per-page waitqueue mechanism uses hashed waitqueues
* per zone.
*/
// 这一块初始化管理区的等待队列。等待该管理区中页面的进程将会使用这个哈希表选择
// 一个队列等待。这意味着在页面解锁时并不需要唤醒所有的等待进程,仅需要唤醒其中的一
// 个子集。
// wait_table_size() 计算所用哈希表的大小。它基于管理区的页面数和队列数与页面
// 数之间的特定比率完成计算。该哈希表不会大于 4 KB。
zone->wait_table_size = wait_table_size(size);
// 计算哈希算法的因子。
zone->wait_table_shift =
BITS_PER_LONG - wait_table_bits(zone->wait_table_size);
// 分配可以容纳 zone→wait_table_size 项的 wait_queue_head_t 表。
zone->wait_table = (wait_queue_head_t *)
alloc_bootmem_node(pgdat, zone->wait_table_size
* sizeof(wait_queue_head_t));
// 初始化所有的等待队列。
for(i = 0; i < zone->wait_table_size; ++i)
init_waitqueue_head(zone->wait_table + i);
// 这一块计算管理区极值并记录管理区地址。这个极值记为管理区大小的比率。
//
// 首先,若激活了一个新的管理区,更新节点中的管理区数量。
pgdat->nr_zones = j+1;
// 计算掩码(将用于 page_min 极值)为管理区的大小除以管理区的平衡因子。所有管
// 理区的平衡因子在 mm/page_alloc.c 的首部声明为 128。
mask = (realsize / zone_balance_ratio[j]);
// 所有管 理 区的 zone_balance_min 比率都为 20,这意味着 page_min 将不低于 20 。
if (mask < zone_balance_min[j])
mask = zone_balance_min[j];
else if (mask > zone_balance_max[j])
// 类似地,所有的 zone_balance_max 都为 255,所以 pages_min 将不会超过 255。
mask = zone_balance_max[j];
// pages_min 设为 mask。
zone->pages_min = mask;
// pages_low 是 pages_min 页面数量的 2 倍。
zone->pages_low = mask*2;
// pages_high 是 pages_min 页面数量的 3 倍。
zone->pages_high = mask*3;
// 记录管理区的第 1 个 struct page 在 mem_map 中的地址。
zone->zone_mem_map = mem_map + offset;
// 记录 mem_map 中管理区起点的索引。
zone->zone_start_mapnr = offset;
// 记录起始的物理地址。
zone->zone_start_paddr = zone_start_paddr;
// 利用伙伴分配器保证管理区已经正确的排列可用。否则,伙伴分配器用到的位
// 级操作就会失败。
if ((zone_start_paddr >> PAGE_SHIFT) & (zone_required_alignment-1))
printk("BUG: wrong zone alignment, it will crash\n");
/*
* Initially all pages are reserved - free ones are freed
* up by free_all_bootmem() once the early boot process is
* done. Non-atomic initialization, single-pass.
*/
// 初始时,管理区中所有的页面都标记为保留,因为没有办法知道引导内存分配
// 器使用的是哪些页面。当引导内存分配器在 free_all_bootmem() 中收回时,
// 未使用页面中的 PG_reserved 会被清除。
for (i = 0; i < size; i++) {
// 获取页面的偏移。
struct page *page = mem_map + offset + i;
// 页面所在的管理区由页面标志编码,见 2.6 节。
set_page_zone(page, nid * MAX_NR_ZONES + j);
// 设置计数为 0,因为管理区未被使用。
set_page_count(page, 0);
// 设置保留标志,然后,若页面不再被使用,引导内存分配器将清除该位。
SetPageReserved(page);
// 初始化页面链表头。
INIT_LIST_HEAD(&page->list);
// 如果页面可用且页面在低端内存,设置 page virtual 字段。
if (j != ZONE_HIGHMEM)
set_page_address(page, __va(zone_start_paddr));
// 将 zone_start_paddr 增加一个页面大小,该参数将用于记录下一个管理区的起点。
zone_start_paddr += PAGE_SIZE;
}
// 这一块初始化管理区的空闲链表,分配伙伴分配器在记录页面伙伴状态时的位图。
offset += size;
// 从 0 循环到 MAX_ORDER -1。
for (i = 0; ; i++) {
unsigned long bitmap_size;
// 初始化当前次序为 i的 free_list 链表。
INIT_LIST_HEAD(&zone->free_area[i].free_list);
// 如果处于最后,设置空闲区域映射为 NULL,表示空闲链表的末端。
if (i == MAX_ORDER-1) {
zone->free_area[i].map = NULL;
break;
}
/*
* Page buddy system uses "index >> (i+1)",
* where "index" is at most "size-1".
*
* The extra "+3" is to round down to byte
* size (8 bits per byte assumption). Thus
* we get "(size-1) >> (i+4)" as the last byte
* we can access.
*
* The "+1" is because we want to round the
* byte allocation up rather than down. So
* we should have had a "+7" before we shifted
* down by three. Also, we have to add one as
* we actually _use_ the last bit (it's [0,n]
* inclusive, not [0,n[).
*
* So we actually had +7+1 before we shift
* down by 3. But (n+8) >> 3 == (n >> 3) + 1
* (modulo overflows, which we do not have).
*
* Finally, we LONG_ALIGN because all bitmap
* operations are on longs.
*/
// 下面两句:
// bitmap_size = (size-1) >> (i+4);
// bitmap_size = LONG_ALIGN(bitmap_size+1);
// 相当于如下代码:
// bitmap_size = size >> i; // 内存块个数
// bitmap_size = (bitmap_size + 7) >> 3; // 因为一个字节有8个位, 所以要除以8
// bitmap_size = LONG_ALIGN(bitmap_size);
//
// 计算 bitmap_size 为容纳整个位图所需的字节数。位图中每一位表示一个有 2^i 数量
// 页面的伙伴对。
bitmap_size = (size-1) >> (i+4);
// 利用 LONG_ALIGN() 转化容量值为一个长整型,因为所有的位操作都在长整型上进行。
bitmap_size = LONG_ALIGN(bitmap_size+1);
// 分配映射用到的内存。
zone->free_area[i].map =
(unsigned long *) alloc_bootmem_node(pgdat, bitmap_size);
}
// 循环到下一个管理区。
}
// 利用 build_zonelists()来构造节点的管理区回退链表。
build_zonelists(pgdat);
}
(a)⇒ alloc_bootmem_node
传送门 alloc_bootmem_node
(b)⇒ 初始化 mem_map
核心函数 free_area_init_core() 为已经初始化过的节点分配局部 lmem_map。而该数组的内存通过引导内存分配器中的 alloc_bootmem_node() 分配得到。在 UMA 结构中,新分配的内存变成了全局的 mem_map。
传送门 初始化 mem_map 描述
(c)⇐ zone_t
每个管理区由一个 zone_t 描述,具体可参考 ⇒ 2.2 管理区,2.6 页面映射到管理区
(d)⇒ wait_table_size
/*
* Helper functions to size the waitqueue hash table.
* Essentially these want to choose hash table sizes sufficiently
* large so that collisions trying to wait on pages are rare.
* But in fact, the number of active page waitqueues on typical
* systems is ridiculously low, less than 200. So this is even
* conservative, even though it seems large.
*
* The constant PAGES_PER_WAITQUEUE specifies the ratio of pages to
* waitqueues, i.e. the size of the waitq table given the number of pages.
*/
#define PAGES_PER_WAITQUEUE 256
// 这一块初始化管理区的等待队列。等待该管理区中页面的进程将会使用这个哈希表选择
// 一个队列等待。这意味着在页面解锁时并不需要唤醒所有的等待进程,仅需要唤醒其中的一
// 个子集。
// wait_table_size() 计算所用哈希表的大小。它基于管理区的页面数和队列数与页面
// 数之间的特定比率完成计算。该哈希表不会大于 4 KB。
// 每 PAGES_PER_WAITQUEUE(256)个使用同一个值
static inline unsigned long wait_table_size(unsigned long pages)
{
unsigned long size = 1;
pages /= PAGES_PER_WAITQUEUE;
while (size < pages)
size <<= 1;
/*
* Once we have dozens or even hundreds of threads sleeping
* on IO we've got bigger problems than wait queue collision.
* Limit the size of the wait table to a reasonable size.
*/
size = min(size, 4096UL);
return size;
}
(e)⇒ wait_table_bits
// mm/page_alloc.c
/*
* This is an integer logarithm so that shifts can be used later
* to extract the more random high bits from the multiplicative
* hash function before the remainder is taken.
*/
static inline unsigned long wait_table_bits(unsigned long size)
{
return ffz(~size);
}
(e)⇒ wait.h
// include/linux/wait.h
struct __wait_queue_head {
wq_lock_t lock;
struct list_head task_list;
#if WAITQUEUE_DEBUG
long __magic;
long __creator;
#endif
};
typedef struct __wait_queue_head wait_queue_head_t;
static inline void init_waitqueue_head(wait_queue_head_t *q)
{
#if WAITQUEUE_DEBUG
if (!q)
WQ_BUG();
#endif
q->lock = WAITQUEUE_RW_LOCK_UNLOCKED;
INIT_LIST_HEAD(&q->task_list);
#if WAITQUEUE_DEBUG
q->__magic = (long)&q->__magic;
q->__creator = (long)current_text_addr();
#endif
}
(f)⇒ mm.h
// include/linux/mm.h
/*
* The zone field is never updated after free_area_init_core()
* sets it, so none of the operations on it need to be atomic.
*/
#define NODE_SHIFT 4
#define ZONE_SHIFT (BITS_PER_LONG - 8)
struct zone_struct;
extern struct zone_struct *zone_table[];
static inline zone_t *page_zone(struct page *page)
{
return zone_table[page->flags >> ZONE_SHIFT];
}
static inline void set_page_zone(struct page *page, unsigned long zone_num)
{
page->flags &= ~(~0UL << ZONE_SHIFT);
page->flags |= zone_num << ZONE_SHIFT;
}
#define set_page_count(p,v) atomic_set(&(p)->count, v)
#define SetPageReserved(page) set_bit(PG_reserved, &(page)->flags)
/*
* In order to avoid #ifdefs within C code itself, we define
* set_page_address to a noop for non-highmem machines, where
* the field isn't useful.
* The same is true for page_address() in arch-dependent code.
*/
#if defined(CONFIG_HIGHMEM) || defined(WANT_PAGE_VIRTUAL)
#define set_page_address(page, address) \
do { \
(page)->virtual = (address); \
} while(0)
#else /* CONFIG_HIGHMEM || WANT_PAGE_VIRTUAL */
#define set_page_address(page, address) do { } while(0)
#endif /* CONFIG_HIGHMEM || WANT_PAGE_VIRTUAL */
(g)⇐ 概览
传送门 6.3 释放页面
(h)⇐ 伙伴算法
一文看懂物理内存分配算法(伙伴系统)
伙伴算法原理简介
(5)build_zonelists
这个函数在所请求的节点中为每个管理区构造回退管理区。这是为了在不能满足一个分配时可以考察下一个管理区而设立的。在考察结束时,分配将从 ZONE_HIGHMEM 回退到 ZONE_NORMAL,在分配从 ZONE_NORMAL 回退到 ZONE_DMA 后就不再回退。
/*
* Builds allocation fallback zone lists.
*/
static inline void build_zonelists(pg_data_t *pgdat)
{
int i, j, k;
// 遍历最大可能数量的管理区。GFP_ZONEMASK(15)
for (i = 0; i <= GFP_ZONEMASK; i++) {
zonelist_t *zonelist;
zone_t *zone;
// 获取管理区的 zonelist 并归 0。
zonelist = pgdat->node_zonelists + i;
memset(zonelist, 0, sizeof(*zonelist));
// 与 ZONE_DMA 对应,j 从 0 开始。
j = 0;
// 设置 k 为当前检查过的管理区类型。
k = ZONE_NORMAL;
if (i & __GFP_HIGHMEM)
k = ZONE_HIGHMEM;
if (i & __GFP_DMA)
k = ZONE_DMA;
switch (k) {
default:
BUG();
/*
* fallthrough:
*/
case ZONE_HIGHMEM:
// 获取 ZONE_HIGHMEM。
zone = pgdat->node_zones + ZONE_HIGHMEM;
// 如果管理区有内存,ZONE_HIGHMEM 就是从高端内存分配的相应管理区。
// 如果 ZONE_HIGHMEM 没有内存,ZONE_NORMAL 将在下一次变成相应的管理区,这是
// 因为 j 并没有在空管理区时加 1。
if (zone->size) {
#ifndef CONFIG_HIGHMEM
BUG();
#endif
zonelist->zones[j++] = zone;
}
// 设置下一个相应的管理区中分配的为 ZONE_NORMAL,同样,如果管理区没
// 有内存就不使用它。
case ZONE_NORMAL:
zone = pgdat->node_zones + ZONE_NORMAL;
if (zone->size)
zonelist->zones[j++] = zone;
case ZONE_DMA:
// 设置最后的回退管理区为 ZONE_DMA。这个检查也对拥有内存的 ZONE_DMA
// 进行。在 NUMA 体系结构中,不是所有的节点都有 ZONE_DMA。
zone = pgdat->node_zones + ZONE_DMA;
if (zone->size)
zonelist->zones[j++] = zone;
}
zonelist->zones[j++] = NULL;
}
}
(a)⇐ mmzone.h
// include/linux/mmzone.h
#define ZONE_DMA 0
#define ZONE_NORMAL 1
#define ZONE_HIGHMEM 2
#define MAX_NR_ZONES 3
/*
* One allocation request operates on a zonelist. A zonelist
* is a list of zones, the first one is the 'goal' of the
* allocation, the other zones are fallback zones, in decreasing
* priority.
*
* Right now a zonelist takes up less than a cacheline. We never
* modify it apart from boot-up, and only a few indices are used,
* so despite the zonelist table being relatively big, the cache
* footprint of this construct is very small.
*/
typedef struct zonelist_struct {
zone_t * zones [MAX_NR_ZONES+1]; // NULL delimited
} zonelist_t;
#define GFP_ZONEMASK 0x0f
build_zonelists 函数执行后,pgdat->node_zonelists 为 15 个大小。其大致如下:

15 个 zonelist_t, k 的值依次为 ZONE_NORMAL、ZONE_DMA、ZONE_HIGHMEM、ZONE_DMA,每 4 个循环一次。而每个 zonelist_t 中有 4 个 zone_t,其值为:
- 当为 ZONE_NORMAL 时,4 个 zone_t 依次为指向 NORMAL、DMA、NULL、NULL
- 当为 ZONE_DMA 时,4 个 zone_t 依次为指向 DMA、NULL、NULL、NULL
- 当为 ZONE_HIGHMEM 时,4 个 zone_t 依次为指向 HIGHMEM、NORMAL、DMA、NULL
123