数据的存储方式(Parquet、ORC)
文章目录
-
- 数据的存储方式
-
- 按行存储
- 按列存储
- Parquest
-
- 文件布局
-
- 概念
-
- 并行处理的单元
- 配置
-
- Row Group Size 行组的大小
- Data Page Size 数据页的大小
- 元数据
- 数据页
- Hive下的Parquet实验
- Parquet简单工具的使用
- 支持的组件
- Apache ORC
-
- 文件布局
-
- Stripe
- Hive下的Parquet实验
- ORC简单工具的使用
- 支持的组件
- 数据存储中的编码
-
- 二进制编码方式
数据的存储方式
目前的数据存储方式分为行式和列式。
按行存储
常见的关系型数据库,如Oracle、DB2、MySQL、SQL SERVER都是行式存储的, 在我们查询的条件需要得到大多数列的时候, 相对列式格式,查询效率更高。基础逻辑存储单元是行数据,在存储介质中是以连续存储的形式存在的。
Hive中的的TextFile文件存储格式中的数据就按行式存储的。
按列存储
大部分分布式分析型数据库,如Hbase、hive、Druid采用是列式存储,
列式存储, 它存储的方式是采用数据按照行分块,每个块按照列存储。
| 姓名 | 性别 | 年龄 |
|---|---|---|
| 张三 | 男 | 20 |
| 李四 | 女 | 30 |
| 王五 | 女 | 40 |
| 赵六 | 男 | 50 |
| 张三 | 李四 | 王五 | 赵六 | 男 | 女 | 女 | 男 | 20 | 30 | 40 | 50 |
|---|
| 张三 | 男 | 20 | 李四 | 女 | 30 | 王五 | 女 | 40 | 赵六 | 男 | 50 |
|---|
简单的对比
| 行式存储 | 列式存储 | |
|---|---|---|
| 特点 | 1.每一行的所有字段都存在一起 2.查询时即使只涉及某几列,所有数据都会被读取 3.读取时硬盘寻址范围很大 4.适合事务性操作 5.主要用于在线交易处理(OLTP)场景的数据存储 |
1.每一列的所有数据存在一起,不同列之间支持分开存储 2.查询时只有涉及到的列会被读取 3.读取时硬盘寻道范围小 4.不适合事务性操作 5.主要用于在线分析处理(OLAP)场景的数据存储 |
| 优点 | 1.对数据进行插入和修改操作很方便 2.适合随机查询;在整行的读取上,要优于列式存储 |
1.采用每一列单独存储时,任何列都具有索引能力 2.同列数据具有相同类型,易于压缩,占用空间小 3.为每一列创建一个字典,存储的时候就仅存储数字编码,降低了存储空间需求 4.利用数据聚合操作 |
| 缺点 | 1.不适合扫描,这意味着要查询一个范围的数据 2.为加速查询会建索引,建立索引很耗时 3.不利于压缩,占用空间大 4.不适合聚合操作 |
1.插入和修改操作麻烦,不适合数据频繁变更的场景 2.查询完成时,被查询的列要重新进行组装 |
| **文件格式 ** | Text File、Sequence File、 Avro file | RCFile、ORC File、Parquet、Arrow |
数据通用压缩算法
- Gzip
- bzip2
- LZO
- LZ4
- Snappy
- zstd
Parquest
(一句话介绍)
Apache Parquet是一种列式存储格式,最初的目的是可供Hadoop生态系统中的任何项目使用,无论选择何种数据处理框架、数据模型或编程语言。
支持高校的压缩和编码方案。具有良好的向后兼容性。
文件布局
概念
block (hdfs块): 代表hdfs中的一个块,其含义对于Parquet这种文件格式来说是不变的。Parquet文件格式被设计为能在hdfs之上很好地工作。
File:一个hdfs文件,必须包括文件的元数据。它不需要实际包含数据。
Row group行组: 将数据横向分割成行的逻辑。对于行组来说,没有任何物理结构是可以保证的。一个行组由数据集中的每一列的列块组成。
Column chunk 列块: 一个特定列的数据块。这些数据生活在一个特定的行组中,并保证在文件中是连续的。
Page 页: 列块被划分为页。在概念上,一个页面是一个不可分割的单位(在压缩和编码方面)。在一个列块中可以有多个页面类型,它们交错排列。
在层次上,一个文件由一个或多个行组组成。一个行组中每一列正好包含一个列块。列块包含一个或多个页面。
并行处理的单元
| 处理框架 | 处理粒度 |
|---|---|
| MapReduce | File/Row group |
| IO | Column chunk |
| 编码/压缩 | Page |
为了支持嵌套类型的数据,Parquet使用了definition层和repetition层的Dremel编码。
Definition 层指定了列的路径中有多少个可选字段被定义。
Repetition 层指定路径中的重复字段在什么地方有重复值。(Repetition 重复 重叠)
配置
Row Group Size 行组的大小
更大的行组允许更大的列块,从而可以执行更大的连续IO。较大的组也需要在写入路径上有更多的缓冲(或两次写入)。我们推荐行组大小为(512MB - 1GB)。由于整个行组可能需要被读取,我们希望它能完全容纳在一个HDFS块中。因此,HDFS块的大小也应该被设置得更大。一个优化的读取设置将是: 1GB的行组,1GB的HDFS块大小,每个HDFS文件有一个HDFS块。
❓HDFS的块的大小不是128MB或者512GB的吗?可以调整成1GB?或者是设置成128MB的倍数
Data Page Size 数据页的大小
数据页应该被认为是不可分割的(即最小的数据处理单元),所以较小的数据页允许更精细的读取(例如,单行查找)。较大的页面尺寸会产生较少的空间开销(较少的页眉)和解析开销(处理页眉)。注意:对于顺序扫描,预计不会一次读取一个页面;这不是IO块。建议页面大小为8KB。
元数据
有三种类型的元数据:文件元数据(FileMetaData)、列(chunk)元数据和页眉元数据。所有的thrift结构都使用TCompactProtocol进行序列化。
数据页
对于数据页,这3个信息是在页眉之后连续编码的。我们有
- 定义层的数据、
- 重复层的数据、
- 编码的值。页眉中指定的大小是所有3个部分的和。
数据页是必要存在的数据的。根据模式的定义,定义层和重复层是可选的。如果列不是嵌套的(即列的路径长度为1),我们不对重复层进行编码(它总是有1的值)。对于需要的数据,定义层被跳过(如果编码,它将总是有最大定义层的值)。
例如,在列非嵌套且是必需的情况下,页面中的数据只是编码后的值。
Hive下的Parquet实验
-- 创建专用数据库
create DATABASE if not EXISTS test_fileformat COMMENT '文件格式测试的库' WITH DBPROPERTIES ('createUser'='顾栋','date'='20230609');
-- 创建无非嵌套字段表
CREATE TABLE test_fileformat.parquet_test (
id int,
name string,
d string
)
STORED AS PARQUET tblproperties ("orc.compress"="NONE");
-- 表创建完成之后 并非立即产生hdfs文件,只是创建了对于的hdfs路径
INSERT INTO TABLE test_fileformat.parquet_test VALUES (1, '张三', '我是张三,呼叫李四'), (2, '李四', '我是李四,呼叫张三');
INSERT INTO TABLE test_fileformat.parquet_test VALUES (3, '王五', '我是王五,呼叫赵六'),(4, '赵六', '');
Drop table test_fileformat.parquet_test;
-- 创建含嵌套字段表 tag是一个复杂类型 是一个struct的数组 struct里面有两个字段tagid,weight
create table test_fileformat.parquet_nested_test (uid string ,tag array<struct<tagid:string,weight:string>>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ' '
MAP KEYS TERMINATED BY ':'
STORED AS PARQUET tblproperties ("orc.compress"="NONE");
INSERT INTO TABLE test_fileformat.parquet_nested_test select '221190xxx9',array(named_struct('tagid',cast(0.30 as string),'weight',cast(0.31 as string)),named_struct('tagid',cast(0.21 as string),'weight',cast(0.11 as string))) as tag;
INSERT INTO TABLE test_fileformat.parquet_nested_test select '221190xxx9',array(named_struct('tagid',cast(0.30 as string),'weight',cast(0.31 as string)),named_struct('tagid',cast(0.21 as string),'weight',cast(0.11 as string))) as tag;
Drop table test_fileformat.parquet_nested_test;
DROP DATABASE test_fileformat;
文件系统
# hadoop dfs -ls -r /user/bigdata/hive/warehouse/test_fileformat.db/parque_test
-rwxr-xr-x 2 bigdata supergroup 595 2023-06-09 11:16 /user/bigdata/hive/warehouse/test_fileformat.db/parquet_test/000000_0
# hadoop dfs -ls -r /user/bigdata/hive/warehouse/test_fileformat.db/parquet_nested_test
-rwxr-xr-x 2 bigdata supergroup 588 2023-06-09 14:46 /user/bigdata/hive/warehouse/test_fileformat.db/parquet_nested_test/000000_0_copy_1
-rwxr-xr-x 2 bigdata supergroup 588 2023-06-09 14:46 /user/bigdata/hive/warehouse/test_fileformat.db/parquet_nested_test/000000_0
Parquet简单工具的使用
根据Parquet文件的定义,每一个Parquet文件都可以单独进行读写和分析。可以使用parquet-cli工具进行简单操作。
java -cp parquet-cli-1.13.1.jar;dependency/* org.apache.parquet.cli.Main meta 000000_0
java -cp parquet-cli-1.13.1.jar;dependency/* org.apache.parquet.cli.Main schema 000000_0
java -cp parquet-cli-1.13.1.jar;dependency/* org.apache.parquet.cli.Main footer 000000_0
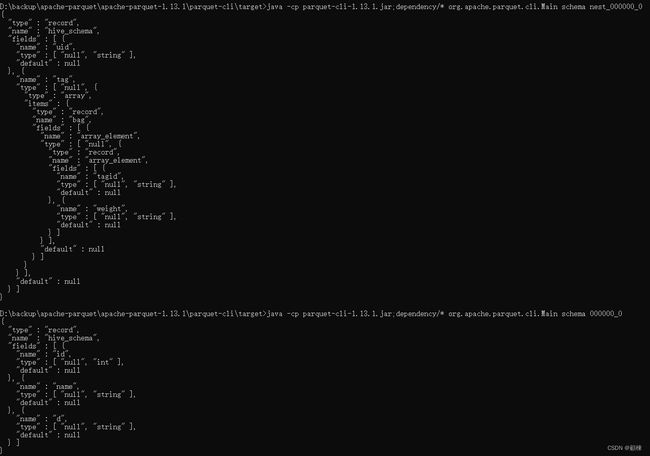
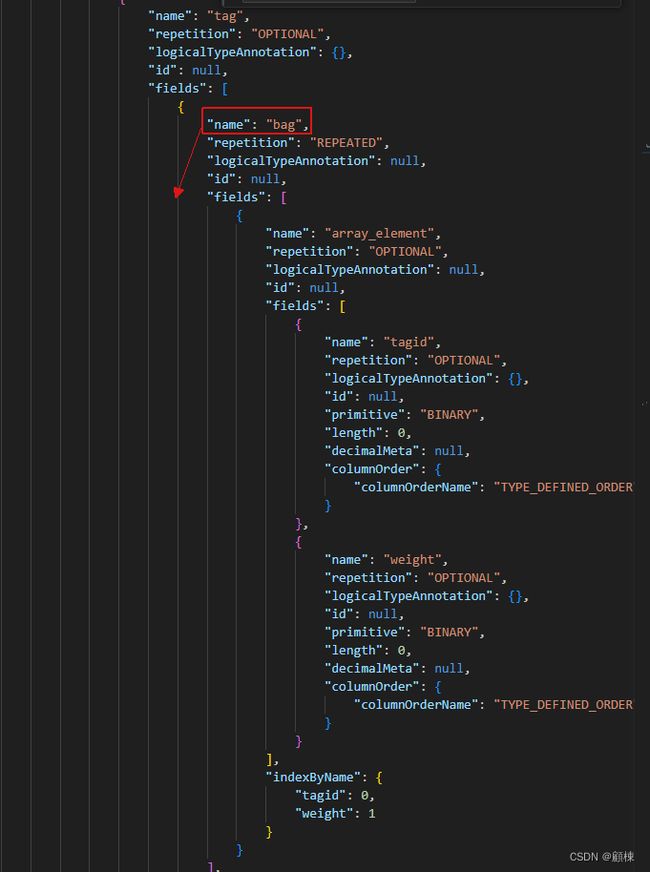
bag:袋子;一套,通过repetition:REPEATED表达字段的嵌套
支持的组件
- Apache Hive
- Apache HDFS
- Apache Doris
- Apache iceberg
- Apace hudi
Apache ORC
(一句话介绍)
Apache Orc也是一种列式存储格式,最初主要是为了极大加速Apache Hive和提高存储在Apache Hadoop中的数据的存储效率,目的是支持高速处理和减小文件大小。
目前有Orc V0(伴随Hive 0.11发布)和ORC V1(伴随Hive 0.12发布)两个版本。
文件布局
文件由1个或1个以上的Stripe,一个文件页脚,一个后记组成。
Orc文件的读取是反向读取,先读取文件尾部,解析出必要信息,再去读取具体数据。
文件尾部由三部分组成;
- 文件元数据:包含stripe粒度的列统计。这些统计信息基于每个stripe评估的谓词下推启用输入拆分消除。在谓词下推的是时候会根据这些统计信息进行对stripe进行评估,来筛选数据。
- 文件页脚:页脚部分包含文件正文的布局、类型模式信息、行数和每列的统计信息。
- 后记(Postscript):提供解析文件其余部分的必要信息,包括文件的页脚和元数据部分的长度、文件的版本以及使用的一般压缩类型(例如 none、zlib 或 snappy)。
Stripe
文件的主体被分成stripes。 每个stripe都是独立的,可以仅使stripe被本身的字节与文件的页脚和后记相结合来读取(每个stripe可以被独立的读取)。大小一般为200+MB。
stripe包含三个部分:
- 索引流:未加密的数据在前,加密的数据在后,行组索引由每个原始列的 ROW_INDEX 流组成,每个原始列都有一个行组条目。 行组由编写器控制,默认为 10,000 行。 每个 RowIndexEntry 给出列的每个流的位置和该行组的统计信息。因为在默认的流式传输情况下不需要读取索引。 它们仅在使用谓词下推或读取器查找特定行时加载使用。
- 数据流:未加密的数据在前,加密的数据在后
- stripe的页脚:包含每一列的编码和流的目录,包括它们的位置
encryptStripeId 和 encryptedLocalKeys 支持列加密。 它们设置在每个带有列加密的 ORC 文件的第一个stripe上,之后不设置。
Hive下的Parquet实验
-- 创建专用数据库
create DATABASE if not EXISTS test_fileformat COMMENT '文件格式测试的库' WITH DBPROPERTIES ('createUser'='顾栋','date'='20230609');
-- 创建无非嵌套字段表
create table test_fileformat.orc_test (
id int,
name string,
d string
) stored as orc tblproperties ("orc.compress"="NONE");
INSERT INTO TABLE test_fileformat.orc_test VALUES (1, '张三', '我是张三,呼叫李四'),(2, '李四', '我是李四,呼叫张三');
INSERT INTO TABLE test_fileformat.orc_test VALUES (3, '王五', '我是王五,呼叫赵六'),(4, '赵六', '');
Drop table test_fileformat.orc_test;
-- 创建含嵌套字段表 tag是一个复杂类型 是一个struct的数组 struct里面有两个字段tagid,weight
create table test_fileformat.orc_nested_test (uid string ,tag array<struct<tagid:string,weight:string>>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ' '
MAP KEYS TERMINATED BY ':'
STORED AS orc tblproperties ("orc.compress"="NONE");
INSERT INTO TABLE test_fileformat.orc_nested_test select '221190xxx9',array(named_struct('tagid',cast(0.30 as string),'weight',cast(0.31 as string)),named_struct('tagid',cast(0.21 as string),'weight',cast(0.11 as string))) as tag;
INSERT INTO TABLE test_fileformat.orc_nested_test select '221190xxx9',array(named_struct('tagid',cast(0.30 as string),'weight',cast(0.31 as string)),named_struct('tagid',cast(0.21 as string),'weight',cast(0.11 as string))) as tag;
Drop table test_fileformat.orc_nested_test;
DROP DATABASE test_fileformat;
文件系统
# hadoop dfs -ls -r /user/bigdata/hive/warehouse/test_fileformat.db/orc_test
-rwxr-xr-x 2 bigdata supergroup 502 2023-06-09 17:16 /user/bigdata/hive/warehouse/test_fileformat.db/orc_test/000000_0_copy_1
-rwxr-xr-x 2 bigdata supergroup 611 2023-06-09 17:15 /user/bigdata/hive/warehouse/test_fileformat.db/orc_test/000000_0
# hadoop dfs -ls -r /user/bigdata/hive/warehouse/test_fileformat.db/orc_nested_test
-rwxr-xr-x 2 bigdata supergroup 590 2023-06-09 17:19 /user/bigdata/hive/warehouse/test_fileformat.db/orc_nested_test/000000_0_copy_1
-rwxr-xr-x 2 bigdata supergroup 590 2023-06-09 17:19 /user/bigdata/hive/warehouse/test_fileformat.db/orc_nested_test/000000_0
ORC简单工具的使用
# 查看orc的元数据信息
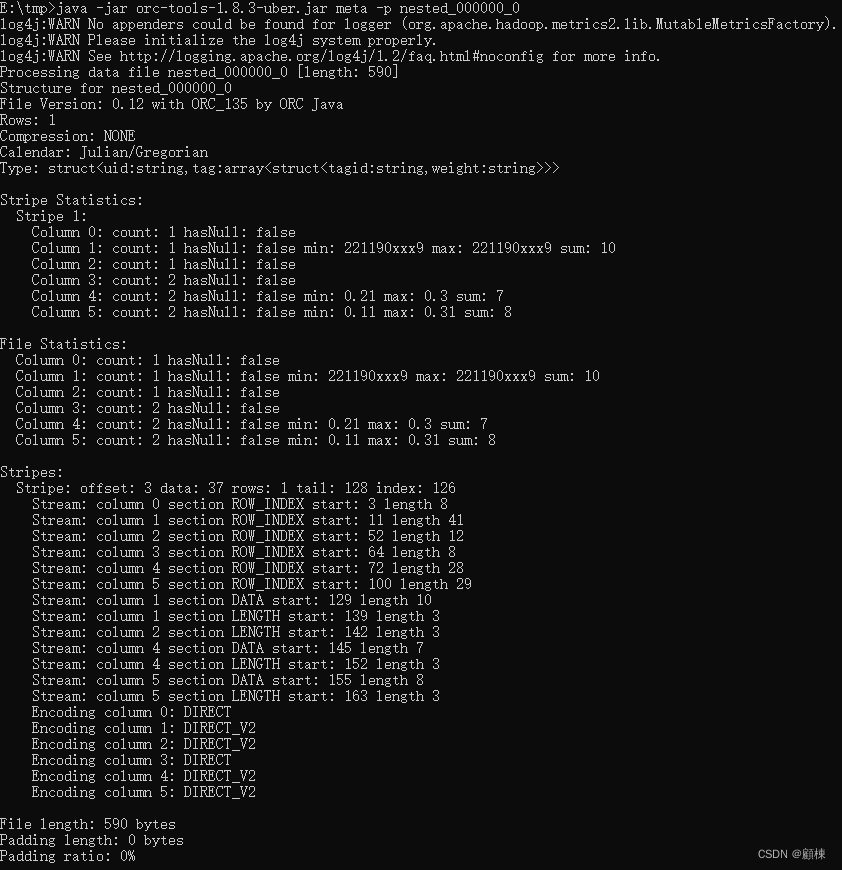
java -jar orc-tools-1.8.3-uber.jar meta -p 000000_0
# 查看orc文件中的记录数
java -jar orc-tools-1.8.3-uber.jar data -n 2 000000_0

支持的组件
- Apache Hive
- Apache HDFS
- Apache Doris
- Apache iceberg
- Apace hudi
数据存储中的编码
字典编码
位打包
增量编码
游程编码
二进制编码方式
Thrift
avro
arrow