全国大学生数据分析课堂记录手册(待更新)
全国大学生数据分析课堂笔记
什么是数据分析?
Excel数据分析
Excel可以进行简单的数据统计分析,如数据图表绘制等。
但Excel在数据分析方面存在一定的局限性:一是Excel因内存受限不易处理大规模数据,这在大数据时代成为一大行业痛点;二是Excel在数据分析方面工作效率较慢,特别是在某些不容易设置自动填充的时候,效率尤为低下;三是Excel绘制图表比较传统,在美观性和创新性方面不足。
Python数据分析
(1)Python不受数据规模的约束,能够处理大规模数据。
(2)Python的sklearn库提供了丰富的数据挖掘和人工智能方法,为使用者分析各种场景提供方法支持。
(3)Python的自动数据分析能够显著提升工作效率。
(4)Python能够绘制各种前沿的数据图表
(5)Python在海量数据采集方面也有独特的优势。
数据分析操作手册
Python知识定义
数据结构
数据结构就是用来存放数据的容器。数据应该按着某种规则放进容器,并且按照某种规则取出。
导入数据
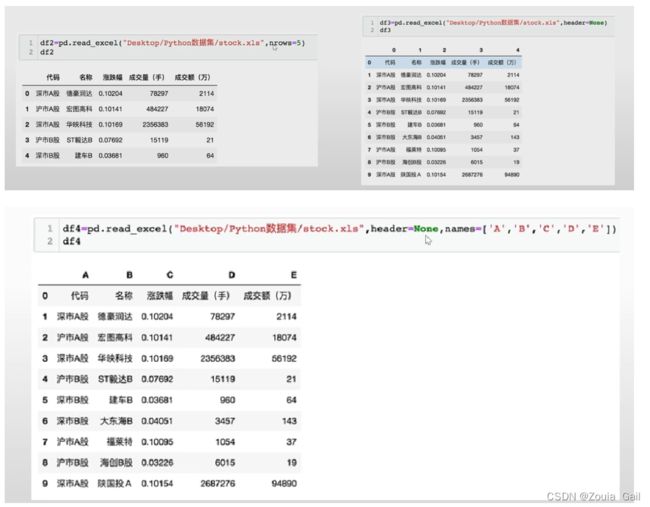
Excel格式数据
import pandas as pd
df = pd.read_excel(r"",index_col = 0)
df = pd.rea_table("")#txt
df = pd.read_excel(r"",header = None,name = ['A','B','C','D','E'],usecols = [1,3])
df
CSV格式数据
CSV定义
CSV是一种用分隔符分割的文件格式。由于Excel文件在存放巨量数据时会占用极大空间,且导入时也存在占用极大内存的缺点,因此,巨量数据常采用CSV格式
import pandas as pd
df = pd.read_csv(r"",sep=",",encoding = 'gbk',now = 3)
df.to_csv()
JSON格式
JSON定义
JSON是一种轻量级的数据交换格式,容易阅读。
import pandas as pd
json = pd.read_json()
json
爬取网络数据
import pandas as pd
#爬取的网络地址
url = ""
#A股公司营业收入排行榜位于所有表格中的第一个
df = pd.read_html(url)[0]
print(df)
数据处理
3.1熟悉数据
1、数据表的基本信息查看
关键技术:使用info()方法查看数据基本类型
在该例中,首先使用pandas库中的read_csv的方法导入数据,在使用info()处理数据
data.info()
2、查看数据表的大小
关键技术:使用pandas库中DataFrame对象的shape()方法
#返回第一个数为行数 第二个为列数
data.shape()
3、数据格式的查看
关键技术:type()方法
import pandas as pd
import numpy as np
#创建df和arr数据
df = pd.DataFrame(np.random.randint(6,10,size = (10,3)),columns = ['a','b','c'])
arr = np.random.randint(6,10,size = (10,3))
#打印df和arr数据和其数据类型
print(types(df))
print(type(arr))
4、查看具体的数据分布
在进行数据分析时,常常需要对数据的分布进行初步分析,包括统计数据中各元素的个数,均值,方差,最小值,最大值和分位数。
关键技术:describe()函数.在做数据分析时,常常需要了解数据元素的特征,describe()函数可以用于描述数据统计量特征。
data.describe()
3.2缺失值处理
1.缺失值的检查
关键技术:isnull()方法。isnull回True;否则,返回False
import pandas as pd
#导入items
df = pd.read.csv('',sep = '',encoding = '')
print(df.isnull())
#打印df各列缺失值的数量
print(df.isnull().sum())
3.2缺失值处理
2、缺失值删除
#当某行或某列值都为NaN时,才删除整行或整列。
关键技术:dropna()方法的how参数
df.dropna()
#全为NaN
df.dropna(how = 'all',axis = 0)#删除行
df.dropna(how = 'all',axis = 1)#删除列
df.dropna(how = 'any',axis = 0)
df.dropna(how = 'any',axis = 1)
3、缺失值替换/填充
如均值填补法、近邻填补法、插值填补法。
#均值
df.fillna(df.mean())
#近邻
df.fillna(method='bfill')#后
df.fillna(method='ffill')#前
#
df['item2'].interpolate(method = "polynomial",order = 2)
#样条插值
df['item2'].interpolate(method = "spline",order = 3)
3.3重复值处理
1、发现重复值
利用duplicated()方法检测冗余的行或列,默认是判断全部列中的值是否全部重复,并返回布尔类型的结果。对于完全没有重复的行,返回值为False。对于重复值的行,第一次出现重复的那一行出现重复的那一行返回False,其余的返回True
#检查重复值
df.puplicated()
#去除冗余数据
df.drop_duplicates()
3.4异常值的检测与处理
1检测异常值
关键技术:query方法和boxplot方法
import pandas as pd
import matplotlib.pyplot as plt
#导入文件
df = pd.read_csv()
#查询其中的异常值
df.query("销售<1000")
plt.boxplot(df['销售'])
2、处理异常值
(1)最常用的方式是删除
(2)将异常值当缺失值处理,以某个值填充
(3)将异常值当特殊情况进行分析,研究异常值出现的原因
关键技术:drop()
import pandas as pd
import matplotlib.pyplot as plt
#导入文件
df = pd.read_csv()
#查询其中的异常值
df.query("销售<1000")
#删除异常值所在的行
df1 = df.drop(index = 3,axis = 0)
df1
#绘制箱型图
plt.boxplot(df1['销售'])
3.5数据类型转换
1、数据类型检查
dtype()
astype()
3.6索引设置
(1)更方便地查询数据
(2)使用索引可以提升查询性能
1、添加索引
import pandas as pd
2、更改索引
df1 = df.set_index('日期')
df2 = pd.read_csv('',index_col= '日期')
3、重命名索引
df = df1.reindex([1,2,3,4,5])
import pandas as pd
data = [[110,105,99],[109,120,130]]
index = ['stu1','stu3','stu5']
columns = ['语文','英语','数学']
df = pd.DataFrame(data = data,index = index,columns = columns)
print(df)
#重置行索引和列索引
df.reindex(index = ['stu1','stu2','stu3','stu4','stu5'],columns = ['语文','物理','数学','英语'])
数据选择与运算
一、NumPy数据选择
数据可视化
1.图形绘制基础
from matplotlib import pyplot as plt
import numpy as np
import math
x = np.arange(0,math.pi*2,0.05)
y = np.sin(x)
plt.plot(x,y)
plt.xlabel('angle')
plt.ylabel('sine')
plt.title("sine curve")
plt.show()
2.组合图
import matplotlib.pyplot as plt
year = [2009]
3.时间序列
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
IndexData = pd.read_csv('D:/timeseries_data.csv')
data = IndexData['close']
temp = np.array(data)
for q in range(10):
try:
model = sm.tsa.ARMA(temp,order = (3,q))
results_ARMA = model.fit()
except:
pass
plt.figure(figsize = (10,4))
plt.plot(temp,'b',label='close')
plt.plot(results_AMRA.fittedvalues,'r',label = 'ARMA model')
plt.legend()
时间序列
时间序列分析,就是对按时间顺序排列的、随时间变化且找出数据变化发展的规律,从而评估和预测未来的走势。
(1)自回归模型(AR)
自回归模型仅通过时间序列变量的自身历史观测值来反映有关因素对预测目标的影响和作用。
时间序列代码模板
import warnings #取消版本警告
warnings.filterwarnings('ignore')
#读入数据
df = pd.read_excel('')
df1 = df[['','']] #选取目标列
#将目标时间设置为索引
df1 = df1.set_index('')
# 按年统计数据
df_y = df1.resample('AS').sum().to_period('A')
# 按季度统计数据
df_q = df1.resample('Q').sum().to_period('Q')
df_q
#绘制多个子图
fig = plt.figure(figsize = (8,3))
ax = fig.subplots(1,2)
df_y.plot(subplot = True, ax = ax[0],color = 'r')
ax[0].set_title('年增长趋势')
df_q.plot(subplots = True,ax = ax[1],color = 'g')
ax[1].set_title('季节性波动')
#调整子图布局
plt.subplots_adjust(top = 0.98,bottom = 0.2)
plt.show()
对比分析
1概念
对比分析:将两个及两个以上的数据进行比较,分析它们的差异,从而揭示这些数据所代表的事物发展变化情况和规律性。
注意事项:
对比的对象要有可比性;对比的指标类型必须一致;指标的口径范围、计算方法、计量单位必须一致。
2类型
横向比较
横比是同一时间条件下,对不同空间数据的比较
纵向比较
纵比是同一空间条件下,对不同时期数据的比较,包括同比、环比、定比等
同比即是历史同期数据对比
相关性分析
绘图颜色表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zx7wL7YI-1676968028377)(C:\Users\GuangZhuo\Desktop\录播课\5.png)]
时间格式转换
方法一:
tran['date'] = tran['date'].astype('datetime64[ns]')
方法二:
tran['date'] = pd.to_datetime(tran['date'])
date转为时间格式
方法三:
缺点:耗时太长
tran['date'] = tran['date'].apply(lambda x: datetime.strptime(x,'%Y-%m-%d'))
中文显示问题
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
为了坐标轴负号正常显示。matplotlib默认不支持中文,设置中文字体后,负号会显示异常。需要手动将坐标轴负号设为False才能正常显示负号。
matplotlib.rcParams['axes.unicode_minus'] = False
解决输出时数列名不对齐的问题
pd.set_option('display.unicode.east_asian_width',True)
清华源设置
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
警告
import warnings
warnings.filterwarnings('ignore')
例题
对于上面股票数据集文件 stockdata.csv,请利用 Python 对数据进行以“月”为单位的采样,请写出相关代码。示例代码:
import pandas as pddf= pd.read_csv('D:/stockdata.csv',index_col=[0],parse_dates =True)monthly=df.resample('M').sum()
monthly
安装库
anaconda search pygrib
3.2 查看第一个conda-forge的包:
anaconda show conda-forge/pygrib
3.3 安装pygrib:
conda install --channel
https://conda.anaconda.org/conda-forge pygrib
决策树
import os
os.environ[“PATH”] += os.pathsep + ‘D:\Graphviz\bin’