Greenplum开发基础
Greenplum开发基础
1. Greenplum介绍
Greenplum数据库是一种基于PostgreSQL开源技术的大规模并行处理(MPP)数据库服务器,其架构特别针对管理大规模分析型数据仓库以及商业智能工作负载而设计。
Greenplum数据库本质上是多个PostgreSQL面向磁盘的数据库实例一起工作形成的一个紧密结合的数据库管理系统(DBMS)。它基于PostgreSQL开发,其SQL支持、特性、配置选项和最终用户功能在大部分情况下和PostgreSQL非常相似。与Greenplum数据库交互的数据库用户会感觉在使用一个常规的PostgreSQL DBMS。
MPP(也被称为shared nothing架构)指有两个或者更多个处理器协同执行一个操作的系统,每一个处理器都有其自己的内存、操作系统和磁盘。Greenplum使用这种高性能系统架构来分布数T字节数据仓库的负载并且能够使用系统的所有资源并行处理一个查询。
● Shared Everthing:一般是针对单个主机,完全透明共享CPU/Memory/IO,并行处理能力差,典型的代表SQLServer。
● Shared Disk:各个处理单元使用自己的私有CPU和Memory,共享磁盘系统。典型的代表Oracle Rac,它是数据共享,可通过增加节点来提高并行处理的能力,扩展能力较好。其类似于SMP(对称多处理)模式,但是当存储器接口达到饱和的时候,增加节点并不能获得更高的性能。
● Shared Nothing:各个处理单元都有自己私有的CPU/内存/硬盘等,不存在共享资源,各处理单元之间通过协议通信,并行处理和扩展能力更好。各节点相互独立,各自处理自己的数据,处理后的结果可能向上层汇总或在节点间流转。Share-Nothing架构在扩展性和成本上都具有明显优势。
2. Greenplum架构
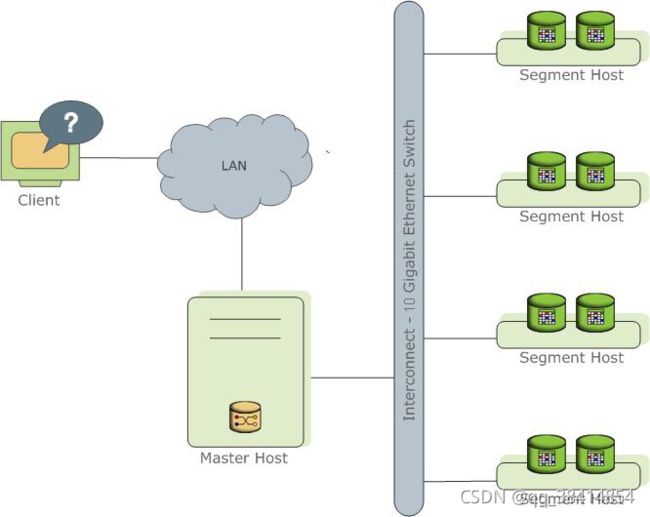
Greenplum数据库通过将数据和处理负载分布在多个服务器或者主机上来存储和处理大量的数据。Greenplum数据库是一个由基于PostgreSQL的数据库组成的阵列,阵列中的数据库工作在一起呈现了一个单一数据库的景象。Master是Greenplum数据库系统的入口。客户端会连接到这个数据库实例并且提交SQL语句。Master会协调与系统中其他称为Segment的数据库实例一起工作,Segment负责存储和处理数据。
2.1. 关于Greenplum的Master
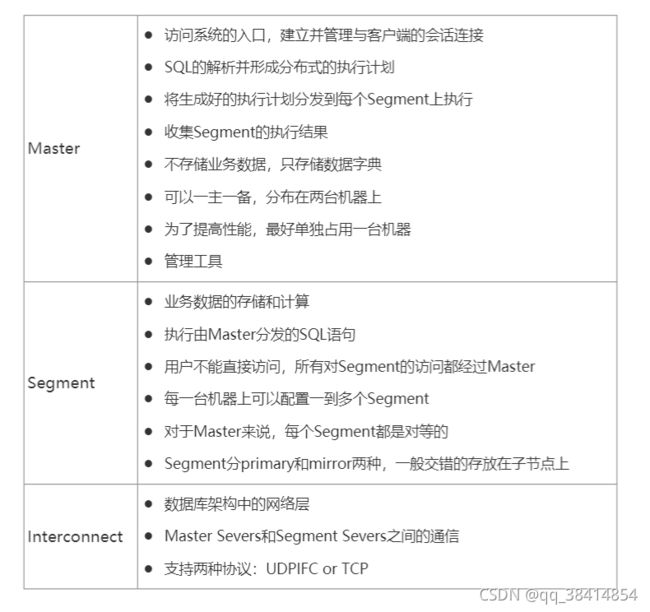
Greenplum数据库的Master是整个Greenplum数据库系统的入口,它接受连接和SQL查询并且把工作分布到Segment实例上。 Greenplum数据库的最终用户与Greenplum数据库(通过Master)交互时,会觉得他们是在与一个典型的PostgreSQL数据库交互。他们使用诸如psql之类的客户端或者JDBC、ODBC、libpq(PostgreSQL的C语言API)等应用编程接口(API)连接到数据库。 Master是全局系统目录的所在地。全局系统目录是一组包含了有关Greenplum数据库系统本身的元数据的系统表。Master上不包含任何用户数据,数据只存在于Segment之上。Master会认证客户端连接、处理到来的SQL命令、在Segment之间分布工作负载、协调每一个Segment返回的结果以及把最终结果呈现给客户端程序。 Greenplum数据库使用预写式日志(WAL)来实现主/备镜像。在基于WAL的日志中,所有的修改都会在应用之前被写入日志,以确保对于任何正在处理的操作的数据完整性。Note: Segment镜像还不能使用WAL日志。
2.2. 关于Greenplum的Segment
Greenplum数据库的Segment实例是独立的PostgreSQL数据库,每一个都存储了数据的一部分并且执行查询处理的主要部分。 当一个用户通过Greenplum的Master连接到数据库并且发出一个查询时,在每一个Segment数据库上都会创建一些进程来处理该查询的工作。 用户定义的表及其索引会分布在Greenplum数据库系统中可用的Segment上,每一个Segment都包含数据的不同部分。服务于Segment数据的数据库服务器进程运行在相应的Segment实例之下。用户通过Master与一个Greenplum数据库系统中的Segment交互。 Segment运行在被称作Segment主机的服务器上。一台Segment主机通常运行2至8个Greenplum的Segment,这取决于CPU核数、RAM、存储、网络接口和工作负载。Segment主机预期都以相同的方式配置。从Greenplum数据库获得最佳性能的关键在于在大量能力相同的Segment之间平均地分布数据和工作负载,这样所有的Segment可以同时开始为一个任务工作并且同时完成它们的工作。
2.3. 关于Greenplum的Interconnect
Interconect是Greenplum数据库架构中的网络层。 Interconnect指的是Segment之间的进程间通信以及这种通信所依赖的网络基础设施。Greenplum的Interconnect采用了一种标准的以太交换网络。出于性能原因,推荐使用万兆网或者更快的系统。 默认情况下,Interconnect使用带流控制的用户数据包协议(UDPIFC)在网络上发送消息。Greenplum软件在UDP之上执行包验证。这意味着其可靠性等效于传输控制协议(TCP)且性能和可扩展性要超过TCP。如果Interconnect被改为TCP,Greenplum数据库会有1000个Segment实例的可扩展性限制。对于Interconnect的默认协议UDPIFC则不存在这种限制。
2.4. 架构总结
3. 表
Greenplum数据库的表与任何一种关系型数据库中的表类似,不过其表中的行被分布在系统中的不同Segment上。当用户创建一个表时,用户会指定该表的分布策略。
3.1. 常用数据类型

注:对于变长数据类型,如果大于或等于 127 字节,需要(除数据本身外)额外 4 字节的存储空间(小于 127 字节时额外只需要 1 字节存储空间)。
3.2. 表和列约束
- 检查约束
检查约束允许用户指定一个特定列中的值必须满足一个布尔(真值)表达式。
create table products (
product_no integer,
name text,
price numeric check ( price > 0 )
);
- 非空约束
非空约束指定一个列不能有空值。非空约束总是被写作为列约束。
create table products (
product_no integer not null,
name text not null,
price numeric
);
- 唯一约束
唯一约束确保一列或者一组列中包含的数据对于表中所有的行都是唯一的。该表必须是哈希分布或复制表(不可以是DISTRIBUTED RANDOMLY)。如果表是哈希分布的,约束列必须是该表的分布键列(或者是一个超集)。
create table products (
product_no integer unique,
name text,
price numeric
) DISTRIBUTED by (product_no);
- 主键
主键约束是一个UNIQUE约束和一个NOT NULL约束的组合。该表必须是哈希分布(非DISTRIBUTED RANDOMLY)的,并且约束列必须是该表的分布键列(或者是一个超集)。如果一个表具有主键,这个列(或者这一组列)会被默认选中为该表的分布键。
create table products (
product_no integer primary key,
name text,
price numeric
) DISTRIBUTED by (product_no);
GreenPlum数据库不支持同时存在两个唯一的字段(复合主键除外)。
create table t_hash_3 (
name varchar(10) unique,
id int primary key
);
ERROR: Greenplum Database does not allow having both PRIMARY KEY and UNIQUE constraints
- 外键
不支持外键。用户可以声明它们,但是参照完整性不会被实施。
外键约束指定一列或者一组列中的值必须匹配出现在另一个表的某行中的值,以此来维护两个相关表之间的参照完整性。参照完整性检查不能在一个Greenplum数据库的分布表段之间实施。
3.3. 表分布策略
数据分布是任何MPP数据库的基础,也是MPP数据库是否高效的关键之一。通过把海量数据分散到多个节点上,一方面大大降低了单个节点处理的数据量,另一方面也为处理并行化奠定了基础,两者结合起来可以极大的提高整个系统的性能。譬如在一百个节点的集群上,每个节点仅保存总数据量的百分之一,一百个节点同时并行处理,性能会是单个配置更强节点的几十倍。如果数据分布不均匀出现数据倾斜,受短板效应制约,整个系统的性能将会和最慢的节点相同。因而数据分布是否合理对Greenplum整体性能影响很大。
在决定表分布策略时,请考虑以下几点:
● 均匀数据分布:为了最好的性能,所有的Segment应该包含等量的数据。如果数据不平衡或者倾斜,具有更多数据的Segment就必须做更多工作来执行它那一部分的查询处理。请选择对于每一个记录都唯一的分布键,例如主键。
● 本地和分布式操作:本地操作比分布式操作更快。在Segment层面上,如果与连接、排序或者聚集操作相关的工作在本地完成,查询处理是最快的。在系统层面完成的工作要求在Segment之间分布元组,其效率会低些。当表共享一个共同的分布键时,在它们共享的分布键列上的连接或者排序工作会在本地完成。对于随机分布策略来说,本地连接操作就行不通了。
● 均匀查询处理:为了最好的性能,所有的Segment应该处理等量的查询负载。如果一个表的数据分布策略与查询谓词匹配不好,查询负载可能会倾斜。例如,假定一个销售事务表按照客户ID列(分布键)分布。如果查询中的谓词引用了一个单一的客户ID,该查询处理工作会被集中在一个Segment上。
Greenplum 6 提供了以下数据分布策略:
● 哈希分布
● 随机分布
● 复制表(Replicated Table)
- Hash分布
create table products (
name varchar(40),
prod_id integer,
supplier_id integer
) DISTRIBUTED by (prod_id);
要使用这一策略,需要在创建表使用“DISTRIBUTED BY ( column , […] )”子句。选择一个列后者多个列作为数据表的分布键。
散列算法使分布键将每一行分配给特定segment。相同值的键将始终散列到同一个segment。选择唯一的分布键(例如Primary Key)将确保较均匀的数据分布。哈希分布是表的默认分布策略。
如果创建表时未提供DISTRIBUTED子句,则将PRIMARY KEY(如果表真的有的话)或表的第一个合格列用作分布键。什么类型的列是合格列呢?几何类型或用户自定义数据类型的列不能用作Greenplum分布键列。如果表中没有合格的列,则退化为随机分布策略。
如果未提供DISTRIBUTED子句,Greenplum最后会选择哪种分布策略还会受其它因素的影响,例如:GUC gp_create_table_random_default_distribution和当时使用的优化器(optimizer)也将影响最终决定。因此,请千万不要忘记在CREATE TABLE时添加DISTRIBUTED BY子句。
概括如下:
● 未提供DISTRIBUTED子句时,如果表中包含主键,则默认会选择主键为分布键;
create table products (
name varchar(40),
prod_id integer,
supplier_id integer
) DISTRIBUTED by (prod_id);
● 未提供DISTRIBUTED子句时,如果表中没有主键但有唯一约束,那么默认选择唯一字段作为分布键;
create table t_hash_2 (
id int unique,
name varchar(10)
);
NOTICE: CREATE TABLE / UNIQUE will create implicit index "t_hash_2_id_key" for table "t_hash_2"
● 未提供DISTRIBUTED子句时,如果表中既没有主键也没有唯一约束,默认使用第一个合格字段作为分布键,并且使用hash分布策略;
create table t_hash (
name varchar(10),
id int
);
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'name' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
● 如果建表时指定的分布键不是主键,那么Greenplum会把表的分布键改为主键字段,而不是指定的字段,但是SQL语句中指定的分布键必须包含主键字段,否则SQL会报错;
create table t_hash_3 (
name varchar(10),
id int primary key
) DISTRIBUTED by(name);
ERROR: PRIMARY KEY and DISTRIBUTED BY definitions incompatible
HINT: When there is both a PRIMARY KEY, and a DISTRIBUTED BY clause, the DISTRIBUTED BY clause must be equal to or a left-subset of the PRIMARY KEY
● 而且主键字段必须在SQL指定的分布键的第一列出现才可以,否则也会遇到错误导致SQL无法成功运行;
create table t_hash_3 (
name varchar(10),
id int primary key
) DISTRIBUTED by(
name,
id
);
ERROR: PRIMARY KEY and DISTRIBUTED BY definitions incompatible
HINT: When there is both a PRIMARY KEY, and a DISTRIBUTED BY clause, the DISTRIBUTED BY clause must be equal to or a left-subset of the PRIMARY KEY
● 上述SQL将ID(主键列)放到前面,SQL即可成功运行;
create table t_hash_3 (
name varchar(10),
id int primary key
) DISTRIBUTED by(
id,
name
);
NOTICE: updating distribution policy to match new primary key
NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "t_hash_3_pkey" for table "t_hash_3"
- 随机分布
create table random_stuff (
things text,
doodads text,
etc text
) DISTRIBUTED RANDOMLY;
要使用这一策略,需要在创建表使用“DISTRIBUTED RANDOMLY”子句。
随机分布会将数据行按到来顺序依次循环发送到各个segment上。与哈希分布策略不同,具有相同值的数据行不一定位于同一个segment上。虽然随机分布确保了数据的平均分布,但只要有可能,应该尽量选择哈希分布策略,哈希分布的性能更加优良。
如果不能确定一张表的哈希分布键或者不存在合理的避免数据倾斜的分布键,则可以使用随机分布。随机分布会采用循环的方式将一次插入的数据存储到不同的节点上。随机性只在单个SQL中有效,不考虑跨SQL的情况。譬如如果每次插入一行数据到随机分布表中,最终的数据会全部保存在第一个节点上。
随机分布不支持主键和唯一键,因为随机分布保证不了整体数据的唯一性。
create table t_randomly_1 (
id int unique,
name varchar(10)
) DISTRIBUTED RANDOMLY;
ERROR: UNIQUE and DISTRIBUTED RANDOMLY are incompatible
alter table t_randomly add constraint pk_id primary key (id);
ERROR: PRIMARY KEY and DISTRIBUTED RANDOMLY are incompatible
- 复制表(Replicated Table)
create table products (
product_no integer,
name text,
price numeric
) DISTRIBUTED REPLICATED;
` Greenplum 6支持一种新的分布策略:复制表,即整张表在每个节点上都有一个完整的拷贝。要使用这一策略,需要在创建表使用“DISTRIBUTED REPLICATED”子句。
这种分布策略下,表数据将均匀分布,因为每个segment都存储着同样的数据行。当您需要在segment上执行用户自定义的函数且这些函数需要访问表中的所有行时,就需要用到复制分布策略。或者当有大表与小表join,把足够小的表指定为replicated也可能提升性能。
4. 自定义分布键哈希函数
create table atab (
a int
) DISTRIBUTED by (
a abs_int_hash_ops
--abs_int_hash_ops自定义哈希操作符类
);
` 可以在DISTRIBUTED BY子句中声明非默认的哈希运算符类。使用自定义哈希运算符类可以用于支持与默认相等运算符(=)不同的运算符上的共存连接。
3.4. 修改表的分布
ALTER TABLE提供了选项来改变一个表的分布策略。当表分布选项改变时,表数据会被在磁盘上重新分布,这可能会造成资源紧张。用户也可以使用现有的分布策略重新分布表数据。
- 更改分布策略
对于已分区的表,对于分布策略的更改会递归地应用到子分区上。这种操作会保留拥有关系和该表的所有其他属性。例如,下列命令使用customer_id列作为分布键在所有Segment之间重新分布表sales:
ALTER TABLE sales SET DISTRIBUTED BY (customer_id);
在用户改变一个表的哈希分布时,表数据会被自动重新分布。把分布策略改成随机分布不会导致数据被重新分布。例如,下面的ALTER TABLE命令不会立刻产生效果:
ALTER TABLE sales SET DISTRIBUTED RANDOMLY;
将表的分布策略更改为DISTRIBUTED REPLICATED或从DISTRIBUTED REPLICATED修改为其他分布,会自动重新分配表数据。
2. 重新分布表的数据
要用一种随机分布策略(或者当哈希分布策略没有被更改时)对表重新分布数据,可使用REORGANIZE=TRUE。重新组织数据对于更正一个数据倾斜问题是必要的,当系统中增加了Segment资源后也需要重新组织数据。例如,下面的命令会使用当前的分布策略(包括随机分布)在所有Segment上重新分布数据。
ALTER TABLE sales SET WITH (REORGANIZE=TRUE);
将表的分布策略更改为DISTRIBUTED REPLICATED或从DISTRIBUTED REPLICATED改为其它总是重新分配表数据,即使REORGANIZE=FALSE也是如此。
3.5. 表存储模型
- 堆表(Heap)
create table foo (
a int,
b text
) DISTRIBUTED by (a);
面向行的堆表是默认的存储类型。默认情况下,Greenplum数据库使用和PostgreSQL相同的堆存储模型。堆表存储在OLTP类型负载下表现最好,这种环境中数据会在初始载入后被频繁地修改。UPDATE和DELETE操作要求存储行级版本信息来确保可靠的数据库事务处理。堆表最适合于较小的表,例如维度表,它们在初始载入数据后会经常被更新。
2. 追加优化表(AO)
create table bar (
a int,
b text
) with (
appendoptimized = true
) DISTRIBUTED by (a);
AO以前是append only,只能追加,不能删除和更新,4.3版本之后支持修改和删除了,内部也改叫append optimized表。
AO表通过一个BITMAP文件来标记被删除的行,事务结束时,需要调用FSYNC记录最后一次写入对应的数据块的偏移。因为每次事务结束都会FSYNC,因此AO表不适合小事务,例如:单行的INSERT语句。
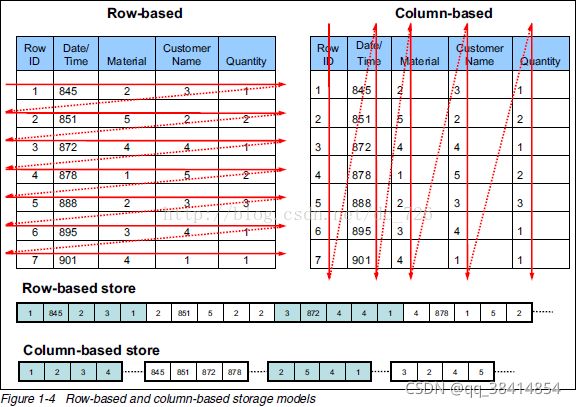
3. 列存储表
create table bar (
a int,
b text
) with (
appendoptimized = true,
orientation = column
) DISTRIBUTED by (a);
面向列的存储的表必须是追加优化表。AO列存主要面向OLAP场景,适合于在少量列上计算数据聚集的数据仓库负载,或者是用于需要对单列定期更新但不修改其他列数据的情况。
- 压缩表
--表级压缩
create table foo (
a int,
b text
) with (
appendoptimized = true,
compresstype = zlib,
compresslevel = 5
);
--列级压缩
create table T1 (
c1 int ENCODING (
compresstype = zstd
),
c2 char ENCODING (
compresstype = quicklz,
blocksize = 65536
),
c3 char
) with (
appendoptimized = true,
orientation = column
);
使用压缩技术的表必须是追加优化表。列数据具有相同的数据类型,因此在列存数据上支持存储尺寸优化,但在行存数据上则不支持。例如,很多压缩方案使用临近数据的相似性来进行压缩。不过,临近压缩做得越好,随机访问就会越困难,因为必须解压数据才能读取它们。
在Greenplum数据库中有两种类型的库内压缩可用:
● 应用于一整个表的表级压缩。
● 应用到一个指定列的列级压缩。用户可以为不同的列应用不同的列级压缩算法。
下面的表总结了可用的压缩算法。
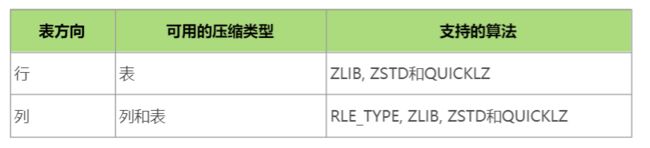
Note: QuickLZ压缩在Greenplum数据库的开源版本中不可用。
在为追加优化表选择一种压缩类型和级别时,要考虑这些因素:
● CPU使用:用户的Segment系统必须具有可用的CPU能力来压缩和解压数据。
● 压缩率/磁盘尺寸:最小化磁盘尺寸是一个因素,但也要考虑压缩和扫描数据所需的时间和CPU计算能力。要找到能高效压缩数据但不导致过长压缩时间或者过慢扫描率的最优设置。
● 压缩的速度:与zlib比较,QuickLZ在较低的压缩率下通常使用较少的CPU计算能力、能更快地压缩数据。zlib提供更高的压缩率,但是速度较慢。例如,在压缩级别1上(compresslevel=1),QuickLZ和zlib具有差不多的压缩率,但是压缩速度不同。使用compresslevel=6的zlib能比QuickLZ更显著地提升压缩率,但是压缩速度更慢。ZStandard压缩可以提供良好的压缩比或速度,具体取决于压缩级别,或两者的良好折衷。
● 解压速度/扫描率:压缩的追加优化表的性能取决于硬件、查询调优设置和其他因素。请执行对比测试来判断在用户的环境中的真实性能。
Note: 不要在使用压缩的文件系统上创建压缩的追加优化表。如果用户的Segment数据目录所在的文件系统是一个压缩的文件系统,用户的追加优化表不能使用压缩。
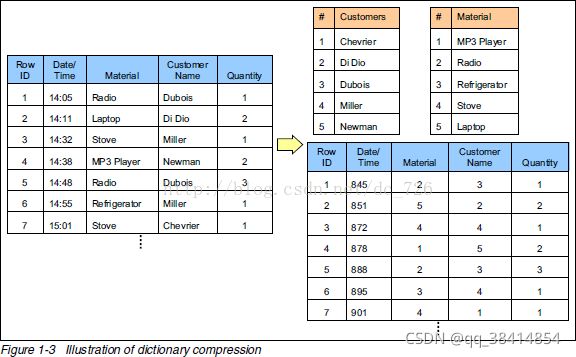
- 检查追加优化表的压缩和分布
Greenplum提供了内建函数来检查一个追加优化表的压缩率和分布情况。这些函数要求对象ID或者表名作为参数。用户可以用schema名来限定表名。
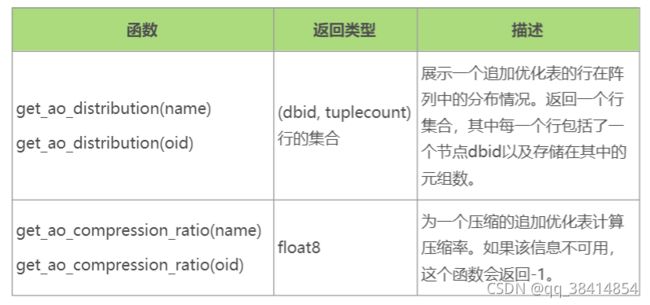
● 压缩比作为公共比率返回。例如,返回值3.19或者3.19:1表示解压后的表比压缩表的尺寸的3倍略大。
● 表的分布被返回为一个行集合,它们反映了每个Segment上存储了多少元组。
select get_ao_distribution('lineitem_comp');
3.6. 修改表的存储模型
表存储、压缩和行列类型只能在创建时声明。要改变存储模型,用户必须用正确的存储选项创建一个表,再把原始表的数据载入到新表中,接着删除原始表并且把新表重命名为原始表的名称。用户还必须重新授权原始表上有的权限。例如:
CREATE TABLE sales2 (
LIKE sales
) WITH (
appendoptimized = TRUE,
compresstype = quicklz,
compresslevel = 1,
orientation = COLUMN
);
INSERT INTO sales2 SELECT * FROM sales;
DROP TABLE sales;
ALTER TABLE sales2 RENAME TO sales;
GRANT ALL PRIVILEGES ON sales TO admin;
GRANT SELECT ON sales TO guest;
使用ALTER TABLE命令为一个表增加一个压缩列。所有在增加列级压缩中描述的用于压缩列的选项和约束都适用于用ALTER TABLE命令增加的列。
下面的例子展示了如何向一个表中增加一个使用zlib压缩的列T1。
ALTER TABLE T1 ADD COLUMN c4 int DEFAULT 0
ENCODING (
compresstype = zlib
);
3.7. 表分区概述
分区并不会改变表数据在Segment之间的物理分布。表分区是逻辑的:Greenplum数据库在逻辑上把表划分为分区来启用大规模并行处理。表分区可以提升查询性能,并且有利于数据仓库维护任务。
- 分区类型
● 范围分区:基于一个数字型范围划分数据,例如按照日期或价格划分。
● 列表分区:基于一个值列表划分数据,例如按照销售范围或产品线划分。
● 两种类型的组合。 - 分区表的结构
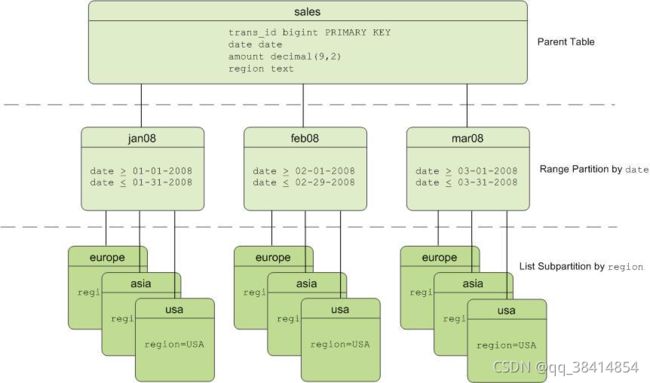
分区操作会创建一个顶层(父)表以及一层或者多层子表。在内部,Greenplum数据库会在顶层表和它的底层分区之间创建继承关系。
Greenplum使用表创建时定义的分区标准来创建每一个分区及其上一个可区分的CHECK约束,这个约束限制了该表能含有的数据。查询优化器使用CHECK约束来决定要扫描哪些表分区来满足一个给定的查询谓词。
Greenplum系统目录存储了分区层次信息,这样插入到顶层父表的行会被正确地传播到子表分区。要更改分区设计或者表结构,可使用带有PARTITION子句的ALTER TABLE修改父表。
要把数据插入到一个分过区的表中,用户需要指定根分区表,也就是用CREATE TABLE命令创建的那个表。用户也可以在INSERT命令中指定分区表的一个叶子子表。如果该数据对于指定的叶子子表不合法,则会返回一个错误。不支持在DML命令中指定一个非叶子或者非根分区表。 - 加载分区表
在用户创建了分区表结构之后,顶层父表为空。数据会被路由到底层的子表分区中。在一个多级分区设计中,只有层次底部的子分区能够包含数据。
不能被映射到一个子表分区的行会被拒绝并且载入会失败。为了避免无法映射的行在载入时被拒绝,可以为用户的分区层次定义一个DEFAULT分区。任何不匹配一个分区的CHECK约束的行会被载入到DEFAULT分区。
在运行时,查询优化器扫描整个表继承层次并使用CHECK表约束来决定要扫描哪个子表分区来满足查询的条件。 DEFAULT分区(如果用户的层次中有一个)总是会被扫描。包含数据的DEFAULT分区会拖慢总体扫描时间。
当用户使用COPY或者INSERT来载入数据到父表时,数据会被自动路由到正确的分区,这就像是向一个常规表中载入数据一样。
向分区表中载入数据的最佳方法是创建一个中间状态表,把数据载入其中,然后把它交换到用户的分区设计中。 - 决定表的分区策略
不是所有的哈希分布表或随机分布表都适合于分区,是否需要使用表分区需要考虑以下因素:
● 表是否足够大?大型的事实表是进行表划分很好的候选。如果在一个表中有几百万或者几十亿个记录,从逻辑上将数据分成较小的块会让用户在性能方面受益。对于只有几千行或者更少数据的小表来说,维护分区的管理开销将会超过用户可能得到的性能收益。
● 用户是否体验到不满意的性能?正如任何性能调节的动机一样,只有针对一个表的查询产生比预期还要慢的响应时间时才应该对该表分区。
● 用户的查询谓词有没有可识别的访问模式?检查用户的查询负载的WHERE子句并且查找一直被用来访问数据的表列。例如,如果大部分查询都倾向于用日期查找记录,那么按月或者按周的日期分区设计可能会对用户有益。或者如果用户倾向于根据地区访问记录,可考虑一种列表分区设计来根据地区划分表。
● 用户的数据仓库是否维护了一个历史数据的窗口?另一个分区设计的考虑是用户的组织对维护历史数据的业务需求。例如,用户的数据仓库可能要求用户保留过去十二个月的数据。如果数据按月分区,用户可以轻易地从仓库中删除最旧的月份分区并且把当前数据载入到最近的月份分区中。
● 数据能否基于某种定义的原则被划分成差不多相等的部分?尽可能选择将把用户的数据均匀划分的分区原则。如果分区包含基本同等数量的记录,查询性能会基于创建的分区数量而提升。例如,通过将一个大型表划分成10个分区,一个查询的执行速度将比在未分区表上快10倍,前提是这些分区就是为支持该查询的条件而设计。
不要创建超过所需数量的分区。创建过多的分区可能会拖慢管理和维护工作,例如清理、恢复Segment、扩展集群、检查磁盘用量等等。
除非查询优化器能基于查询谓词排除一些分区,否则分区技术不能改进查询性能。每个分区都扫描的查询运行起来会比表没有分区时还慢,因此如果用户的查询中很少能排除分区,请避免进行分区。
Warning: 请对多级分区格外谨慎,因为分区文件的数量可能会增长得非常快。例如,如果一个表被按照日和城市划分并且有1,000个日以及1,000个城市,那么分区的总数就是一百万。列存表会把每一列存在一个物理表中,因此如果这个表有100个列,系统就需要为该表管理一亿个文件。
在选定一种多级分区策略之前,可以考虑一种带有位图索引的单级分区。索引会降低数据装载的速度,因此推荐用用户的数据和模式进行性能测试以决定最佳的策略。 - 分区表的限制
● 对于每个分区级别,一个已分区的表最多能有32,767个分区。
● 用DISTRIBUTED REPLICATED分布策略创建的表不能被分区。
● 其他限制参见官方文档
3.8. 创建分区表
设计一个表分区需要考虑以下内容:
● 决定分区设计:日期范围、数字范围或者值的列表。
● 选择要按哪个(哪些)列对表分区。
● 决定用户需要多少个分区级别。例如,用户可以按月创建一个日期范围分区表,然后对每个月的分区按照销售地区划分子分区。
- 日期范围分区表
一个按日期范围分区的表使用单个date或者timestamp列作为分区键列。如果需要,用户可以使用同一个分区键列来创建子分区,例如按月分区然后按日建子分区。请考虑使用最细的粒度分区。例如,对于一个用日期分区的表,用户可以按日分区并且得到365个每日的分区,而不是先按年分区然后按月建子分区再然后按日建子分区。一种多级设计可能会减少查询规划时间,但是一种平面的分区设计运行得更快。
用户可以通过给出一个START值、一个END值以及一个定义分区增量值的EVERY子句让Greenplum数据库自动产生分区。默认情况下,START值总是被包括在内,而END值总是被排除在外。例如:
create table sales (
id int,
date date,
amt decimal(10, 2)
) DISTRIBUTED by (id)
partition by range (date) (
start (date '2016-01-01') INCLUSIVE
end (date '2017-01-01') EXCLUSIVE
every (interval '1 day')
);
用户也可以逐个声明并且命名每一个分区。例如:
create table sales (
id int,
date date,
amt decimal(10, 2)
) DISTRIBUTED by (id)
partition by range (date) (
partition Jan16 start (date '2016-01-01') INCLUSIVE ,
partition Feb16 start (date '2016-02-01') INCLUSIVE ,
partition Mar16 start (date '2016-03-01') INCLUSIVE ,
partition Apr16 start (date '2016-04-01') INCLUSIVE ,
partition May16 start (date '2016-05-01') INCLUSIVE ,
partition Jun16 start (date '2016-06-01') INCLUSIVE ,
partition Jul16 start (date '2016-07-01') INCLUSIVE ,
partition Aug16 start (date '2016-08-01') INCLUSIVE ,
partition Sep16 start (date '2016-09-01') INCLUSIVE ,
partition Oct16 start (date '2016-10-01') INCLUSIVE ,
partition Nov16 start (date '2016-11-01') INCLUSIVE ,
partition Dec16 start (date '2016-12-01') INCLUSIVE
end (date '2017-01-01') EXCLUSIVE
);
- 数字范围分区表
一个按数字范围分区的表使用单个数字数据类型列作为分区键列。例如:
create table rank (
id int,
rank int,
year int,
gender char(1),
count int
) DISTRIBUTED by (id)
partition by range (year) (
start (2006)
end (2016) every (1),
default partition extra
);
- 列表分区表
一个按列表分区的表可以使用任意允许等值比较的数据类型列作为它的分区键列。一个列表分区也可以用一个多列(组合)分区键,反之一个范围分区只允许单一列作为分区键。对于列表分区,用户必须为每一个用户想要创建的分区(列表值)声明一个分区说明。例如:
create table rank (
id int,
rank int,
year int,
gender char(1),
count int
) DISTRIBUTED by (id)
partition by LIST (gender) (
partition girls values ('F'),
partition boys values ('M'),
default partition other
);
Note: 当前的Greenplum数据库传统优化器允许列表分区带有多列(组合)分区键。一个范围分区只允许单一列作为分区键。Greenplum查询优化器不支持组合键,因此用户不能使用组合分区键。
4. 多级分区表
用户可以用分区的子分区创建一种多级分区设计。使用一个子分区模板可以确保每一个分区都有相同的子分区设计,包括用户后来增加的分区。例如,下面的SQL创建所示的两级分区设计:
create table sales (
trans_id int,
date date,
amount decimal(9, 2),
region text
) DISTRIBUTED by (trans_id)
partition by range (date)
SUBPARTITION by LIST (region)
SUBPARTITION TEMPLATE (
SUBPARTITION usa values ('usa'),
SUBPARTITION asia values ('asia'),
SUBPARTITION europe values ('europe'),
default SUBPARTITION other_regions
) (
start (date '2011-01-01') INCLUSIVE
end (date '2012-01-01') EXCLUSIVE
every (interval '1 month'),
default partition outlying_dates
);
下面的例子展示了一个三级分区设计,其中sales表被按照year分区,然后按照month分区,再然后按照region分区。SUBPARTITION TEMPLATE子句保证每一个年度的分区都有相同的子分区结构。这个例子在该层次的每一个级别上都声明了一个DEFAULT分区。
create table p3_sales (
id int,
year int,
month int,
day int,
region text
) DISTRIBUTED by (id)
partition by range (year)
SUBPARTITION by range (month)
SUBPARTITION TEMPLATE (
start (1)
end (13)
every (1),
default SUBPARTITION other_months
)
SUBPARTITION by LIST (region)
SUBPARTITION TEMPLATE (
SUBPARTITION usa values ('usa'),
SUBPARTITION europe values ('europe'),
SUBPARTITION asia values ('asia'),
default SUBPARTITION other_regions
) (
start (2002)
end (2012)
every (1),
default partition outlying_years
);
注意:当用户创建基于范围的多级分区时,很容易会创建大量的子分区,有一些包含很少的甚至不包含数据。这可能会在系统表中增加很多项,这些项增加了优化和执行查询所需的时间和内存。增加范围区间或者选择一种不同的分区策略可减少创建的子分区数量。
5. 对已有的表进行分区
表只能在创建时被分区。如果用户有一个表想要分区,用户必须创建一个分过区的表,把原始表的数据载入到新表,再删除原始表并且把分过区的表重命名为原始表的名称。用户还必须重新授权表上的权限。例如:
create table sales2 (
like sales
) partition by range (date) (
start (date '2016-01-01') INCLUSIVE
END (date '2017-01-01') EXCLUSIVE
EVERY (INTERVAL '1 month')
);
insert into sales2 select * from sales;
drop table sales;
alter table sales2 rename to sales;
grant all privileges on sales to admin;
grant select on sales to guest;
- 查看分区表的信息
● pg_partitions:查看有关分区设计的信息。
● pg_partition:跟踪分区表以及它们的继承层次关系。
● pg_partition_templates:展示使用一个子分区模板创建的子分区。
● pg_partition_columns:显示在一个分区设计中用到的分区键列。
3.9. 维护分区表
要维护一个分区表,对顶层父表使用ALTER TABLE命令。最常用的情景是删除旧的分区以及增加新的分区,以此在一种范围分区设计中维护数据的一个滚动窗口。用户可以把旧的分区转换(交换)成追加优化的压缩存储格式来节省空间。如果在用户的分区设计中有一个默认分区,用户可以通过分裂默认分区来增加一个分区。
- 增加分区
用户可以用ALTER TABLE命令为一个分区设计增加一个分区。如果原始分区设计包括由一个子分区模板定义的子分区,新增加的分区也会根据该模板划分子分区。例如:
alter table sales add partition
start (date '2017-02-01') INCLUSIVE
end (date '2017-03-01') EXCLUSIVE;
如果在创建表时没有使用一个子分区模板,用户可以在增加分区时定义子分区:
alter table sales add partition
start (date '2017-02-01') INCLUSIVE
end (date '2017-03-01') EXCLUSIVE (
SUBPARTITION usa values ('usa'),
SUBPARTITION asia values ('asia'),
SUBPARTITION europe values ('europe')
);
当用户为一个现有分区增加一个子分区时,用户可以指定要更改的分区。例如:
alter table sales alter partition for (rank(12))
add partition africa values ('africa');
Note: 用户不能向一个具有默认分区的分区设计中增加分区。用户必须分裂默认分区来增加分区。
2. 重命名分区
分区表使用下列命名习惯。分区子表的名称服从唯一性要求和长度限制。
<parentname>_<level>_prt_<partition_name>
例如:sales_1_prt_jan16
对于自动生成的范围分区,在没有给出名称时会分配一个数字:sales_1_prt_1
要重命名一个已分区的子表,应重命名顶层父表。在所有相关的子表分区的表名中,都会改变。例如下面的命令:
alter table sales rename to globalsales;
会修改相关的表名:globalsales_1_prt_1
用户可以更改一个分区的名称让它更容易标识。例如:
alter table sales rename partition for ('2016-01-01') to jan16;
会把相关的表名改为如下:sales_1_prt_jan16
在使用ALTER TABLE命令修改分区表时,总是用它们的分区名(jan16)而不是它们的完整表名(sales_1_prt_jan16)引用表。
Note: 表名不能是一个ALTER TABLE语句中的分区名。例如,ALTER TABLE sales…是正确的。 ALTER TABLE sales_1_part_jan16…则不被允许。
3. 增加默认分区
用户可以用ALTER TABLE命令为一个分区设计增加一个默认分区。
alter table sales add default partition other;
如果用户的分区设计是多级的,该层次中每一级都必须有一个默认分区。例如:
alter table sales alter partition for (rank(1)) add default partition other;
alter table sales alter partition for (rank(2)) add default partition other;
alter table sales alter partition for (rank(3)) add default partition other;
如果到来的数据不匹配一个分区的CHECK约束并且没有默认分区,该数据就会被拒绝。默认分区确保到来的不匹配一个分区的数据能被插入到默认分区中。
4. 删除分区
用户可以使用ALTER TABLE命令从用户的分区设计中删除一个分区。当用户删除一个具有子分区的分区时,子分区(以及其中的所有数据)也会被自动删除。对于范围分区,从范围中删除较老的分区很常见,因为旧的数据会被滚出数据仓库。例如:
alter table sales drop partition for (rank(1));
- 截断分区
用户可以使用ALTER TABLE命令截断一个分区。当用户截断一个具有子分区的分区时,子分区也会被自动截断。
alter table sales TRUNCATE partition for (rank(1));
- 交换分区
用户可以使用ALTER TABLE命令交换一个分区。交换一个分区用一个表换掉一个现有的分区。用户只能在分区层次的最底层交换分区(只有包含数据的分区才可以被交换)。
不可以交换包含复制表的分区。不支持使用分区表或分区表的子分区交换分区。
分区交换对数据装载有用。例如,装载一个分段表并且把装载好的表换入到用户的分区设计中去。用户可以使用分区交换来把较老分区的存储类型改为追加优化表。例如:
create table jan12 (
like sales
) with (
appendoptimized = true
);
insert into jan12 select * from sales_1_prt_1;
alter table sales EXCHANGE partition for (DATE '2012-01-01') with table jan12;
Note: 这个例子指的是表sales的单级定义,就是在前面那些例子对它增加或者修改分区之前。
Warning: 如果用户指定WITHOUT VALIDATION子句,用户必须确保用户用于交换现有分区的表中的数据对于该分区上的约束是合法的。否则,针对分区表的查询可能会返回不正确的结果。
Warning: 在用户交换默认分区前,用户必须确保要被交换的表中的数据(即新的默认分区)对于默认分区是合法的。例如,新默认分区中的数据不能含有对分区表其他叶子子分区有效的数据。否则,交换过默认分区的分区表上由GPORCA执行的查询可能会返回不正确的结果。
7. 分裂分区
分裂一个分区会把一个分区划分成两个分区。用户可以使用ALTER TABLE命令分裂分区。只能在最低层级的分区做分裂(包含数据的分区)。对于对级别分区,只是范围分区可以分裂,列表分区不行。用户指定的分裂值会分在后一个分区中。
例如,把一个月度分区分裂成两个,第一个分区包含日期January 1-15而第二个分区包含日期January 16-31:
alter table sales SPLIT partition
for ('2017-01-01') at ('2017-01-16')
into
(
partition jan171to15,
partition jan1716to31
);
如果用户的分区设计有一个默认分区,用户必须分裂该默认分区来增加分区。
在使用INTO子句时,指定当前的默认分区为第二个分区名。例如,要分裂一个默认的范围分区来为January 2017增加一个新的月度分区:
alter table sales SPLIT default partition
start ('2017-01-01') INCLUSIVE
end ('2017-02-01') EXCLUSIVE
into
(
partition jan17,
default partition
);
4. 视图
视图允许用户保存常用的或者复杂的查询,然后在一个SELECT语句中把它们当作表来访问。视图在磁盘上并没有被物理存储:当用户访问视图时查询会作为一个子查询运行。
如果一个子查询与一个单一查询相关联,考虑使用SELECT命令的WITH子句而不是创建一个很少使用的视图。
4.1. 创建视图
create view comedies as
select * from films where kind = 'comedy';
视图会忽略存储在视图中的ORDER BY以及SORT操作。
4.2. 删除视图
drop view topten;
DROP VIEW … CASCADE命令也可以移除所有依赖的对象。例如,如果另一个视图依赖于将要被删除的视图,这个其他的视图也将被删除。如果没有CASCADE选项,这个DROP VIEW命令将会失败。
5. 索引
在大部分传统数据库中,索引能够极大地改善数据访问时间。不过,在一个Greenplum之类的分布式数据库中,索引应该被更保守地使用。Greenplum数据库会执行非常快的顺序扫描,索引则使用一种随机搜索的模式在磁盘上定位记录。Greenplum的数据分布在Segment上,因此每个Segment会扫描全体数据的一小部分来得到结果。通过表分区,要扫描的数据量可能会更少。因为商业智能(BI)查询负载通常会返回非常大的数据集,使用索引并不是很有效。
Greenplum数据库数据库支持Postgres索引类型B-树、GiST和GIN,不支持Hash索引。每一种索引类型都使用一种不同的算法,它们最适合的查询类型也不同。
Note: 只有索引键的列与Greenplum分布键相同(或者是其超集)时,Greenplum数据库才允许唯一索引。在追加优化表上不支持唯一索引。在分区表上,唯一索引无法在一个分区表的所有子表分区之间被实施。唯一索引只能在一个分区内实施。
5.1. 创建索引
1. B-树索引
CREATE INDEX gender_idx ON employee (gender);
B-树索引适合于最常见的情况并且是默认的索引类型。
2. 位图索引
CREATE INDEX title_bmp_idx ON films USING bitmap (title);
● 何时使用位图索引
位图索引最适合用户只查询数据而不更新数据的数据仓库应用。对于拥有100至100,000个可区分值的列并且当被索引列常常与其他被索引列联合查询时,位图索引表现最好。低于100个可区分值的列通常无法从任何类型的索引受益,例如有两个可区分值的性别列(男和女)。而在具有超过100,000个可区分值的列上,位图索引的性能和空间效率会下降。
位图索引能够提升临时查询的查询性能。在将结果位图转换成元组ID之前,一个查询的WHERE子句中的AND以及OR条件可以通过在位图上直接执行相应的布尔操作快速地解决。如果结果行数很小,查询能够在不做全表扫描的情况下很快地被回答。
● 何时不用位图索引
不要为唯一列或者具有高基数数据的列使用位图索引,例如顾客姓名或者电话号码。位图索引的性能增益和磁盘空间优势在具有100,000或者更多唯一值的列上开始减小,这与表中的行数无关。
位图索引不适合有大量并发事务修改数据的OLTP应用。
请保守地使用位图索引。测试并且比较使用索引和不使用索引的查询性能。只有被索引列的查询性能有提升时才增加索引。
3. 表达式索引
索引列不必只是表的一列,而是可以是从表的一列或多列计算的函数或标量表达式。此功能对于根据计算结果快速访问表非常有用。
索引表达式的维护成本相对较高,因为必须在插入和每次更新时为每一行计算派生表达式。但是,索引表达式在索引搜索期间不会重新计算,因为它们已存储在索引中。因此,当检索速度比插入和更新速度更重要时,表达式上的索引很有用。
● 示例一:
CREATE INDEX test1_lower_col1_idx ON test1 (lower(col1));
SELECT * FROM test1 WHERE lower(col1) = 'value';
● 示例二:
CREATE INDEX people_names ON people ((first_name || ' ' || last_name));
SELECT * FROM people WHERE (first_name || ' ' || last_name) = 'John Smith';
5.2. 管理索引
1. 重建索引
使用REINDEX命令可以重建一个表现不好的索引。
--重建一个表上的所有索引
REINDEX my_table;
--重建一个索引
REINDEX my_index;
2. 删除索引
在载入数据时,删除所有索引、载入数据然后重建索引会更快。
DROP INDEX title_idx;
3. 聚簇索引
聚簇一个索引意味着记录会根据索引被物理排序后存储在磁盘上。如果用户需要的数据被随机分布在磁盘上,数据库必须在磁盘上来回寻找以取得所需的记录。如果这些记录被存储得彼此临近,那么取得它们的操作就会更高效。例如,一个在日期列上的聚簇索引中数据会按照日期顺序存放。针对一个指定日期范围的查询将会导致对磁盘的一次有序地读取,这会利用快速的顺序访问。
使用CLUSTER命令根据一个索引从物理上重新排序一个非常大的表可能会花费很长的时间。为了更快达到同样的结果,用户可以通过创建一个中间表并且按照想要的顺序重载数据来手工在磁盘上重排数据。
CREATE TABLE new_table (LIKE old_table) AS
SELECT * FROM old_table ORDER BY myixcolumn;
DROP old_table;
ALTER TABLE new_table RENAME TO old_table;
CREATE INDEX myixcolumn_ix ON old_table;
VACUUM ANALYZE old_table;
6. 最佳实践
6.1. 数据模型
● Greenplum数据库是一种shared nothing的分析型MPP数据库。这种模型与高度规范化的/事务型 的SMP数据库有显著区别。正因为如此,推荐以下几项最佳实践。Greenplum数据库使用非规范化的模式设计会工作得最好,非规范化的模式适合于MPP分析型处理,例如:带有大型事实表和较小维度表的星形模式或者雪花模式。
● 表之间用于连接(join)的列采用相同的数据类型。
6.2. 堆存储 vs 追加优化存储
● 经常进行反复的批量或单一UPDATE,DELETE和INSERT操作的表或分区使用堆存储。
● 经常进行并发UPDATE,DELETE和INSERT的表或分区使用堆存储。
● 对于在初始装载后很少更新并且只会在大型批处理操作中进行后续插入的表和分区,使用追加优化存储。
● 绝不在追加优化表上执行单个INSERT,UPDATE或 DELETE操作。
● 绝不在追加优化表上执行并发的批量UPDATE或DELETE操作。可以执行并发的批量INSERT操作。
6.3. 行存 vs 列存
● 如果负载中有要求更新并且频繁执行插入的迭代事务,则对这种负载使用行存。
● 在对宽表选择时使用行存。
● 为一般目的或混合负载使用行存。
● 选择面很窄(很少的列)和在少量列上计算数据聚集时使用列存。
● 如果表中有单个列定期被更新而不修改行中的其他列,则对这种表使用列存。
6.4. 压缩
● 在大型追加优化和分区表上使用压缩以改进系统范围的I/O。
● 在数据最终的存储位置表设置列压缩。
● 平衡压缩解压缩时间和CPU执行周期,选择性能最高的压缩级别。
6.5. 数据分布
● 为所有的表显式定义一个列分布或者随机分布。不要使用默认值。
● 使用能将数据在所有segment上均匀分布的单个列作为分布键。
● 不要采用查询的WHERE条件中使用的列作为分布键。
● 不要采用日期或时间戳作为分布键。
● 不要将同一列同时用于数据分布和分区。
● 在经常做连接(join)操作的大表上采用相同的分布键,这样可以通过本地连接(join)来显著提高性能。
● 在初始装载数据以及增量装载数据之后验证数据没有明显倾斜。
6.6. 分区
● 只对大型表分区。不要分区小表。
● 只有能基于查询条件实现分区消除(分区裁剪)时才使用分区。
● 选择范围分区而舍弃列表分区。
● 基于查询谓词对表分区。
● 不要在同一列上对表进行分布和分区。
● 不要使用默认分区。
● 不要使用多级分区,创建较少的分区让每个分区中有更多数据。
● 通过检查查询的EXPLAIN计划验证查询有选择地扫描分区表(分区被裁剪)。
● 不要用列存储创建太多分区,因为每个Segment上的物理文件总数:physical files = segments x columns x partitions
6.7. 索引
● 通常在Greenplum数据库中无需使用索引。
● 对高基数的表在列式表的单列上创建索引用于钻透目的要求查询具有较高的选择度。
● 不要索引被频繁更新的列。
● 总是在装载数据到表之前删除索引。在装载后,重新为该表创建索引。
● 创建具有选择性的B-树索引。
● 不要在被更新的列上创建位图索引。
● 不要为唯一列、基数非常高或者非常低的数据使用位图索引。位图索引在列值唯一性位于100-100,000之间时性能最好。
● 不要为事务性负载使用位图索引。
● 通常不要索引分区表。如果需要索引,索引列必须与分区列不同。