《Flink应用实战》(五)--流合并-Connect算子
目录
一、基本概念
1.流合并条件
2.Flink 中支持 双流join 的算子
二、Connect介绍
1. Connect算子特点
2.Connect算子和union算子区别
3.广播连接流(BroadcastConnectedStreams)
三、Connect开发实战
1、connect连接流的map应用
2、connect连接流的flatMap应用
一、基本概念
1.流合并条件
Flink 中的两个流要实现 Join 操作,必须满足以下两点:
-
流需要能够等待,即:两个流必须在同一个窗口中;
-
双流等值 Join,即:两个流中,必须有一个字段相等才能够 Join 上。
2.Flink 中支持 双流join 的算子
Flink 中支持双流 Join 的算子目前已知有5种,如下:
-
**union**:union 支持双流 Join,也支持多流 Join。多个流类型必须一致; -
**connector**:connector 支持双流 Join,两个流的类型可以不一致; -
**join**:该方法只支持 inner join,即:相同窗口下,两个流中,Key都存在且相同时才会关联成功; -
**coGroup**:同样能够实现双流 Join。即:将同一 Window 窗口内的两个DataStream 联合起来,两个流按照 Key 来进行关联,并通过 apply()方法 new CoGroupFunction() 的形式,重写 join() 方法进行逻辑处理。 -
**intervalJoin**:Interval Join 没有 Window 窗口的概念,直接用时间戳作为关联的条件,更具表达力。
join() 和 coGroup() 都是 Flink 中用于连接多个流的算子,但是两者也有一定的区别,推荐能使用 coGroup 不要使用Join,因为coGroup更强大(**inner join 除外。就 inner join 的话推荐使用 join ,因为在 join 的策略上做了优化,更高效**)
二、Connect介绍
1. Connect算子特点
-
只能用于连接两个DataStream流,不能用于DataSet;
-
连接的两个数据流数据类型可以不同。
-
连接后两个流可以使用不同的处理方法,两个流可以共享状态。
-
连接的结果为一个ConnectedStream流。
-
连接的两个流可以是DataStream或者是 BroadcastStream(广播数据流)。
-
连接两个DataStream流,返回一个新的ConnectedStream
publicConnectedStreams dataStream) { return new ConnectedStreams<>(environment, this, dataStream); } -
连接的数据流其中一个是 BroadcastStream(广播数据流),返回一个新的 BroadcastConnectedStream。
publicBroadcastConnectedStream broadcastStream) { return new BroadcastConnectedStream<>( environment, this, Preconditions.checkNotNull(broadcastStream), broadcastStream.getBroadcastStateDescriptor()); } -
2.Connect算子和union算子区别
union虽然可以合并多个数据流,但有一个限制,即多个数据流的数据类型必须相同。connect提供了和union类似的功能,用来连接两个数据流,它与union的区别在于:
-
connect只能连接两个数据流,union可以连接多个数据流。 -
connect所连接的两个数据流的数据类型可以不一致,union所连接的两个数据流的数据类型必须一致。 -
两个
DataStream经过connect之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且双流之间可以共享状态。
connect经常被应用在对一个数据流使用另外一个流进行控制处理的场景上,如下图所示。控制流可以是阈值、规则、机器学习模型或其他参数。
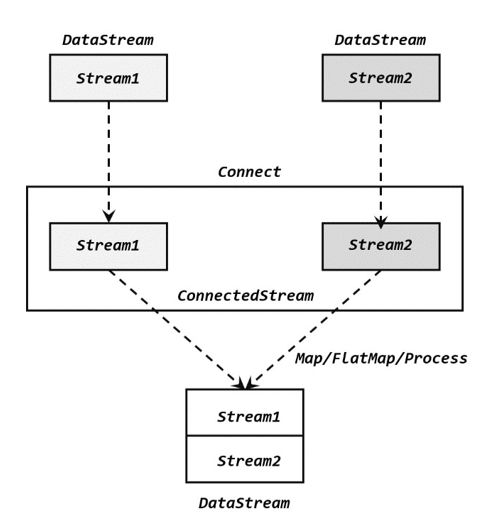
对于ConnectedStreams,我们需要重写CoMapFunction或CoFlatMapFunction。这两个接口都提供了三个泛型,这三个泛型分别对应第一个输入流的数据类型、第二个输入流的数据类型和输出流的数据类型。在重写函数时,对于CoMapFunction,map1处理第一个流的数据,map2处理第二个流的数据;对于CoFlatMapFunction,flatMap1处理第一个流的数据,flatMap2处理第二个流的数据。Flink并不能保证两个函数调用顺序,两个函数的调用依赖于两个数据流数据的流入先后顺序,即第一个数据流有数据到达时,map1或flatMap1会被调用,第二个数据流有数据到达时,map2或flatMap2会被调用。
3.广播连接流(BroadcastConnectedStreams)
DataStream 调用.connect()方法时,传入的参数也可以不是一个DataStream,而是一个“广播流”(BroadcastStream),这时合并两条流得到的就变成了一个“广播连接流”。
这种连接方式往往用在需要动态定义某些规则或配置的场景。因为规则是实时变动的,所以我们可以用一个单独的流来获取规则数据;而这些规则或配置是对整个应用全局有效的,所以不能只把这数据传递给一个下游并行子任务处理,而是要“广播”(broadcast)给所有的并行子任务。而下游子任务收到广播出来的规则,会把它保存成一个状态,这就是所谓的“广播状态”(broadcast state)。
三、Connect开发实战
1、connect连接流的map应用
import com.alibaba.fastjson.JSON;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.table.shaded.org.joda.time.format.DateTimeFormat;
import org.apache.flink.table.shaded.org.joda.time.format.DateTimeFormatter;
import org.apache.flink.util.Collector;
import org.apache.flink.table.shaded.org.joda.time.DateTime;
import java.util.Properties;
public class TextConnect {
public static void main(String[] args) throws Exception {
//1、创建环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.1 设置窗口时间为事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//1.2 设置并行度
env.setParallelism(1);
//2、获取数据源
//2.1 获取用户的浏览信息
DataStream userBrowseStream = getUserBrowseDataStream(env);
//2.2 获取用户点击信息
DataStream userClickStream = getUserClickStream(env);
//打印结果
userBrowseStream.print();
userClickStream.print();
//3、数据转换
//3.1 进行双流Connect操作
ConnectedStreams connectStream = userBrowseStream.connect(userClickStream);
DataStream resData = connectStream.map(new CoMapFunction() {
@Override
public String map1(UserBrowseLog value) throws Exception {
return value.getProductID();
}
@Override
public String map2(UserClickLog value) throws Exception {
return value.getUserID();
}
});
//打印结果
resData.print();
//4、执行
env.execute("TextConnect");
//输出结果
//UserBrowseLog{userID='1', eventTime='2022-06-30 12:20:04', eventType='Xiaomi', productID='pd0001', productPrice=99}
//pd0001
//UserClickLog{userID='2', eventTime='2022-06-30 12:20:04', eventType='HuaWei', pageID='11'}
//2
}
private static DataStream getUserBrowseDataStream(StreamExecutionEnvironment env) {
//联接kafka
// Properties consumerProperties = new Properties();
// consumerProperties.setProperty("bootstrap.severs","page01:9001");
// consumerProperties.setProperty("grop.id","browsegroup");
// //加载kafka数据源
// DataStreamSource dataStreamSource = env.addSource(new FlinkKafkaConsumer("browse_topic", new SimpleStringSchema(), consumerProperties));
//数据格式:{"userID":1,"productID":"pd0001","productPrice":99.2,"eventType":"Xiaomi","eventTime":"2022-06-30 12:20:04"}
DataStreamSource dataStreamSource = env.socketTextStream("127.0.0.1", 9999);
//kafka消息序列化成对象
DataStream processData = dataStreamSource.process(new ProcessFunction() {
@Override
public void processElement(String value, Context ctx, Collector out) throws Exception {
try {
UserBrowseLog browseLog = JSON.parseObject(value, UserBrowseLog.class);
if (browseLog != null) {
out.collect(browseLog);
}
} catch (Exception e) {
System.out.println("解析Json——UserBrowseLog异常:" + e.getMessage());
}
}
});
//设置watermark
return processData.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor(Time.seconds(1)) {
@Override
public long extractTimestamp(UserBrowseLog element) {
DateTimeFormatter dateTimeFormatter= DateTimeFormat.forPattern("yyyy-MM-dd HH:mm:ss");
DateTime dateTime=DateTime.parse(element.getEventTime(),dateTimeFormatter);
//用数字表示时间戳,单位是ms,13位
return dateTime.getMillis();
}
});
}
private static DataStream getUserClickStream(StreamExecutionEnvironment env) {
// //联接kafka
// Properties consumerProperties = new Properties();
// consumerProperties.setProperty("bootstrap.severs","page01:9001");
// consumerProperties.setProperty("grop.id","browsegroup");
// //加载kafka数据源
// DataStreamSource dataStreamSource = env.addSource(new FlinkKafkaConsumer("browse_topic", new SimpleStringSchema(), consumerProperties));
//数据格式:{"userID":2,"pageID":11,"eventType":"HuaWei","eventTime":"2022-06-30 12:20:04"}
DataStreamSource dataStreamSource = env.socketTextStream("127.0.0.1", 9998);
DataStream processData = dataStreamSource.process(new ProcessFunction() {
@Override
public void processElement(String value, Context ctx, Collector out) throws Exception {
try {
UserClickLog userClickLog = JSON.parseObject(value, UserClickLog.class);
if (userClickLog != null) {
out.collect(userClickLog);
}
} catch (Exception e) {
System.out.print("解析Json——UserClickLog异常:" + e.getMessage());
}
}
});
//设置watermark
return processData.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor(Time.seconds(1)) {
@Override
public long extractTimestamp(UserClickLog element) {
DateTimeFormatter dateTimeFormatter= DateTimeFormat.forPattern("yyyy-MM-dd HH:mm:ss");
DateTime dateTime=DateTime.parse(element.getEventTime(),dateTimeFormatter);
//用数字表示时间戳,单位是ms,13位
return dateTime.getMillis();
}
});
}
}
import java.io.Serializable;
//浏览bean
public class UserBrowseLog implements Serializable {
private String userID;
private String eventTime;
private String eventType;
private String productID;
private Integer productPrice;
public String getUserID() {
return userID;
}
public String getEventTime() {
return eventTime;
}
public String getEventType() {
return eventType;
}
public String getProductID() {
return productID;
}
public Integer getProductPrice() {
return productPrice;
}
public void setUserID(String userID) {
this.userID = userID;
}
public void setEventTime(String eventTime) {
this.eventTime = eventTime;
}
public void setEventType(String eventType) {
this.eventType = eventType;
}
public void setProductID(String productID) {
this.productID = productID;
}
public void setProductPrice(Integer productPrice) {
this.productPrice = productPrice;
}
@Override
public String toString() {
return "UserBrowseLog{" +
"userID='" + userID + '\'' +
", eventTime='" + eventTime + '\'' +
", eventType='" + eventType + '\'' +
", productID='" + productID + '\'' +
", productPrice=" + productPrice +
'}';
}
}
import java.io.Serializable;
//点击bean
public class UserClickLog implements Serializable {
private String userID;
private String eventTime;
private String eventType;
private String pageID;
public void setUserID(String userID) {
this.userID = userID;
}
public void setEventTime(String eventTime) {
this.eventTime = eventTime;
}
public void setEventType(String eventType) {
this.eventType = eventType;
}
public void setPageID(String pageID) {
this.pageID = pageID;
}
public String getUserID() {
return userID;
}
public String getEventTime() {
return eventTime;
}
public String getEventType() {
return eventType;
}
public String getPageID() {
return pageID;
}
@Override
public String toString() {
return "UserClickLog{" +
"userID='" + userID + '\'' +
", eventTime='" + eventTime + '\'' +
", eventType='" + eventType + '\'' +
", pageID='" + pageID + '\'' +
'}';
}
}
2、connect连接流的flatMap应用
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoFlatMapFunction;
import org.apache.flink.util.Collector;
public class ConnectOpDemo1 {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStream> src1 = env.fromElements(
new Tuple2<>("shanghai", 15),
new Tuple2<>("beijing", 25));
DataStream src4 = env.fromElements(2, 3);
ConnectedStreams, Integer> connStream = src1.connect(src4);
// 对不同类型的流,进行不同的处理,并统一输出成一个新的数据类型。
// 这里,我把两个流的数据都转成了String类型,这样方便后续的处理。
DataStream res = connStream.flatMap(new CoFlatMapFunction, Integer, String>() {
@Override
public void flatMap1(Tuple2 value, Collector out) {
out.collect(value.toString());
}
@Override
public void flatMap2(Integer value, Collector out) {
String word = String.valueOf(value);
out.collect(word);
}
});
res.print();
env.execute();
//输出结果
//3> 2
//4> 3
//2> (shanghai,15)
//3> (beijing,25)
}
} 参考资料:
滑动验证页面
Flink的Union算子和Connect算子,流合并_月疯的博客-CSDN博客_flink union和connect
Flink实战--多流合并_一 铭的博客-CSDN博客_flink 多流合并
最新 Flink 1.13 多流转换(Union、Connect、Window Join、Interval Join、Window CoGroup)快速入门、详细教程_数据文的博客-CSDN博客_flink 多流connect
Flink算子使用方法及实例演示:union和connect - 掘金