鱼眼摄像头 实时动、静目标的检测,跟踪,分类
论文:《Real-time Detection, Tracking, and Classification of Moving and Stationary Objects using Multiple Fisheye Images》
作者:Iljoo Baek∗, Albert Davies∗, Geng Yan, and Ragunathan (Raj) Rajkumar
发表日期:2018.3.16
摘要:
检测行人以及其他运动目标对自动驾驶来说至关重要。这必须以最小系统开销做到实时处理。本文讨论了利用环视系统来对本车(装有环视系统车辆)附近的运动及静止目标做识别。4个鱼眼摄像头分别捕获图像后融合成的一张图像,算法是在该融合图像上做的处理。运动目标检测与跟踪解决方案利用最小系统隔离出ROI区域,这些ROI区域包含运动目标。利用DNN来对这些ROI中的运动目标做分类。我们在一辆车上布置该套系统并在城市工况下做了测试,验证了该算法实践灵活性。
1.介绍(抽重点翻译)
本文呈现了一个能够对车辆周边物体做实时检测与分类一些运动目标的解决方案。并搭载在Carnegie Mellon University的自动驾驶研究车——Cadillac SRX上。
A.相关工作
检测车辆周边障碍物的方法有: 用基于lidar和radar的方法 [2] H. Wang, B. Wang, B. Liu, X. Meng, and G. Yang, “Pedestrian recognition and tracking using 3d lidar for autonomous vehicle,” Robotics and Autonomous Systems, vol. 88, pp. 71–78, 2017.。 基于立体摄像头获取额外深度信息的方法 [3] N. Bernini, M. Bertozzi, L. Castangia, M. Patander, and M. Sabbatelli, “Real-time obstacle detection using stereo vision for autonomous ground vehicles: A survey,” in Intelligent Transportation Systems (ITSC), 2014 IEEE 17th International Conference on. IEEE, 2014, pp. 873–878.。 用来自4个鱼眼摄像头做目标检测与跟踪的方法 [4] M. Bertozzi, L. Castangia, S. Cattani, A. Prioletti, and P. Versari, “360 detection and tracking algorithm of both pedestrian and vehicle using fisheye images,” in Intelligent Vehicles Symposium (IV), 2015 IEEE. IEEE, 2015, pp. 132–137.。 基于多传感器的数据融合方法。 一旦获取环境信息后,可通过 处理单帧图像或者 对比相邻帧图像来检测目标。其中 通过处理单帧图像可利用 基于特征或 机器学习的方法实现,这类方法是在单帧中寻找多种类别,诸如行人,自行车, 缺点是需要大的计算量,并且可能对潜在危险目标(这类目标由于在训练时没有先验知识,本人理解为在训练模型时可能样本只有人,自行车这类,如实际中可能出现过来的狗,猫等)遗漏的情况。其中 通过处理相邻帧的检测方法的 优势在于利用了目标运动特性来减少搜索区域和计算时间,基于光流的方法是这类方法中较为流行的。当与跟踪相结合时,这些方法即使在没有相对运动的情况下也能检测到物体,如果物体在过去任何时候都在移动的话。其他的方法是将这类方法结合在一起来开发出一种混合方法 [6] J. Choi, “Realtime on-road vehicle detection with optical flows and haar-like feature detectors,” Tech. Rep., 2012.。
B.本文贡献(重点哈)
为了达到实际需求,我们做了些设计选择。运动目标的检测时再CPU中进行,基于DNN的分类器是在GPU中进行。最大的挑战是维持低计算量,这对于能同时实时处理来自4个鱼眼摄像头图像流至关重要。为了实现低计算量,我们规避了相似解决方案中常会用到的De-Wrap这个步骤[4] M. Bertozzi, L. Castangia, S. Cattani, A. Prioletti, and P. Versari, “360 detection and tracking algorithm of both pedestrian and vehicle using fisheye images,” in Intelligent Vehicles Symposium (IV), 2015 IEEE. IEEE, 2015, pp. 132–137.。 我们的算法是直接在获取的鱼眼摄像头捕获图像上开发。
我们将 四个鱼眼视频流融合成一个视频流做处理,而不是4个分别处理。我们 处理4个视频流中固定ROI的内容,如图1所示(每个视野中都有3个固定的ROI区域)。这使我们能够缩小搜索范围,并将查找移动对象所在位置的任务转换为更简单的任务——只需确定某一特定区域是否包含一个移动的对象。为了确保在它停止移动之后仍然检测到一个先前检测到的移动对象,我们已经开发了一个使用稀疏LK算法的更简单的跟踪版本。
我们的解决方案另一个优势是具有足够的可移植性,可以独立于平台。为了实现这一目标,在OpenCV中实施检测和跟踪。这些模块也相互独立开发,这允许我们在必要时只启用某个子模块。这也使得模块可以在不需要大量使用新解决方案的情况下集成。我们已经对一辆真车进行了广泛的测试,并使用了离线计算。我们的整个解决方案已经移植到x86、TI TDA2x和NVIDIA TX2。
2.架构与算法(抽重点翻译)
整个方案的框架包含 检测, 跟踪和 分类模块。 检测模块对每个视野中固定的ROI区域做运动目标检测。 跟踪模块确保那些之前检测到的目标能够持续被检测到,即使它停止运动。 分类模块用深度学习来对运动目标做分类。各类模块的设计与功能解释一下。
A.检测
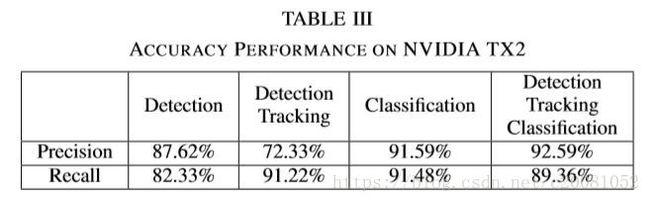
图2是我们检测与跟踪的pipeline。如图所示, 第一步是对相邻帧做背景提取,这么做能将我们的搜索范围缩小到只有运动目标的区域。接着在背景提取后的图像上 找适当的特征点用作跟踪,类似可使用的特征描述子有SIFT( D. G. Lowe, “Object recognition from local scale-invariant features,” in Computer vision, 1999. The proceedings of the seventh IEEE international conference on, vol. 2. Ieee, 1999, pp. 1150–1157.),SURF( H. Bay, T. Tuytelaars, and L. Van Gool, “Surf: Speeded up robust features,” Computer vision–ECCV 2006, pp. 404–417, 2006.),BRIEF( M. Calonder, V. Lepetit, C. Strecha, and P. Fua, “Brief: Binary robust independent elementary features,” Computer Vision–ECCV 2010, pp. 778–792, 2010.),和ORB( E. Rublee, V. Rabaud, K. Konolige, and G. Bradski, “Orb: An efficient alternative to sift or surf,” in Computer Vision (ICCV), 2011 IEEE international conference on. IEEE, 2011, pp. 2564–2571.)。我们 使用ORB特征描述子因为它计算效率好。一旦特征点被提取出来后,我们使用 LK算法寻找接下来帧中相应的特征点。分别统计每个ROI区域中连接当前帧特征点和下一帧特征点的光流矢量数,通过对光流矢量的长度( 还是个数??)进行阈值化处理来判断每个ROI区域是否包含运动目标。
B.跟踪
上述简单的检测,存在缺陷是:当运动目标进入ROI区域并停止运动会导致检测失败。我们引入一个跟踪模块,能够跟踪之前检测到的目标,即使它停止运动。跟踪视频流中的移动物体是一个被广泛研究的问题,许多最先进的追踪器都可以使用 [12] M. Kristan, J. Matas, A. Leonardis, M. Felsberg, L. Cehovin, G. Fern´andez, T. Vojir, G. Hager, G. Nebehay, and R. Pflugfelder, “The visual object tracking vot2015 challenge results,” in Proceedings of the IEEE international conference on computer vision workshops, 2015, pp. 1–23.。由于本文的需求是只需检测在ROI中目标是否出现,要求不高,也不需要跟踪多目标,只是对ROI中有无目标出现做报警而已,不需要对提取的目标BBOX做跟踪,基于这些宽松的需求以及考虑计算负载,我们的方案是,一旦我们检测到移动目标的存在,我们就会存储这些特征点。当检测器从正向负过渡时,我们将在先前帧存储的特征点上运行另一个稀疏LK算法。如果在当前帧中检测到特征点,并且具有较高的可信度,并且特征点的运动矢量很小,我们得出结论,移动的对象仍然存在于ROI中,但是已经停止移动。这个ROI被认为包含移动的对象,直到检测器模块启动并新检测到一个移动的对象,此时,存储的特征点将被丢弃。
C. 分类
检测和跟踪模块是用来寻找ROI中的运动目标的。本文还需要明确运动目标的属性,特别是它的类别(如人,自行车,购物车等)。我们引入一个基于深度神经网络的分类模块。
1)MobileNet: (对于这块的知识点想要详细了解的话请参考:深刻解读MobileNet)
卷积神经网络在多任务识别,分割和检测方面的性能优于传统方法。然而本文同许多真实应用系统,需要执行在小的,低功耗的嵌入式系统,且无强大的GPU以供运行深的网络。2017年,Andrew等人提出的mobileNet( A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.),用depth-wise卷积和point-wise卷积替代标准的卷积操作,以达到更小,低延迟的模型,这正是我们需求的。
(此处我白话解释论文中表达含义)MobileNet的作用就是把一个标准的卷积操作分解成先对输入特征各个通道上(M个)独立做卷积核大小为Dk x Dk的卷积,输入特征图尺寸大小为DFxDF,如果这个卷积stride为2则类似扮演池化操作,输出特征图大小DF/2 * DF/2,通道数不变,仍是M的结构;如果这个卷积stride为1则输出特征大小不变仍DF *DF,通道数为M; 再通过一个1x1卷积(核数为N);以上就是分解的两个卷积操作,先depth-wise再point-wise;
对于标准的卷积 ,其计算量将是: ,而对于depthwise convolution其计算量为: ,pointwise convolution计算量是: ,所以depthwise separable convolution总计算量是:
可以比较depthwise separable convolution和标准卷积如下:
一般情况下 比较大,那么如果采用3x3卷积核的话,depthwise separable convolution相较标准卷积可以降低大约9倍的计算量。其实,后面会有对比,参数量也会减少很多。
2)分类器:
MobileNet作为我们提取图像特征的描述子。我们利用这些描述子来构建一个分类器。我们选择SoftMax和交叉熵一起使用来作为损失函数。其中,SoftMax的定义如下:

它常用在网络最后层,构建真实值到【0,1】概率分布值的映射,用于表达K种目标类别各自的概率分布。
我们用交叉熵来计算损失,并可为反向传播阶段提供梯度,定义如下:

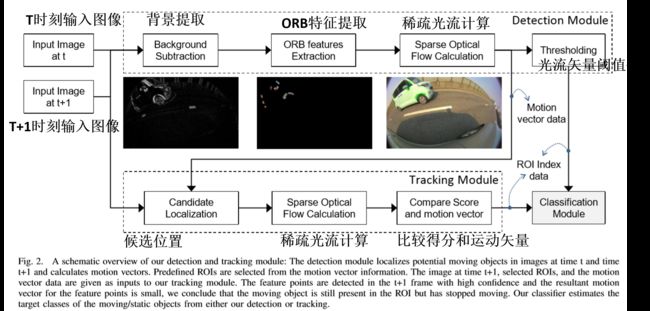
训练前,我们将从摄像头获得的图像帧做处理,将图像划分出几个固定ROI区域。由于MobileNet的网络输入图像大小是224x224,我们把不同分辨率图像都resize到224x224,如图3.
3.评估
这块内容主要是讲用本文的算法在不同硬件平台和不同区域获取图像下的试验评估。
A.硬件和实现
这块作者主要讲了在哪些硬件上做了实现,用了什么版本的额软件之类的,可具体看原论文吧(如下)。


系统的实现架构如下(见对应下图):
1)Capture/Merge:主要是实现4个鱼眼摄像头图像捕获和融合到一张4视角图(如图1)。
2)Detection/Tracking:该模块主要将上面得到的4视角图做运动目标检测。输出的是包含有运行目标的ROI索引号。
3)Detection Output Transfer:利用socket通信,第2步输出的结果将被转移到分类模块中。
4)object classification:该模块将四视野图和第2步中ROI索引作为输入,将这些运动目标分类成不同类别。

B.试验结果
作者主要对以上各个算法模块做了性能和准确度的测试,为了这么做,作者将各个模块间做了一些方式的组合来做评估。
试验1:只有检测;
试验2:检测+跟踪;
试验3:只有分类;
试验4:检测,跟踪,分类;
收集的视频序列分辨率为1280x720,30fps,4个鱼眼FOV 190° ,采用7段视频流作为训练数据源。共选了1009帧视频图像,12个预先固定的ROI,ROI中的图像被切成独立的图像,每个图像的label信息包含是否出现目标以及目标类别以便MobileNet训练目标类别。我们还另外标注了5个视频作为测试集,手动标注这12个ROI中是否有目标以及目标类别的groundtruth信息。训练数据集和测试数据集采集自室内室外场景。
试验结果表明,由于算法在做检测时是对稀疏特征而非像素点做处理,因此检测和跟踪模块所花时间在CPU和GPU上相近,本文作者因此选CPU做目标检测和跟踪用。选GPU做分类。
本文测试的性能可参考下面几个表。并且定义了召回率和准确率的评判公式。