容易理解的计算机组成原理中主存与Cache的3种映射方式(直接映射,全相联映射,组相联映射)
容易理解的计算机组成原理中主存与Cache的3种映射方式(直接映射,全相联映射,组相联映射)
一.为了让大家更加方便的理解,我首先设置了两个问题,同时也写了相应的个人所理解的答案
-
为什么引入Cache?
答: Cache是一种高速缓冲存储器,他位于cpu和主存之间,是为了提高cpu对主存的访问速度。 -
为什么主存与Cache之间要进行映射?
答:前面我们知道,Cache是为了提高cpu对主存的访问速度。故cache可看做是一种介质,而这种介质是主存的替代品,而cpu只认主存的单元地址,所以我们需要把主存的地址映射到cache,这样cpu直接访问cache即相当于间接的访问主存,从而提高了cpu对主存的访问速度。
二.正式进入三种映射方式
1.直接映射
直接映射:说白了就是一对一的映射方式。前者 ‘一’ 指的是主存中的任意一块,主存中的不同分区下的块号,后者 ‘一’ 指的是cache中特定的某一个块。
直接来看下面主存与cache之间的直接映射,如下图:
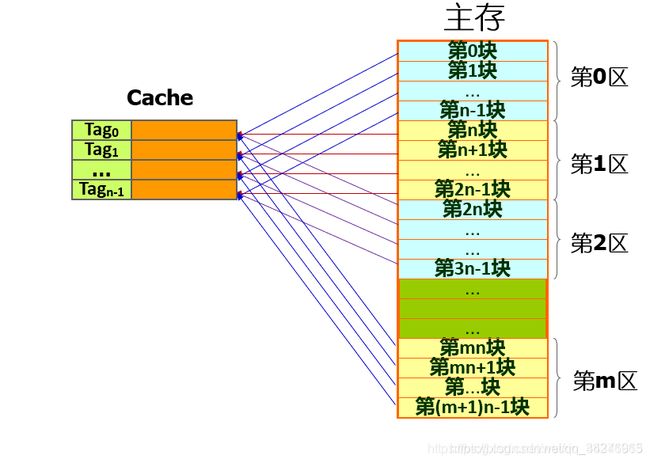
从上面图形分析着手:左边的cache被分成了n行,其次右边主存部分被分成了m个区,其中每个区被分成了n块,n块和n行不是巧合,这恰好说明了cache是主存的替代品,其次我们还发现每个区中的每一块都是有规律的映射到cache中的一个特定行中。
所以在主存,区中的某一块映射到cache中的某一个特定行有如下规律

其中上面的i指的是cache中的特定行,j指的是主存区中的块号,n指的是cache中的总行数或每个主存区中的总块数。
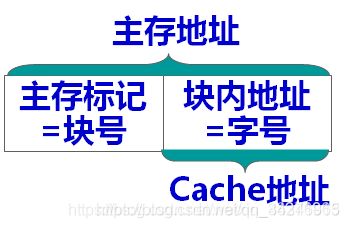
相对应的地址格式
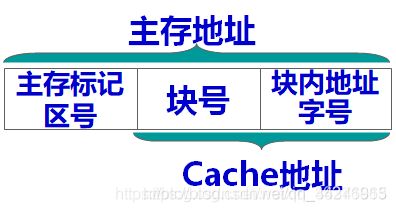
下面以一道题为例:
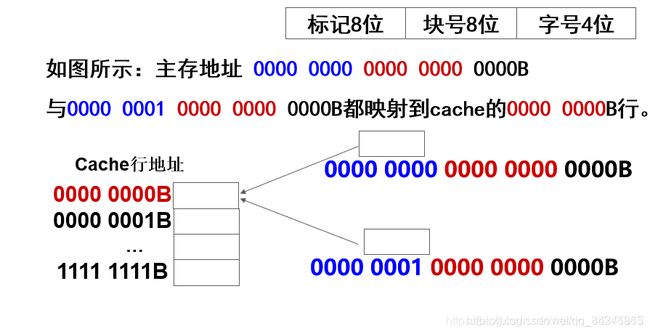
有一处理机,主存容量1MB,字长1B,块大小16B;Cache容量4KB,若cache采用直接映射,请给出2个不同标记的内存地址,它们映射到同一个cache行。
我的解法思路:首先要写出内存地址,我们就首先要求出主存的地址格式:区号、块号、字号。
区号:主存容量1MB,Cache容量4KB,故:1MB/4KB=2^8,即区号或标记位8位。
块号:Cache容量4KB,块大小16B,故:4KB/16B=2^8,即块号8位。
字号:字长1B,块大小16B,故:2^4,即字号4位。
所以:题目中的映射到同一个cache行,即只要块号相同即可满足。
直接映射总结:
优点:地址映射方式简单,数据访问时只需要检查块号是否相等即可,因而能得到比较快的访问速度,硬件设备简单;
缺点;替换操作频繁,命中率比较低。
2.全相联映射
全相联映射即主存块可以映射到cache中的任意一块,即说白了就是一对多,‘一’指的是主存中的任意一块,‘多’指的是cache的每一行,即主存块可以映射到cache中的任意一块。
直接来看下面主存与cache之间的全相联映射,如下图:
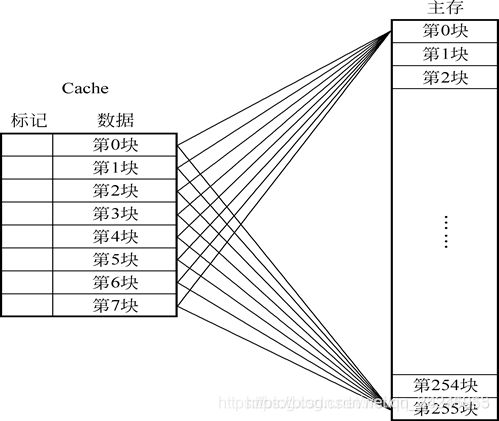
从上面的图片我们也可以很直观的看出一对多的含义,所以全相联映射也相对比较简单。
相对应的地址格式
例题演示
若数据在主存和Cache之间按块传送单位为512字节。Cache大小为8KB,主存容量为1MB ,求其主存的地址格式。
我的解法思路:
字号:按块传送单位为512字节,即512=2^9,故字号为9位
块号或主存标记:主存容量为1MB,即 1M/512=2^11,故标记号11位。
全相联映射总结:
优点:命中率比较高,cache存储空间利用率高;
缺点:访问相关存储器时,每次都要与全部内容比较,速度低,成本高,因而利用少。
3.组相联映射
组相联映射:说白了就是基于直接映射和全相联映射的一个比较折中的方式,即组内是全相联映射,组间是直接映射。就是一对N,‘一’指的是主存中的任意一块,‘N’ 指的是cache的每组内的块数,即主存块可以映射到cache中的任意一组的若干块。
直接来看下面的组相联映射的图进行下一步分析解释
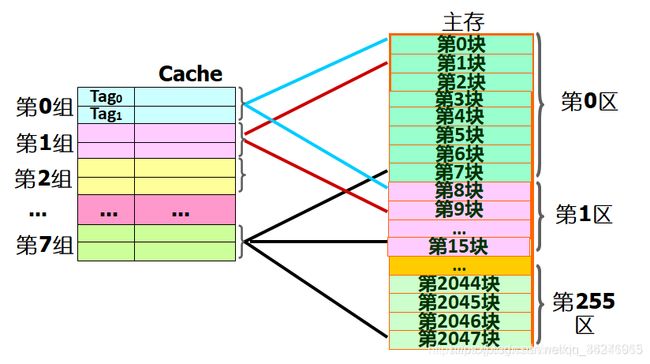
根据上面的图:我们知道cache被分为了8组,每组又分为了2块,右边主存部分被分成了256个区,每个区8块,每个区的8块与cache中的8组不是巧合,而是为了实现组间直接映射,然疑问来了,当主存的某一块按直接映射方式规则进行映射后到了cache中相应的组,而此时在cache中每组有两块,这时候就是实行组内全映射。
前面我说过组相联映射是直接映射和全相联映射的一个折中形式,那么必然也就存在下面俩种特殊的形式:
1>当cache中每组内的块数变为1时,这就变成了直接映射;
2>当cache中只有一组时,这就变成了全相联映射。
组相联映射相对应的主存地址格式(和直接映射方式很像,只是块号变成了组号):
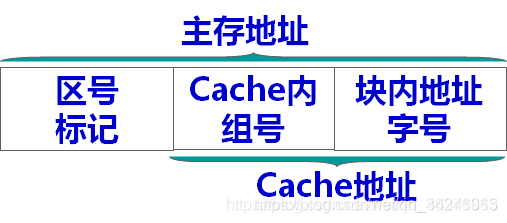
下面以一道例题为例:
某计算机按字节寻址,主存有2K个块,每块32个字节。 Cache由64个块组成,每组8块(8路组相联)。请表示主存地址格式。给内存地址为A21FH和C028H两个地址对应的标记、组号和字号。
我的解法思路是:
字号:每块32个字节,即 32=2^5,故字号5位。
组号:Cache由64个块组成,每组8块,即64/8=8=2^3,故组号3位。
区号标记:主存有2K个块,又因为我们知道组间是直接映射(所以把cache中的组数看作直接映射中的块),即2k/8=2^8,故区号8位。
所以,主存格式为:区号8位、组号3位、字号5位。
又A21FH=1010001000011111B
故对应的标记:10100010,组号:000,字号:11111
同理C028H=1100000000101000B
故对应的标记:11000000、组号:001、字号:01000
组相联映射总结:
优点:块的冲突概率比较低,块的利用率大幅度提高;
缺点:实现难度和造价要比直接映射高。
————————————————
版权声明:本文为CSDN博主「-希冀-」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_46371813/article/details/107631076
